案例说明
将Excel数据导入Postgresql,并实现常见统计(数据示例如下)
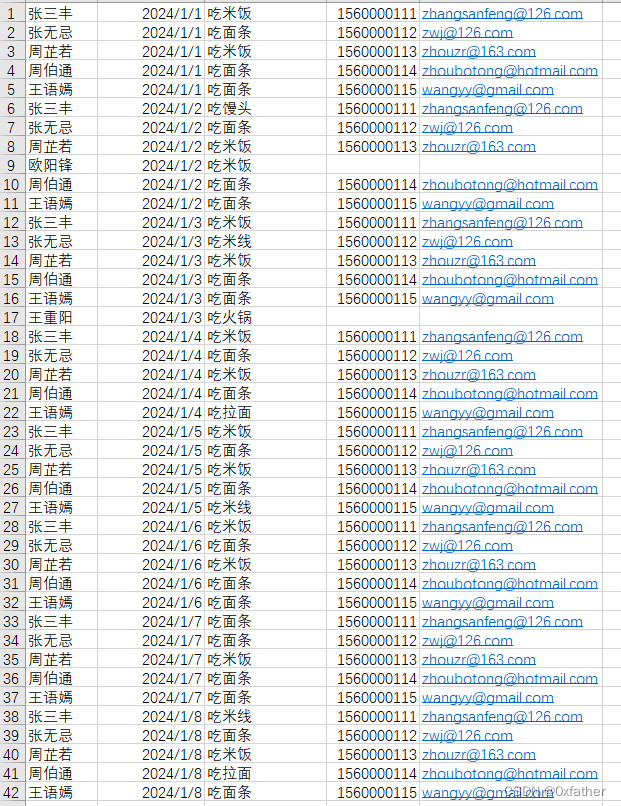
导入Excel数据到数据库
使用Navicat工具连接数据库,使用导入功能可直接导入,此处不做过多介绍,详细操作请看下图:
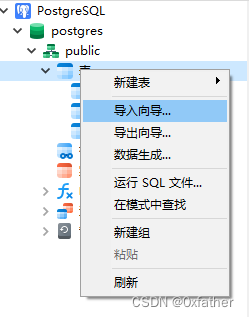
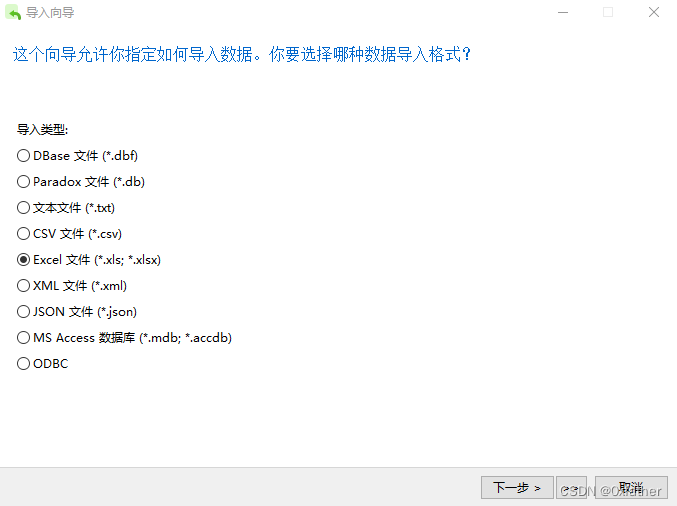
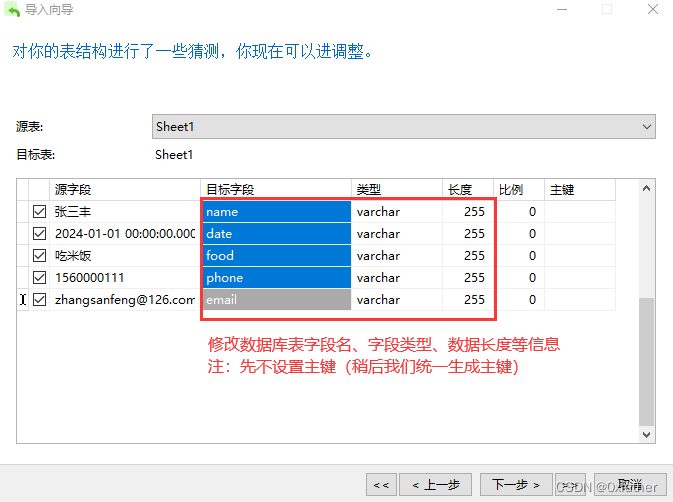
点击“下一步”完成导入操作(导入完成后,我们将表名命名为“eatLog”)。
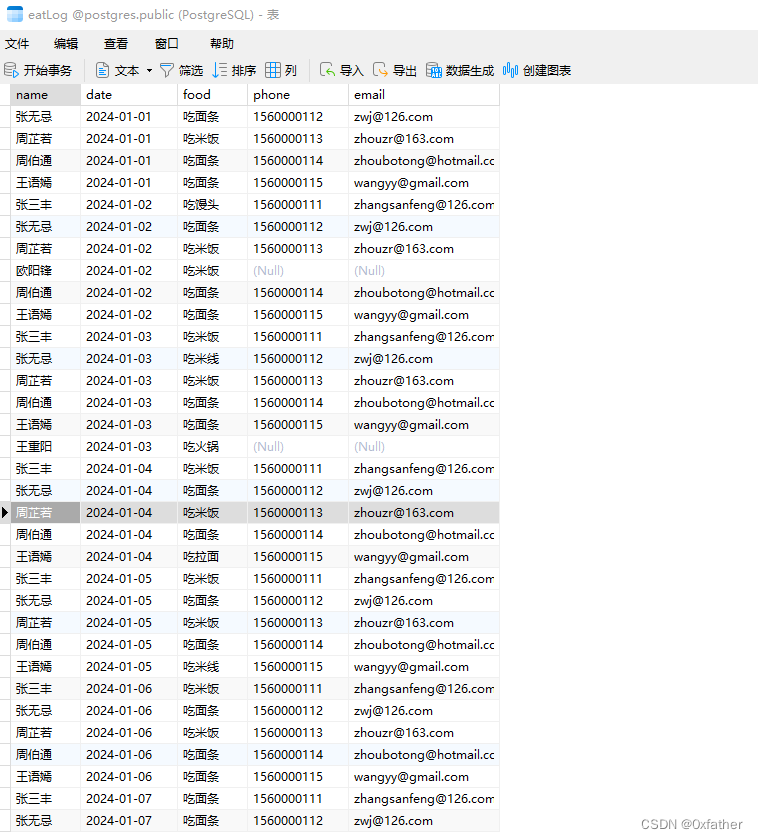
给数据表添加自增主键
导入的数据是没有主键的,这样不利于我们对数据的管理(如:在查询时,没有数据主键不能对数据进行修改等),因此我们需要扩展主键字段
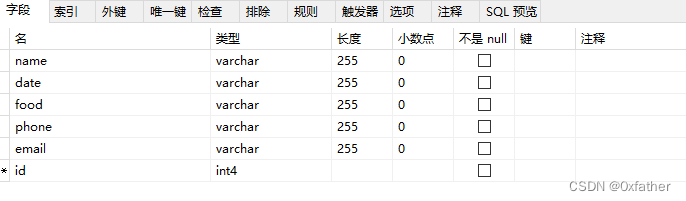
添加主键字段
修改表设计,增加主键id字段(此时请勿添加主键约束)
创建自增序列
Postgresql没有像Oracle、MySQL那样的默认自增序列,因此要实现自增,可以通过自定义序列来实现
create SEQUENCE seq_eatlog_id
start with 1
increment by 1
no MINVALUE
no MAXVALUE
cache 1;语句说明:
seq_eatlog_id:自定义的自增序列名称,根据自己需要命名
start with 1:序列从1开始
increment 1:序列自增步长为1(每次加1)
no MINVALUE:没有最小值约束
no MAXVALUE:没有最大值约束
cache 1:在数据库中始终缓存下一个序列
更新序列到数据表
update "eatLog"
set id = nextval('seq_eatlog_id')nextval函数可获取下一个序列,可使用 select nextval('seq_eatlog_id') 来查询下一个序列。
注:调用一次nextval(),序列将被消费掉,因此不要轻易使用nextval()来查询序列,避免序列顺序混乱。
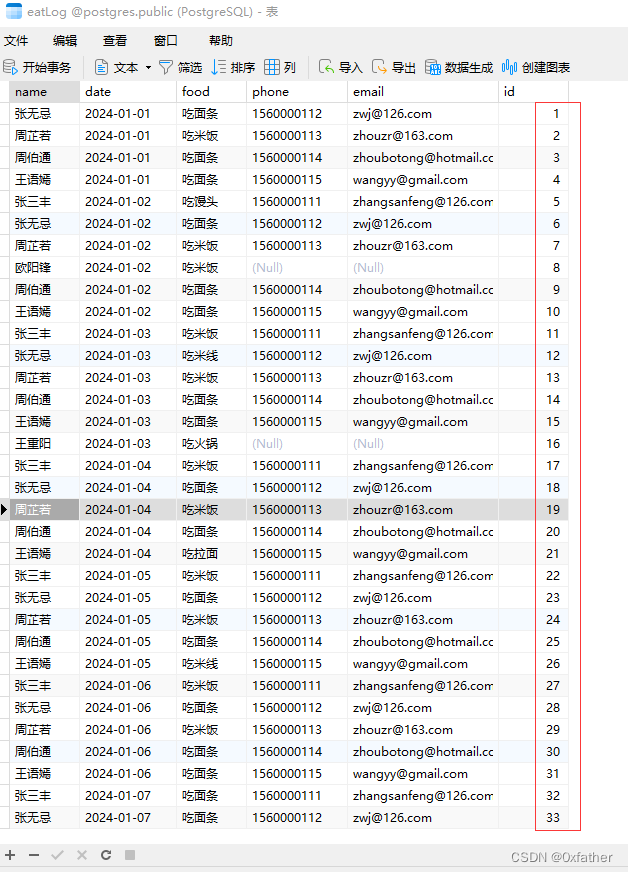
此时id已填充为自增的序列值(此时可以再修改表设计,给该表增加主键非空约束,顺手把date字段的数据类型修改为日期类型,数据会自动转换)
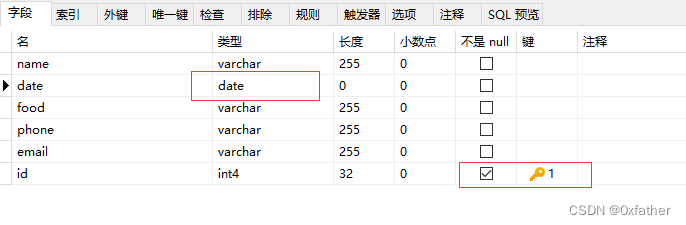
给表主键增加自增序列
上面将主键已填充,但是在新增数据时,仍需手动添加主键,否则会提示主键为空问题。
insert into "eatLog" values('乔峰',to_date('2024-01-04','YYYY-MM-DD'),'吃拉面',null,'xiaofeng@tianlong.com');题外话:
