参考文章读写锁 - ARM汇编同步机制实例(四)_汇编 prefetchw-CSDN博客
读写锁允许多个执行流并发访问临界区。但是写访问是独占的。适用于读多写少的场景
另外好像有些还区分了读优先和写优先
读写锁定义
typedef struct {arch_rwlock_t raw_lock;
#ifdef CONFIG_GENERIC_LOCKBREAKunsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCKunsigned int magic, owner_cpu;void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOCstruct lockdep_map dep_map;
#endif
} rwlock_t;typedef struct {u32 lock;
} arch_rwlock_t;可以看到在arm上面读写锁其实就是一个u32的变量。通过这个变量的值能够知道读者和写者的情况。(arm上面有strex指令能够实现独占访问)
读加锁
read_lock->_raw_read_lock->__raw_read_lock->do_raw_read_lock->arch_read_lock
可以看到就是不断的用指令strex去改写这个值,直到修改成功。
读加锁简单的理解就是执行rw->lock++。
static inline void arch_read_lock(arch_rwlock_t *rw)
{unsigned long tmp, tmp2;
/* 指令strex https://blog.csdn.net/w906787/article/details/78907067 指令条件pl(非负)https://blog.csdn.net/m0_73649248/article/details/132796539rsb及常见指令 https://blog.csdn.net/Tong89_xi/article/details/103458289wfe https://blog.csdn.net/xy010902100449/article/details/126812552
*/prefetchw(&rw->lock);__asm__ __volatile__(
"1: ldrex %0, [%2]\n" // ldrex tmp, *(&rw->lock) 获取lock的值并保存在tmp中
" adds %0, %0, #1\n" // adds tmp, tmp, #1 tmp = tmp + 1 //难道是被当做一个有符号数看的,0x80000000其实是个负数??
" strexpl %1, %0, [%2]\n" // strexpl tmp2, tmp, *(&rw->lock) rw->lock = tmp, strex能独占访问,赋值成功tmp2会设置为0,反之为1WFE("mi") // wfemi (CPSR NZCV )负数就进入低功耗模式,睡眠//需要特定的事件触发才能被唤醒
" rsbpls %0, %1, #0\n" // rsbpls tmp, tmp2, #0 tmp = 0 - tmp2 运算结果会影响到cpsr寄存器。如果cpsr中N为1(感觉这里还是adds如果为负数),则执行减法,并且修改cpsr寄存器
" bmi 1b" // bmi 1b 如果strex执行成功 tmp = 0 - tmp2(0) = 0,为0 bmi不执行: "=&r" (tmp), "=&r" (tmp2): "r" (&rw->lock): "cc");smp_mb();
}之前一直不理解adds为什么会出现负数的情况。感觉确实是把相加的结果看做是有符号的,即如果加出来的值,最高位为1,cpsr的n就会被置为1
" adds %0, %0, #1\n" // adds tmp, tmp, #1 tmp = tmp + 1 //难道是被当做一个有符号数看的,0x80000000其实是个负数??
" strexpl %1, %0, [%2]\n" // strexpl tmp2, tmp, *(&rw->lock) rw->lock = tmp, strex能独占访问,赋值成功tmp2会设置为0,反之为1测试样例
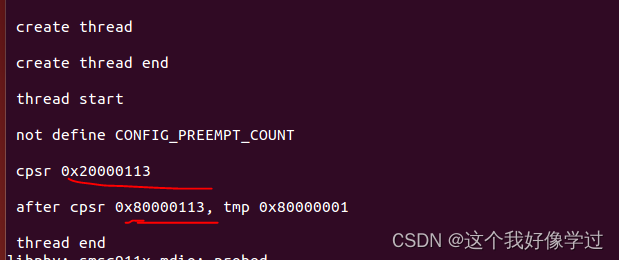
int test_thread(void* a)
{printk(KERN_EMERG "\r\n thread start\n");
#ifdef CONFIG_PREEMPT_COUNTprintk(KERN_EMERG "\r\n CONFIG_PREEMPT_COUNT\n");
#elseprintk(KERN_EMERG "\r\n not define CONFIG_PREEMPT_COUNT\n");
#endif unsigned int cpsr = 0;unsigned long tmp = 0;unsigned long tmp2 = 0x80000000;__asm__ __volatile__("mrs %0, cpsr\n" //rw->lock = 0;:: "r" (cpsr): "cc");printk(KERN_EMERG "\r\n cpsr 0x%lx\n", cpsr);__asm__ __volatile__("adds %0, %1, #1\n": "=&r" (tmp): "r" (tmp2): "cc");__asm__ __volatile__("mrs %0, cpsr\n" //rw->lock = 0;:: "r" (cpsr): "cc");printk(KERN_EMERG "\r\n after cpsr 0x%lx, tmp 0x%lx\n", cpsr, tmp);printk(KERN_EMERG "\r\n thread end\n");return 0;
