作者:宇轩辞白,运维研发工程师,目前专注于云原生、Kubernetes、容器、Linux、运维自动化等领域。
前言
2023 年 11 月 7 号下午,研发同事反馈,项目线上日志平台某个服务无法查看近期的日志。我登上 KubeSphere 平台进行查看,发现日志收集展示停留在 10 月 15 号那天,而其它的服务是正常的。
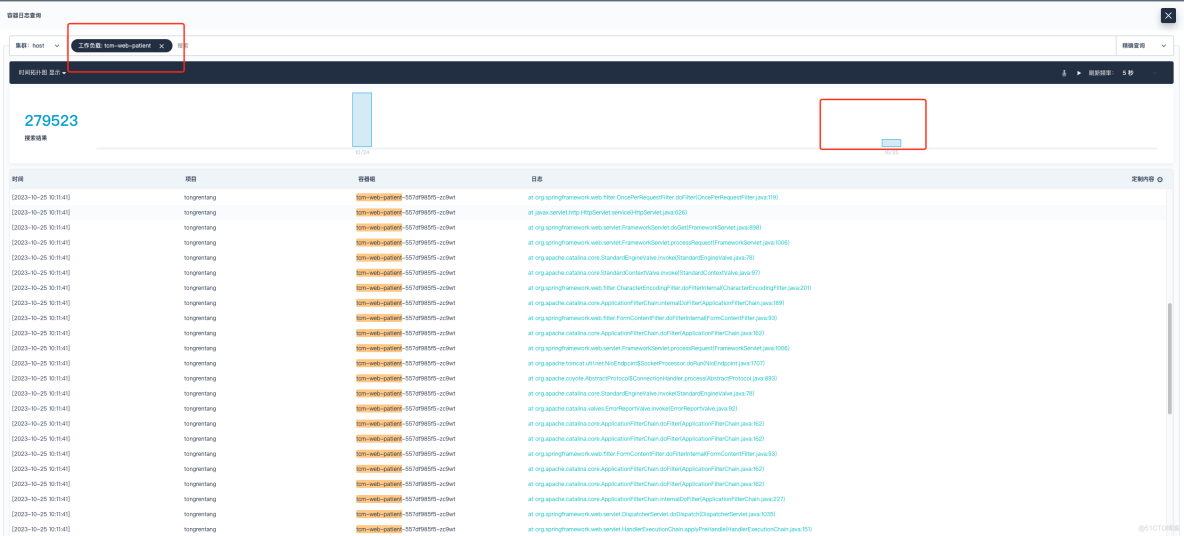
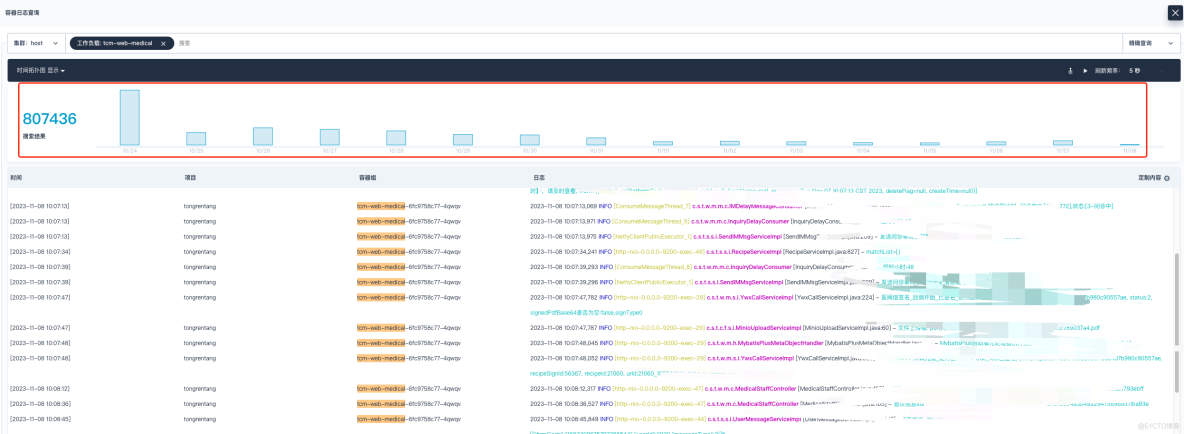
问题跟踪定位分析
结合已有的经验积累,我做了如下猜想:
- 一种原因,是不是日志系统对应的 PVC 存储卷被打满了,导致日志索引被锁定,间接影响服务的日志采集呢?