Postgresql的表名和字段都是区分大小写的,因此针对驼峰名称必须添加双引号进行操作,否则会提示表或字段不存在
全大写或全小写的表名可以省略双引号

因此需要给主键id字段添加自增序列,以便后续新增数据。
alter table "eatLog" alter COLUMN id set DEFAULT nextval('seq_eatlog_id');
再次执行插入语句,即可添加成功(以后添加数据无需再管主键id字段了)。

常见日期操作
获取周
查询数据中的日期在当年第几周,并将周信息保存到数据库中,以便后续按周统计
表设计中增加“周(week)”字段
select date_part('week',date::timestamp) week from "eatLog";将周信息更新到表中
update "eatLog"
set week = date_part('week',date::timestamp)获取月
查询月份方式一(格式化字符方式):
select to_char(date,'MM') from "eatLog";查询月份方式二(日期函数获取):
select date_part('month',date::timestamp) from "eatLog";查询月份方式三(提取函数获取):
select extract(month from date) as month from "eatLog";查询部分时段数据
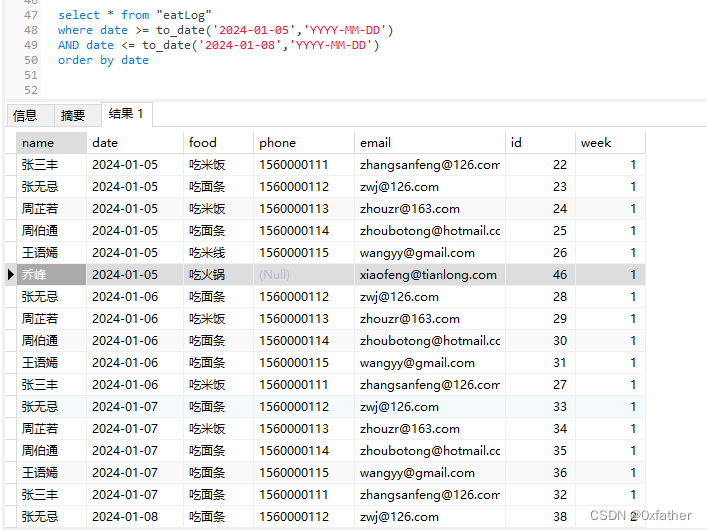
select * from "eatLog"
where date >= to_date('2024-01-05','YYYY-MM-DD')
AND date <= to_date('2024-01-08','YYYY-MM-DD')
and phone is not null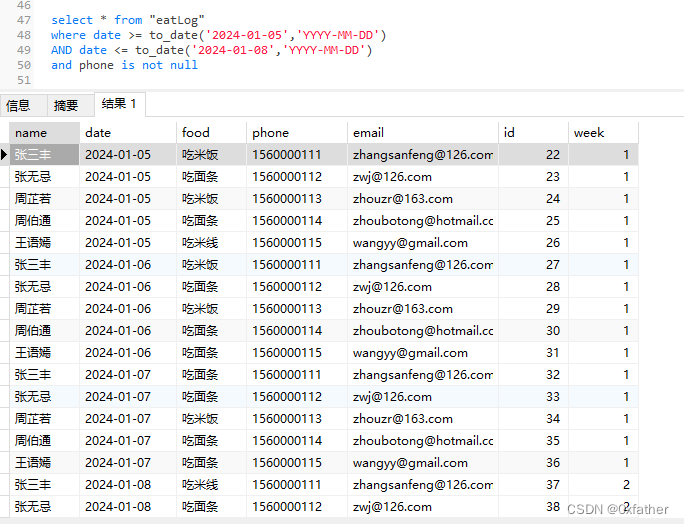
数据脱敏
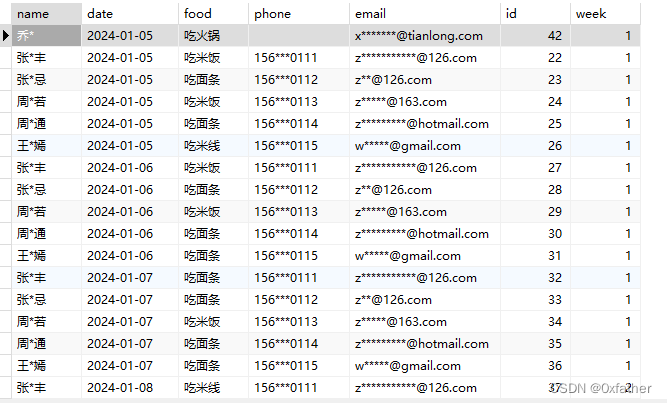
姓名脱敏
使用“*”号代替姓名中除第一个字和最后一个字的所有字符,两个字的名字仅替换最后一个字。
----三字及以上姓名脱敏
update "eatLog"
set name = concat(left(name,1),repeat('*', length(name) - 2),right(name,1)
)
where length(name) > 2;----两字姓名脱敏
update "eatLog"
set name = concat(left(name,1),repeat('*', length(name) - 1)
)
where length(name) = 2;concat()函数:用于拼接字符串
left()函数:用于截取字符串,指定从左截取多少位
