基本介绍
物理信息神经网络是一种基于物理系统的神经网络模型。它的设计灵感来自于神经科学和量子力学,旨在利用物理系统的特性来处理和存储信息。
传统的神经网络使用数字或模拟电子组件作为基本单元进行计算和存储。而物理信息神经网络则使用物理系统中的元件来代替传统的计算单元,例如利用光子、自旋、超导电流等作为信息的载体。
物理信息神经网络的关键特点之一是并行处理能力。由于物理系统的并行性质,可以同时处理多个信息,从而加快计算速度。此外,物理信息神经网络还具有较低的能耗和更高的能效,这是由于物理系统自身的特性所决定的。
在物理信息神经网络的实现中,可以使用不同的物理系统作为基础。例如,光子学是一种常见的选择,利用光的传播和相干性来进行信息处理。另外,自旋电子学和超导电路等也可以作为实现物理信息神经网络的平台。
物理信息神经网络的研究领域仍处于发展阶段,但已经取得了一些有趣的成果。这种新型的神经网络模型有望在信息处理、模式识别和优化等领域展现出独特的优势。然而,目前仍面临许多挑战,包括物理系统的噪声、稳定性和可扩展性等方面的问题。
总的来说,物理信息神经网络是一种利用物理系统来进行信息处理的新型神经网络模型。它结合了神经科学和物理学的思想,具有并行处理、低能耗和高能效等优势,但仍需要进一步的研究和发展来解决相关的挑战。
Python代码
导入包
import torch
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
自定义种子,由于神经网络是随机设置初始解,这是为了使输出的每次结果都固定
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
setup_seed(888888)
设置基础参数,包括网格中点的数量,边界点数量,内点数量等等
基础参数
epochs = 10000 # 训练代数
h = 100 # 画图网格密度
N = 1000 # 内点配置点数
N1 = 100 # 边界点配置点数
N2 = 1000 # PDE数据点
设置边界点和偏微分方程右边的值
def interior(n=N):
# 内点
x = torch.rand(n, 1)
y = torch.rand(n, 1)
cond = 2 * torch.pi**2 * torch.sin(torch.pi * x) * torch.sin(torch.pi * y)
return x.requires_grad_(True), y.requires_grad_(True), cond
requires_grad=True 的作用是让 backward 可以追踪这个参数并且计算它的梯度。
最开始定义你的输入是 requires_grad=True ,那么后续对应的输出也自动具有 requires_grad=True
,如代码中的 y 和 z ,而与 z 对 x 求导无关联的 a ,其 requires_grad 仍等于 False。
def down(n=N1):
# 边界 u(x,0)=0
x = torch.rand(n, 1)
y = torch.zeros_like(x)
cond = torch.zeros_like(x)
return x.requires_grad_(True), y.requires_grad_(True), cond
def up(n=N1):
# 边界 u(x,1)=0
x = torch.rand(n, 1)
y = torch.ones_like(x)
cond = torch.zeros_like(x)
return x.requires_grad_(True), y.requires_grad_(True), cond
def left(n=N1):
# 边界 u(0,y)=0
y = torch.rand(n, 1)
x = torch.zeros_like(y)
cond = torch.zeros_like(y)
return x.requires_grad_(True), y.requires_grad_(True), cond
def right(n=N1):
# 边界 u(1,y)=0
y = torch.rand(n, 1)
x = torch.ones_like(y)
cond = torch.zeros_like(y)
return x.requires_grad_(True), y.requires_grad_(True), cond
def data_interior(n=N2):
# 内点
x = torch.rand(n, 1)
y = torch.rand(n, 1)
cond = torch.sin(torch.pi * x) * torch.sin(torch.pi * y)
return x.requires_grad_(True), y.requires_grad_(True), cond
ps:data_interior是解析解的真实值,不要带入到模型中(损失函数)训练哦,requires_grad_(True)是非常有必要的,不然会疯狂报错。
定义神经网络层,我在此定义了一个输入层(x和y输入),三个全连接隐藏层,一个输出层(u)
class MLP(torch.nn.Module):
def init(self):
super(MLP, self).init()
self.net = torch.nn.Sequential(
torch.nn.Linear(2, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 32),
torch.nn.Tanh(),
torch.nn.Linear(32, 1)
)
def forward(self, x):return self.net(x)建立损失函数,如同前文所述,损失函数的数量=偏微分方程+边界条件。只要把x,y导入到神经网络中后计算并且与前面设置的右边的值做2范数即可
