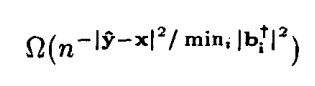数字图像处理练习题
文章目录
- 数字图像处理练习题
- 第 一 章
- 1.什么是数字图像?
- 2.数字图像有哪些特点?
- 3.数字图像处理的目的是什么?
- 4.简述数字图像的历史。
- 5.数字图像有哪些主要应用?
- 6.列举生活中数字图像的获得途径。
- 7.结合自己的生活实例,举出一个数字图像的应用实例
- 8.数字图像今后的发展方向是什么?
- 9.使用 OpenCV 显示一张图片。
- 第 二 章
- 1.什么是三基色?相加混色与相减混色的基色是否相同?
- 2.在图像处理中有哪几种常用的颜色模型?它们的应用对象是什么?
- 3.图像数字化过程中的失真有哪此原因?
- 4.一幅模拟彩色图像经数字化后,其分辨率为 1024X768 像素,若每像素用红,蓝三基色表示.三基色的灰度等级为 8,在无压缩的情况下,计算该图像占用的存储空间
- 5.编写程序,实现 RGB颜色空间模型与 HSV颜色空间模型的转换。
- 6.对于彩色图像,通常用于区分颜色的特性有哪些?
- 8.提出将像素宽度的8 通路转换为 4 通路的一种算法
- 10.对于点 p 和 q 间的D,举例等于这两点间最短 4 通路的情况,给出需要的条件,这个通路唯一吗?
- 第 三 章
- 1.为什么点运算不会改变图像内像素的空间位置关系?
- 2.非线性变换中指数变换的作用是什么?
- 3.请阐述分段线性变换的大致作用。
- 4.图像相加运算能消除图像的加性随机噪声吗?
- 5.请阐述图像与运算的应用场景
- 6.图像的几何运算满足交换律吗?
- 7.请列举图像的常见插值算法
- 8.图像变形的原理是什么?
- 第 四 章
- 1.什么是灰度直方图?它有哪些应用?
- 2.从灰度直方图能获得图像的哪些信息?
- 3.图像增强的目的是什么?它包含哪些内容?
- 4.直方图修正有哪两种方法?它们二者有何区别与联系?
- a. 线性直方图修正:
- b. 非线性直方图修正(直方图匹配):
- 区别与联系:
- 5.直方图规定化处理的技术难点是什么?如何解决?
- 技术难点:
- 解决方法:
- 6.灰度直方图的特性是什么?
- 7.直方图均衡化和直方图规格化的区别是什么?
- 直方图均衡化:
- 直方图规定化:
- 区别:
- 8.使用 OpenCV 编写代码,实现图像的直方图均衡化
- 9.使用 OpenCV 编写代码,实现图像的直方图对比。
- 10.使用 OpenCV 编写代码,实现图像的直方图反向投影
- 11.使用 OpenCV 编写代码,实现图像的直方图模板匹配
- 12.直方图近年来与什么技术相融合?具体有什么运用?
- 第 五 章
- 1.空间域滤波方法分为几类”每一类中包含哪些方法?
- 2.平滑空间滤波方法中,哪些方法是线性的?哪些方法是非线性的?
- 3.中值滤波的特点是什么”它主要用于消除什么类型的噪声?
- 4.试提出一种过程来求一个n x n 领域的中值。
- 5.最大值滤波器和最小值滤波器对图像的关注点分别是什么?
- 6.空间域滤波和频率域滤波对图像的滤波效果有何异同?
- 7.常用的图像锐化算子有哪几种?
- 8.高斯分布的标准差。在图像平滑中的影响是什么?
- 9.简述用于平滑和锐化处理的滤波器之间的联系和区别。
- 10.在给定的应用中,一个均值掩模被用于输人图像以减少噪声,然后再用一个拉普拉斯掩模增强图像中的小细节,如果交换这两个步骤,结果是否相同?
- 第 六 章
- 1.理想滤波器主要有哪些?它们各有什么特点?
- a. 理想低通滤波器:
- b. 理想高通滤波器:
- c. 理想带通滤波器:
- d. 理想带阻滤波器:
- 2.巴特沃斯滤波器分几类?它们各有什么特点
- a. 无限远通带巴特沃斯滤波器:
- b. 有限通带巴特沃斯滤波器:
- c. 无限远阻带巴特沃斯滤波器:
- d. 有限阻带巴特沃斯滤波器:
- 3.频率域中研究图像的原因有哪此?
- 4.简述低通滤波器。
- 5.判断题:频率域去噪声的技术流程就是先把图像从空间域变换到频率域,然后在频率域对噪声成分进行掩模滤波,抑制或者消除噪声,最后再把图像从频率域逆变换到空间域。
- 6.下列对频率域图像增强法描述正确的是(A)
- 7.傅里叶变换是图像处理中一种有效而重要的方法,应用十分广泛。下列选项中属于傅里叶变换的是(C)
- 8.关于傅里叶变换的描述,正确的是(C)
- 9.不属于在频率域中研究图像的原因是(A)
- 10.高通滤波后的图像通常较暗,为改善这种情况,将高通滤波器的转移函数加上一常数量以便引入一些低频分量,这样的滤波器叫(B)。
- 第 七 章
- 1._**腐蚀**__是一种消除连通域的边界点,使边界向内收缩的处理。
- 2.__**膨胀**_是将与目标区城的背景点合并到该目标物中,使目标物边界向外部扩张的处理。
- 3.对一幅不全为背景的图像反复膨胀或腐蚀,分别会产生什么样的效果?(假设结构元不为单像素点)
- 5.开运算相比腐蚀运算的优点是什么?
- 6.闭运算相比膨胀运算的优点是什么?
- 7.简述灰度图像使用形态学梯度处理后可以生成对象轮廓的原因。
- 8.灰度图像形态学梯度处理有无类似二值图像边界提取的多种操作?如果有,则通过代码实现,并观察提取到的边界有什么区别。
- 9.简述灰度图像使用顶帽变换后可以消除不均匀的光照背景影响的原因。
- 10.编程实现二值图像的连通分量提取算法(可调用书中已展示的代码,下同)
- 11.编程实现灰度图像的开运算算法。
- 12.编程实现灰度图像形态学平滑算法
- 13.编程实现灰度图像形态学梯度。
- 14.编程实现灰度图像形态学顶帽变换.
- 第 八 章
- 1.举例说明分割在图像处理中的实际应用。
- 2.取一幅二值图像作为输入,试使用不同的阀值对图像进行阀值分割,观察不同的闽值对图像分割处理的结果有何不同。
- 3.在灰度阀值分割中如何选择合适的阙值? 用 C++ 语言编写出相应的程序。
- 4.采用霍夫变换检测直线时,为什么不采用 y=ax 的直角坐标表达形式?
- 5.证明: 在极坐标系中的霍夫变换将图像空间 XY 的共线点映射为p 平面上的正弦曲线并交汇于一点。
- 6.采用区域生长法进行图像分割时,可采用哪些生长准则? 观察图 8-14(a),更换初始生长点和生长准则,绘制出新的区域生长结果图。
- 7.用区域分裂-生长法分割图 8-26 所示的图像,并给出分割过程图。
- 8.分水岭算法的主要缺点是什么?如何克服?
- 9.若运动图像帧与帧之间没有配准好,对图像差分法会有什么影响?
- 10.试列举光流不等于运动流的情况。
- 第 九 章
- 1.图像特征检测与匹配过程对于完成图像处理及分析任务具有重要意义,请谈谈你对这句话的理解。
- 2.常见的图像特征有哪些种类? 请举例说明它们各自的特点。
- 3.什么是角点?常见的角点检测方法有哪些? 与特征点相比,角点有什么劣势
- 4.基于特征点的图像匹配策略分为哪几个步骤?
- 5.本章一共介绍了多少种特征点?它们分别是哪些特征点? 除本章介绍的特征点外,还能找到哪些其他的特征点?
- 6.简述 SIFT、SURF、ORB 算法的原理,对比它们之间的性能并评价。
- 7.设计程序,检测你感兴趣的不同种类的特征点,并统计在图像中提取到的特征占数量,观察这一过程在你机器上所用的时间。
- 8.我们发现 ORB 特征点在图像中分布不够均匀,你是否能够找到或提出一种 ORB特征均匀提取策略?
- 9.除本章介绍的基于计算特征向量欧几里得距离的匹配算法,你还能找到哪些其他的匹配算法?快速近似近邻算法(FLANN)是一种常用的匹配方法,研究 FLANN 为何能够快速处理匹配问题? 除 FLANN 外,还有哪些方法可以加速匹配的手段?
- 10.在特征点匹配的过程中,难免存在误匹配的问题,如果保留了这些错误匹配,会对后续工作(如三维重建、目标识别、运动跟踪)产生什么影响? 你还能想到哪些避免误匹配的方法?
本习题来自高飞的数字图像处理教程,仅供参考!
第 一 章
1.什么是数字图像?
数字图像是由离散的像素点组成的图像,每个像素点都具有特定的位置和色彩信息。这些像素点按照一定的排列方式构成图像,而图像则可以通过在空间中的不同位置和颜色来表示视觉信息。数字图像通常由数字矩阵表示,其中每个元素对应于图像中的一个像素,其值表示该像素的亮度或颜色信息。这样的表示方式使得图像可以被计算机处理、存储和传输。
2.数字图像有哪些特点?
数字图像具有一些显著的特点,其中一些主要特点包括:
-
离散性: 数字图像是由离散的像素组成的,每个像素具有特定的位置和数值。这与连续性的模拟图像形成鲜明对比。
-
有限性: 数字图像的尺寸是有限的,由像素的数量和分辨率决定。这在计算机视觉和图像处理中是一个重要的概念。
-
分辨率: 分辨率表示单位面积内像素的数量,影响图像的清晰度和细节程度。高分辨率图像包含更多的像素,因此能够呈现更多的细节。
-
颜色深度: 表示每个像素颜色的位数,决定了图像的色彩表现能力。常见的颜色深度包括8位(256色)、24位(真彩色)等。
-
格式: 数字图像可以以不同的格式存储,如JPEG、PNG、BMP等。每种格式都有其优点和适用场景。
-
可编程性: 由于数字图像以矩阵形式表示,因此可以通过编程来进行各种图像处理操作,如滤波、变换、增强等。
-
易于存储和传输: 数字图像可以通过数字方式存储在计算机中,也可以通过网络进行传输。这使得图像的存储、共享和传递变得更加便捷。
-
可压缩性: 数字图像通常可以通过压缩算法减小文件大小,而仍然保持较高的图像质量。
这些特点使得数字图像在计算机科学、计算机视觉和图像处理等领域得到广泛应用。
3.数字图像处理的目的是什么?