right()函数:用于截取字符串,指定从右截取多少位
repeat()函数:用于替换字符串,指定替换多少位
手机号脱敏
保留手机号前三位和后四位,其他信息用“*”号代替
update "eatLog"
set phone = concat(left(phone,3),repeat('*',length(phone) - 7),right(phone,4)
)
注:身份证、银行卡脱敏思路相同
邮箱脱敏
update "eatLog"
set email = concat(left(email,1),repeat('*',position('@' in email) - 2),substring(email from position('@' in email))
)
substring()函数:截取字符串
position()函数:定位字符或字符串所在下标位置
数据统计
分组统计
根据周、饮食类型分组查询
select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
行转列统计
统计所有数据
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
group by extract(week from t1.date),t1.food
order by extract(week from t1.date),t1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week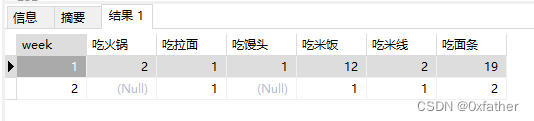
行转列使用crosstab(sql1,sql2)函数
参数说明:
sql1:统计数据的语句
sql2:行转列的列查询SQL
crosstab的sql1返回值中必须有且只有三个字段:
第一个字段表示行ID(可由分组生成),
第二个字段表示分组目录(即待转换列),
第三个字段表示统计数据
as中的内容是转换的列名及列值类型,此处的列明必须完全列出,与实际数据相符,否则会报错误。
注一:
postgresql默认未安装扩展函数,因此要使用crosstab()函数,必须先启用扩展
使用命令:
CREATE EXTENSION IF NOT EXISTS tablefunc;
注二:
行转列时,sql2参数必须进行排序,若不排序,虽然能转成功,但是会发现数据可能已经混乱,postgresql在行转列时,通过as中指定顺序匹配,而非是通过字段名称匹配,所以orader by固定数据位置,很容易造成匹配错误(as中的顺序可以使用sql2执行之后确认是否一致)
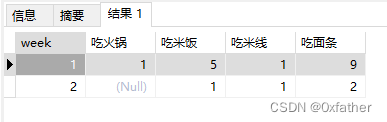
统计部分数据
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1)
