摘要
稀疏混合专家(SMoE) 语言模型Mixtral 8x7B
(那大概可以理解成他是一个缝合怪,把所有的任务模型缝合到一起,然后有一个类似打分投票的路由机制来针对输入问题选择任务子模型从而得到针对性的结果。)。Mixtral具有与Mistral 7B相同的架构,不同之处在于每层由8个前馈块(即专家)组成。对于每一个令牌,在每一层,路由器网络都会选择两名专家来处理当前状态并组合他们的输出。尽管每个令牌只能看到两个专家,但在每个时间步长选择的专家可能不同。结果,每个令牌都可以访问47B参数,但在推理期间仅使用13B活动参数。Mixtral是用32k个令牌的上下文大小进行训练的,在所有评估的基准中,它都优于或匹配Llama 2 70B和GPT-3.5。特别是,Mixtral在数学、代码生成和多语言基准测试方面大大优于Llama 2 70B。我们还提供了一个根据说明进行微调的模型,Mixtral 8x7B–Instruction,它在人类基准测试上超过了GPT-3.5 Turbo、Claude-2.1、Gemini Pro和Llama 2 70B–聊天模型。基本模型和指令模型都是在Apache 2.0许可证下发布的。
引言
由于Mixtral只对每个令牌使用其参数的子集,因此在低批量时可以实现更快的推理速度,在大批量时可以获得更高的吞吐量。Mixtral是一个稀疏的专家混合网络。它是一个仅解码器的模型
(那就意味着它更多地在意输出,所以和bert是相反的极端,bert更侧重于完型理解,Mixtral侧重于生成),其中前馈块从一组8个不同的参数中选取。在每一层,对于每一个令牌,路由器网络选择其中两个组(“专家”)来处理令牌,并将其输出相加。这项技术增加了模型的参数数量,同时控制了成本和延迟,因为模型每个令牌只使用总参数集的一小部分。
使用32k令牌的上下文大小使用多语言数据进行预训练的
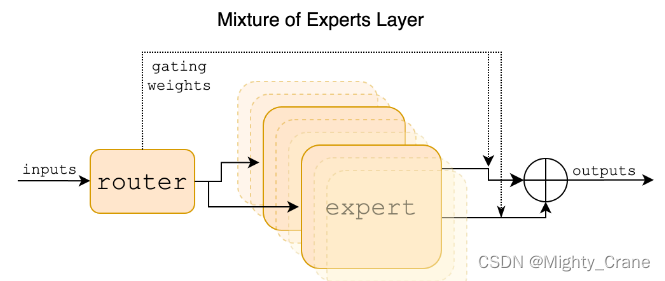
混合专家层。每个输入矢量由路由器分配给8个专家中的2个。该层的输出是两个选定专家的输出的加权和。在Mixtral中,专家是一个标准的前馈块,就像在vanilla transformer架构中一样。
Mixtral在数学、代码生成和需要多语言理解的任务方面表现出卓越的能力,在这些领域显著优于Llama 2 70B。实验表明,无论序列长度和信息在序列中的位置如何,Mixtral都能够成功地从其32k个令牌的上下文窗口中检索信息。我们还介绍了Mixtral 8x7B–Instruction,这是一种使用监督微调和直接偏好优化进行微调以遵循指令的聊天模型[25]。在人类评估基准上,它的性能显著超过了GPT-3.5 Turbo、Claude-2.1、Gemini Pro和Llama 2 70B聊天模型。Mixtral–Instruction还展示了减少的偏见,以及在BBQ和BOLD等基准中更平衡的情绪。
那总结一下就是:
总参数可以增多,因为实际每token利用参数少,节省复杂度成本
在数学、代码生成和多语言领域出色
Mixtral 8x7B–Instruction聊天更客观沉稳
架构细节
提到专家层的稀疏性,我的理解是这个专家门控遇到稀疏的张量会使得大部分的专家权重为0,从而避免计算这些多余的内容,从而达到门控、路由等等达到有选择有针对的效果。
至于这个专家权重的得到,
- 输入x会与门控网络的权重Wg相乘,得到logits。
- Top-K 操作会从这些 logits 中选择 K 个最大的值。这意味着只有部分专家(即得分最高的 K 个)会被选中来处理当前的 token
(也就是x)。 - 然后通过 Softmax函数将这些 Top-K 的 logits 转化为概率分布,即权重 G(x)。
- 接下来,模型计算每个专家网络 Ei(x)的输出,并将这些输出乘以对应的权重 G(x)i。由于大多数权重为零(即那些没有被选中的专家),模型实际上不会计算这些专家的输出,从而节省了计算资源。
(所以实际利用的参数量只和k有关) - 最后,模型将所有被选中的专家的加权输出相加,形成最终的输出
可以单/多GPU处理,但是多GPU分布式时需要注意均匀分配工作负载
对于Transformer结构来说,不论是在自然语言处理(NLP)还是计算机视觉(CV)领域,它都是以一次处理整个序列的方式运行的。即使是在处理图像的时候,所有的patches(tokens)也是作为序列的一部分一起处理的。
当论文中提到“MoE layer is applied independently per token”时,并不是指物理上独立地单个处理每个token。而是指在计算过程中,每个token都会通过MoE层,并且每个token都可以独立地选择它的“专家”或参数集合。这个过程在模型的内部是并行化的,并且是由深度学习框架在后台处理的。模型并不是逐个序列化地处理每个token,而是在整个批次的tokens上并行地应用MoE层。
所以,虽然处理是“独立”于每个token的,但这并不意味着在硬件上每个token是单独处理的。在硬件上,这些操作仍然是在一个批次的数据上高度并行化的,以利用现代GPU的并行处理能力。这样的设计旨在保持Transformer模型在处理大规模数据时的高效率,同时通过MoE层引入更多的模型容量和灵活性。
结果
与llama打擂台
•常识推理(0-shot): Hellaswag [32], Winogrande [26], PIQA [3], SIQA [27], OpenbookQA [22], ARC-Easy, ARC-Challenge [8], CommonsenseQA[30]
•世界知识(5-shot): NaturalQuestions [20], TriviaQA[19]
•阅读理解(0-shot): BoolQ [7], QuAC[5]
•数学:GSM8K [9] (8-shot) with maj@8和Math [17] (4-shot) with maj@4
•代码:Humaneval [4] (0-shot)和MBPP [1] (3-shot)
•大众综合结果:MMLU16、BBH29和AGI Eval34
路由分析
专家模型的选择并没有显示出强烈的针对特定领域问题的倾向性。这意味着专家子模型并不是专门为解决某个特定领域的问题而训练的。专家并没有在某个具体问题上表现出专业化的行为,所以它们不太可能被单独摘出来单独作为针对特定问题的模型。
这样的结果可能意味着Mixtral模型的路由器在分配任务给专家时,侧重于更细粒度的特征而非整体的领域或主题。