- 另一种原因,日志采集工具 Fluent Bit 缓冲区资源配置无法满足当前的日志输出量,也会导致该问题的出现。
为了验证上述的猜想,我展开了详细排查:
- 把 es 的接口放开,查询索引状态,看看有没有被锁定的。
- 确认无法收集日志容器所在的 node 节点,并找与之对应同 node 节点的 Fluent Bit 容器服务,查看 Fluent Bit 日志输出是否存在异常信息。
登录到 node 节点查看 Fluent Bit 服务日志信息,关键信息如下:
[2023/07/23 00:15:37][ warn] [http_client] cannot increase buffer: current=512000 requested=544768 max=512000
{"log":"[2023/11/08 10:26:33][ warn] [input] tail.2 paused (mem buf overlimit)\n","stream":"stderr","time":"2023-11-08T10:26:33.406030339Z"}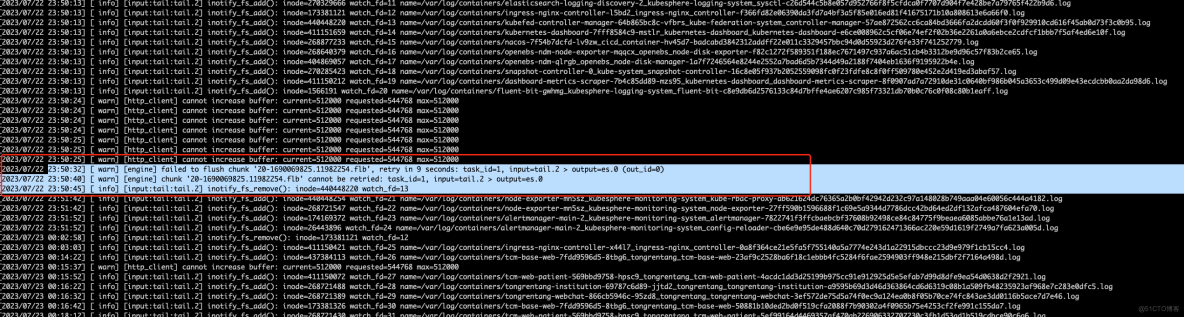
报错问题分析 1
tail.2 paused (mem buf overlimit) 表示 tail 输入插件在 Fluent Bit 中的实例 tail.2 因为内存缓冲区超出限制而被暂停。 这个告警信息意味着 Fluent Bit 的内存缓存区超过了先前设置的"memBuflimit"限制的大小,导致插件被暂停。之后,存储缓冲区超过限制时被恢复,这可能代表着 Fluent Bit 尝试将一些缓冲数据写入目标存储介质。
这通常是由于日志产生的速度过快,而内存缓冲区无法及时处理并写入到输出目标中,结合问题现象来看,那就不难说明日志为啥在 10 月 25 号之后就没有采集展示了。
