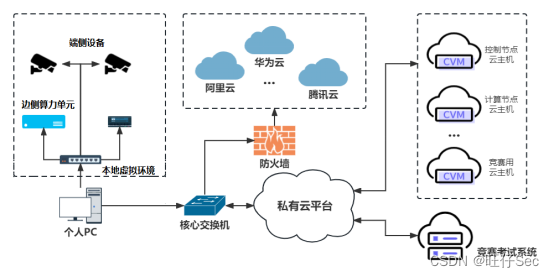
一:爬虫
1、爬取的目标
将读书网上的书籍的基本信息,比如:封面、书名、作者、出版社、价格、出版时间、内容简介、作者简介、书籍目录、ISBN和标签爬取出来,并将爬取的结果放入数据库中,方便存储。
2、网站结构

图1读书网书籍类别详情
此次实验爬取读书网页面中文学、小说、传记、青春文学、艺术、散文随笔、励志、人文社科、经济管理、励志十大类书籍。
每一类书籍包括书名、价格、作者、出版社、ISDN、出版时间、封面以及书籍简介、作者简介、书目录和书籍所属类别。页面具体情况如图2所示。

图2读书网书籍属性设计详情
3、爬虫技术方案
1)、所用技术:
网站解析的使用的是Xpath、数据库存储使用的是pymysql。
2)、爬取步骤:
(1)、分析目标网站:了解页面结构;
(2)、获取页面内容:使用python中的requests库来获取页面内容;
(3)、定位页面:使用Xpath定位我们所需要的数据的位置;
(4)、连接数据库:创建数据连接,放入自己数据库的端口、用户和密码等数据,使得连接上自己的数据库,将爬取好的数据返给数据库中,方便存储;
(5)、关闭连接:关闭数据库连接。
4、爬取过程:
1)、常量定义

此处定义了网页后缀END=‘.html’用于进行网页拼接。
Start_Page = 1 定义爬取起始页码,end_Page = 10 定义爬取结束页码。
Base_url 用于设置爬取网页的基础网站,进行后续网页拼接。
Book_type={},该字典设置爬取书籍类别。
Header={},该字典进行请求头设置。
2)、设置游标,连接数据库,再使用for循环,确保书籍能够循环爬取,最后将爬取完毕的数据放入数据库中,最后关闭数据库的连接。

3)、一级链接爬取,接收参数基本网页地址、书籍类型、网页页数后,再使用requests库中r.get(url=url,headers=header)发送请求,使用response接收请求数据。

4)、二级链接爬取,在数据获取步骤,进行更细致的xpath语句书写。
使用try-except语句提高程序健壮性,返回一个书籍信息字典。

5)、保存数据,创建游标,编写sql语言,之后执行sql语言,执行成功就插入所给的表,如果执行失败则输出插入失败。

5、爬虫结果


二:预处理
-
删除列
1)、新建转换,之后使用表输入,将MySQL文件中的表输入kettle。需要连接数据库的类型是MySQL,主机名称是localhost、用户是root、密码是root、端口号是3306。

之后进行字段获取。

2)、选择转换中的字段选择进行列删除,将dictroy这个列进行删除。

2、选择转换中的增加常量,增加remainder这一列,查询书籍卖出剩余的情况。

-
、最后选择文本文件输出,将处理好的数据输出,输出的格式是csv文件,分割符用逗号隔开,编码用UTF-8J进行转码,防止输出文件中有乱码。文本文件命名为姓名_处理完成_csv。
4、预处理完全处理全流程

