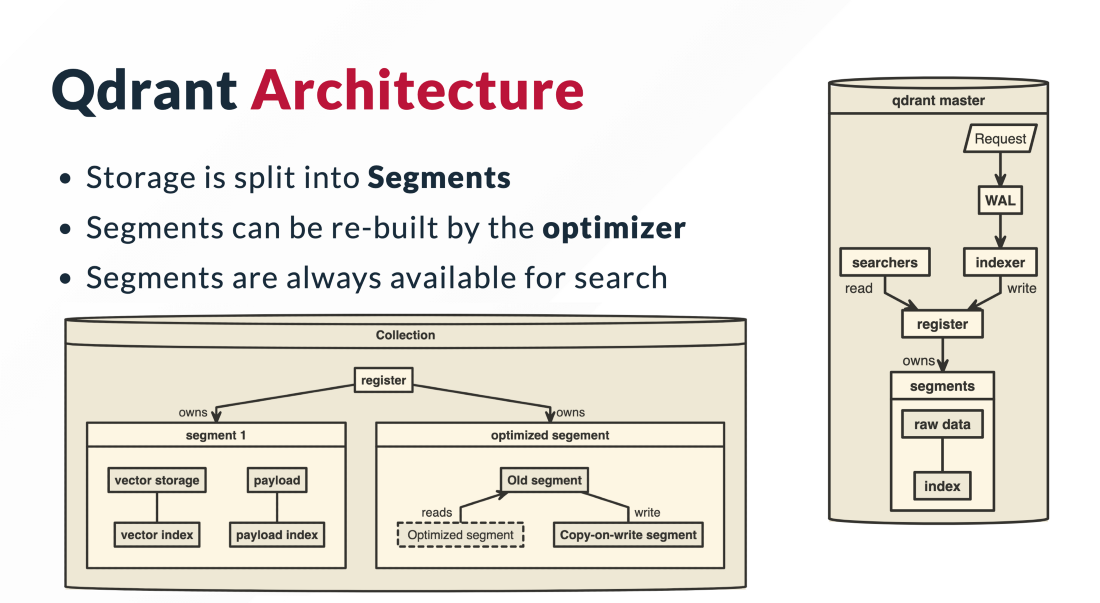
一、参考资料
目标检测:SPP-net
SPP原理及实现
金字塔池化系列的理解SPP、ASPP
SPP,PPM、ASPP和FPN结构理解和总结
二、空间金字塔池化(SPP)
原始论文:[1]
1. 引言
传统的卷积神经网络中,池化层通常采用固定的池化层级和固定的池化大小,这种方法对于不同大小的输入图像会导致信息的丢失,从而影响模型的准确性。而SPP空间金字塔池化方法则可以自适应地对不同大小的输入图像进行池化操作,从而能够更好地保留图像的信息。

2. SPP简介
2.1 SPP的概念
空间金字塔池化(Spatial Pyramid Pooling,SPP)是一种用于处理不同尺寸输入的卷积神经网络中的池化方法。它通过将不同大小的池化层级进行组合,从而能够对任意大小的输入图像进行池化操作,从而提高了网络的灵活性和泛化能力。
空间金字塔的基本思想是:在网络内设计参数不同的并行支路,每条支路基于各自的感受野提取不同空间尺度下的特征图,最后将所有分支的特征图进行融合。
2.2 SPP的原理
SPP空间金字塔池化方法的主要思想是将输入图像分成不同的层级,每一层级采用不同大小的池化窗口进行池化操作,然后将所有层级的池化结果拼接(concatenate)在一起,作为网络的特征表示。这样做的好处是,通过组合不同大小的池化层级,SPP空间金字塔池化方法可以对不同大小的输入图像进行池化操作,从而能够更好地保留图像的信息。

2.3 SPP的作用
在含有FC层的网络中,利用SPP改进输入需要固定尺寸的问题。因为带有FC层的网络结构结构都需要固定输入图像的尺度。
2.4 SPP的应用
//TODO
Yolov4的Neck结构采用了SPP模块。
3. SPP结构

如上图所示,最左边的图表示卷积操作得到的256维特征图,即对于每个区域厚度都为256,通过三种方式进行池化:
- 直接对整个特征图池化,每一维得到一个池化后的值,构成一个1x256的向量;
- 将特征图分成2x2共4份,每份单独进行池化,得到一个1x256的向量,最终得到2x2=4个1x256的向量;
- 将特征图分成4x4共16份,每份单独进行池化,得到一个1x256的向量,最终得到4x4=16个1x256的向量;
将三种划分方式池化得到的结果进行拼接(concatenate),得到(1+4+16)x256=21x256的特征。由图中可以看出,整个过程对于输入的尺寸大小完全无关,因此可以处理任意尺寸的候选框。
空间池化层实际上就是一种自适应的层,这样无论你输入的尺寸是什么,输出都是固定的。
4. (PyTorch)代码实现
github代码:sppnet-pytorch
4.1 SPP
函数功能:构建SPP结构。
import mathdef spatial_pyramid_pool(self,previous_conv, num_sample, previous_conv_size, out_pool_size):'''previous_conv: a tensor vector of previous convolution layernum_sample: an int number of image in the batchprevious_conv_size: an int vector [height, width] of the matrix features size of previous convolution layerout_pool_size: a int vector of expected output size of max pooling layerreturns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling''' # print(previous_conv.size())for i in range(len(out_pool_size)): # out_pool_size=[4, 2, 1]# print(previous_conv_size)# 计算池化块的尺寸, pooling_size=(h_wid, w_wid)h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))# 计算padding的尺寸, padding=(h_pad, w_pad)h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)/2w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)/2# 实例化MaxPool2dmaxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))# 执行最大池化操作,输出特征图的通道数不变, 尺寸变为(4, 4, 256), (2, 2, 256), (1, 1, 256)x = maxpool(previous_conv)if(i == 0):# reshape变为2D,即(4, 4, 256) -> (1, 4*4*256)spp = x.view(num_sample,-1)# print("spp size:",spp.size())else:# 将所有的最大池化结果拼接(concatenate)到第一个池化结果的尾部,组成一个更高维度的池化结果# 输入特征图: (1, 4*4*256) concat (1, 2*2*256) concat (1, 1*1*256)# 输出特征图: (1, (4*4+2*2+1*1)*256), 即(1, 5376)# print("size:",spp.size())spp = torch.cat((spp,x.view(num_sample,-1)), 1)return spp
4.2 CNN with SPP
函数功能:搭建一个带有SPP结构的CNN网络模型。
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):'''A CNN model which adds spp layer so that we can input multi-size tensor'''def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):super(SPP_NET, self).__init__()self.gpu_ids = gpu_idsself.output_num = [4,2,1]self.conv1 = nn.Conv2d(input_nc, ndf, 4, 2, 1, bias=False)self.conv2 = nn.Conv2d(ndf, ndf * 2, 4, 1, 1, bias=False)self.BN1 = nn.BatchNorm2d(ndf * 2)self.conv3 = nn.Conv2d(ndf * 2, ndf * 4, 4, 1, 1, bias=False)self.BN2 = nn.BatchNorm2d(ndf * 4)self.conv4 = nn.Conv2d(ndf * 4, ndf * 8, 4, 1, 1, bias=False)self.BN3 = nn.BatchNorm2d(ndf * 8)self.conv5 = nn.Conv2d(ndf * 8, 64, 4, 1, 0, bias=False)self.fc1 = nn.Linear(10752,4096)self.fc2 = nn.Linear(4096,1000)def forward(self,x):x = self.conv1(x)x = self.LReLU1(x)x = self.conv2(x)x = F.leaky_relu(self.BN1(x))x = self.conv3(x)x = F.leaky_relu(self.BN2(x))x = self.conv4(x)# x = F.leaky_relu(self.BN3(x))# x = self.conv5(x)spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)# print(spp.size())fc1 = self.fc1(spp)fc2 = self.fc2(fc1)s = nn.Sigmoid()output = s(fc2)return output
