目录
一、NIO三大组件
1、Channel
2、Buffer
3、Selector
二、ByteBuffer
1、基本使用
2、内部结构
3、常用方法
allocate方法
读取方法
字符串与ByteBuffer互转
Scattering Reads
4、念包、半包问题
三、文件编程
1、FileChannel
2、两个Channel传输数据
3、Path
4、Files
一、NIO三大组件
non-blocking io 非阻塞IO
1、Channel
Channel就是通道,在这里是指数据的双向通道,可以从channel将数据读入buffer,也可以将buffer的数据写入channel,而之前的stream要么是输入,要么是输出,channel比stream更底层
常见的Channel有:
- FileChannel:做文件的数据传输通道
- DatagramChannel:UDP传输的数据通道
- SocketChannel:是做TCP的时候的数据传输通道(客户端服务器都能用)
- ServerSocketChannel:是做TCP的时候的数据传输通道(专用服务器)
2、Buffer
buffer则用来缓冲读写数据,常见的buffer有:
ByteBuffer(字节为单位缓存数据的)是抽象类,实现类有:
- MapperByteBuffer
- DirectByteBuffer
- HeapByteBuffer
3、Selector
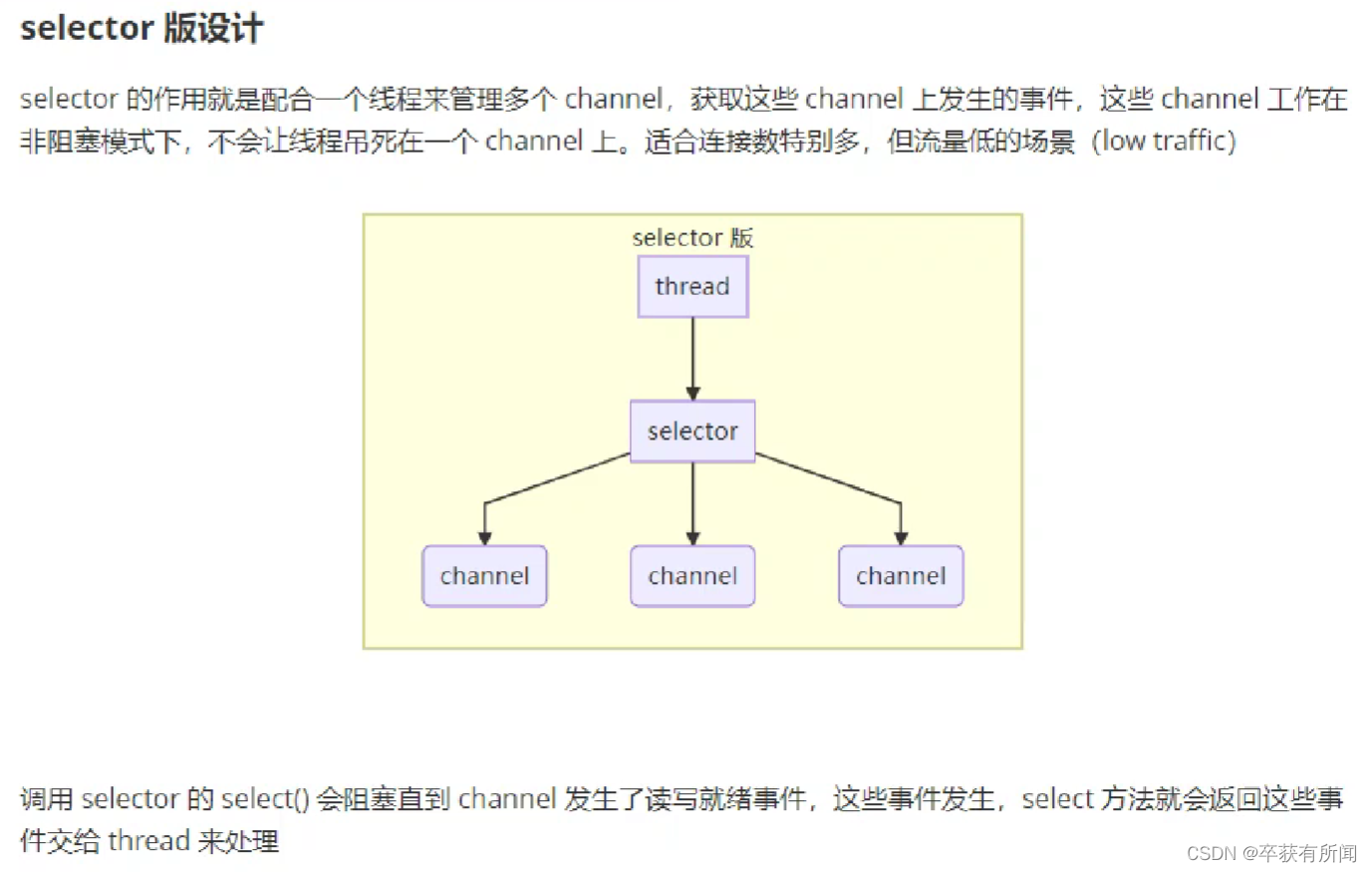
selector单从字面意思是选择器,需要结合服务器的设计演化来理解它的用途
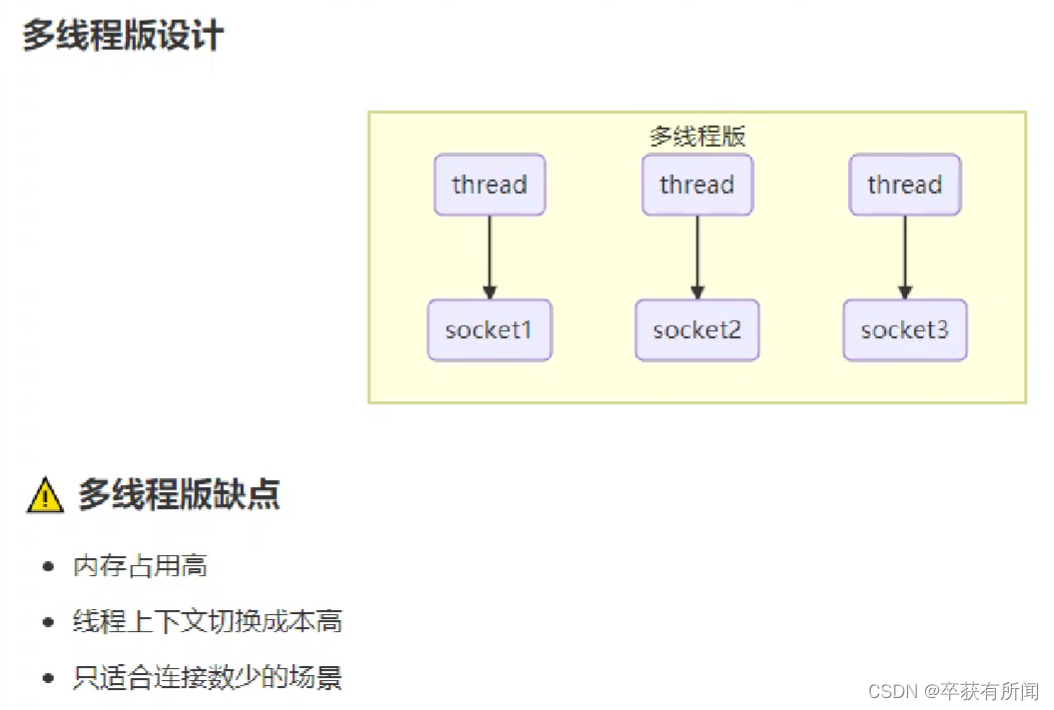
服务器处理多个客户端的通信,每次来一个就为客户端创建一个线程为客户端提供服务,如果多个就开多个线程,每个线程专门管理一个连接,当连接数很多的时候,就不行了,因为线程会占用内存,每个线程都会占用内存,当1000个线程的时候就很大了,内存会撑不住。 但是cpu核数有限,所以线程上下文切换成本高,这种只适合连接数少的场景。
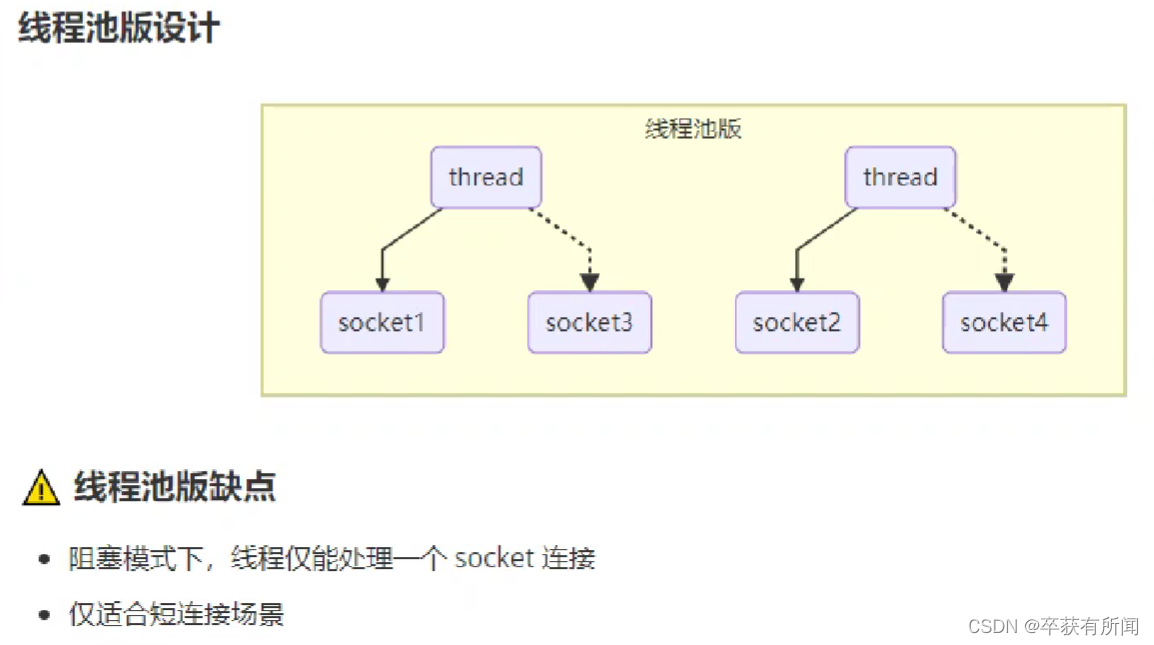
改进为线程池就可以限制线程数量了,但是这样会让socket工作在堵塞模式下,因为一个线程要管理多个socket连接,一个时间只能处理一个,其余会阻塞(线程一个时间只能处理一个socket,直到这个socket断开连接,才能退出,即使这个socket并没有读写请求也得在上面等),所以只适合短连接的场景。
