前言
人声分离 是一项重要的音频处理技术,它可以将混合音频中的 人声和背景音乐 分离出来,为音频处理和后期制作提供了便利。
随着人声分离技术的发展,越来越多的开源工具被开发出来,为音频处理领域带来了新的发展机遇。小编之前也体验过不少人声分离 开源项目工具。分离效果有好的,有差的,参差不齐。
今天又逛到一块刚刚开源的人声分离工具 vocal-separate,看小样示例还不错,而且部署也比其他GPT产品简单些,还有编译好的Windows版工具可直接使用。
项目简介
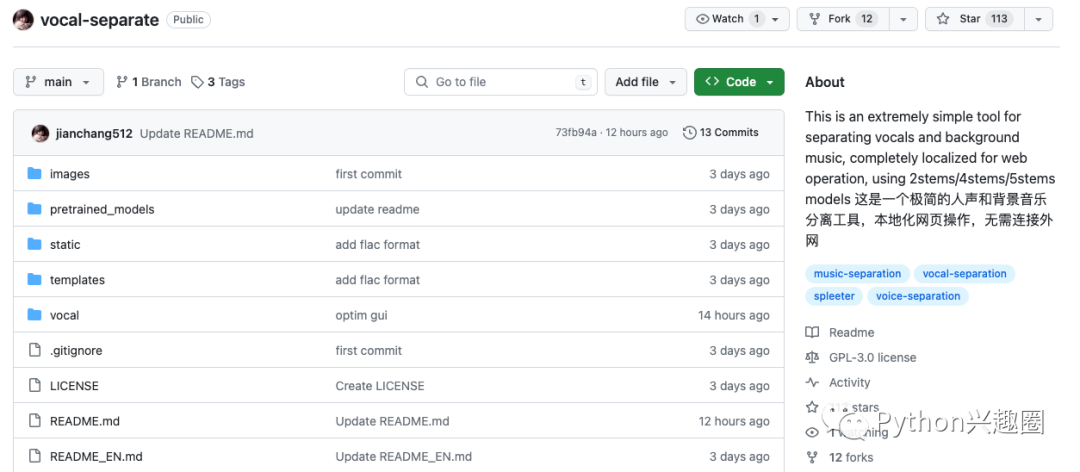
vocal-separate 是一款极简的人声和背景音乐分离工具。可直接本地网页化操作,无需连接外网,使用了 2stems/4stems/5stems 模型。
项目地址:https://github.com/jianchang512/vocal-separate
支持视频(mp4/mov/mkv/avi/mpeg)和音频(mp3/wav)格式。
使用方法
1、预编译Win版
- 直接在项目Release页面下载预编译文件

-
解压到本地某目录下,如:E:\vocal-separate
-
双击 start.exe ,等待自动打开浏览器窗口

- 点击页面中的上传区域,在弹窗中找到想分离的音视频文件,或直接拖拽音频文件到上传区域,然后点击“立即分离”,稍等片刻,底部会显示每个分离文件以及播放控件,点击播放。
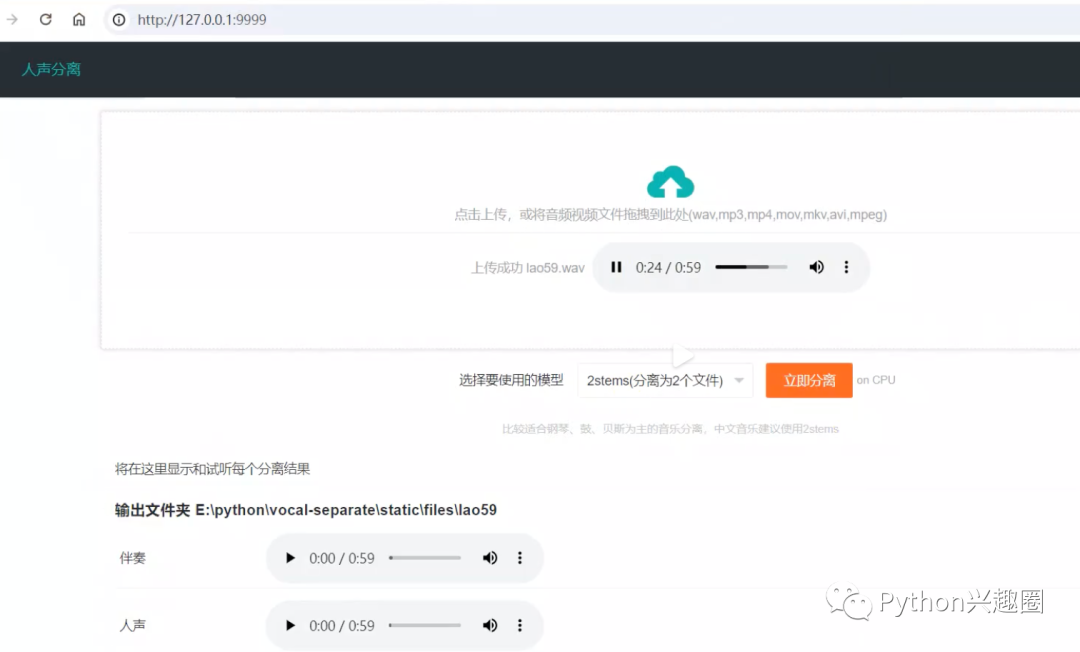
- 如果电脑拥有英伟达GPU,并正确配置了CUDA环境,将自动使用CUDA加速
2、源码部署(Linux/Mac/Window)
要求 python 3.9->3.11
1)拉取 vocal-separate 拉取源码到指定目录
git clone git@github.com:jianchang512/vocal-separate.git
2)创建Python虚拟环境(根据本地安装的虚拟env软件来)
3)激活环境
# win下命令
%cd%/venv/scripts/activate
# linux和Mac下命令
source ./venv/bin/activate
4)安装依赖
pip install -r requirements.txt
5)ffmpeg工具准备
win下解压 ffmpeg.7z,将其中的ffmpeg.exe和ffprobe.exe放在项目目录下
linux和mac 到 ffmpeg官网下载对应版本ffmpeg,解压其中的ffmpeg和ffprobe二进制程序放到项目根目录下
6)下载模型压缩包
在项目根目录下的 pretrained_models 文件夹中解压,解压后,pretrained_models中将有3个文件夹,分别是2stems/3stems/5stems
7)执行 python start.py ,等待自动打开本地浏览器窗口。
网页打开后,跟Win编译版使用方法一样。
具体使用详情
将一首歌曲或者含有背景音乐的音视频文件,拖拽到本地网页中,即可将其中的人声和音乐声分离为单独的音频wav文件,可选单独分离“钢琴声”、“贝斯声”、“鼓声”等。
自动调用本地浏览器打开本地网页,模型已内置,无需连接外网下载。
只需点两下鼠标,一选择音视频文件,二启动处理。
总结
作者将相关资源包,部署依赖都说的非常详细,直接根据步骤一步步安装即可。针对单独的音乐原声分离效果还是Ok的。如果是视频、影视、音乐等混合,可能还不是特别完美,还有优化的空间。