数字图像处理的主要目的是通过对图像进行一系列的计算机算法和技术的处理,以改变图像的特性、提取信息、改善图像质量、进行分析、识别对象或实现其他特定的目标。以下是数字图像处理的一些主要目的:
-
增强图像质量: 调整图像的亮度、对比度、锐度等,以改善图像的视觉品质。
-
去噪和降低失真: 使用滤波和去噪算法来降低图像中的噪声和失真。
-
图像压缩: 减小图像文件的大小,以便更方便地存储和传输。
-
特征提取: 通过算法提取图像中的特定信息,如边缘、纹理、形状等。
-
目标识别和检测: 识别图像中的特定对象、物体或模式,常用于计算机视觉应用。
-
图像分割: 将图像分成不同的区域,以便更容易处理或分析各个部分。
-
颜色空间转换: 在不同的颜色表示之间进行转换,如RGB到HSV的转换。
-
图像合成: 将多个图像合成为一个图像,或者通过图像合成生成新的图像。
-
医学图像处理: 在医学领域,用于诊断、治疗和研究,如CT扫描、MRI等图像的分析和处理。
-
图像分析: 进行图像统计、模式识别等分析,提取有关图像内容的信息。
-
虚拟现实和计算机图形学: 用于创建逼真的图像,支持虚拟现实、计算机游戏等应用。
总的来说,数字图像处理的目的是通过使用计算机算法和技术来改善、分析、理解和操作图像,以满足特定的应用需求。
4.简述数字图像的历史。
数字图像的历史可以追溯到20世纪中叶。以下是数字图像发展的一些关键阶段:
-
1950s-1960s: 早期数字图像处理主要集中在军事和科学研究领域。在这个时期,计算机的出现为数字图像处理奠定了基础。早期的计算机用于处理雷达图像和卫星图像等。
-
1970s: 随着计算机技术的发展,数字图像处理开始进入工业和医学领域。计算机图形学、图像分析和模式识别等领域开始崭露头角。
-
1980s: 个人计算机的兴起和图像传感器技术的改进推动了数字图像处理的普及。图像处理软件的开发和商业化促使数字图像处理技术在广泛的应用领域得以推广。
-
1990s: 数字相机的商业化推动了数字图像的普及,使得普通消费者也能够轻松拍摄和处理数字图像。同时,互联网的兴起促进了数字图像的在线共享和传播。
-
2000s: 高分辨率数字图像、计算机视觉技术和深度学习的发展推动了数字图像处理的创新。图像处理应用进一步扩展,包括医学成像、人脸识别、虚拟现实等领域。
-
2010s-2020s: 深度学习的崛起带来了图像识别和分类等任务的革命性变化。神经网络和卷积神经网络(CNN)等技术在图像处理中取得显著成果。同时,云计算和大数据技术的发展为处理大规模图像数据提供了支持。
总体而言,数字图像处理的发展经历了从军事和科研领域到广泛应用于工业、医学、娱乐和社交等多个领域的过程。随着技术的不断进步,数字图像处理在日常生活和各个行业中发挥着越来越重要的作用。
5.数字图像有哪些主要应用?
数字图像在各个领域有广泛的应用,以下是一些主要的应用领域:
-
医学影像处理: 医学图像处理用于医学影像的获取、分析和诊断,包括X射线、CT扫描、MRI等。它帮助医生进行疾病诊断和治疗规划。
-
计算机视觉: 用于图像识别、物体检测、人脸识别等。计算机视觉在自动驾驶、安防监控、工业生产等方面有着重要应用。
-
图像处理软件: 包括图像编辑软件(如Photoshop)、图像浏览器和管理工具等,用于图像的处理、编辑和组织。
-
遥感图像处理: 用于处理卫星图像、空中摄影图像,支持地理信息系统(GIS)和环境监测等应用。
-
数字摄影: 数字相机的兴起使得数字图像在摄影领域得到广泛应用。摄影师可以使用数字技术进行后期处理和编辑。
-
虚拟现实和游戏开发: 用于创建逼真的虚拟场景,支持虚拟现实(VR)和增强现实(AR)技术,以及计算机游戏的开发。
-
娱乐和多媒体: 包括电影、电视、广告等领域,数字图像处理用于特效制作、视频编辑、动画制作等。
-
艺术和设计: 数字图像处理在艺术创作、平面设计、广告设计等领域中被广泛应用。
-
自动化和工业应用: 在工业生产中,数字图像处理用于质量控制、产品检测和自动化生产线中的视觉检测。
-
教育和研究: 用于教学、研究和实验,包括数字图像处理课程、实验室和科研项目。
-
社交媒体和在线共享: 用户通过社交媒体平台共享和传播数字图像,包括照片、图形和表情等。
这些只是数字图像处理应用领域的一部分,随着技术的不断进步,数字图像处理在更多领域发挥着越来越重要的作用。
6.列举生活中数字图像的获得途径。
在日常生活中,我们可以通过多种途径获取数字图像。以下是一些常见的数字图像获取途径:
-
数码相机和智能手机: 数码相机和智能手机是最常见的数字图像获取工具。人们使用相机和手机拍摄照片,从而产生数字图像。
-
摄像机和摄像机录像: 摄像机用于录制视频,而视频可以通过截取帧来生成一系列数字图像。
-
扫描仪: 扫描仪用于将纸质文件、照片或绘画等物理媒介转换为数字图像。这在文档数字化和图像存档中很常见。
-
卫星和航空遥感: 卫星和航空器上搭载的传感器可以获取地球表面的高分辨率卫星图像,用于地理信息系统、环境监测等应用。
-
医学成像设备: 医学设备如X射线机、CT扫描仪、MRI等产生医学图像,这些图像用于诊断和治疗。
-
无人机: 无人机配备的相机可以用于航拍和地理勘测,生成高分辨率的数字地图和图像。
-
摄像监控系统: 安防摄像头和监控系统用于实时监测和记录场所的活动,生成数字图像作为证据。
-
社交媒体平台: 在社交媒体上,用户通过上传照片、图像或视频来分享他们的生活和经验,这些图像随后被转化为数字形式。
-
传感器技术: 各种传感器,如温度传感器、湿度传感器、光传感器等,可以生成数字图像来反映不同的环境参数。
-
计算机生成图像: 通过计算机生成的图形、动画和虚拟场景也是数字图像的一种来源。
这些途径展示了数字图像在我们日常生活中的广泛应用,以及各种设备和技术是如何产生和获取数字图像的。
7.结合自己的生活实例,举出一个数字图像的应用实例
假设我是一位摄影爱好者,以下是一个基于我的生活实例的数字图像的应用实例:
实例:数字图像在摄影爱好中的应用
作为一位摄影爱好者,我经常使用数码相机或智能手机拍摄照片。这些照片可以通过不同的数字图像处理方式得到优化和改进。以下是一些应用实例:
-
图像编辑软件: 使用图像编辑软件,比如Adobe Photoshop或Lightroom,对拍摄的照片进行后期处理。我可以调整亮度、对比度、色调和饱和度,以优化图像的视觉效果。
-
滤镜和效果: 应用各种滤镜和特效,如黑白滤镜、模糊效果或艺术滤镜,以赋予照片不同的风格和情感。
-
修复和去除瑕疵: 使用修复工具去除照片中的不良元素,比如杂物、瑕疵或不需要的对象,以提高照片的整体质量。
-
HDR(高动态范围)合成: 在场景中存在明暗差异较大时,通过HDR合成多张曝光不同的照片,以保留更多细节和提升照片的动态范围。
-
全景照片: 利用全景拍摄功能或后期全景合成,创建宽广的全景照片,捕捉更多的场景和细节。
-
社交媒体分享: 将优化过的照片分享到社交媒体平台,与朋友和家人交流分享生活中的美好瞬间。
这个实例突显了数字图像处理在摄影领域的广泛应用,通过利用各种工具和技术,我可以提高照片的质量、表达个人风格,并分享精彩的摄影作品。这种数字图像处理的应用不仅仅在专业摄影师中常见,也在普通摄影爱好者的日常生活中起到了重要作用。
8.数字图像今后的发展方向是什么?
数字图像领域在未来将继续发展,可能涉及以下一些方向:
-
深度学习和人工智能: 深度学习技术的发展将在数字图像处理中发挥重要作用,包括图像识别、目标检测、语义分割等。人工智能的引入有望提高图像处理系统的智能性和自适应性。
-
计算机视觉的进一步集成: 计算机视觉技术将与数字图像处理更加深度地融合,应用领域可能包括自动驾驶、智能监控、人机交互等。
-
增强现实和虚拟现实: 数字图像在增强现实(AR)和虚拟现实(VR)中的应用将进一步扩展。更逼真的虚拟环境和与真实世界的融合将成为发展趋势。
-
更先进的图像传感器技术: 高分辨率、低噪声、更灵敏的图像传感器将推动数字图像质量的提升。新型传感器技术可能包括量子传感器等。
-
实时图像处理: 针对实时应用的需求,数字图像处理算法将更加注重效率和速度。这对于自动驾驶、视频流处理等领域尤为重要。
-
多模态图像处理: 结合多种传感器和信息源,进行多模态数据的融合与处理,以获得更全面、准确的图像信息。
-
图像安全和隐私: 随着图像处理技术的普及,图像的安全和隐私问题也变得更为突出。未来的发展可能包括更安全的图像传输和存储方式,以及更高级的图像加密和隐私保护技术。
-
可解释性和可控性: 针对深度学习模型的不透明性,研究人员将致力于提高算法的可解释性,以便更好地理解和控制数字图像处理的结果。
总体而言,数字图像处理领域将在技术和应用层面继续迎来创新,推动着计算机视觉、人工智能和其他领域的发展。这些趋势将有助于数字图像在更广泛的行业和日常生活中发挥更大的作用。
9.使用 OpenCV 显示一张图片。
在Python中使用OpenCV显示一张图片非常简单。
import cv2# 读取图片
image_path = "path/to/your/image.jpg" # 请将路径替换为你图片的实际路径
image = cv2.imread(image_path)# 显示图片
cv2.imshow("Image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
第 二 章
1.什么是三基色?相加混色与相减混色的基色是否相同?
三基色是指三种色彩,通过它们的不同组合可以产生所有其他颜色。这三种基色是红色、绿色和蓝色,通常缩写为RGB(Red, Green, Blue)。在彩色显示技术中,这三种基色是通过不同强度的光来发出的,它们的组合可以产生各种颜色。
相加混色和相减混色是两种不同的颜色混合方式,它们使用的基色是不同的。
-
相加混色(加色法): 这是光的混合方式,通过将不同颜色的光叠加在一起,产生新的颜色。在相加混色中,三基色是红、绿、蓝,简称RGB。通过调节这三种颜色的光强度,可以形成各种其他颜色。电视屏幕和计算机显示器就是使用相加混色的原理来显示图像的。
-
相减混色(减色法): 这是颜料的混合方式,通过将不同颜色的颜料混合在一起,产生新的颜色。在相减混色中,基色是青色、品红色和黄色,简称CMY。这是因为颜料混合时,它们吸收而不是发光。打印机和印刷行业通常使用相减混色的原理。
总的来说,相加混色和相减混色使用的基色是不同的。相加混色使用的是红、绿、蓝(RGB),而相减混色使用的是青、品红、黄(CMY)。这是因为它们分别应用于光的和颜料的颜色混合。
2.在图像处理中有哪几种常用的颜色模型?它们的应用对象是什么?
在图像处理中,有几种常用的颜色模型,每种模型都有其特定的应用对象。以下是其中一些常见的颜色模型:
-
RGB 模型(红绿蓝模型):
- 应用对象: 主要用于显示器、电视屏幕、数码相机等设备。在RGB模型中,颜色是通过红色(R)、绿色(G)、蓝色(B)三种基本颜色的组合来表示的。这是一种相加混色模型,其中不同强度的三种颜色叠加在一起形成其他颜色。
-
CMY 模型(青品红黄模型):
- 应用对象: 主要用于印刷和打印领域。CMY模型是一种相减混色模型,它使用青色(C)、品红色(M)、黄色(Y)三种颜色的组合来表示其他颜色。这是因为在印刷过程中,颜料叠加的方式是通过减少反射光的某种波长来产生颜色。
-
HSV 模型(色相、饱和度、明度模型):
- 应用对象: 主要用于图像处理和计算机图形学。HSV模型将颜色表示为色相(Hue)、饱和度(Saturation)、明度(Value)三个分量。这种模型更符合人类对颜色的感知,使得调整颜色更为直观。
-
YUV 模型:
- 应用对象: 主要用于视频压缩和传输。YUV模型将颜色分为亮度(Y)和两个色度(U、V)分量。这种分离亮度和色度的方式有助于视频编码中对亮度和颜色信息的独立处理,从而实现更高效的压缩。
-
LAB 模型(CIE Lab 模型):
- 应用对象: 主要用于颜色空间的标准化和色彩匹配。LAB模型是基于人眼对颜色的感知设计的,包括亮度(L)和两个色度(a、b)分量。它不依赖于特定的设备或显示器,因此在图像处理和计算机视觉中常用于颜色校正和比较。
这些颜色模型在不同的应用场景中有各自的优势,选择合适的模型取决于具体的图像处理任务和需求。
3.图像数字化过程中的失真有哪此原因?