三、空洞空间金字塔池化(ASPP)
原始论文:[2]
1. 引言
在语义分割任务中,利用ASPP在不丢失信息时,组合不同大小感受野的语义信息,提高分割精度。
在图像分割领域(以FCN为例),图像输入到CNN中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野。但是由于图像分割预测是 pixel-wise 的输出,所以要将pooling后较小的图像尺寸 upsampling 到原始的图像尺寸进行预测。简单理解,图像分割FCN在pooling阶段减小图像尺寸增大感受野,在upsampling阶段扩大图像尺寸减小了感受野。在先减小再增大尺寸的过程中,导致了图像信息的丢失。为了解决该问题,DeepLab v2提出了ASPP模块,通过四个并行的膨胀卷积层来捕捉多尺度信息,可以在不丢失分辨率(不进行下采样)的情况下,组合不同大小感受野的语义信息,提高分割精度。
2. ASPP的概念
简单理解, ASPP = SPP+Dilated Convolution。
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)结合了SPP和 Dilated Convolution(中文称作”膨胀卷积“,或”空洞卷积“)的思想。结合Dilated Convolution,可以在不丢失分辨率(不进行下采样)的情况下,扩大卷积核的感受野。ASPP可以认为是SPP在语义分割任务中的应用。
3. 通俗理解ASPP

在输入特征图(input Feature Map )上并联四个分支,每个分支的第一层使用不同膨胀率(dilation rate)的 Dilated Convolution,使得每个分支的感受野不同,从而具有解决目标多尺度的问题。这里设计不同采样率的膨胀卷积来捕捉多尺度信息,但采样率并不是越大越好。因为膨胀率越大,导致滤波器会跑到padding上,产生无意义的权重,因此需要选择合适的采样率。
4. ASPP结构
这里,以DeepLab v3论文中的ASPP为例,详细介绍ASPP的结构:

对于输入input:
Conv1x1:用一个1×1的卷积对input进行降维;Conv3x3, rate=6:用一个padding为6,dilation rate为6,卷积核大小为3×3的卷积层进行卷积;注意:padding=dilation rate,参阅下文中的代码实现。Conv3x3, rate=12:用一个padding为12,dilation rate为12,卷积核大小为3×3的卷积层进行卷积;Conv3x3, rate=18:用一个padding为18,dilation rate为18,卷积核大小为3×3的卷积层进行卷积;Pool(1x1)——》Conv1x1——》upsample:首先,用一个尺寸为input大小的池化层将input池化为尺寸1×1的特征图,然后用一个1×1的卷积对特征图进行降维,最后 上采样(双线性插值) 恢复原始输入大小。
最后将这五层的输出进行concat,并用1×1卷积层降维至给定通道数,得到最终输出。
可以看到,ASPP本质由一个1×1的卷积 (最左侧绿色)+ 池化金字塔(中间三个蓝色) + ASPPPooling(最右侧三层)组成。而ASPPConv层的dilation rate是可以自定义的,从而实现自由的多尺度特征提取。
5. (PyTorch)代码实现
SOURCE CODE FOR TORCHVISION.MODELS.SEGMENTATION.DEEPLABV3
Pytorch-torchvision源码解读:ASPP
以DeepLab v3中的源代码为例,介绍ASPP的代码实现。
5.1 ASPPConv
函数功能:计算
Dilated Convolution,执行Conv3x3, rate=6/12/18过程。输入:输入特征图,(N, in_channels, H, W)
输出:输出特征图,(N, out_channels, H, W),输出尺寸与输入特征图一致
class ASPPConv(nn.Sequential):def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:"""in_channels: 输入通道数out_channels: 输出通道数dilation: 膨胀率padding=dilation"""modules = [nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),]super().__init__(*modules)
通过 Conv3x3, rate=6/12/18 三个 Dilated Convolution 得到的 输出特征图尺寸相等,且都等于输入特征图尺寸,关于 Dilated Convolution 的计算公式,可参阅另一篇博客:深入浅出理解Dilated Convolution(空洞卷积,膨胀卷积)
5.2 ASPPPolling
函数功能:计算池化,执行
Pool(1x1)——》Conv1x1——》upsample过程。输入:输入特征图,(N, in_channels, H, W)
输出:输出特征图,(N, out_channels, H, W),输出尺寸与输入特征图一致
-
首先,通过自适应均值池化(
AdaptiveAvgPool2d)将各通道的特征图分别压缩至1×1,从而提取各通道的特征,进而获取全局的特征。nn.AdaptiveAvgPool2d(1)所谓自适应均值池化,其自适应的地方在于不需要指定
kernel size和stride,只需要指定最后的输出尺寸(这里为1×1)。 -
然后,用一个1×1的卷积,对上一步获取的特征进行降维:
nn.Conv2d(in_channels, out_channels, 1, bias=False) -
最后,通过上采样恢复原始输入大小:
F.interpolate(x, size=size, mode="bilinear", align_corners=False)
完整源码如下:
class ASPPPooling(nn.Sequential):def __init__(self, in_channels: int, out_channels: int) -> None:super().__init__(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),)def forward(self, x: torch.Tensor) -> torch.Tensor:size = x.shape[-2:]for mod in self:x = mod(x)return F.interpolate(x, size=size, mode="bilinear", align_corners=False)
5.3 ASPP
函数功能:搭建ASPP的整体结构,并执行ASPP操作。
-
用1×1的卷积层,进行降维:
super(ASPP, self).__init__() modules = [] modules.append(nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())) -