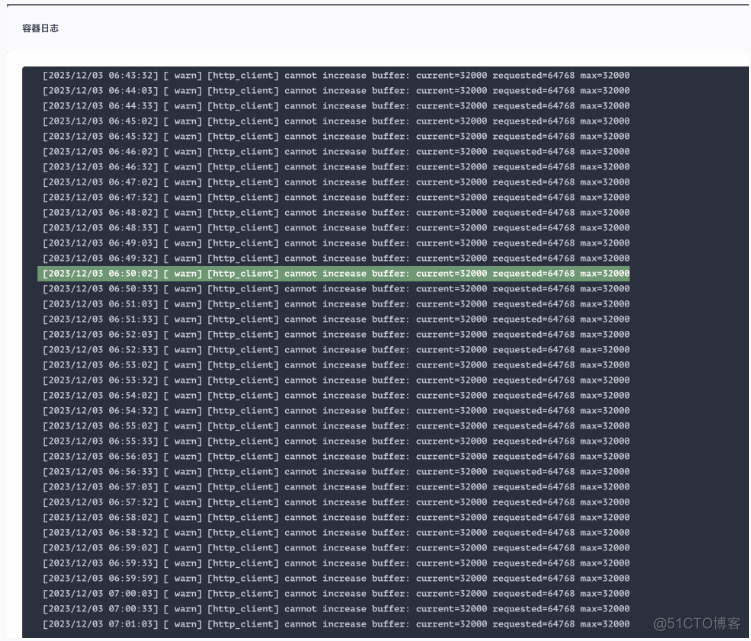
报错问题分析 2
根据日志信息中 [ warn] [http_client] cannot increase buffer: current=32000 requested=64768 max=32000 可知,在 HTTP 客户端无法增加缓冲区大小。当前的缓冲区大小为 32000B(也就是默认大小为 32KB 字节),无法满足请求。由于项目是初期建设,日志平台参数都没有进行优化调整,都保持默认值,因此当日志量级达到一定的级别就会出现该问题,且无法动态调整。
解决方案
针对上述问题,这里可以尝试通过以下方案去解决该问题:
增加
memBufLimit的值,调整内存缓冲区大小:根据具体情况,可以增加memBufLimit的大小,以提供更多内存缓冲区空间处理更多的日志。但需要注意,增加内存缓冲区的大小可能会占用更多的内存资源,因此需要确保系统有足够的内存资源。另外可以调整存储缓冲区大小。根据告警信息,存储缓冲区大小为 128KB,可以考虑增加存储缓冲区大小,以适应更大的数据负载。调整
Buffer_Size的值,调整缓冲区大小:根据实际具体情况,适当增加Buffer_Size的大小。优化日志收集和处理过程:评估当前的日志收集和处理流程,查找可能导致日志快速增长的原因,并采取相应的措施来优化日志生成和处理速度。例如,限制日志的输出频率,对日志进行压缩或者聚合等。
调整日志处理的配置:结合实际情况,调整 Fluent Bit 的配置来更好地适应日志生成和处理需求。例如,可以使用更快的输出插件,调整日志过滤器或者解析器的配置等。
参数剖析
在 Fluent Bit(日志收集和转发工具)的场景中,memBufLmit 和 buffer_size 是两个相关但是不同的参数。