图像数字化过程中可能出现各种失真,这些失真可能来自多个原因。以下是一些主要的原因:
-
采样失真: 采样是将连续的图像转换为离散的像素值的过程。过低的采样率可能导致细节丢失,造成锯齿状边缘效应,这就是所谓的走样(aliasing)。
-
量化失真: 量化是将连续的亮度值映射到离散的数字值的过程。当位深度较低时,即使用较少的比特数表示每个像素的亮度,就会发生量化失真。这导致图像的灰度级别减少,出现块状效应或灰度跳跃。
-
压缩失真: 图像压缩是为了减小图像文件的大小,但压缩通常会引入一定的失真。有损压缩方法,如JPEG,通过去除图像中的某些细节以减小文件大小,但这可能导致图像细节的丢失。无损压缩方法,如PNG,能够保留图像完整性,但文件大小可能不如有损压缩小。
-
颜色失真: 在颜色表示的过程中,可能会出现颜色空间的转换误差,导致颜色的不准确表示。这在图像处理和显示的过程中可能发生。
-
运动模糊和模糊失真: 如果图像中存在运动,相机移动或目标移动可能导致图像模糊。此外,图像采集设备的光学特性或图像传感器的性能也可能引入模糊失真。
-
噪声: 在图像采集和传输过程中,可能会引入各种类型的噪声,如电子噪声、量化噪声等。这些噪声会降低图像质量。
-
几何失真: 在图像采集过程中,可能发生透视失真、径向畸变等几何失真,使得图像中的对象形状变得不准确。
-
照明条件: 不同的照明条件会影响图像的亮度和对比度,从而导致颜色和细节的失真。
这些失真因素通常是数字图像处理中需要考虑和处理的问题,以提高图像质量和准确性。
4.一幅模拟彩色图像经数字化后,其分辨率为 1024X768 像素,若每像素用红,蓝三基色表示.三基色的灰度等级为 8,在无压缩的情况下,计算该图像占用的存储空间

5.编写程序,实现 RGB颜色空间模型与 HSV颜色空间模型的转换。
RGB(红绿蓝)颜色空间与HSV(色相、饱和度、明度)颜色空间之间的转换涉及一些数学运算。以下是一个简单的Python程序示例,用于实现RGB到HSV和HSV到RGB的转换。请注意,这只是一个基本的示例,实际实现可能会根据特定的需求进行调整。
import colorsysdef rgb_to_hsv(r, g, b):# 将RGB值归一化到[0, 1]范围r, g, b = r / 255.0, g / 255.0, b / 255.0# 使用colorsys.rgb_to_hsv进行转换h, s, v = colorsys.rgb_to_hsv(r, g, b)# 将h值从[0, 1]转换回[0, 360]h *= 360return h, s, vdef hsv_to_rgb(h, s, v):# 将h值从[0, 360]转换回[0, 1]h /= 360# 使用colorsys.hsv_to_rgb进行转换r, g, b = colorsys.hsv_to_rgb(h, s, v)# 将RGB值从[0, 1]转换回[0, 255]r, g, b = int(r * 255), int(g * 255), int(b * 255)return r, g, b# 示例:RGB到HSV
rgb_color = (255, 0, 0) # 红色
hsv_color = rgb_to_hsv(*rgb_color)
print(f"RGB: {rgb_color} -> HSV: {hsv_color}")# 示例:HSV到RGB
hsv_color = (0, 1, 1) # 红色
rgb_color = hsv_to_rgb(*hsv_color)
print(f"HSV: {hsv_color} -> RGB: {rgb_color}")
这个程序使用Python内置的colorsys库来执行RGB到HSV和HSV到RGB的转换。请注意,colorsys库中的rgb_to_hsv和hsv_to_rgb函数期望的输入和输出值范围是[0, 1],因此在进行转换之前需要将RGB值归一化到[0, 1]范围,然后再将其转换回[0, 255]范围。
6.对于彩色图像,通常用于区分颜色的特性有哪些?
彩色图像中用于区分颜色的特性主要包括以下几个方面:
-
色相(Hue): 色相是指颜色在色谱上的位置,即它是红、绿、蓝等颜色的具体类型。色相是通过光的波长来描述的,例如,红色对应较长的波长,蓝色对应较短的波长。
-
饱和度(Saturation): 饱和度表示颜色的纯度或强度,即颜色的强烈程度。高饱和度表示颜色更加鲜艳,而低饱和度则表示颜色较为淡雅。无饱和度的颜色是灰色。
-
明度(Value/Brightness): 明度是颜色的亮度或明暗程度。较高的明度表示颜色更亮,而较低的明度表示颜色更暗。在HSV颜色空间中,明度指的是颜色的亮度。
-
色调(Tone): 色调是颜色的相对深浅程度,它与明度的概念相似。较高的色调表示颜色更深,而较低的色调表示颜色更浅。
-
对比度(Contrast): 对比度是图像中颜色之间差异的度量。高对比度意味着颜色之间的差异更为显著,而低对比度则表示颜色之间的差异较小。
-
色温(Color Temperature): 色温描述了光源的颜色,通常用来表示白色光的冷暖程度。较高的色温会使颜色呈现蓝色调,而较低的色温则会呈现黄色调。
-
亮度对比度(Luminance Contrast): 亮度对比度描述了图像中不同区域之间亮度的差异。这在黑白图像中尤为重要,但对于彩色图像,颜色的亮度也会影响亮度对比度。
这些特性在彩色图像处理、计算机视觉和图形设计中都具有重要意义,因为它们决定了人眼对图像的感知和理解方式。
8.提出将像素宽度的8 通路转换为 4 通路的一种算法
将像素宽度的8通路转换为4通路的算法通常涉及颜色信息的降维,从而减少通路数。以下是一种简单的算法示例,可以将每个像素的8通路(比如RGBA)转换为4通路(比如RGB):
def convert_8_to_4_channels(pixel_data):# 假设pixel_data是一个包含RGBA通路的元组或列表if len(pixel_data) != 4:raise ValueError("输入像素数据的通路数不是8。")# 从8通路中提取RGB通路r, g, b, _ = pixel_data# 计算新的RGB值new_r = int((r + g) / 2) # 可根据需要调整权重new_g = int((g + b) / 2)new_b = int((b + r) / 2)# 返回新的4通路像素数据return new_r, new_g, new_b
这个示例算法是简单地将原始8通路中的三个相邻通路的值取平均,然后将这个平均值用于形成新的4通路像素。这是一个基础的示例,实际应用中可能需要更复杂的算法,具体取决于要保留的颜色信息和通路的权重。这个例子中,为了演示目的,我们只是将相邻通路的值取平均。
请注意,这种转换会损失信息,因为从8通路到4通路的转换涉及到信息的减少。在实际应用中,您可能需要根据特定的需求和应用场景来选择更适合的转换算法。
10.对于点 p 和 q 间的D,举例等于这两点间最短 4 通路的情况,给出需要的条件,这个通路唯一吗?

第 三 章
1.为什么点运算不会改变图像内像素的空间位置关系?
点运算是一种图像处理中的基本操作,它通过对图像的每个像素点进行相同的操作,而不考虑像素的空间位置,来实现图像的变换。这种操作不会改变像素的空间位置关系的原因主要有两点:
-
独立性: 点运算的操作是对图像中的每个像素点独立进行的,每个像素点的处理都只依赖于其本身的值,而不受周围像素的影响。这种独立性保证了图像中每个像素点的处理都是相互独立的,不受空间位置关系的影响。
-
操作函数的输入输出关系: 点运算的数学表达通常可以表示为
output_pixel = function(input_pixel),其中input_pixel是输入像素值,function是对应的操作函数,output_pixel是输出像素值。这个表达式表明输出像素只与输入像素的值有关,而与其在图像中的位置无关。因此,对于相同的输入像素值,无论它们在图像中的位置如何,通过相同的操作函数,都会得到相同的输出像素值。
举个简单的例子,如果我们对一幅图像进行灰度调整,将每个像素的亮度值都乘以一个相同的系数,这个操作是独立应用于每个像素的,而不考虑其周围像素。这就是点运算的基本思想,它保持了图像中像素之间的空间关系,不对图像的结构和形状进行变换。
2.非线性变换中指数变换的作用是什么?
在数字图像处理中,非线性变换中的指数变换是一种常见的操作,也称为伽马校正或伽马调整。指数变换通过对图像的每个像素进行指数运算,调整像素的灰度值,其作用主要有两方面:
-
灰度值的调整: 指数变换可以对图像的灰度值进行非线性调整。通过指定一个伽马值(γ),对每个像素的灰度值进行变换。这个变换公式通常表示为
output_pixel = input_pixel^γ,其中input_pixel是输入像素值,output_pixel是输出像素值。当 γ 大于1时,会增强较低灰度级的细节,而 γ 小于1时则增强高灰度级的细节。这样的调整对于图像的对比度和亮度具有显著的影响。 -
显示设备的适应性: 伽马校正还用于使图像更适应于人眼对亮度的感知。人眼对亮度的感知并非线性,而是近似于对数关系。因此,通过应用伽马校正,可以使图像在显示设备上更符合人眼的感知,提高图像的视觉质量。
在实际应用中,伽马校正经常用于矫正由于显示设备、摄像机或光照条件引起的图像的亮度和对比度问题。同时,它也是图像处理中一种常见的预处理手段,为后续的图像分析和计算提供更好的条件。
3.请阐述分段线性变换的大致作用。
分段线性变换是一种图像灰度变换的方法,它将图像的不同灰度级别划分为若干个段,对每个段分别进行线性变换。这样的处理方式可以在不同的灰度范围内施加不同的变换,从而实现对图像的定制调整。分段线性变换的大致作用如下:
-
对比度调整: 通过设置不同的斜率(变换的斜率)来调整不同灰度范围内的对比度。对于斜率较大的段,对比度增强,而对于斜率较小的段,对比度降低。
-
亮度调整: 通过设置不同段的截距(变换的截距)来调整不同灰度范围内的亮度水平。截距的增减将导致整个图像在亮度上的整体调整。
-
增强特定灰度范围: 可以选择性地增强或减弱特定灰度范围内的细节或特征。例如,可以通过提高高灰度值段的斜率来增强亮部细节,或通过降低低灰度值段的斜率来增强暗部细节。
-
动态范围压缩和扩展: 分段线性变换也可以用于压缩或扩展图像的动态范围。通过调整不同段的斜率和截距,可以限制图像中灰度的范围,使得灰度值更集中或更分散。
-
定制图像外观: 分段线性变换允许根据特定需求对图像的不同部分进行不同的调整,以满足特定的视觉效果或分析要求。
总的来说,分段线性变换为图像处理提供了更灵活的方式,可以有选择性地对不同的灰度范围进行调整,以实现对比度、亮度和动态范围等方面的个性化优化。
4.图像相加运算能消除图像的加性随机噪声吗?