用
ASPPConv构建池化金字塔。对于给定的膨胀因子atrous_rates,叠加相应的空洞卷积层,提取不同尺度下的特征:rates = tuple(atrous_rates) for rate in rates:modules.append(ASPPConv(in_channels, out_channels, rate)) -
添加
ASPPPooling层:modules.append(ASPPPooling(in_channels, out_channels)) -
输出层,用于对ASPP各层叠加后的输出,进行卷积操作,得到最终结果:
self.project = nn.Sequential(nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Dropout(0.5))
完整代码:
class ASPP(nn.Module):def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:"""in_channels: 输入通道数atrous_rates: dilation rateout_channels: 输出通道数,默认为"""super().__init__()modules = []modules.append(nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU()))rates = tuple(atrous_rates)for rate in rates:modules.append(ASPPConv(in_channels, out_channels, rate))modules.append(ASPPPooling(in_channels, out_channels))self.convs = nn.ModuleList(modules)self.project = nn.Sequential(nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Dropout(0.5),)def forward(self, x: torch.Tensor) -> torch.Tensor:_res = []for conv in self.convs:_res.append(conv(x))# (B, C, H, W), dim = 1, 按通道拼接res = torch.cat(_res, dim=1)return self.project(res)
注意:对于forward方法,其顺序执行ASPP的各层,将各层的输出按通道叠加,并通过输出层的 conv->bn->relu->dropout 降维至给定通道数,获取最终结果。
5.4 整体代码
# Dilated Convolution
class ASPPConv(nn.Sequential):def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:modules = [nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),]super().__init__(*modules)# Pool(1x1) -> 1*1 卷积 -> 上采样
class ASPPPooling(nn.Sequential):def __init__(self, in_channels: int, out_channels: int) -> None:super().__init__(nn.AdaptiveAvgPool2d(1), # 自适应均值池化nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),)def forward(self, x: torch.Tensor) -> torch.Tensor:# (N, C, H, W)size = x.shape[-2:] # (H, W)for mod in self:x = mod(x)# 上采样return F.interpolate(x, size=size, mode="bilinear", align_corners=False)# 整个ASPP结构
class ASPP(nn.Module):def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:super().__init__()modules = []# 1*1 卷积modules.append(nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU()))# 多尺度空洞卷积rates = tuple(atrous_rates)for rate in rates:modules.append(ASPPConv(in_channels, out_channels, rate))# 添加ASPPPoolingmodules.append(ASPPPooling(in_channels, out_channels))self.convs = nn.ModuleList(modules)# 输出层self.project = nn.Sequential(nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Dropout(0.5),)def forward(self, x: torch.Tensor) -> torch.Tensor:_res = []for conv in self.convs:_res.append(conv(x))# 对输出结果进行concatres = torch.cat(_res, dim=1)return self.project(res)
四、深度可分离金字塔池化(DSPP)
论文:[3]
深度可分离金字塔池化(depthwise separable pyramidal pooling,DSPP),本文以 SPEEP 论文为例介绍DSPP。
1. SPEED结构
SPEEP(Separable Pyramidal pooling EncodEr-Decoder)是基于Encoder-Decoder架构的单目深度估计网络模型。
SPEED结构,如下图所示:

2. SPEED encoder结构
DSPP Encoder结构,如下图所示:

3. DSPP结构
DSPP由4个分支构成,每个分支由1个平均池化层(Average pooling) 和1个深度可分离卷积层(Depthwise separable convolution,Separable Conv2D)组成。4个分支最后输出的特征图与原始输入特征图进行拼接(concatenate)。DSPP的结构,如下图所示:

如上图所示,原始输入特征图尺寸为(12, 16, 512),最后经过拼接的输出特征图尺寸为 (12, 16, 1024)。
4. (TensorFlow)代码实现
4.1 SPEED_Encoder
函数功能:构建 SPEED_Encoder结构。