三、爬虫源代码
import re
import requests
from lxml import etree
import pymysql
import datetime
"""
爬取一个网站
1.获得数据不小于一千条
2.每条数据属性不小于10
"""END = '.html'
start_Page = 1
end_Page = 10
base_url = 'https://www.dushu.com'
# 以字典形式保存每一类对应的网页数字
book_type = {"文学": 1077, "小说": 1078, "传记": 1081, "青春文学": 1079,"艺术": 1082, "散文随笔": 1163, "鉴赏": 1222, "人文社科": 1003,"经济管理": 1004, "励志": 1094
}header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}def get_one_bookInfo_link(base_url, _type, page):# url 控制爬取的书籍类型、网页页数url = base_url+'/book/'+str(_type)+'_'+str(page)+END# print(url)response = requests.get(url=url, headers=header)if response.status_code == 200:htmlTEXT = response.content.decode(response.apparent_encoding)html = etree.HTML(htmlTEXT)bookLinke_List = html.xpath('//div[@class="container margin-top"]//div[@class="bookslist"]/ul/li/div[@class="book-info"]/h3/a/@href')return bookLinke_Listelse:print("请求失败")def get_oneBook_info(bookLinke):url = base_url + bookLinkecontent = requests.get(url=url, headers=header)if content.status_code == 200:info = etree.HTML(content.content.decode(content.apparent_encoding))# 获取书籍详细信息,十个try:img = info.xpath('//div[@class="bookdetails-left"]/div[@class="book-pic"]//img/@src')[0] # 封面title = info.xpath('//div[@class="bookdetails-left"]/div[@class="book-pic"]//img/@alt')[0] # 书名author = info.xpath('//div[@id="ctl00_c1_bookleft"]/table//tr[1]//td[2]/text()')[0] # 作者publish = info.xpath('//div[@id="ctl00_c1_bookleft"]/table//tr[2]//td[2]/text()')[0] # 出版社temp_price = info.xpath('//div[@id="ctl00_c1_bookleft"]/p/span/text()')[0] # 价格price = temp_price.split('¥')[1]time = info.xpath('//div[@class="bookdetails-left"]/div[@class="book-details"]/table//tr[1]/td[@class="rt"][2]/text()')[0] # 出版时间cont = info.xpath('//div[@class="container margin-top"]//div[contains(@class, "book-summary")][1]/div/div/text()')[0] # 内容简介blurb = info.xpath('//div[@class="container margin-top"]//div[contains(@class, "book-summary")][2]/div/div/text()')[0] # 作者简介directory = info.xpath('//div[@class="container margin-top"]//div[contains(@class, "book-summary")][3]/div/div/text()')[0] # 书籍目录isbn = info.xpath('//div[@class="bookdetails-left"]/div[@class="book-details"]/table//tr[1]/td[@class="rt"][1]/text()')[0] # ISBNlabel = info.xpath('//div[@id="ctl00_c1_bookleft"]/table//tr[4]//td[2]/text()')[0] # 标签# 使用字典保存一本书籍的信息book_info = {"img": img,"title": title,"author": author,"publish": publish,"price": price,"time": time,"cont": cont,"blurb": blurb,"directory": directory,"isbn": isbn,"label": label}return book_infoexcept Exception as e:print("爬取时单本书籍获取出现错误:", e, "\n发生错误地址为:"+url)err_info = {"img": 'https://a.dushu.com/img/n200.png',"title": 'titleEro',"author": 'authorEro',"publish": 'publishEro',"price": '00.00',"time": '2001-01-01',"cont": 'contEro',"blurb": 'blurbEro',"directory": 'directoryEro',"isbn": 'isbnEro',"label": 'labelEro'}return err_infoelse:print("请求失败")def set_BookInfo_ToMySql(book_info, db):# print(book_info.values())cursor = db.cursor()# sql语句sql = "INSERT INTO book(img,title,author,publish,price,time,cont,blurb,directory,isbn,label) VALUES " \"('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')"\%(book_info["img"], book_info["title"], book_info["author"], book_info["publish"],book_info["price"], book_info["time"], book_info["cont"], book_info["blurb"],book_info["directory"], book_info["isbn"], book_info["label"])print(book_info.values())try:# 执行sql语句if cursor.execute(sql):print('插入数据成功')# 提交到数据库执行db.commit() # 持久化except Exception as e:# 如果发生错误则回滚print("插入失败", e)db.rollback()def main():# 用于存储计算数据爬取数量count = 0# 连接数据库db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='pachong')# 开启爬取程序for type in book_type: # 控制爬取书籍的类别for i in range(start_Page, end_Page+1): # 控制每一类爬取的页数# 每一个网页的书籍的二级连接bookLinke_List = get_one_bookInfo_link(base_url=base_url, _type=book_type[type], page=i)if bookLinke_List:for link in bookLinke_List:print(link)info = get_oneBook_info(link)info['label'] = type# print(info)set_BookInfo_ToMySql(book_info=info, db=db)count += 1else:print("爬取内容为空")# 数据插入完成后关闭数据库if db:db.close()print("关闭数据库成功,程序结束")else:print("数据加载成功,数据库未关闭")return countif __name__ == '__main__':print("Run...")# 获取开始时间start_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')# db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='movie')# info = get_oneBook_info('/book/13981332/')# set_BookInfo_ToMySql(info, db=db)# db.close()print("已爬取书籍数量:", main())# 获取结束时间end_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("程序结束{}\n运行开始时间:{}".format(end_time, start_time))