图像相加运算一般不能完全消除图像的加性随机噪声。事实上,简单地对图像进行相加操作可能会将噪声累积,并导致更明显的问题。加性随机噪声通常是由于传感器的不完美性、电磁干扰或其他环境因素引起的。
加性随机噪声的产生通常表现为在图像的每个像素上添加一些随机值。假设我们有两个图像A和B,它们分别受到加性随机噪声的影响,表示为Na和Nb。如果我们简单地对这两个图像进行相加(A + B),噪声也会相加(Na + Nb)。这意味着在相加的结果中,噪声将成为更大的问题,而不是被消除。
要有效地减少加性随机噪声,通常采用图像处理中的其他技术,例如:
-
平均法: 通过对多幅具有相同内容的图像进行平均,可以在一定程度上减少随机噪声。这种方法假设噪声是随机的,而信号是稳定的。
-
滤波器: 使用适当的滤波器,如中值滤波、高斯滤波等,可以在图像中降低噪声的影响。
-
频域滤波: 使用傅里叶变换等频域方法,可以在频域中去除或减少噪声的影响。
-
图像增强: 一些图像增强方法,如小波变换,可以在保留图像细节的同时降低噪声。
总之,简单的图像相加操作并不是消除加性随机噪声的有效方法,而需要采用更复杂的图像处理技术。选择适当的方法取决于噪声的性质和对图像的特定需求。
5.请阐述图像与运算的应用场景
图像与运算是一种逐像素的操作,它对两个输入图像的每个对应像素执行逻辑运算。这种操作在许多图像处理和计算机视觉的应用场景中都有用途。以下是一些图像与运算的常见应用场景:
-
图像融合(Image Fusion): 图像与运算可用于融合两个或多个图像,生成一个新的图像。通过逻辑运算,可以选择性地保留两幅图像中的某些部分,例如通过使用逻辑与运算实现遮罩效果。
-
目标检测和分割: 在计算机视觉中,图像与运算经常用于目标检测和分割任务。通过与运算,可以提取两幅图像中相同区域的信息,从而检测出共同存在的目标。
-
图像增强: 图像与运算可用于增强图像的特定部分。通过逻辑运算,可以突出显示感兴趣区域或将图像中的某些特征突出显示。
-
图像蒙版(Image Masking): 图像与运算常用于生成蒙版。通过与运算,可以将一个图像的特定区域与另一个图像中的对应区域进行相交,从而创建一个蒙版,用于控制图像的可见性。
-
图像编辑: 图像与运算在图像编辑中有广泛应用。例如,可以使用逻辑运算将两个图像进行混合,实现叠加效果或合成图像。
-
图像的选择性合并: 在一些情况下,只有在满足特定条件时才希望将两个图像合并。图像与运算可以用于选择性地合并两个图像中的像素。
-
医学图像处理: 在医学图像处理中,图像与运算可以用于结合不同类型的医学影像,以提供更全面的信息。
-
图像的透明度控制: 图像与运算可以用于调整图像的透明度,使得一个图像在另一个图像上呈现透明效果。
总的来说,图像与运算是一种强大的工具,它可以在图像处理和计算机视觉任务中进行复杂的图像操作,从而满足特定应用场景的需求。
6.图像的几何运算满足交换律吗?
图像的几何运算并不总是满足交换律。交换律意味着运算的顺序不影响最终的结果。在图像的几何运算中,包括平移、旋转、缩放等操作,它们的交换律取决于具体的运算。
例如,对于平移操作,交换平移的顺序通常不会影响最终的结果。但是对于旋转和缩放,交换的顺序可能会影响最终的图像变换。因此,一般而言,图像的几何运算并不满足严格的交换律。
7.请列举图像的常见插值算法
在图像处理中,插值算法用于估计已知点之间的值。在图像的缩放、旋转等操作中,插值算法可以帮助确定目标位置的像素值。常见的图像插值算法包括:
- 最近邻插值(Nearest-neighbor interpolation): 使用离目标点最近的已知点的像素值来估计目标点的像素值。
- 双线性插值(Bilinear interpolation): 使用目标点周围的四个已知点的像素值,通过线性插值计算目标点的像素值。
- 双三次插值(Bicubic interpolation): 使用目标点周围的16个已知点的像素值,通过三次插值计算目标点的像素值。它比双线性插值更精确,但也更复杂。
- 拉格朗日插值: 使用拉格朗日多项式进行插值,适用于非均匀分布的已知点。
- 样条插值: 使用样条曲线进行插值,可以是线性样条、二次样条或三次样条,适用于平滑曲线的插值。
8.图像变形的原理是什么?
图像变形是指改变图像的形状或尺寸,通常包括平移、旋转、缩放等操作。图像变形的原理取决于具体的变形操作:
- 平移(Translation): 平移是通过将图像的每个像素沿着水平和垂直方向移动来实现的。平移操作的原理是对图像的每个像素进行坐标的调整。
- 旋转(Rotation): 旋转是通过改变图像中每个像素的位置和方向来实现的。旋转操作的原理涉及到旋转矩阵和插值算法,以确保在旋转过程中保持图像的质量。
- 缩放(Scaling): 缩放是通过增加或减小图像的尺寸来实现的。缩放操作的原理是对图像中每个像素进行插值计算,以确定目标位置的像素值。
- 仿射变换: 仿射变换包括平移、旋转、缩放和错切等操作,它可以通过矩阵运算来实现。矩阵中的元素用于描述各种变换的参数。
- 透视变换: 透视变换是一种非线性的变换,可以模拟近大远小的效果。透视变换的原理涉及到透视矩阵的计算。
无论采用哪种变形操作,图像变形的原理都涉及到对图像中每个像素的坐标、位置或像素值进行适当的调整,以实现所需的形状或尺寸的改变。在实际操作中,通常会使用
第 四 章
1.什么是灰度直方图?它有哪些应用?
灰度直方图是一幅图像中各个灰度级别出现的频率分布统计图。通常,灰度直方图横坐标表示图像的灰度级别,纵坐标表示对应灰度级别的像素数量或像素占比。
在灰度直方图中,每个灰度级别的柱子高度表示图像中具有该灰度级别的像素数量。通过观察和分析灰度直方图,可以获取关于图像对比度、亮度和分布的信息。
应用:
-
图像增强和调整: 通过分析灰度直方图,可以了解图像的对比度和亮度分布情况。对直方图进行调整,例如直方图均衡化,有助于增强图像的视觉效果,使得图像的灰度级别更均匀分布。
-
图像分割: 灰度直方图可以用于图像分割,即将图像分成具有相似灰度特性的区域。通过寻找直方图中的峰值、谷值或阈值,可以帮助确定合适的分割阈值,从而实现图像分割。
-
图像质量评估: 分析灰度直方图有助于评估图像的质量。例如,一张良好曝光的图像应该具有均匀的直方图分布,而过曝或欠曝的图像则可能在直方图中表现出明显的不均匀性。
-
目标检测和识别: 灰度直方图可以用于识别图像中的不同对象或目标。每个对象通常对应于直方图中的一个峰值。
-
图像压缩: 灰度直方图信息可用于图像压缩。通过对图像进行频率分析,可以设计更有效的压缩算法,以减小文件大小而保持图像质量。
-
医学图像分析: 在医学领域,灰度直方图被用于分析X射线、CT扫描等图像,以帮助诊断和疾病检测。
总的来说,灰度直方图在图像处理和计算机视觉领域中有广泛的应用,是图像分析和处理的重要工具。
2.从灰度直方图能获得图像的哪些信息?
灰度直方图提供了关于图像灰度分布的丰富信息,通过对其分析,可以获得以下有关图像的信息:
-
对比度信息: 直方图的宽度反映了图像的对比度。对比度较高的图像,其直方图将在不同灰度级别上具有较大的波动。
-
亮度信息: 直方图的整体位置可以用于估计图像的亮度水平。峰值偏向较低灰度级别表示图像可能偏向较暗,而峰值偏向较高灰度级别表示图像可能偏向较亮。
-
灰度级别分布信息: 直方图的形状反映了图像中各个灰度级别的分布情况。例如,均匀分布的直方图可能对应于一张具有良好对比度的图像,而峰值较高的直方图可能对应于图像中存在明亮或暗的主要对象。
-
饱和度信息: 直方图的峰值宽度和高度可以提供有关图像饱和度的信息。饱和度较高的图像通常具有广泛分布的峰值,而饱和度较低的图像可能有更窄的峰值。
-
图像质量信息: 直方图的形状和均匀性可以提供有关图像质量的线索。例如,一张图像的直方图均匀分布可能表示图像曝光良好,而不均匀分布可能表示曝光问题或者图像中存在阴影或高光区域。
-
目标检测信息: 直方图中的不同峰值可能对应于图像中的不同对象或目标。通过分析直方图的峰值,可以帮助检测和识别图像中的特定区域或对象。
总体而言,灰度直方图是图像处理和分析中的有用工具,通过对其进行适当的解释和理解,可以提取有关图像特征和属性的重要信息。
3.图像增强的目的是什么?它包含哪些内容?
图像增强的目的是改善图像的质量,使得图像更适合于特定的应用或提高人类观察的效果。增强的方法旨在使图像更清晰、更对比、更易于理解,或者使其中的某些特征更为突出。图像增强常用于计算机视觉、医学图像分析、遥感图像处理、图像编辑等领域。
增强图像的常见目标和内容包括:
-
提高对比度: 通过调整图像中不同灰度级别之间的差异,增强图像的对比度,使得细节更为清晰可见。
-
增强亮度和色彩: 调整图像的亮度和颜色饱和度,使其更加生动和有吸引力。
-
降噪: 减少或移除图像中的噪声,使图像更清晰,有助于提高图像的质量和可用性。
-
图像锐化: 强调图像中的边缘和细节,使其更为清晰和鲜明。
-
直方图均衡化: 调整图像的灰度分布,使其更均匀,提高图像的整体对比度。
-
去雾: 在有雾或大气污染的图像中,通过去除或减轻雾霾效应,使图像更为清晰。
-
图像缩放和旋转: 改变图像的大小和方向,以适应不同的显示或分析需求。
-
目标突出: 通过调整图像中的颜色、对比度或其他特征,使感兴趣的目标更为突出。
-
图像融合: 将多个图像融合在一起,以获取更多信息或提高图像质量。
-
色彩空间转换: 将图像从一种色彩空间转换为另一种,以满足不同的处理或显示需求。
图像增强的具体方法和技术根据应用和需求而异,可以是基于规则的手工操作,也可以是基于数学和统计方法的自动化操作。增强的结果应该能够提高图像的可读性、解释性或适应性,以满足特定任务的要求。
4.直方图修正有哪两种方法?它们二者有何区别与联系?
a. 线性直方图修正:
- 原理: 通过线性的缩放和平移操作,调整图像的灰度级别,从而改变整个图像的对比度和亮度。
- 方法: 通常通过公式 �(�,�)=�⋅�(�,�)+�g(x,y)=a⋅f(x,y)+b 来表示,其中 �(�,�)g(x,y) 是修正后的像素值,�(�,�)f(x,y) 是原始像素值,�a 和 �b 是调整参数。
- 特点: 简单直观,但对图像整体亮度和对比度的调整有限。
b. 非线性直方图修正(直方图匹配):
- 原理: 将图像的直方图映射到一个目标直方图,以匹配目标分布,从而实现对整个图像的修正。
- 方法: 通过累积分布函数(CDF)的映射来实现,使得原始图像的分布接近目标分布。
- 特点: 能够更灵活地调整图像的分布,但计算较复杂。
区别与联系:
- 区别: 线性直方图修正是通过线性变换调整像素值,而非线性直方图修正通过映射直方图实现。
- 联系: 两者都是通过调整图像的灰度级别来实现图像的对比度和亮度调整。
5.直方图规定化处理的技术难点是什么?如何解决?
技术难点:
- 目标直方图确定: 确定一个合适的目标直方图是关键,它通常是期望的图像灰度分布。
- 灰度值映射: 如何将原始图像的灰度级别映射到目标直方图上,需要进行准确的灰度值匹配。
解决方法:
- 目标直方图确定: 选择一个合适的目标图像,从中提取出目标直方图,或者根据任务需求设计一个期望的目标直方图。
- 灰度值映射: 利用累积分布函数(CDF)的映射关系,将原始图像的灰度级别映射到目标直方图的灰度级别上。
6.灰度直方图的特性是什么?