def SPEED_Encoder(input_shape, alpha=1.0, depth_multiplier=1):img_input = layers.Input(shape=input_shape)# (192, 256, 3) -> (96, 128, 32)x = _conv_block(img_input, 32, alpha, strides=(2, 2))# (96, 128, 32) -> (96, 128, 64)x = _depthwise_conv_block(x, 64, alpha, depth_multiplier, block_id=1)# (96, 128, 64) -> (48, 64, 128)x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, strides=(2, 2), block_id=2)# (48, 64, 128) -> (48, 64, 128)x = _depthwise_conv_block(x, 128, alpha, depth_multiplier, block_id=3)# (48, 64, 128) -> (24, 32, 256)x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, strides=(2, 2), block_id=4)# (24, 32, 256) -> (24, 32, 256)x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=5)# (24, 32, 256) -> (12, 16, 256)x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, strides=(2, 2), block_id=6)# (12, 16, 256) -> (12, 16, 512)x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=7)# (12, 16, 512) -> (12, 16, 1024)x = depthwise_separable_pyramid_pooling(x, [2, 4, 6, 8], x.shape[1], x.shape[2], filters=128)# x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=8)# x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=9)# x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=10)# x = _depthwise_conv_block(x, 512, alpha, depth_multiplier, block_id=11)# (12, 16, 1024) -> (6, 8, 1024)x = _depthwise_conv_block(x, 1024, alpha, depth_multiplier, strides=(2, 2), block_id=12)# (6, 8, 1024) -> (6, 8, 256)x = _depthwise_conv_block(x, 256, alpha, depth_multiplier, block_id=13) # 1024model = Model(img_input, x, name='SPP_encoder')return model
4.2 DSPP
函数功能:构建DSPP的总体结构。
def depthwise_separable_pyramid_pooling(input_tensor, bin_sizes, w, h, filters):concat_list = [input_tensor]for bin_size in bin_sizes:x = tf.keras.layers.AveragePooling2D(pool_size=(w // bin_size, h // bin_size), strides=(w // bin_size, h // bin_size))(input_tensor)x = tf.keras.layers.SeparableConv2D(filters, 3, strides=1, padding='same')(x)x = tf.keras.layers.Lambda(lambda x: tf.image.resize(x, (w, h)))(x)concat_list.append(x)return tf.keras.layers.concatenate(concat_list)
4.3 AveragePooling2D
tf.keras.layers.AveragePooling2D
函数功能:进行平均池化操作。
for bin_size in bin_sizes:x = tf.keras.layers.AveragePooling2D(pool_size=(w // bin_size, h // bin_size), strides=(w // bin_size, h // bin_size))(input_tensor)
从AveragePooling2D函数参数中可知,pool_size=(w // bin_size, h // bin_size), strides=pool_size,已知 bin_size=[[2, 4, 6, 8]],则计算输出特征图尺寸为:
分支1:bin_size=2,pool_size= (12 // 2, 16 // 2) = (6, 8),平均池化后输出特征图尺寸(2, 2, 512)
分支2:bin_size=4,pool_size= (12 // 4, 16 // 4) = (3, 4),平均池化后输出特征图尺寸(4, 4, 512)
分支3:bin_size=6,pool_size= (12 // 6, 16 // 6) = (2, 2),平均池化后输出特征图尺寸(6, 8, 512)
分支4:bin_size=8,pool_size= (12 // 8, 16 // 8) = (1, 2),平均池化后输出特征图尺寸(12, 8, 512)
4.4 Depthwise separable convolution
函数功能:进行深度可分离卷积操作。
在TensorFlow中,深度可分离卷积的函数是:tf.keras.layers.SeparableConv2D
关于深度可分离卷积的详细介绍,可查阅另一篇博客:深入浅出理解深度可分离卷积(Depthwise Separable Convolution)
for bin_size in bin_sizes:x = tf.keras.layers.SeparableConv2D(filters, 3, strides=1, padding='same')(x)
从 SeparableConv2D函数参数中可知,strides=1, padding='same' ,filters=128,根据深度可分离卷积的计算公式,计算输出特征图尺寸为:
分支1:特征图尺寸(2, 2, 512)经过深度可分离卷积操作后,输出特征图尺寸(3, 3, 128)
分支2:特征图尺寸(4, 4, 512)经过深度可分离卷积操作后,输出特征图尺寸(6, 6, 128)
分支3:特征图尺寸(6, 8, 512)经过深度可分离卷积操作后,输出特征图尺寸(8, 10, 128)
分支4:特征图尺寸(12, 8, 512)经过深度可分离卷积操作后,输出特征图尺寸(14, 10, 128)
4.5 resize
tf.image.resize
函数功能:将输出特征图的尺寸resize恢复到原始输入特征图的尺寸。
resize默认的插值算法是 ResizeMethod.BILINEAR。经过resize操作后,计算输出特征图尺寸为:
分支1:特征图尺寸(3, 3, 128)经过深度可分离卷积操作后,输出特征图尺寸(12, 16, 128)
分支2:特征图尺寸(6, 6, 128)经过深度可分离卷积操作后,输出特征图尺寸(12, 16, 128)
分支3:特征图尺寸(8, 10, 128)经过深度可分离卷积操作后,输出特征图尺寸(12, 16, 128)
分支4:特征图尺寸(14, 10, 128)经过深度可分离卷积操作后,输出特征图尺寸(12, 16, 128)