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date),t1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week
在crosstab的sql参数中,若已经使用了单引号('),则需要使用两个单引号('')表示一个单引号,用于转义,否则SQL执行报错
另外,SQL查询时,若表名或字段使用驼峰时,必须使用双引号修饰,否则会找不到对象(Postgresql严格区分大小写,全大写或全小写时可以省略双引号修饰)
自定义统计列
select * from crosstab('select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)',$$values('吃火锅'),('吃米饭'),('吃米线'),('吃面条')$$
)
as (week int,吃火锅 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week可通过$$values()$$来指定转哪些列,注意values()的顺序必须与as中的顺序一致
其他操作
计算精度问题
试想,我们的数据是统计每周的饮食统计,那每种饮食在每周占比是多少呢?
select m1.week,m1.food,m1.food_count, (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date('2024-01-05','YYYY-MM-DD')AND t2.date <= to_date('2024-01-08','YYYY-MM-DD')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date)) week_count
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date('2024-01-05','YYYY-MM-DD')
AND t1.date <= to_date('2024-01-08','YYYY-MM-DD')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food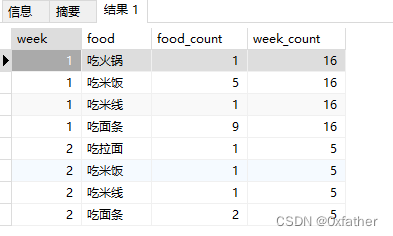
计算占比时请注意精度问题
select m1.week,m1.food,round(m1.food_count::numeric / (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date('2024-01-05','YYYY-MM-DD')AND t2.date <= to_date('2024-01-08','YYYY-MM-DD')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date))::numeric * 100,2) "rate(%)"