灰度直方图具有以下特性:
- 表征图像分布: 可以反映图像中不同灰度级别的分布情况。
- 对比度信息: 直方图的宽度反映了图像的对比度,对比度较高的图像直方图分布较广。
- 亮度信息: 直方图的整体位置可以估计图像的亮度水平,峰值偏向较低灰度级别表示图像可能偏向较暗。
- 分割信息: 直方图的波峰和波谷可以用于图像分割,找到合适的阈值。
- 峰值和谷值: 反映图像中存在的主要对象或背景,通过分析峰值和谷值可以进行目标检测。
7.直方图均衡化和直方图规格化的区别是什么?
直方图均衡化:
- 目的: 旨在增强图像的对比度,使得图像的灰度级别更均匀分布。
- 过程: 通过调整图像的灰度级别,使得累积分布函数(CDF)均匀分布,从而实现对比度的增强。
- 效果: 增强了整体对比度,但可能会使得图像的一些细节被放大。
直方图规定化:
- 目的: 旨在将图像的灰度级别映射到一个预定义的目标直方图,以匹配目标分布。
- 过程: 通过将原始图像的直方图映射到目标直方图上,实现图像的规定化。
- 效果: 使得图像的分布更接近于预定的目标分布,保留了目标分布的特性。
区别:
- 直方图均衡化主要关注对比度的增强,而直方图规定化关注于将图像的分布调整到目标分布。
- 直方图均衡化是一个自适应的过程,而直方图规定化需要事先确定目标分布。
8.使用 OpenCV 编写代码,实现图像的直方图均衡化
import cv2
import matplotlib.pyplot as plt# 读取图像
image = cv2.imread('input_image.jpg', cv2.IMREAD_GRAYSCALE)# 进行直方图均衡化
equalized_image = cv2.equalizeHist(image)# 显示原始图像和均衡化后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image, cmap='gray')
plt.title('Original Image')plt.subplot(1, 2, 2)
plt.imshow(equalized_image, cmap='gray')
plt.title('Equalized Image')plt.show()9.使用 OpenCV 编写代码,实现图像的直方图对比。
import cv2
import numpy as np
import matplotlib.pyplot as plt# 读取两幅图像
image1 = cv2.imread('image1.jpg', cv2.IMREAD_GRAYSCALE)
image2 = cv2.imread('image2.jpg', cv2.IMREAD_GRAYSCALE)# 计算直方图
hist1 = cv2.calcHist([image1], [0], None, [256], [0, 256])
hist2 = cv2.calcHist([image2], [0], None, [256], [0, 256])# 计算巴氏距离
bhattacharyya_distance = cv2.compareHist(hist1, hist2, cv2.HISTCMP_BHATTACHARYYA)# 显示原始图像和直方图
plt.figure(figsize=(12, 6))plt.subplot(2, 2, 1)
plt.imshow(image1, cmap='gray')
plt.title('Image 1')plt.subplot(2, 2, 2)
plt.imshow(image2, cmap='gray')
plt.title('Image 2')plt.subplot(2, 2, 3)
plt.plot(hist1, color='blue', label='Image 1')
plt.plot(hist2, color='red', label='Image 2')
plt.title('Histograms')
plt.legend()plt.subplot(2, 2, 4)
plt.text(0.5, 0.5, f'Bhattacharyya Distance: {bhattacharyya_distance:.4f}', fontsize=12, ha='center', va='center')
plt.axis('off')plt.show()10.使用 OpenCV 编写代码,实现图像的直方图反向投影
import cv2
import numpy as np
import matplotlib.pyplot as plt# 读取目标图像和输入图像
target_image = cv2.imread('target_image.jpg')
input_image = cv2.imread('input_image.jpg')# 转换为HSV色彩空间
target_hsv = cv2.cvtColor(target_image, cv2.COLOR_BGR2HSV)
input_hsv = cv2.cvtColor(input_image, cv2.COLOR_BGR2HSV)# 计算目标图像的直方图
target_hist = cv2.calcHist([target_hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])# 计算输入图像的直方图反向投影
back_projection = cv2.calcBackProject([input_hsv], [0, 1], target_hist, [0, 180, 0, 256], 1)# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(target_image, cv2.COLOR_BGR2RGB))
plt.title('Target Image')plt.subplot(1, 2, 2)
plt.imshow(back_projection, cmap='gray')
plt.title('Back Projection')plt.show()11.使用 OpenCV 编写代码,实现图像的直方图模板匹配
import cv2
import numpy as np
import matplotlib.pyplot as plt# 读取图像和模板
image = cv2.imread('image.jpg')
template = cv2.imread('template.jpg')# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray_template = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)# 模板匹配
result = cv2.matchTemplate(gray_image, gray_template, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)# 在原图上绘制矩形框
top_left = max_loc
bottom_right = (top_left[0] + template.shape[1], top_left[1] + template.shape[0])
cv2.rectangle(image, top_left, bottom_right, (0, 255, 0), 2)# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title('Matching Result')plt.subplot(1, 2, 2)
plt.imshow(gray_template, cmap='gray')
plt.title('Template')plt.show()
12.直方图近年来与什么技术相融合?具体有什么运用?
直方图在近年来与深度学习技术相融合,主要应用包括:
- 图像检索: 使用深度学习技术提取图像特征,结合直方图信息进行图像检索,提高检索的准确性和效率。
- 目标检测: 结合深度学习中的目标检测算法,使用直方图信息对图像进行预处理或增强,以提高目标检测的性能。
- 图像分割: 在深度学习图像分割任务中,直方图信息可用于初始化或优化分割算法,提高分割精度。
- 图像生成: 利用深度学习生成模型,结合直方图信息,生成具有特定颜色和对比度分布的图像。
- 视频处理: 将深度学习应用于视频处理中,结合视频帧的直方图信息,实现更智能的视频
第 五 章
1.空间域滤波方法分为几类”每一类中包含哪些方法?
空间域滤波方法可以分为两类:
- 线性滤波: 线性滤波方法是基于线性加权的,输出图像中的每个像素值是输入图像中对应像素值的线性组合。常见的线性滤波方法包括:
- 均值滤波
- 加权平均滤波
- 高斯滤波
- 拉普拉斯滤波
- Sobel、Prewitt等边缘检测滤波器
- 非线性滤波: 非线性滤波方法是基于像素的非线性变换,输出图像中的每个像素值不是输入像素值的线性组合。一些常见的非线性滤波方法包括:
- 中值滤波
- 最大值滤波
- 最小值滤波
- 形态学滤波(腐蚀、膨胀等)
2.平滑空间滤波方法中,哪些方法是线性的?哪些方法是非线性的?
在平滑空间滤波中,线性滤波方法包括:
- 均值滤波
- 加权平均滤波
- 高斯滤波
这些方法是线性的,因为它们都是对输入图像中的像素值进行线性组合。而非线性滤波方法中,中值滤波是一种常见的非线性滤波方法。
3.中值滤波的特点是什么”它主要用于消除什么类型的噪声?
中值滤波的特点包括:
- 中值滤波是一种非线性滤波方法,它对图像中的每个像素使用一个窗口内像素值的中值来替代该像素的原始值。
- 中值滤波对于椒盐噪声等脉冲性噪声具有较好的去噪效果。
- 它在保持图像边缘信息的同时,可以有效地去除极端值的影响。
中值滤波主要用于消除脉冲性噪声,即在图像中出现的偶然的亮或暗的离群点。
4.试提出一种过程来求一个n x n 领域的中值。
求一个 n x n 领域的中值的过程可以通过以下步骤实现:
- 定义 n x n 的窗口: 对于图像中的每个像素,定义一个大小为 n x n 的窗口,以该像素为中心。
- 提取窗口内像素值: 从图像中提取窗口内的所有像素值,并将其排序。
- 计算中值: 对排序后的像素值取中值,即取排序后中间位置的值作为中值。
- 将中值赋给目标像素: 将计算得到的中值赋给图像中对应的目标像素。
- 遍历所有像素: 重复以上过程,遍历图像中的所有像素,对每个像素都计算其 n x n 领域的中值。
5.最大值滤波器和最小值滤波器对图像的关注点分别是什么?
- 最大值滤波器: 最大值滤波器关注于获取图像局部区域内的最大像素值。它常被用于消除图像中的最小噪声,同时可能导致图像边缘模糊。
- 最小值滤波器: 最小值滤波器关注于获取图像局部区域内的最小像素值。它通常用于去除图像中的最大噪声,但也可能导致图像边缘的模糊。
这两种滤波器主要用于去除特定类型的噪声,其中最大值滤波器对椒盐噪声有较好的去噪效果,而最小值滤波器对斑点噪声有较好的去噪效果
6.空间域滤波和频率域滤波对图像的滤波效果有何异同?
- 空间域滤波: 空间域滤波是直接在图像的原始像素空间中进行的。它主要包括一些基于像素值的操作,例如均值滤波、中值滤波等。这种滤波方法直接处理图像的像素,能够改变图像的亮度和对比度,但可能会损失图像的细节。
- 频率域滤波: 频率域滤波是通过对图像进行傅里叶变换,将图像转换到频率域进行处理。常见的频率域滤波包括使用频率域滤波器进行高通滤波、低通滤波等操作。频率域滤波主要用于增强或抑制图像的特定频率成分,如边缘、纹理等。
异同点:
- 异同点: 两者都可以用于图像的平滑、锐化、去噪等处理。频率域滤波更适合处理频域信息,例如在频域中选择性地增强或抑制特定频率分量,而空间域滤波则更直接地操作图像的原始像素。
- 不同点: 空间域滤波可能更容易理解和实现,但可能会引入一些图像伪影。频率域滤波通常对特定频率成分更有针对性,但需要使用傅里叶变换等复杂的数学操作。
7.常用的图像锐化算子有哪几种?
图像锐化是通过增强图像中的边缘和细节来使图像看起来更加清晰。常用的图像锐化算子包括:
- Sobel算子: 用于边缘检测,具有垂直和水平两个方向的算子。
- Prewitt算子: 类似于Sobel,也用于边缘检测,有垂直和水平两个方向的算子。
- Laplacian算子: 通过计算图像的二阶导数来增强边缘。
- Scharr算子: 类似于Sobel和Prewitt,用于增强边缘。
- Canny边缘检测: 结合了多个步骤,包括高斯平滑、梯度计算、非极大值抑制和双阈值边缘跟踪。
这些算子用于突出图像中的边缘和细节,以实现图像锐化的效果。
8.高斯分布的标准差。在图像平滑中的影响是什么?