for bin_size in bin_sizes:x = tf.keras.layers.Lambda(lambda x: tf.image.resize(x, (w, h)))(x)concat_list.append(x)
4.6 concatenate
函数功能:将4个分支最后输出的特征图与原始输入特征图进行拼接(concatenate)。
输入特征图尺寸:(12, 16, 128)*4 + (12, 16, 512)
输出特征图尺寸:(12, 16, 1024)
tf.keras.layers.concatenate(concat_list)
五、混合深度可分离金字塔池化(MDSPP)
论文:[3]
混合深度可分离金字塔池化(mixed depthwise separable pyramidal pooling,MDSPP),本文以 SPEEP 论文为例介绍MDSPP。
1. MDSPP结构
MDSPP前半部分(Average Pooling 和 Separable Conv2D)与DSPP结构相同,后半部分为2个不同的分支,最后将这2个分支进行拼接(concatenate)。MDSPP的结构,如下图所示:

2. upsample结构

3. (TensorFlow)代码实现
3.1 SPEED
根据SPEED的结构示意图,搭建SPEED模型。
def create_SPEED_model(input_shape, existing=''):if len(existing) == 0:# encoder阶段, (192, 256, 3) -> (6, 8, 256)encoder = SPEED_Encoder(input_shape=input_shape)# encoder.summary()print('Number of layers in the encoder: {}'.format(len(encoder.layers)))# Starting point for decoderbase_model_output_shape = encoder.layers[-1].output.shapedecode_filters = 256# Decoder Layers# 初始化decoder_0, 不进行upsample, (6, 8, 256) -> (6, 8, 256)decoder_0 = Conv2D(filters=decode_filters,kernel_size=1,padding='same',input_shape=base_model_output_shape,name='conv_Init_decoder')(encoder.output)# decoder_1, 进行upsample, (6, 8, 256) -> (12, 16, 128)decoder_1 = upsample_layer(decoder_0, int(decode_filters / 2), 'up1', concat_with='conv_dw_6', base_model=encoder)# decoder_2, 进行upsample, (12, 16, 128) -> (24, 32, 64)decoder_2 = upsample_layer(decoder_1, int(decode_filters / 4), 'up2', concat_with='conv_dw_4', base_model=encoder)# decoder_3, 进行upsample, (24, 32, 64) -> (48, 64, 32)decoder_3 = upsample_layer(decoder_2, int(decode_filters / 8), 'up3', concat_with='conv_dw_2', base_model=encoder)# 维度变换,输出特征图尺寸不变,通道数变为1, (48, 64, 32) -> (48, 64, 1)convDepthF = Conv2D(filters=1,kernel_size=3,padding='same',name='convDepthF')(decoder_3)model = Model(inputs=encoder.input, outputs=convDepthF)print('Number of layers in the SPEED model: {}'.format(len(model.layers)))model.summary()else:if not existing.endswith('.h5'):sys.exit('Please provide a correct model file when using [existing] argument.')custom_objects = {'accurate_obj_boundaries_loss': accurate_obj_boundaries_loss}model = models.load_model(existing, custom_objects=custom_objects)for layer in model.layers:layer.trainable = Trueprint('Number of layers in the SPEED model: {}'.format(len(model.layers)))print('Existing model loaded.\n')return model
代码分析
SPEED Decoder由4个decoder子层构成,其中decoder_0用于decoder初始化,不进行upsample,输出特征图尺寸不变,通道数不变;decoder_1用于upsample上采样,输出特征图尺寸翻倍,通道数减半;decoder_2用于upsample上采样,输出特征图尺寸翻倍,通道数减半;decoder_3用于upsample上采样,输出特征图尺寸翻倍,通道数减半。经过3次upsample,最终输出的特征图通道数变为32。详细过程,请查阅源码。
3.2 MDSPP
函数功能:执行MDSPP操作,输出特征图尺寸不变,通道数翻倍。
输入特征图:(h, w, filters)
输出特征图:(h, w, filters*2)
def depthwise_mixed_separable_pyramid_pooling(input_tensor, bin_sizes, w, h, filters, name):"""(h, w, filters) -> (h, w, filters*2)"""concat_list = []for bin_size in bin_sizes: # bin_sizes=[2, 4, 6, 8]"""执行AveragePooling2D+SeparableConv2D+resize操作之后,(h, w, filters) -> (h, w, filters//4) * 4个"""x = AveragePooling2D(pool_size=(w // bin_size, h // bin_size), strides=(w // bin_size, h // bin_size), name=name + '_avgpool_' + str(bin_size))(input_tensor)x = SeparableConv2D(filters=filters // 4, kernel_size=3, padding='same', name=name + '_upconv_1_' + str(bin_size), use_bias=False)(x)x = tf.keras.layers.Lambda(lambda x: tf.image.resize(x, (w, h)))(x)concat_list.append(x)# 