二、ByteBuffer
1、基本使用
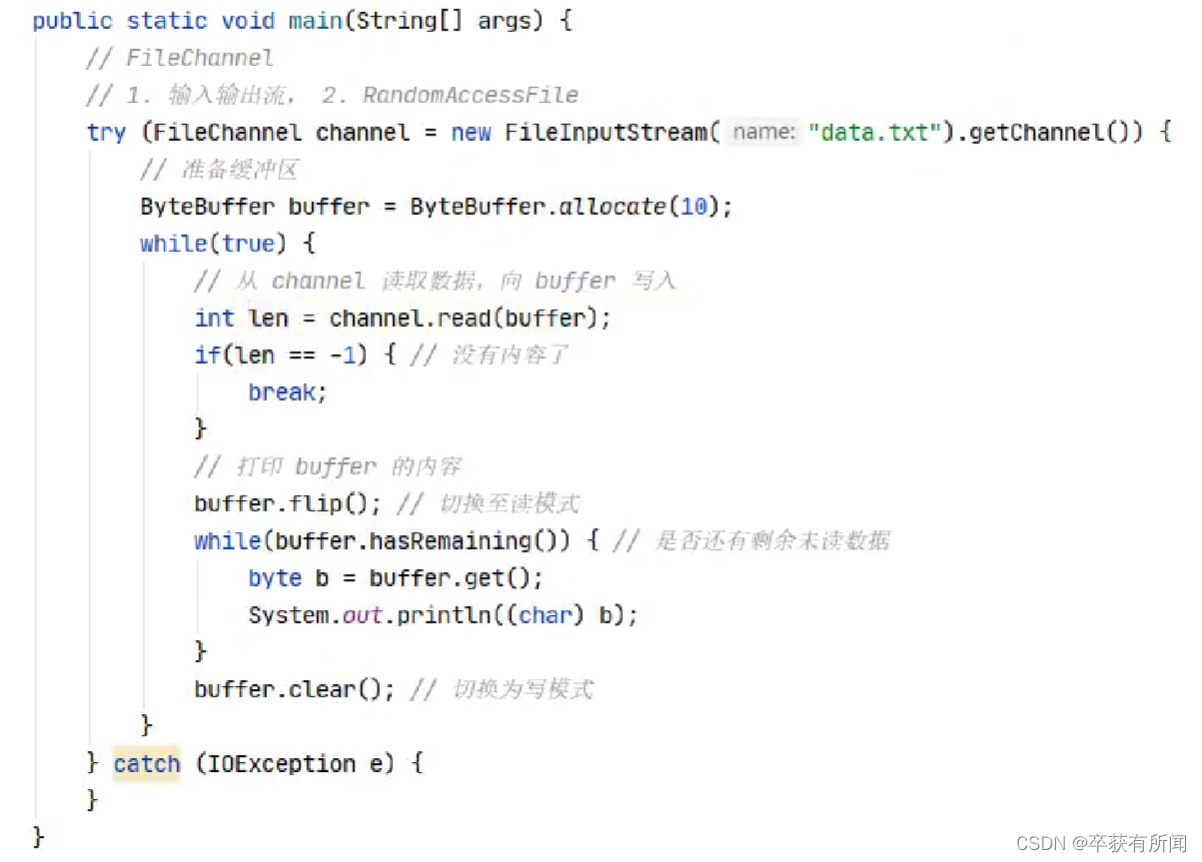
初始化一个大小为10字节缓冲区,然后循环取写入读取,channel就是个读取数据的通道,每次读出来的数据就存在buffer中,然后调用buffer中的api去获取数据
ByteBuffer正确使用姿势:
- 向buffer写入数据,例如调用channel.read(buffer)
- 调用flip()切换到读模式
- 从buffer读取数据,例如调用buffer.get()
- 调用clear()或compact()切换到写模式
- 重复1-4的步骤
2、内部结构
ByteBuffer有以下重要的属性
- capacity 容量
- position 读写指针,索引下标
- limit 读写的限制,应该读多少字节写多少字节
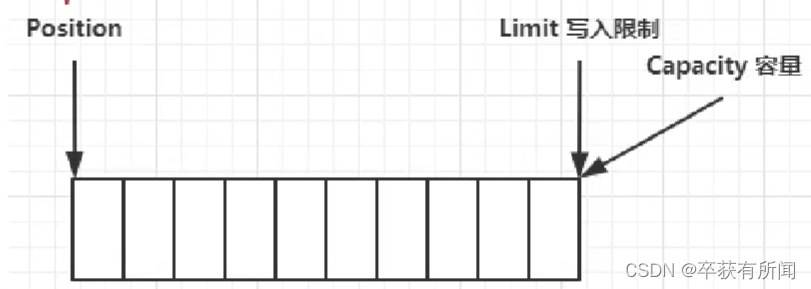
写模式下,position是写入位置,limit等于容量,下图表示写入4个字节后的状态
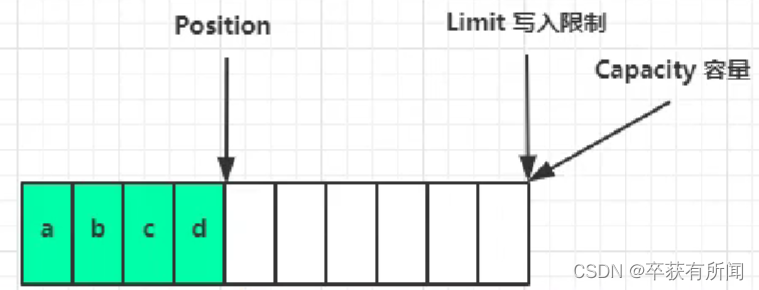
filp动作发生后,position切换为读取位置,limit切换为读取限制(写的最后一个位置)