高斯滤波是一种常用的平滑图像的方法,其中高斯分布的标准差(σ)决定了滤波核的形状。标准差越大,滤波核越宽,平滑效果越强。在图像平滑中,高斯滤波的影响如下:
- 小标准差(σ): 对应较窄的滤波核,保留更多的细节,但可能较弱地去除噪声。
- 大标准差(σ): 对应较宽的滤波核,更强烈地平滑图像,有助于去除噪声,但可能会模糊细节。
选择合适的标准差取决于图像的特性和应用需求。通常,在进行高斯平滑时,需要根据具体情况调整标准差,以在去噪的同时尽量保留图像的关键特征。
9.简述用于平滑和锐化处理的滤波器之间的联系和区别。
- 都属于空间域滤波: 平滑和锐化处理的滤波器都是空间域滤波器,直接在图像的原始像素空间中进行操作。
- 都是通过卷积操作实现: 两者都通过将图像与特定的滤波核进行卷积来实现对图像的处理。
区别:
- 目标不同:
- 平滑处理: 主要目标是减小图像中的噪声,使图像更加模糊。常见的平滑滤波器有均值滤波、高斯滤波等。
- 锐化处理: 主要目标是增强图像中的边缘和细节,使图像更加清晰。常见的锐化滤波器有拉普拉斯滤波、Sobel滤波等。
- 效果不同:
- 平滑处理: 降低图像的变化率,减小亮度和颜色的波动,有助于去除噪声。
- 锐化处理: 强调图像中的变化,增加亮度和颜色的差异,使边缘更加明显。
- 滤波核不同:
- 平滑处理: 使用平均型的滤波核,如均值滤波、高斯滤波,以模糊图像。
- 锐化处理: 使用增强边缘的滤波核,如拉普拉斯滤波、Sobel滤波,以突出图像中的边缘和细节。
10.在给定的应用中,一个均值掩模被用于输人图像以减少噪声,然后再用一个拉普拉斯掩模增强图像中的小细节,如果交换这两个步骤,结果是否相同?
不一定。交换均值滤波和拉普拉斯滤波的顺序可能导致不同的结果。这是因为两个滤波器的操作目标和效果不同。
- 均值滤波: 用于平滑图像,减小噪声。它将图像中每个像素的值替换为其周围邻域像素值的平均值,从而模糊图像。
- 拉普拉斯滤波: 用于增强图像中的边缘和细节。它强调图像中像素值的变化,可以使边缘更加明显。
如果先进行均值滤波,将会模糊图像并减小细节,然后再进行拉普拉斯滤波,可能会强调模糊后的图像中的一些细节,但整体效果可能仍然模糊。
如果先进行拉普拉斯滤波,强调图像中的细节和边缘,然后再进行均值滤波,可能会在一定程度上模糊图像,但保留了边缘和细节。
因此,结果可能在某些方面相似,但总体上可能不同。最终的效果取决于具体的图像内容和应用需求。
第 六 章
1.理想滤波器主要有哪些?它们各有什么特点?
理想滤波器主要包括:
a. 理想低通滤波器:
- 特点: 完全阻塞截止频率以下的频率成分,完全通过截止频率以上的频率成分。
- 效果: 对于低于截止频率的成分进行保留,高于截止频率的成分完全消除,产生图像的边缘会出现振铃效应。
b. 理想高通滤波器:
- 特点: 完全阻塞截止频率以下的频率成分,完全通过截止频率以上的频率成分。
- 效果: 对于高于截止频率的成分进行保留,低于截止频率的成分完全消除,产生图像的低频部分会失真。
c. 理想带通滤波器:
- 特点: 保留两个截止频率之间的频率成分,阻塞其他频率成分。
- 效果: 对于带通范围内的频率成分进行保留,带通范围外的频率成分完全消除。
d. 理想带阻滤波器:
- 特点: 阻塞两个截止频率之间的频率成分,保留其他频率成分。
- 效果: 对于带阻范围外的频率成分进行保留,带阻范围内的频率成分完全消除。
2.巴特沃斯滤波器分几类?它们各有什么特点
巴特沃斯滤波器分为无限远通带、有限通带、无限远阻带和有限阻带四类。它们的特点如下:
a. 无限远通带巴特沃斯滤波器:
- 特点: 在通带中,频率响应具有幅度下降的趋势,但没有截止频率的概念。
- 应用: 适用于需要在通带内逐渐减小振幅的情况。
b. 有限通带巴特沃斯滤波器:
- 特点: 在通带中,频率响应幅度在截止频率处有一个极小值,然后在截止频率以上逐渐下降。
- 应用: 适用于需要在通带内有一个极小值的情况。
c. 无限远阻带巴特沃斯滤波器:
- 特点: 在阻带中,频率响应具有幅度下降的趋势,但没有截止频率的概念。
- 应用: 适用于需要在阻带内逐渐减小振幅的情况。
d. 有限阻带巴特沃斯滤波器:
- 特点: 在阻带中,频率响应幅度在截止频率处有一个极小值,然后在截止频率以下逐渐下降。
- 应用: 适用于需要在阻带内有一个极小值的情况。
3.频率域中研究图像的原因有哪此?
在频率域中研究图像的原因包括:
- 频率表示更直观: 频率域中使用傅里叶变换可以将图像表示为频率分量,更直观地展示图像的频率信息。
- 频率滤波: 频率域中的滤波操作能够方便地去除或增强特定频率的成分,对图像进行处理。
- 噪声分析: 频率域分析有助于识别和分析图像中的噪声成分,便于选择合适的去噪方法。
- 特征提取: 某些图像特征在频率域中更为明显,通过频率域分析可以提取这些特征。
- 压缩: 在频率域中,图像的高频成分通常较少,因此在压缩中使用频率域表示可以更有效地实现图像压缩。
4.简述低通滤波器。
低通滤波器是一类允许低频信号通过而抑制高频信号的滤波器。其特点包括:
- 通带: 低通滤波器允许低频信号通过,通带内的频率成分保留。
- 阻带: 低通滤波器在阻带内抑制高频信号,高频成分被滤除。
- 应用: 常用于图像去噪、平滑和模糊等任务,能够保留图像的整体特征,抑制细节和噪声。
常见的低通滤波器包括理想低通滤波器、巴特沃斯低通滤波器和高斯低通滤波器等。
5.判断题:频率域去噪声的技术流程就是先把图像从空间域变换到频率域,然后在频率域对噪声成分进行掩模滤波,抑制或者消除噪声,最后再把图像从频率域逆变换到空间域。
判断:正确。 频率域去噪的一般流程包括傅里叶变换(空间域到频率域)、频率域滤波(对噪声成分进行掩模滤波)、傅里叶逆变换(频率域到空间域)。这一流程允许在频率域中对图像进行处理,特别是去除或减弱噪声成分,最终得到去噪后的图像。
6.下列对频率域图像增强法描述正确的是(A)
A.频率域增强的第一步是对图像进行傅里叶变换
B.任意波器都可以完成对频谱图像的处理,且效果差别不大
C.滤波处理后的频谱图像无须进行傅里叶逆变换,就可得到增强的图像
D.为了去除噪声,通常采用高通滤波器抑制低频成分
解析:频率域图像增强的一般流程包括将图像进行傅里叶变换,然后在频率域进行滤波或增强操作,最后再进行傅里叶逆变换得到增强后的图像。
7.傅里叶变换是图像处理中一种有效而重要的方法,应用十分广泛。下列选项中属于傅里叶变换的是©
A.图像恢复
B.周期性噪声去除
C.频率域滤波
D.纹理分析
解析:傅里叶变换在图像处理中应用广泛,其中频率域滤波是傅里叶变换的一种常见应用。
8.关于傅里叶变换的描述,正确的是©
A.傅里叶变换分为连续傅里叶变换和离散傅里叶变换
B.图像的傅里叶变换研究的是时间域和频率域之间的关系
C.图像的傅里叶变换研究的是空间域和频率域之间的关系
D.空间上的梯度变化决定频率域图像的高频率特性
解析:傅里叶变换用于将图像从空间域转换到频率域,研究图像在这两个域之间的关系。
9.不属于在频率域中研究图像的原因是(A)
A.空间域处理图像的效果不如频率域处理图像的效果
B.如果在空间域中难以表达增强任务,可以考虑在频率域中完成
C.滤波在频率域中更直观
D.可以按需要在频率域中指定滤波器,并将结果用于空间滤波
解析:频率域处理和空间域处理各有优势,选择使用频率域处理图像的原因不应是因为空间域处理效果不好,而是因为频率域处理更适合特定任务或需求。
10.高通滤波后的图像通常较暗,为改善这种情况,将高通滤波器的转移函数加上一常数量以便引入一些低频分量,这样的滤波器叫(B)。
A.巴特沃斯高通滤波器
C.高频加强滤波器
B.高频提升滤波器
D.理想高通滤波器
解析:高频提升滤波器通过在高通滤波器的转移函数上加上一个常数,可以提高高频分量,以改善高通滤波后图像较暗的问题。
第 七 章
1._腐蚀__是一种消除连通域的边界点,使边界向内收缩的处理。
2.__膨胀_是将与目标区城的背景点合并到该目标物中,使目标物边界向外部扩张的处理。
3.对一幅不全为背景的图像反复膨胀或腐蚀,分别会产生什么样的效果?(假设结构元不为单像素点)
- 反复膨胀: 图像中的目标区域逐渐扩大,连接成为更大的连通域,而细小的间隙可能会被填充。
- 反复腐蚀: 图像中的目标区域逐渐减小,细小的连接部分可能会被消除,而目标之间的间隙可能逐渐增大。
5.开运算相比腐蚀运算的优点是什么?
开运算是先腐蚀后膨胀的组合操作。
优点:
- 去除小的目标物体: 开运算能够有效消除图像中小于结构元素的目标物体,有助于去除噪声。
- 保持目标的整体形状: 对于较大的目标,开运算可以保持其整体形状,减小腐蚀操作可能引起的形状变化。
6.闭运算相比膨胀运算的优点是什么?