对奇数项的特征图进行拼接(concat)# 输入通道数:(h, w, filters//4) concat (h, w, filters//4)# 输出通道数:(h, w, filters//2)x_even = Concatenate()([concat_list[0], concat_list[2]])x_even = ReLU()(x_even)# (h, w, filters//2) -> (h, w, filters//2)x_even = SeparableConv2D(filters=filters // 2, kernel_size=3, padding='same', name=name + '_upconv_2_odd', use_bias=False)(x_even)x_even = ReLU()(x_even)# 对偶数项的特征图进行拼接(concat)# 输入通道数:(h, w, filters//4) concat (h, w, filters//4)# 输出通道数:(h, w, filters//2)x_odd = Concatenate()([concat_list[1], concat_list[3]])x_odd = ReLU()(x_odd)# 输入通道数:filters//2# 输出通道数:filters//2# (h, w, filters//2) -> (h, w, filters//2)x_odd = SeparableConv2D(filters=filters // 2, kernel_size=3, padding='same', name=name + '_upconv_2_even', use_bias=False)(x_odd)x_odd = ReLU()(x_odd)# 输入通道数:(h, w, filters//2) concat (h, w, filters//2) concat (h, w, filters)# 输出通道数:(h, w, filters*2)x = Concatenate()([x_even, x_odd, input_tensor])return x
3.3 upsample
函数功能:采用转置卷积(
Conv2DTranspose)进行upsample上采样操作,输出特征图尺寸翻倍,通道数减半。
def upsample_layer(tensor, filters, name, concat_with, base_model):"""进行三次上采样decoder_1, filters=256//2=128, tensor=(6, 8, 256) -> (12, 16, 128)decoder_2, filters=256//4=64, tensor=(12, 16, 128) -> (24, 32, 64)decoder_2, filters=256//8=32, tensor=(24, 32, 64) -> (48, 64, 32)"""def HPO2(filters_value):for i in range(filters_value, 0, -1):if (i & (i - 1)) == 0:return iif name == 'up1':# 上采样采用转置卷积,输出特征图尺寸翻倍,通道数变为128# decoder_1, tensor=(6, 8, 256), 则(6, 8, 256) -> (12, 16, 128)up_i = Conv2DTranspose(filters=filters, kernel_size=3, strides=2, padding='same', dilation_rate=1, name=name + '_upconv', use_bias=False)(tensor)else:# 执行MDSPP操作,输出特征图尺寸不变,通道数翻倍# decoder_2, (12, 16, 128) -> (12, 16, 256)# decoder_3, (24, 32, 64) -> (24, 32, 128)up_i = depthwise_mixed_separable_pyramid_pooling(input_tensor=tensor, bin_sizes=[2, 4, 6, 8], w=tensor.shape[1], h=tensor.shape[2], filters=filters, name=name)# 上采样采用转置卷积,输出特征图尺寸翻倍,通道数变为64、32# decoder_2, (12, 16, 256) -> (24, 32, 64)# decoder_3, (24, 32, 128) -> (48, 64, 32)up_i = Conv2DTranspose(filters=filters, kernel_size=3, strides=2, padding='same', dilation_rate=1, name=name + '_upconv_final', use_bias=False)(up_i)# decoder_1, conv_dw_6=(12, 16, 512), 则(12, 16, 128) concat (12, 16, 512) -> (12, 16, 640)# decoder_2, conv_dw_4=(24, 32, 256), 则(24, 32, 64) concat (24, 32, 256) -> (24, 32, 320)# decoder_3, conv_dw_2=(48, 64, 128), 则(48, 64, 32) concat (48, 64, 128) -> (48, 64, 160)up_i = Concatenate(name=name + '_concat')([up_i, base_model.get_layer(concat_with).output]) # Skip connectionup_i = ReLU()(up_i)# decoder_1, (12, 16, 640) 取2的次幂,可得(12, 16, 512),则(12, 16, 512) -> (12, 16, 128)# decoder_2, (24, 32, 320) 取2的次幂,可得(24, 32, 256),则(24, 32, 256) -> (24, 32, 64)# decoder_3, (48, 64, 160) 取2的次幂,可得(48, 64, 128),则(48, 64, 128) -> (48, 64, 32)up_i = SeparableConv2D(filters=HPO2((up_i.shape[-1]) // 4),kernel_size=3,padding='same',use_bias=False,name=name + '_sep_conv')(up_i)up_i = ReLU()(up_i)return up_i
解释说明
decoder_1:不进行MDSPP操作,首先采用转置卷积(Conv2DTranspose)进行upsample操作,然后进行拼接(concatenate)操作,最后进行深度可分离卷积操作(SeparableConv2D)。decoder_2:首先进行MDSPP操作,再采用转置卷积(Conv2DTranspose)进行upsample上采样操作,然后进行拼接(concatenate)操作,最后进行深度可分离卷积操作(SeparableConv2D)。decoder_3:首先进行MDSPP操作,再采用转置卷积(Conv2DTranspose)进行upsample上采样操作,然后进行拼接(concatenate)操作,最后进行深度可分离卷积操作(SeparableConv2D)。
六、DeepLab系列网络
1. DeepLab v1
原始论文:[4]
DeepLabV1网络简析