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date('2024-01-05','YYYY-MM-DD')
AND t1.date <= to_date('2024-01-08','YYYY-MM-DD')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food
Postgresql在计算时默认使用int来计算,因此不会取小数,若需要保留小数,需指明参加运算的字段类型,可通过“::numeric”来指明运算字段为数字型,这样运算结果可以保留小数
要具体精确到多少位,需要使用round()函数
行转列后效果
select * from crosstab('select m1.week,m1.food,round(m1.food_count::numeric / (select count(1) week_countfrom "eatLog" t2where t2.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')AND t2.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')and extract(week from t2.date) = m1.weekgroup by extract(week from t2.date)order by extract(week from t2.date))::numeric * 100,2) "rate(%)"
from
(
select extract(week from t1.date) as week,t1.food,count(1) food_count
from "eatLog" t1
where t1.date >= to_date(''2024-01-05'',''YYYY-MM-DD'')
AND t1.date <= to_date(''2024-01-08'',''YYYY-MM-DD'')
group by extract(week from t1.date),t1.food
order by extract(week from t1.date)
) m1
order by m1.week,m1.food','select food from "eatLog" group by food order by food'
)
as (week int,吃火锅 NUMERIC,吃拉面 NUMERIC,吃馒头 NUMERIC,吃米饭 NUMERIC,吃米线 NUMERIC,吃面条 NUMERIC
)
order by week
以上,就是Postgresql在使用中常见操作及示例说明,希望对您有所帮助。