闭运算是先膨胀后腐蚀的组合操作。
优点:
- 填充目标的孔洞: 闭运算能够填充目标物体内的小孔洞,使目标更加完整。
- 平滑目标边界: 闭运算有助于平滑目标的边界,使得目标更加连续。
总体而言,开运算和闭运算是形态学处理中常用的图像操作,它们可以根据具体的图像特征和处理需求选择使用。
7.简述灰度图像使用形态学梯度处理后可以生成对象轮廓的原因。
形态学梯度是通过对图像进行膨胀和腐蚀操作,然后对这两者之间的差异进行计算而得到的。对于灰度图像,形态学梯度可以突出物体的边缘和轮廓。原因如下:
- 膨胀操作: 膨胀可以使物体的边缘部分扩张,使得物体的亮度增加。在灰度图像中,这意味着膨胀操作会导致图像中亮部分扩张。
- 腐蚀操作: 腐蚀可以使物体的边缘部分缩小,使得物体的亮度减小。在灰度图像中,这意味着腐蚀操作会导致图像中亮部分收缩。
- 梯度计算: 形态学梯度是膨胀和腐蚀之间的差异。这种差异会突出物体的边缘,因为在物体边缘附近,膨胀和腐蚀的效果差异较大。
因此,形态学梯度操作对于灰度图像可以用于突出对象的边缘和轮廓。
8.灰度图像形态学梯度处理有无类似二值图像边界提取的多种操作?如果有,则通过代码实现,并观察提取到的边界有什么区别。
在灰度图像中,形态学梯度处理的一种常见变体是通过其他形态学操作实现的。其中,开运算和闭运算也可以用于类似于二值图像边界提取的目的。
下面是通过开运算和闭运算实现灰度图像梯度操作的简单代码:
pythonCopy codeimport cv2
import numpy as np
import matplotlib.pyplot as plt# 读取灰度图像
image_gray = cv2.imread('input_image.jpg', cv2.IMREAD_GRAYSCALE)# 定义结构元素
kernel = np.ones((5, 5), np.uint8)# 开运算
gradient_opening = cv2.morphologyEx(image_gray, cv2.MORPH_GRADIENT, kernel)# 闭运算
gradient_closing = cv2.morphologyEx(image_gray, cv2.MORPH_CLOSE, kernel)# 显示结果
plt.figure(figsize=(10, 5))plt.subplot(131), plt.imshow(image_gray, cmap='gray'), plt.title('Original Image')
plt.subplot(132), plt.imshow(gradient_opening, cmap='gray'), plt.title('Gradient by Opening')
plt.subplot(133), plt.imshow(gradient_closing, cmap='gray'), plt.title('Gradient by Closing')plt.show()
这段代码分别使用了开运算和闭运算进行梯度处理。开运算的结果强调物体的边缘外部,而闭运算的结果强调物体的边缘内部。这两种操作可以根据具体的应用需求选择,以得到不同的边缘效果。
9.简述灰度图像使用顶帽变换后可以消除不均匀的光照背景影响的原因。
顶帽变换是通过原始图像与图像的开运算之间的差异来获得的。在灰度图像中,顶帽变换可以用于消除不均匀的光照背景影响。原因如下:
- 开运算: 开运算能够平滑图像并消除较小的目标物体,同时保留较大目标的结构信息。在灰度图像中,开运算可以消除图像中亮度较小的背景细节。
- 顶帽变换: 顶帽变换是原始图像与开运算之间的差异。这个差异图像突出了图像中较小和较暗的细节,即原始图像中的背景。
因此,通过应用顶帽变换,可以得到消除不均匀的光照背景影响的图像,强调了图像中较小的细节和暗部分。这对于一些图像处理任务,如目标检测和图像分割,能够更好地突出目标物体。
10.编程实现二值图像的连通分量提取算法(可调用书中已展示的代码,下同)
import cv2
import numpy as npdef connected_components(image_path):# 读取二值图像image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)# 二值化处理_, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)# 连通分量标记_, labels, stats, centroids = cv2.connectedComponentsWithStats(binary_image)# 显示标记结果labeled_image = np.zeros_like(image)for label in range(1, len(stats)):cv2.putText(labeled_image, str(label), (int(centroids[label][0]), int(centroids[label][1])),cv2.FONT_HERSHEY_SIMPLEX, 0.5, 255, 2)cv2.rectangle(labeled_image, (stats[label][0], stats[label][1]),(stats[label][0] + stats[label][2], stats[label][1] + stats[label][3]), 255, 2)# 显示原图和标记结果cv2.imshow('Original Image', image)cv2.imshow('Connected Components', labeled_image)cv2.waitKey(0)cv2.destroyAllWindows()# 调用函数
connected_components('binary_image.png')11.编程实现灰度图像的开运算算法。
import cv2
import numpy as npdef grayscale_opening(image_path, kernel_size=(5, 5)):# 读取灰度图像image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)# 定义结构元素kernel = np.ones(kernel_size, np.uint8)# 开运算opened_image = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)# 显示结果cv2.imshow('Original Image', image)cv2.imshow('Opening Result', opened_image)cv2.waitKey(0)cv2.destroyAllWindows()# 调用函数
grayscale_opening('gray_image.png')12.编程实现灰度图像形态学平滑算法
import cv2
import numpy as npdef grayscale_smoothing(image_path, kernel_size=(5, 5)):# 读取灰度图像image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)# 定义结构元素kernel = np.ones(kernel_size, np.uint8)# 形态学平滑smoothed_image = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernel)# 显示结果cv2.imshow('Original Image', image)cv2.imshow('Smoothing Result', smoothed_image)cv2.waitKey(0)cv2.destroyAllWindows()# 调用函数
grayscale_smoothing('gray_image.png')13.编程实现灰度图像形态学梯度。
import cv2
import numpy as npdef grayscale_gradient(image_path, kernel_size=(5, 5)):# 读取灰度图像image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)# 定义结构元素kernel = np.ones(kernel_size, np.uint8)# 形态学梯度gradient_image = cv2.morphologyEx(image, cv2.MORPH_GRADIENT, kernel)# 显示结果cv2.imshow('Original Image', image)cv2.imshow('Gradient Result', gradient_image)cv2.waitKey(0)cv2.destroyAllWindows()# 调用函数
grayscale_gradient('gray_image.png')14.编程实现灰度图像形态学顶帽变换.
import cv2
import numpy as npdef grayscale_tophat(image_path, kernel_size=(5, 5)):# 读取灰度图像image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)# 定义结构元素kernel = np.ones(kernel_size, np.uint8)# 顶帽变换tophat_image = cv2.morphologyEx(image, cv2.MORPH_TOPHAT, kernel)# 显示结果cv2.imshow('Original Image', image)cv2.imshow('Top Hat Result', tophat_image)cv2.waitKey(0)cv2.destroyAllWindows()# 调用函数
grayscale_tophat('gray_image.png')第 八 章
1.举例说明分割在图像处理中的实际应用。
分割在图像处理中有许多实际应用,其中一些包括:
- 医学图像分割: 在医学图像中,分割可以用于识别和分离不同组织结构,如肿瘤、血管等,有助于医生进行诊断和治疗规划。
- 目标检测与跟踪: 在计算机视觉中,图像分割可用于检测和跟踪图像中的目标,如行人、车辆等,是自动驾驶和视频监控等领域的基础。
- 面部识别: 图像分割可以用于面部识别系统中,将图像中的面部与背景分离,有助于提高识别的准确性。
- 地图制作与遥感图像分析: 在地图制作和遥感图像分析中,分割可用于提取地物信息,如道路、建筑物、植被等,支持城市规划和环境监测。
- 图像编辑和合成: 图像分割可以用于图像编辑,如移除或替换图像中的特定对象,或将图像中的元素合成到其他图像中。
2.取一幅二值图像作为输入,试使用不同的阀值对图像进行阀值分割,观察不同的闽值对图像分割处理的结果有何不同。
import cv2
import matplotlib.pyplot as plt# 读取二值图像
image = cv2.imread('binary_image.png', cv2.IMREAD_GRAYSCALE)# 设定不同的阈值
threshold_values = [50, 100, 150]# 显示原始图像
plt.figure(figsize=(10, 4))
plt.subplot(1, 4, 1)
plt.imshow(image, cmap='gray')
plt.title('Original Image')# 对图像进行不同阈值的分割并显示结果
for i, threshold in enumerate(threshold_values):_, segmented_image = cv2.threshold(image, threshold, 255, cv2.THRESH_BINARY)plt.subplot(1, 4, i + 2)plt.imshow(segmented_image, cmap='gray')plt.title(f'Threshold = {threshold}')plt.show()3.在灰度阀值分割中如何选择合适的阙值? 用 C++ 语言编写出相应的程序。
#include <opencv2/opencv.hpp>
#include <iostream>int main() {// 读取灰度图像cv::Mat image = cv::imread("grayscale_image.jpg", cv::IMREAD_GRAYSCALE);// 计算直方图cv::Mat hist;int histSize = 256;float range[] = {0, 256};const float* histRange = {range};cv::calcHist(&image, 1, 0, cv::Mat(), hist, 1, &histSize, &histRange, true, false);// 归一化直方图cv::normalize(hist, hist, 0, 1, cv::NORM_MINMAX, -1, cv::Mat());// 寻找 Otsu's 阈值double otsu_threshold = 0.0;cv::threshold(image, image, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);otsu_threshold = cv::threshold(image, image, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);// 显示结果cv::imshow("Original Image", image);std::cout << "Otsu's Threshold: " << otsu_threshold << std::endl;cv::waitKey(0);return 0;
}4.采用霍夫变换检测直线时,为什么不采用 y=ax 的直角坐标表达形式?
在霍夫变换中,通常不采用直角坐标系中的 y=ax 表达形式,而采用极坐标系表示直线。这是因为直角坐标系中的 y=ax 表达形式在处理垂直于 x 轴的直线时,斜率 a 为无穷大,导致计算上的问题和不稳定性。
霍夫变换通过使用极坐标系中的参数化表达式 r = x * cos(theta) + y * sin(theta) 来表示直线,这样就避免了斜率无穷大的问题。极坐标系中的霍夫变换更加鲁棒,适用于检测任意方向的直线。
5.证明: 在极坐标系中的霍夫变换将图像空间 XY 的共线点映射为p 平面上的正弦曲线并交汇于一点。

6.采用区域生长法进行图像分割时,可采用哪些生长准则? 观察图 8-14(a),更换初始生长点和生长准则,绘制出新的区域生长结果图。
在区域生长法进行图像分割时,可采用以下一些生长准则:
- 灰度值相似性: 区域中相邻像素的灰度值相似性达到一定阈值时,将其合并为一个区域。
- 空间相似性: 考虑像素之间的空间关系,若相邻像素之间的距离小于一定阈值,则将其合并为一个区域。
- 纹理相似性: 对于具有纹理信息的图像,可以考虑像素间纹理特征的相似性,将相似纹理的像素合并为一个区域。
- 生长点选择: 不同的生长点选择会导致不同的分割结果,可以尝试不同的生长点来观察效果。
import cv2
import numpy as np
import matplotlib.pyplot as pltdef region_growing(image, seed):height, width = image.shapevisited = np.zeros_like(image)region = np.zeros_like(image)threshold = 30 # 调整阈值stack = [seed]while stack:current_pixel = stack.pop()x, y = current_pixelif visited[x, y] == 1:continueif abs(int(image[x, y]) - int(image[seed])) < threshold:region[x, y] = 255visited[x, y] = 1# 将相邻像素入栈if x > 0:stack.append((x - 1, y))if x < height - 1:stack.append((x + 1, y))if y > 0:stack.append((x, y - 1))if y < width - 1:stack.append((x, y + 1))return region# 读取图像
image = cv2.imread('region_growing_example.jpg', cv2.IMREAD_GRAYSCALE)# 选择不同的生长点和生长准则
seed1 = (50, 50)
seed2 = (150, 150)region1 = region_growing(image, seed1)
region2 = region_growing(image, seed2)# 显示结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 3, 1)
plt.imshow(image, cmap='gray')
plt.title('Original Image')plt.subplot(1, 3, 2)
plt.imshow(region1, cmap='gray')
plt.title('Region Growing - Seed 1')plt.subplot(1, 3, 3)
plt.imshow(region2, cmap='gray')
plt.title('Region Growing - Seed 2')plt.show()7.用区域分裂-生长法分割图 8-26 所示的图像,并给出分割过程图。
- 初始化: 将整个图像看作一个初始区域,并计算该区域的平均灰度值。
- 区域生长: 对于每个像素,判断它是否与相邻像素的灰度值差异在一定范围内。如果是,则将其归入同一区域,并更新该区域的平均灰度值。
- 区域分裂: 对于某些满足分裂条件的区域,将其分裂成更小的子区域。通常,分裂条件可以基于灰度差异、纹理等。
- 迭代: 重复进行区域生长和分裂的步骤,直到满足停止条件为止,例如达到预定的区域数目或无法再分裂为止。
对于给定的图像,你需要根据具体的像素值和分割条件进行实际的编程或手工操作。
8.分水岭算法的主要缺点是什么?如何克服?
分水岭算法的主要缺点:
- 过分分割: 分水岭算法容易在图像中的纹理复杂、有噪声或存在小的亮度变化的区域过分分割,导致生成大量的水域(watershed)。
- 对噪声敏感: 分水岭算法对图像中的噪声非常敏感,可能导致噪声像素被错误地标记为分割线。
- 区域封闭问题: 算法可能产生不合理的区域,尤其在图像中存在弱纹理或低对比度区域时。
克服分水岭算法的方法:
- 前处理: 在应用分水岭算法之前,进行图像预处理以降低噪声对算法的影响,例如使用平滑滤波器。
- 调整参数: 调整分水岭算法的参数,例如梯度阈值和标记的设置,以平衡分割的精度和过分分割的问题。
- 后处理: 对分割结果进行后处理,合并相邻的小区域或移除面积较小的区域,以减少过分分割。
- 结合其他方法: 将分水岭算法与其他分割方法结合使用,形成一种混合方法,可以充分发挥各自方法的优势。
9.若运动图像帧与帧之间没有配准好,对图像差分法会有什么影响?
