分析慢 SQL
如何定位慢 SQL 呢?
可以通过 slow log 来查看慢SQL,默认的情况下,MySQL 数据库是不开启慢查询日志(slow query log)。所以我们需要手动把它打开。
查看下慢查询日志配置,我们可以使用 show variables like 'slow_query_log%' 命令,如下:

- slow query log:表示慢查询开启的状态。
- slow_query_log_file:表示慢查询日志存放的位置。
还可以使用 show variables like 'long_query_time' 命令,查看超过多少时间,才记录到慢查询日志,如下:
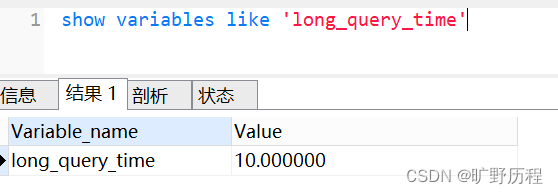
- long_query_time:表示查询超过多少秒才记录到慢查询日志。
可以通过慢查询日志,定位那些执行效率较低的 SQL 语句,重点关注分析。
explain 查看分析 SQL 的执行计划
当定位出查询效率低的 SQL 后,可以使用 explain 查看 SQL 的执行计划。
当 explain 与 SQL 一起使用时,MySQL 将显示来自优化器的有关语句执行计划的信息。即 MySQL 解释了它将如何处理该语句,包括有关如何连接表以及以何种顺序连接表等信息。
一条简单SQL,使用了explain的效果如下:

一般来说,我们需要重点关注id、type、key、rows、filtered、extra。
profile 分析执行耗时
explain 只是看到 SQL 的预估执行计划,如果要了解SQL真正的执行线程状态及消耗的时间,需要使用 profiling。开启 profiling 参数后,后续执行的SQL语句都会记录其资源开销,包括IO、上下文切换、CPU、内存等等,我们可以根据这些开销进一步分析当前慢 SQL 的瓶颈再进一步进行优化。
profiling 默认是关闭的,我们可以使用 show variables like '%profil%' 查看是否开启,如下:

可以使用 set profiling=ON 开启。开启后,可以运行几条 SQL,然后使用 show profiles 查看一下:
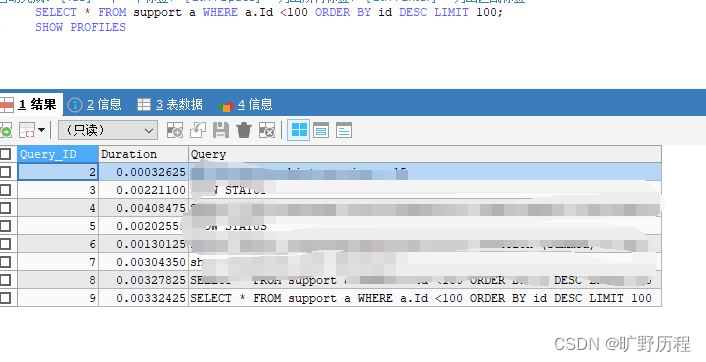
show profiles会显示最近发给服务器的多条语句,条数由变量profiling_history_size定义,默认是 15。如果我们需要看单独某条 SQL 的分析,可以show profile查看最近一条 SQL 的分析。也可以使用show profile for query id(其中 id 就是 show profiles 中的 QUERY_ID)查看具体一条的 SQL 语句分析。

除了查看 profile ,还可以查看 cpu 和 io,如上图。
Optimizer Trace 分析详情
profile 只能查看到 SQL 的执行耗时,但是无法看到 SQL 真正执行的过程信息,即不知道 MySQL 优化器是如何选择执行计划的。这时候还可以使用 Optimizer Trace,它可以跟踪执行语句的解析优化执行的全过程。
可以使用 set optimizer_trace="enabled=on" 打开开关,接着执行要跟踪的 SQL,最后执行 select * from information_schema.optimizer_trace 跟踪,如下:

大家可以查看分析其执行树,会包括三个阶段:
- join_preparation:准备阶段
- join_optimization:分析阶段
- join_execution:执行阶段
由于 trace 中的内容太长,就不贴出来了。
采取措施
- 多数慢 SQL 都跟索引有关,比如不加索引、索引不生效、不合理等,这时候,我们可以优化索引。
- 优化 SQL 语句,比如一些 in 元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询。
- SQl 若不能继续优化时可以改用 ES 的方式,或者数仓。
- 如果单表数据量过大导致慢查询,则可以考虑分库分表。
- 如果数据库在刷脏页导致慢查询,考虑是否可以优化一些参数。
- 如果存量数据量太大,考虑是否可以让部分数据归档。