Loss
loss = torch.nn.MSELoss()
递归求导
def gradients(u, x, order=1):
if order == 1:
return torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u),
create_graph=True,
only_inputs=True, )[0]
else:
return gradients(u, x, order=order-1)
以下4个损失是PDE损失
def l_interior(u):
pde
x, y, cond = interior()
uxy = u(torch.cat([x, y], dim=1))
return loss(-gradients(uxy, x, 2) - gradients(uxy, y, 2), cond)
def l_down(u):
# 损失函数L4
x, y, cond = down()
uxy = u(torch.cat([x, y], dim=1))
return loss(uxy, cond)
def l_up(u):
# 损失函数L5
x, y, cond = up()
uxy = u(torch.cat([x, y], dim=1))
return loss(uxy, cond)
def l_left(u):
# 损失函数L6
x, y, cond = left()
uxy = u(torch.cat([x, y], dim=1))
return loss(uxy, cond)
def l_right(u):
# 损失函数L7
x, y, cond = right()
uxy = u(torch.cat([x, y], dim=1))
return loss(uxy, cond)
构造数据损失
def l_data(u):
# 损失函数L8
x, y, cond = data_interior()
uxy = u(torch.cat([x, y], dim=1))
return loss(uxy, cond)
模型训练,这个就不多说了
Training
u = MLP()
opt = torch.optim.Adam(params=u.parameters())
初始化模型的参数,并将它们传入Adam函数构造出一个Adam优化器
这里可以通过设定 lr的数值来给定学习率
for i in range(epochs):
opt.zero_grad()
# 将这一轮的梯度清零,防止其影响下一轮的更新
l = l_interior(u) + l_up(u) + l_down(u) + l_left(u) + l_right(u)
l.backward()
# 反向计算出各参数的梯度
opt.step()
# 更新网络中的参数
if i % 100 == 0:
print(i)
结果对比(无可视化)
xc = torch.linspace(0, 1, h)
xm, ym = torch.meshgrid(xc, xc)
xx = xm.reshape(-1, 1)
yy = ym.reshape(-1, 1)
xy = torch.cat([xx, yy], dim=1)
u_pred = u(xy)
u_real = torch.sin(torch.pi * xx) * torch.sin(torch.pi * yy)
u_error = torch.abs(u_pred-u_real)
u_pred_fig = u_pred.reshape(h,h)
u_real_fig = u_real.reshape(h,h)
u_error_fig = u_error.reshape(h,h)
print("Max abs error is: ", float(torch.max(torch.abs(u_pred - torch.sin(torch.pi * xx) * torch.sin(torch.pi * yy)))))
可视化输出结果
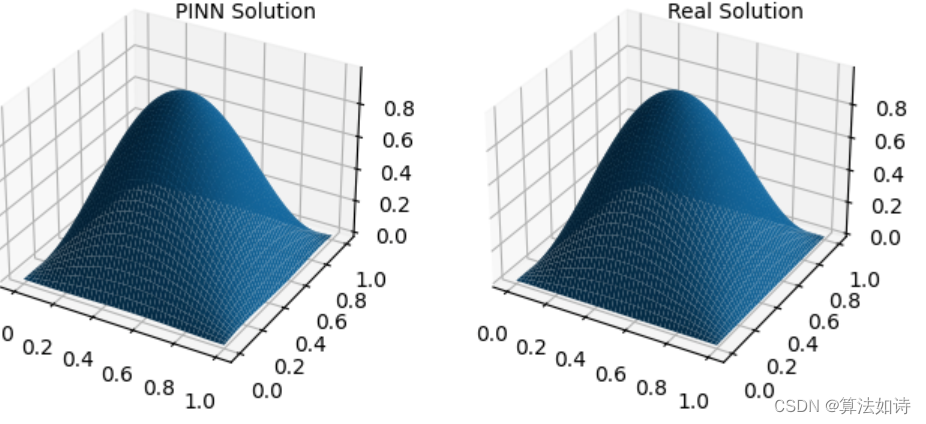
作PINN数值解图
fig = plt.figure(1, figsize=(12, 5)) # 调整图像大小
ax = fig.add_subplot(131, projection=‘3d’) # 使用子图
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_pred_fig.detach().numpy())
ax.text2D(0.5, 0.9, “PINN Solution”, transform=ax.transAxes)
作真实解图
ax = fig.add_subplot(132, projection=‘3d’) # 使用子图
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_real_fig.detach().numpy())
ax.text2D(0.5, 0.9, “Real Solution”, transform=ax.transAxes)
绘制误差图
fig = plt.figure(2, figsize=(8, 6)) # 调整误差图的大小
ax = fig.add_subplot(111, projection=‘3d’)
ax.plot_surface(xm.detach().numpy(), ym.detach().numpy(), u_error_fig.detach().numpy())
ax.text2D(0.5, 0.9, “Absolute Error”, transform=ax.transAxes)
plt.show()