如果运动图像的帧与帧之间没有进行良好的配准,即相邻帧之间存在微小的位移或旋转,对图像差分法会产生一些问题:
- 虚假运动检测: 差分图像可能包含运动检测结果,但这些结果可能是由于帧之间的微小位移引起的,而不是实际的目标运动。
- 局部运动误差: 差分法可能对帧之间的微小变化非常敏感,导致局部运动误差。这可能在背景中存在微小的运动或噪声时更为明显。
- 稳定性差: 若帧之间存在微小的非线性运动或扭曲,差分法可能无法准确检测到目标的实际运动,从而影响稳定性。
如何解决:
- 运动校正: 在应用图像差分之前,对图像帧进行运动校正,确保它们在空间上对齐。这可以通过使用光流估计等方法来实现。
- 多帧平均: 使用多帧平均方法,将多个相邻帧的像素平均,减少微小运动的影响。
- 使用稳定的特征点: 如果目标中存在稳定的特征点,可以选择使用这些特征点进行运动检测,而不是直接使用像素差分。
10.试列举光流不等于运动流的情况。
光流(Optical Flow)和运动流(Motion Flow)是两个相关但不完全相同的概念。以下是它们不同的情况:
- 变化场景: 当场景中的物体不仅仅因为相机运动而导致像素强度变化时,光流可能无法准确表示物体的运动。运动流更通常用于描述场景中物体的整体运动。
- 非刚性变换: 光流通常假设场景中的物体是刚性的,即物体的形状在时间上不发生变化。如果物体经历了非刚性变换,如弯曲或扭曲,光流可能无法正确描述物体的形变。
- 遮挡: 当一个物体遮挡另一个物体时,
第 九 章
1.图像特征检测与匹配过程对于完成图像处理及分析任务具有重要意义,请谈谈你对这句话的理解。
图像特征检测与匹配是计算机视觉领域中的重要任务,具有以下重要意义:
- 目标识别与跟踪: 特征检测与匹配能够识别图像中的关键特征,从而用于目标检测与跟踪,例如在视频中追踪物体的运动。
- 图像配准与对齐: 特征匹配可用于图像配准,将不同图像中的相似特征对齐,如医学图像配准、卫星图像配准等。
- 三维重建: 通过在多个视角捕捉的图像中匹配特征,可以进行三维场景的重建,例如从多张图片中恢复出场景的三维结构。
- 图像检索与识别: 特征匹配在图像检索与识别中有关键作用,通过对图像进行特征提取和匹配,可以实现图像检索和识别任务。
- 视觉SLAM: 在视觉SLAM(Simultaneous Localization and Mapping)中,通过特征点的匹配来进行相机定位和建图,实现机器人或无人车在未知环境中的导航。
2.常见的图像特征有哪些种类? 请举例说明它们各自的特点。
常见的图像特征主要包括:
- 角点(Corners): 突出的图像区域,如Harris角点、Shi-Tomasi角点等。
- 边缘(Edges): 图像中明显的边缘,如Sobel、Prewitt等。
- 斑点(Blob/Region): 局部区域内的亮度变化,如SIFT(Scale-Invariant Feature Transform)。
- 纹理(Texture): 图像区域内的纹理信息,如LBP(Local Binary Pattern)。
- 线段(Lines): 直线或曲线的特征,如Hough变换。
3.什么是角点?常见的角点检测方法有哪些? 与特征点相比,角点有什么劣势
角点是图像中具有突出变化的区域,是在两个或多个方向上有明显梯度变化的点。角点检测方法包括:
- Harris角点检测: 利用局部区域内像素强度的变化来检测角点。
- Shi-Tomasi角点检测: 是Harris角点检测的改进版本,对于小于一定阈值的特征值进行了抑制。
- FAST(Features from Accelerated Segment Test): 基于圆周上的像素集合,通过快速的像素比较来检测角点。
与特征点相比,角点的劣势在于:
- 密度较低: 角点相对于其他特征,如斑点或纹理,通常密度较低,不能提供足够的信息来描述整个图像。
- 对旋转和尺度不变性差: 角点检测通常对图像的旋转和尺度变化不具有不变性,而一些特征点检测方法,如SIFT和SURF,具有更强的旋转和尺度不变性。
4.基于特征点的图像匹配策略分为哪几个步骤?
基于特征点的图像匹配策略一般分为以下步骤:
- 特征提取: 从两幅图像中提取关键的特征点,如SIFT、SURF、ORB等方法。
- 特征描述: 对提取的特征点进行描述,将其表示为具有区分性的向量。
- 特征匹配: 使用匹配算法将第一幅图像的特征点与第二幅图像的特征点进行匹配,建立它们之间的对应关系。
- 几何验证: 对匹配的特征点进行几何验证,排除错误的匹配。
5.本章一共介绍了多少种特征点?它们分别是哪些特征点? 除本章介绍的特征点外,还能找到哪些其他的特征点?
- Harris角点: 通过梯度的变化来检测角点。
- Shi-Tomasi角点: 是Harris角点的改进版本,对特征值进行了抑制。
- FAST角点: 通过像素快速比较来检测角点。
- SIFT(Scale-Invariant Feature Transform): 具有尺度不变性的特征点。
- SURF(Speeded-Up Robust Features): 在SIFT的基础上加速并提高了鲁棒性。
- ORB(Oriented FAST and Rotated BRIEF): 结合了FAST和BRIEF的特点。
除上述特征点外,还有其他一些特征点如:
- BRISK(Binary Robust Invariant Scalable Keypoints): 具有尺度和旋转不变性的二进制特征点。
- KAZE(2D and 3D Kazed Features): 具有尺度不变性和旋转不变性的特征点。
6.简述 SIFT、SURF、ORB 算法的原理,对比它们之间的性能并评价。
- SIFT(Scale-Invariant Feature Transform):
- 原理: SIFT通过寻找图像中的极值点,使用高斯金字塔来提取多尺度特征,并计算主方向和描述子。
- 性能: 具有很好的尺度不变性和旋转不变性,但计算量较大。
- SURF(Speeded-Up Robust Features):
- 原理: SURF基于图像的Hessian矩阵,通过快速Hessian检测特征点,并使用积分图加速计算描述子。
- 性能: 在一定程度上保持了SIFT的性能,但计算速度更快。
- ORB(Oriented FAST and Rotated BRIEF):
- 原理: ORB结合了FAST关键点检测和BRIEF特征描述,同时引入了方向性信息。
- 性能: 具有较快的计算速度和相对较好的性能,适合实时应用。
对比:
- 计算速度: ORB > SURF > SIFT。
- 尺度不变性: SIFT > SURF > ORB。
- 旋转不变性: SIFT > SURF > ORB。
- 鲁棒性: SIFT = SURF > ORB。
选择适合任务需求的算法取决于应用场景,如果对计算速度要求较高,可以选择ORB;如果需要更好的尺度和旋转不变性,可以选择SIFT或SURF。
7.设计程序,检测你感兴趣的不同种类的特征点,并统计在图像中提取到的特征占数量,观察这一过程在你机器上所用的时间。
import cv2
import time
import numpy as np
import matplotlib.pyplot as pltdef detect_and_draw_keypoints(image, detector, name):start_time = time.time()keypoints = detector.detect(image, None)end_time = time.time()print(f"{name} keypoints: {len(keypoints)}, Time: {end_time - start_time:.4f} seconds")image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))plt.title(f"{name} Keypoints")plt.show()# 读取图像
image = cv2.imread('your_image_path.jpg')# 创建 SIFT、SURF 和 ORB 检测器
sift = cv2.SIFT_create()
surf = cv2.xfeatures2d.SURF_create()
orb = cv2.ORB_create()# 检测并绘制特征点
detect_and_draw_keypoints(image, sift, 'SIFT')
detect_and_draw_keypoints(image, surf, 'SURF')
detect_and_draw_keypoints(image, orb, 'ORB')8.我们发现 ORB 特征点在图像中分布不够均匀,你是否能够找到或提出一种 ORB特征均匀提取策略?
ORB特征点分布不均匀的问题可以通过以下策略来改善:
- 使用金字塔: 通过构建金字塔,在不同尺度上提取特征点,有助于提高特征点的均匀分布。
- 调整尺度参数: 调整ORB算法的尺度参数,可以控制特征点在图像中的分布密度。
- 非极大值抑制: 在ORB特征提取过程中,可以使用非极大值抑制(NMS)来限制特征点的数量,避免在局部区域提取过多的特征点。
以下是一个示例,使用ORB算法并结合上述策略来提取均匀分布的特征点:
import cv2
import numpy as np
import matplotlib.pyplot as pltdef detect_and_draw_keypoints(image, orb, name):keypoints = orb.detect(image, None)keypoints = sorted(keypoints, key=lambda x: -x.response)[:1000] # 非极大值抑制,保留前1000个关键点image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))plt.title(f"{name} Keypoints")plt.show()# 读取图像
image = cv2.imread('your_image_path.jpg')# 创建ORB检测器
orb = cv2.ORB_create()# 检测并绘制特征点
detect_and_draw_keypoints(image, orb, 'ORB')9.除本章介绍的基于计算特征向量欧几里得距离的匹配算法,你还能找到哪些其他的匹配算法?快速近似近邻算法(FLANN)是一种常用的匹配方法,研究 FLANN 为何能够快速处理匹配问题? 除 FLANN 外,还有哪些方法可以加速匹配的手段?
除了基于欧几里得距离的匹配算法,还有以下一些常见的匹配算法:
- 汉明距离匹配: 用于二进制特征描述子的匹配,如BRIEF和ORB。
- 最近邻搜索(Nearest Neighbor Search): 在特征空间中查找最近邻的点,常用的算法包括KD树和球树。
- 基于词袋模型的匹配: 将图像特征表示为词袋模型,通过词袋模型中的词汇进行匹配。
快速近似近邻算法(FLANN) 是一种用于加速最近邻搜索的方法。它采用了树结构(如KD树)来组织数据,以实现高效的最近邻搜索。FLANN的优势在于它能够在大规模数据集上快速进行近似最近邻搜索,从而加速匹配过程。
其他加速匹配的方法包括:
- GPU加速: 利用图形处理单元(GPU)进行并行计算,加速特征匹配算法的执行。
- 局部敏感哈希(Locality-Sensitive Hashing,LSH): 通过哈希函数将相似的特征点映射到相同的桶中,从而实现快速的最近邻搜索。
- 分布式计算: 使用分布式计算框架,如Apache Spark,对大规模数据集进行并行化处理,加速匹配过程。
10.在特征点匹配的过程中,难免存在误匹配的问题,如果保留了这些错误匹配,会对后续工作(如三维重建、目标识别、运动跟踪)产生什么影响? 你还能想到哪些避免误匹配的方法?
保留误匹配可能会对后续工作产生以下影响:
- 降低精度: 误匹配会引入噪声,降低了三维重建或目标识别的精度。
- 影响鲁棒性: 误匹配可能导致对物体运动或形状变化的不稳定性,影响运动跟踪的鲁棒性。
- 增加计算负担: 误匹配会增加后续处理步骤的计算负担,降低系统的效率。
避免误匹配的方法包括:
- 使用更具判别性的描述子: 选择具有更好区分性的特征点描述子,如使用更长的BRIEF描述子或使用更高维度的特征向量。
- 几何验证: 利用匹配的特征点之间的几何关系,进行RANSAC(随机抽样一致)等几何验证方法,剔除误匹配。
- 使用多传感器信息: 结合其他传感器信息,如深度信息或惯性传感器,提高对误匹配的鲁棒性。
- 阈值筛选: 根据匹配的相似度或距离设置合适的阈值,筛选出高质量的匹配,剔除可能的误匹配。
- 人工辅助: 在关键场景中,可以进行手动标定或利用用户交互来消除误匹配。
大家好,我是xwhking,一名技术爱好者,目前正在全力学习 Java,前端也会一点,如果你有任何疑问请你评论,或者可以加我QQ(2837468248)说明来意!希望能够与你共同进步