bilibili视频讲解:DeepLabV1网络简介(语义分割)
DeepLab v1加入了多尺度的特性,是LargeFOV的升级版。
1.1引言
针对语义分割任务,信号下采样导致分辨率降低和空间“不敏感” 问题。
-
信号下采样导致分辨率降低。作者说主要是采用Maxpooling导致的,为了解决这个问题作者引入了
'atrous'(with holes) algorithm(空洞卷积 / 膨胀卷积 / 扩张卷积)。 -
空间“不敏感”。作者说分类器自身的问题,因为分类器本来就具备一定空间不变性。为了解决这个问题,作者采用了fully-connected CRF(Conditional Random Field)方法,这个方法只在DeepLabv1-v2中使用到了,从v3之后就不去使用了,而且这个方法挺耗时的。
1.2 backbone
DeepLab v1的backbone为VGG-16。
2. DeepLab v2
原始论文:[5]
DeepLabV2网络简析
解读DeepLab v2
bilibili视频讲解:DeepLabV2网络简介(语义分割)
DeepLab v2加入了ASPP模块,通过四个并行的膨胀卷积层,每个分支上的膨胀卷积层所采用的膨胀系数不同。这里的膨胀卷积层后面没有BatchNorm,并使用了Bias偏置。接着通过add相加的方式融合四个分支上的输出。
2.1 引言
在文章的引言部分,作者提出了DCNNs应用在语义分割任务中遇到的问题。
- 分辨率被降低(主要由于下采样
stride>1的层导致)。 - 目标的多尺度问题。
- DCNNs的不变性(invariance)会降低定位精度。
解决办法
- 针对分辨率被降低的问题,一般就是将最后的几个Maxpooling层的stride给设置成1(如果是通过卷积下采样的,比如resnet,同样将stride设置成1即可),然后在配合使用膨胀卷积。
- 针对目标多尺度的问题,最容易想到的就是将图像缩放到多个尺度分别通过网络进行推理,最后将多个结果进行融合即可。这样做虽然有用但是计算量太大了。为了解决这个问题,DeepLab v2 中提出了ASPP模块(atrous spatial pyramid pooling)。
- 针对DCNNs不变性导致定位精度降低的问题,和DeepLab v1差不多还是通过CRFs解决,不过这里用的是fully connected pairwise CRF,相比V1里的fully connected CRF要更高效点。在DeepLab v2中CRF涨点就没有DeepLab v1猛了,在DeepLab v1中大概能提升4个点,在DeepLab v2中通过Table4可以看到大概只能提升1个多点了。
2.2 backbone
DeepLab v1的backbone为ResNet101。
2.3 DeepLab v2流程
如下图所示,和v1的流程类似,DeepLab v2的流程为:输入Input -> CNN提取特征 -> 粗糙的分割图(1/8原图大小) -> 双线性插值回原图大小 -> CRF后处理 -> 最终输出Output。

2.4 DeepLab v2网络结构
这里以ResNet101作为backbone为例。在ResNet的Layer3中的Bottleneck1中原本是需要下采样的(3x3的卷积层stride=2),但在DeepLab v2中将stride设置为1,即不在进行下采样。而且3x3卷积层全部采用膨胀卷积膨胀系数为2。在Layer4中也是一样,取消了下采样,所有的3x3卷积层全部采用膨胀卷积膨胀系数为4。最后需要注意的是ASPP模块,在以ResNet101做为Backbone时,每个分支只有一个3x3的膨胀卷积层,且卷积核的个数都等于num_classes。

2.5 代码示例
这里以VGG-16作为backbone为例。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass ASPP(nn.Module):def __init__(self, in_channels, num_classes):super().__init__()self.branch1 = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=3, stride=1, padding=6, dilation=6, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=num_classes, kernel_size=1, stride=1, padding=0, bias=True),)self.branch2 = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=3, stride=1, padding=12, dilation=12, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=num_classes, kernel_size=1, stride=1, padding=0, bias=True),)self.branch3 = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=3, stride=1, padding=18, dilation=18, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=num_classes, kernel_size=1, stride=1, padding=0, bias=True),)self.branch4 = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=3, stride=1, padding=24, dilation=24, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=1, stride=1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=num_classes, kernel_size=1, stride=1, padding=0, bias=True),)def forward(self, x):return self.branch1(x) + self.branch2(x) + self.branch3(x) + self.branch4(x)class DeepLabv2(nn.Module):def __init__(self, in_channels: int = 3, num_classes: int = 21):super().