}可以看到经过tmp = tmp2 + 1后cpsr的最高位(N)确实被置为了1
那结合后面写加锁,就能看到,如果有写者加了锁,读者是无法成功加锁的(strexpl 需要tmp非负才执行)。但是如果存在读者的情况下,其他读者继续尝试加锁是可以成功的。这样就运行多个读者进行临界区
读解锁
其实就是rw->lock--。最后需要注意的是如果tmp为0,即没有读者的时候,需要唤醒因为获取写锁失败的cpu(dsb_sev)
If the Event Register is not set, WFE(这个并不会让出cpu) suspends execution until
one ofthe following events occurs:1、an IRQ interrupt, unless masked by the CPSR I-bit
2、an FIQ interrupt, unless masked by the CPSR F-bit
3、an Imprecise Data abort, unless masked by the CPSR A-bit
4、a Debug Entry request, if Debug is enabled
5、an Event signaled by another processor using the SEV instruction.
————————————————
版权声明:本文为CSDN博主「狂奔的乌龟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xy010902100449/article/details/126812552
static inline void arch_read_unlock(arch_rwlock_t *rw)
{unsigned long tmp, tmp2;smp_mb();prefetchw(&rw->lock);__asm__ __volatile__(
"1: ldrex %0, [%2]\n" //tmp = rw->lock
" sub %0, %0, #1\n" //tmp = tmp - 1
" strex %1, %0, [%2]\n" //rw->lock = tmp
" teq %1, #0\n" //检查指令是否执行成功
" bne 1b": "=&r" (tmp), "=&r" (tmp2): "r" (&rw->lock): "cc");if (tmp == 0)dsb_sev();//唤醒获取锁失败的cpu(wfe需要sev事件唤醒)
}写加锁
write_lock->_raw_write_lock->__raw_write_lock->do_raw_write_lock
1、感觉这里是写者加锁,需要等待全部读者退出才行 。并且这个时候写者是没有加锁成功的(即lock的值没有成功赋值为0x80000000)。read_lock那里不会出现相加为负数的情况。读者一直能够加锁成功。即只有等到读者全部退出,才能加锁成功。如果在你尝试加锁的时候,后面又来了很多加读锁的情况,你也无法阻止。只能看着读锁加锁成功
2、rw->lock = 0x80000000
static inline void arch_write_lock(arch_rwlock_t *rw)
{unsigned long tmp;prefetchw(&rw->lock);__asm__ __volatile__(
"1: ldrex %0, [%1]\n" //tmp = rw->lock
" teq %0, #0\n" //tmp == 0,需要读者全部退出才行WFE("ne") //不为0休眠,等待特定事件发生后唤醒
" strexeq %0, %2, [%1]\n" // rw->lock = 0x80000000
" teq %0, #0\n" // %0保存strex执行结果,0表示成功, 1表示失败
" bne 1b" //执行失败,则重复上述流程: "=&r" (tmp): "r" (&rw->lock), "r" (0x80000000): "cc");smp_mb();
}写解锁
比较简单就是rw->lock = 0,然后唤醒其他获取锁失败的cpu
static inline void arch_write_unlock(arch_rwlock_t *rw)
{smp_mb();__asm__ __volatile__("str %1, [%0]\n" //rw->lock = 0;:: "r" (&rw->lock), "r" (0): "cc");dsb_sev();//这里估计是唤醒获取锁失败的cpu
}总结
(1)假设临界区内没有任何的thread,这时候任何read thread或者write thread可以进入,但是只能是其一。
(2)假设临界区内有一个read thread,这时候新来的read thread可以任意进入,但是write thread不可以进入
(3)假设临界区内有一个write thread,这时候任何的read thread或者write thread都不可以进入
(4)假设临界区内有一个或者多个read thread,write thread当然不可以进入临界区,但是该write thread也无法阻止后续read thread的进入,他要一直等到临界区一个read thread也没有的时候,才可以进入,多么可怜的write thread。
————————————————
版权声明:本文为CSDN博主「生活需要深度」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012294613/article/details/123905288