一、目录
- 模型参数单位
- 内存计算案例
- 显卡算力
- 推理显存计算
- 训练显存计算
- huggface 官网计算 模型推理/训练 需要的显存
- 大模型输入长度与显存的关系
- 大模型推理 多线程与显存的关系
参考:https://blog.csdn.net/Johntill/article/details/132629075
二、实现
-
模型参数单位
“10b”、“13b”、"70b"等术语通常指的是大型神经网络模型的参数数量。“10b” 意味着模型有大约 100 亿个参数。 -
内存计算案例
● fp32 精度,一个参数需要 32 bits, 4 bytes.
● fp16 精度,一个参数需要 16 bits, 2 bytes.
● int8 精度,一个参数需要 8 bits, 1 byte.
内存分配: 1.模型参数 2. 梯度 3.优化器参数。 -
显卡算力
显卡算力是什么?
显卡算力是指显卡能够在给定时间内完成多少次浮点运算。它用于评估显卡的性能。通常被表示为每秒执行的浮点运算次数,也称为 FLOPS(Floating Point Operations Per Second)。
计算显卡算力涉及到几个因素。首先,需要知道显卡的核心数量、时钟速度和每个核心的浮点运算单元数量。然后,将这些因素结合在一起,使用以下公式计算显卡算力:
显卡算力 = 核心数量 x 时钟速度 x 浮点运算单元数量
例如,如果显卡具有1280个核心,时钟速度为1400 MHz,每个核心具有两个浮点运算单元,则该显卡的算力为
算力 = 1280 x 1400 x 2 = 3.584 TFLOPS -
推理显存计算
Llama-2-7b-hf 为例,全精度模型参数是float32类型:
1b(10亿)个模型参数,约占用4G显存(实际大小:10^9 * 4 / 1024^3 ~= 3.725 GB),那么LLaMA的参数量为7b,那么加载模型参数需要的显存为:3.725 * 7 ~= 26.075 GB -
训练显存计算
大小=模型参数占用+梯度占用+优化器占用+CUDA kernel占用
LLaMA-6B为例:
模型参数:等于参数量每个参数所需内存。
对于 fp32,LLaMA-6B 需要 6B4 bytes = 24GB内存
对于 int8,LLaMA-6B 需要 6B1 byte = 6GB
梯度:同上,等于参数量每个梯度参数所需内存。
对于 fp32,LLaMA-6B 需要 6B4 bytes = 24GB内存
对于 int8,LLaMA-6B 需要 6B1 byte = 6GB
优化器参数:不同的优化器所储存的参数量不同。
对于常用的 AdamW 来说,需要储存两倍的模型参数(用来储存一阶和二阶momentum)。
fp32 的 LLaMA-6B,AdamW 需要 6B8 bytes = 48 GB
int8 的 LLaMA-6B,AdamW 需要 6B2 bytes = 12 GB
除此之外,CUDA kernel也会占据一些 RAM,大概 1.3GB 左右,查看方式如下。
综上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB+6GB+12GB+1.3GB = 25.3GB 左右 -
huggface 官网计算 推理/训练 需要的显存
https://huggingface.co/spaces/hf-accelerate/model-memory-usage -
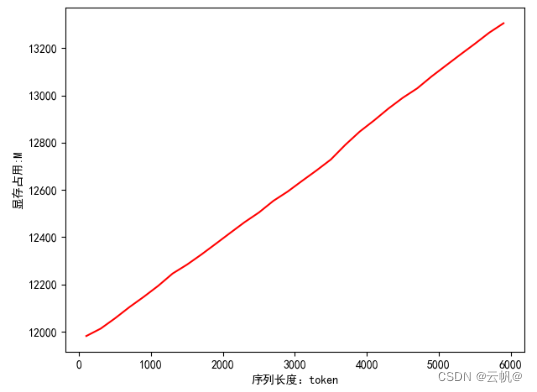
大模型输入长度与显存的关系
当前程序从启动到目前 查看显存最大占用情况:torch.cuda.max_memory_allocated("cuda:0")/1024**2
以chatglm2为例:
from transformers import AutoModel, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("../chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("../chatglm2-6b", trust_remote_code=True).half().to(torch.device("cuda:0"))
model = model.eval()
res=[]
for i in range(100,6000,200):prompt=text[:i]max_length = len(prompt)top_p = 1temperature = 0.8response, history=model.chat(tokenizer, prompt, [], max_length=max_length, top_p=top_p,temperature=temperature)print(torch.cuda.max_memory_allocated("cuda:0")/1024**2) #默认返回当前程序从开始所占用的最大显存print("=============================")res.append(torch.cuda.max_memory_allocated("cuda:0")/1024**2)
#查看显存
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"]
x=[i for i in range(100,6000,200)]
#服务器无法绘图,进行拷贝查看y=res
y=[11981.630859375, 12013.05419921875, 12056.77099609375, 12104.171875, 12147.87890625, 12194.2587890625, 12246.16259765625, 12283.880859375, 12326.7431640625, 12372.0830078125, 12418.00439453125, 12463.4248046875, 12504.59521484375, 12553.66162109375, 12593.26708984375, 12638.40234375, 12682.5390625, 12728.97021484375, 12790.80615234375, 12846.7744140625, 12894.125, 12944.5283203125, 12990.2294921875, 13030.0068359375, 13080.41064453125, 13126.8134765625, 13173.08203125, 13218.35302734375, 13265.4736328125, 13305.5966796875]
plt.plot(x,y,c="r")
plt.ylabel("显存占用:M")
plt.xlabel("序列长度:token")
plt.show()
8. 大模型推理 多线程与显存的关系
print(torch.cuda.memory_allocated("cuda:0")/1024**2) #torch 模型占用显存
print(torch.cuda.max_memory_allocated("cuda:0")/1024**2) #torch 模型占用显存最大值
显存大小=torch.cuda.memory_allocated("cuda:0")/1024**2 + (torch.cuda.max_memory_allocated("cuda:0")/1024**2)* 线程数