__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),)self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1, bias=True),nn.ReLU(inplace=True),)self.pool4 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.conv5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=2, dilation=2, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=2, dilation=2, bias=True),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=2, dilation=2, bias=True),nn.ReLU(inplace=True),)self.pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.ASPP = ASPP(in_channels=512, num_classes=num_classes)def forward(self, x):conv1_x = self.conv1(x)print('# Conv1 output shape:', conv1_x.shape)pool1_x = self.pool1(conv1_x)print('# Pool1 output shape:', pool1_x.shape)conv2_x = self.conv2(pool1_x)print('# Conv2 output shape:', conv2_x.shape)pool2_x = self.pool2(conv2_x)print('# Pool2 output shape:', pool2_x.shape)conv3_x = self.conv3(pool2_x)print('# Conv3 output shape:', conv3_x.shape)pool3_x = self.pool3(conv3_x)print('# Pool3 output shape:', pool3_x.shape)conv4_x = self.conv4(pool3_x)print('# Conv4 output shape:', conv4_x.shape)pool4_x = self.pool4(conv4_x)print('# Pool4 output shape:', pool4_x.shape)conv5_x = self.conv5(pool4_x)print('# Conv5 output shape:', conv5_x.shape)pool5_x = self.pool5(conv5_x)print('# Pool5 output shape:', pool5_x.shape)out = self.ASPP(pool5_x)print('# Output shape:', out.shape)return outif __name__ == '__main__':inputs = torch.randn(4, 3, 224, 224)print('# input shape:', inputs.shape)net = DeepLabv2(in_channels=3, num_classes=21)output = net(inputs)
输出结果
# input shape: torch.Size([4, 3, 224, 224])
# Conv1 output shape: torch.Size([4, 64, 224, 224])
# Pool1 output shape: torch.Size([4, 64, 112, 112])
# Conv2 output shape: torch.Size([4, 128, 112, 112])
# Pool2 output shape: torch.Size([4, 128, 56, 56])
# Conv3 output shape: torch.Size([4, 256, 56, 56])
# Pool3 output shape: torch.Size([4, 256, 28, 28])
# Conv4 output shape: torch.Size([4, 512, 28, 28])
# Pool4 output shape: torch.Size([4, 512, 28, 28])
# Conv5 output shape: torch.Size([4, 512, 28, 28])
# Pool5 output shape: torch.Size([4, 512, 28, 28])
# Output shape: torch.Size([4, 21, 28, 28])
3. DeepLab v3
DeepLab v3(2017年):[3]
DeepLab v3+(2018年):[6]
DeepLab V3网络简介
DeepLabV3网络简析
bilibili视频讲解:DeepLabV3网络简介(语义分割)
DeepLab v3改进了ASPP模块,通过五个并行的膨胀卷积层,其分别是1x1的卷积层,三个3x3的膨胀卷积层,以及一个全局平均池化层。其中,全局平均池化层后面跟有一个1x1的卷积层,然后通过双线性插值的方法还原回输入的W和H,全局平均池化分支增加了全局上下文信息。之后,通过Concat的方式将5个分支的输出沿着channels进行拼接。最后再通过一个1x1的卷积层进一步融合信息。
3.1 DeepLab v3网络结构
这里以ResNet101作为backbone为例。

3.2 训练技巧
- 在训练过程中增大训练输入的尺寸。论文中介绍,在采用大的膨胀系数时,输入的图像尺寸不能太小,否则3x3的膨胀卷积可能退化成1x1的普通卷积。
- 计算损失时,将预测的结果通过上采样还原回原尺度(即网络通过最后的双线性插值上采样8倍),再和真实标签图像计算损失。而在DeepLab v1和DeepLab v2中,将真实标签图像下采样8倍的特征图与没有进行上采样的预测结果计算损失,这样做的目的也能加快训练。
- 训练后,冻结bn层的参数,fine-turn网络。
3.3 DeepLab v3中的ASPP
DeepLab v3论文中的ASPP结构,如下图所示:

其中的1*1卷积,论文中的解释是当 rate = feature map size 时,dilation conv 就变成了 1 ×1 conv,所以这个 1 × 1 conv相当于rate很大的空洞卷积。还加入了全局池化,再上采样到原来的 feature map size,思想来源于PSPnet。为什么用 rate = [6, 12, 18] ?是论文实验得到的,因为这个搭配比例的 mIOU 最高。
七、相关经验
PSPNet
基于港中文和商汤组的 PSPNet 里的 Pooling module,ASPP则在 decoder 中对于不同尺度上用不同大小的 dilation rate 来抓取多尺度信息,每个尺度则为一个独立分支,在网络最后把它们合并起来,再接一个卷积层输出预测 label。这样的设计有效避免了在 encoder 上获取冗余的信息,直接关注与物体之间的相关性。
八、参考文献
[1] He K, Zhang X, Ren S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2015, 37(9): 1904-1916.
[2] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arxiv preprint arxiv:1706.05587, 2017.
[3] Papa L, Alati E, Russo P, et al. Speed: Separable pyramidal pooling encoder-decoder for real-time monocular depth estimation on low-resource settings[J]. IEEE Access, 2022, 10: 44881-44890.
[4] Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected crfs[J]. arxiv preprint arxiv:1412.7062, 2014.
[5] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(4): 834-848.
[6] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.