- memBufLmit(内存缓冲区限制):
memBufLimit 是 Fluent Bit 中内存缓冲区大小限制,它定义了 Fluent Bit 在内存中分配给缓冲区的最大空间,当缓冲区达到这个限制时,后续的数据将不再接受和处理。
memBufLimit 可以用来限制 Fluent Bit 处理大量日志所使用的内存大小,以防止它过度消耗系统资源,配合合理的 memBufLimit 值可以帮助确保 Fluent Bit 在接受的内存范围内运行,并避免因内存不足导致性能下降或者崩溃。
- buffer_size(缓冲区大小):
buffer_size 是 Fluent Bit 在输出插件中使用的一个参数,用于定义缓冲区的大小,缓冲区用于将日志数据暂存在内存中,以便在一次性批量处理/传输到目标存储或者服务时提高效率。
buffer_size 可以影响日志数据的传输和内存的消耗,较大的缓冲区可以减少传输的次数,提高效率,但也会占用更多的内存,较小的缓冲区可能会导致更频繁的传输,但会减少内存的消耗。根据具体情况调整缓冲区大小可以平衡传输速度和内存占用。
总结来说,在 Fluent Bit 场景中,memBufLimit 和 buffer_size 的作用如下:
memBufLimit用于限制 Fluent Bit 整体内存缓冲区的大小,以确保其在合理的内存范围内运行。buffer_size用于控制输出插件的缓冲区大小,以提高传输效率和内存消耗。
问题解决
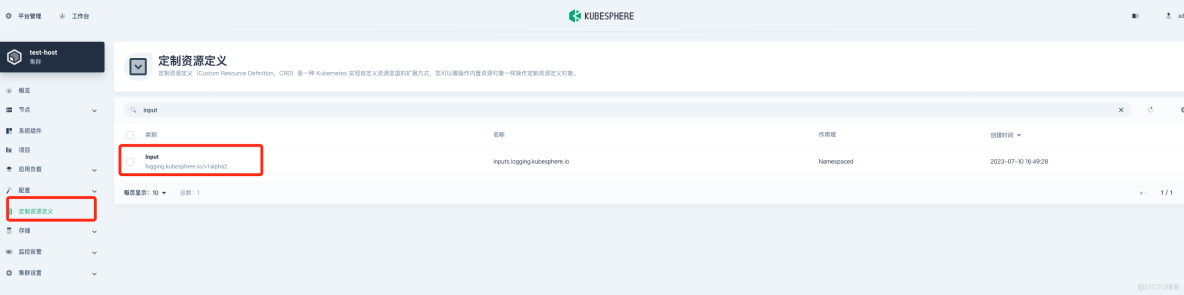
在"定制资源定义(CRD)"->input->"tail" 修改 memBufLimit 参数限制大小,可参考下图:

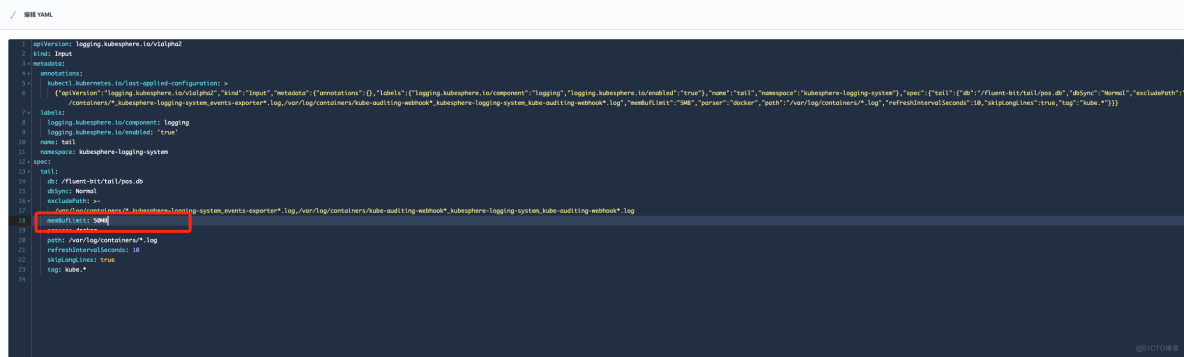
在"定制资源定义(CRD)"->Output->"es" 修改 bufferSize 参数大小,可参考下图:

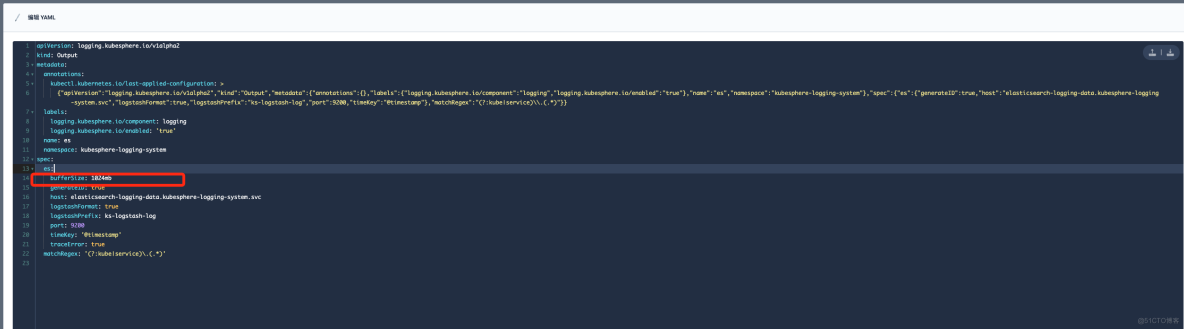
修改完毕之后,随后进行验证日志是否正常展示。参数大小一定要根据自己生产环境的配置进行调整,如果服务器节点性能配置不是很高,那么参数调整之后会严重影响业务,造成 Node 节点负载过高,本人因为这个调整被狠狠地坑过一次。下方截图是当时触发了告警,因为参数调整之后,大量的日志疯狂的刷新,导致节点流量带宽以及负载暴涨。
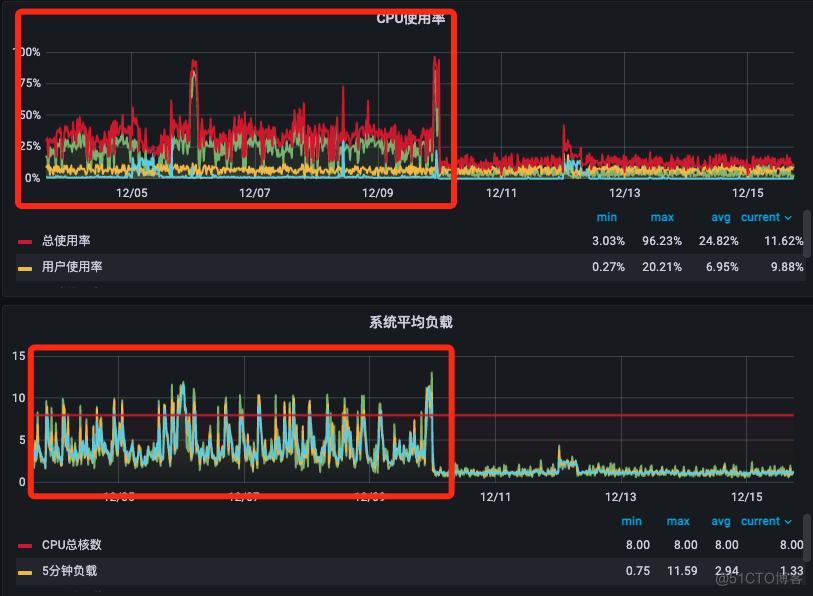
此时可以查看下 Fluent Bit 容器输出日志是否正常。
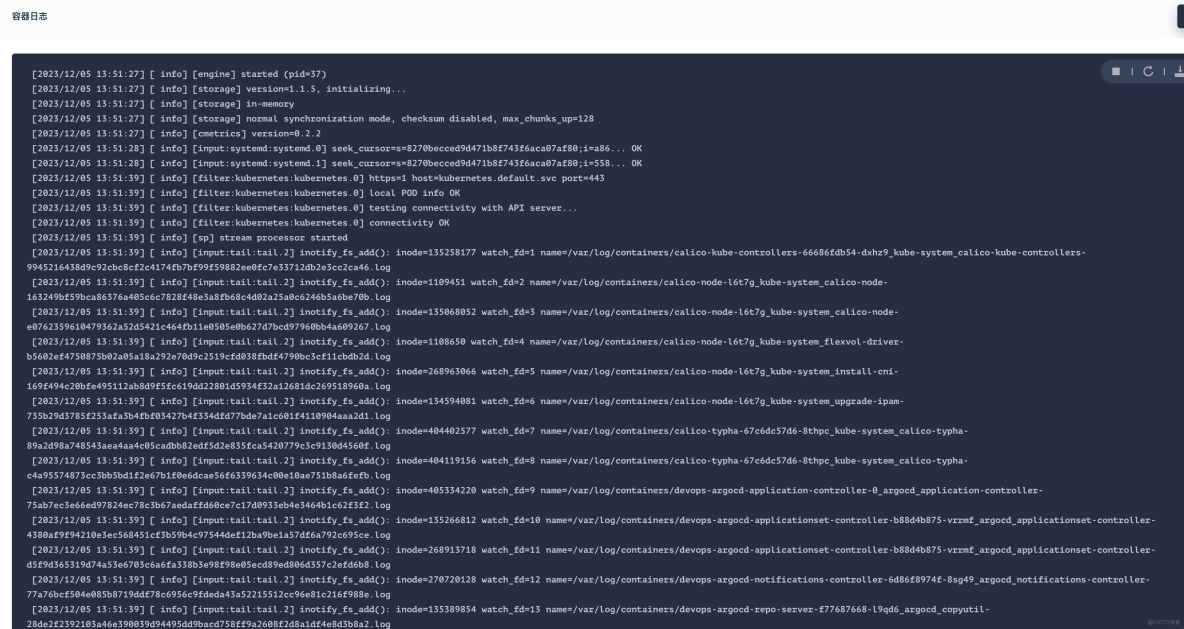
参考文档信息
- https://docs.fluentbit.io/manual/v/1.8/administration/buffering-and-storage
- https://docs.fluentbit.io/manual/v/1.8/administration/scheduling-and-retries
- https://docs.fluentbit.io/manual/v/1.8/pipeline/outputs/elasticsearch
- https://docs.fluentbit.io/manual/v/1.8/pipeline/filters/kubernetes
- https://docs.fluentbit.io/manual/v/1.8/pipeline/inputs/tail
本文由博客一文多发平台 OpenWrite 发布!