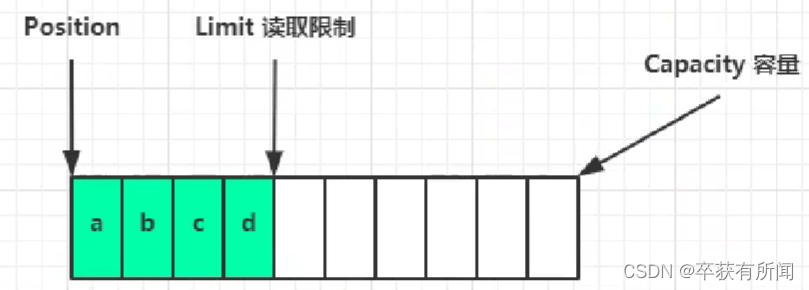
读取4个字节后,状态

发生clear动作后,状态从读模式切换到写模式
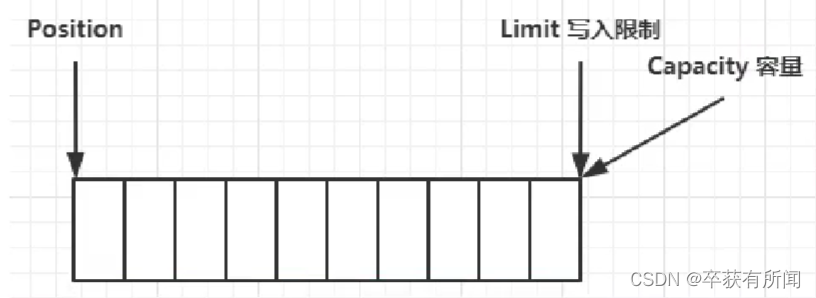
compact方法,是把为读完的部分向前压缩,然后切换至写模式

3、常用方法
allocate方法
ByteBuffer.allocate()方法可以传入参数,为ByteBuffer分配内存,是固定的,不可以动态调节,超过这个容量就会报错,netty对byteBuffer做了增强可以动态调整。
使用allocate方法初始化使用的是Java的堆内存(读写效率较低,会收到GC的影响,GC的标记整理和复制都可能会数据拷贝),用allocateDirect()方法初始化使用的是直接内存(读写效率较高,会少一次数据拷贝;分配内存的效率低,使用不当可能会内存泄漏)
读取方法
rewind():可以重复的读取数据,本来按顺序读取一次就往后移动指针,但是rewind的源码会把指针直接移动到0重新读取。与rewind搭配使用的还有mark和reset方法,mark会记录当前的position位置,reset会将position重置到mark的位置,这两个就是为rewind做增强。
字符串与ByteBuffer互转
字符串转ByteBuffer
第一种是手动转化为二进制形式put进去;第二种是用charset提供的encode方法,他提供了很多编码格式,放进去之后会自动切换为读模式;第三种也是nio提供的warp方法来放进去,这种也是会切换为读模式

ByteBuffer转字符串
切换到读模式之后,所以如果是第一种模式转的buffer要加flip方法先切换模式,然后用charset的decode方法区转化,返回的结果是个CharBuffer加toString转为字符串
Scattering Reads
分散读取数据onetwothree,使用下面方式读取可以将数据填充到多个buffer

4、念包、半包问题

解决办法:
我们写个方法来接收消息,先切换为读模式,然后循环遍历到分隔符就截取出消息的长度,然后把消息存入心得byteBuffer中(循环从source去读往target去写)。

三、文件编程
1、FileChannel
FileChannel只能工作在阻塞模式下
获取
不能直接打开FileChannel,必须通过FileInputStream、FileOutputStream或者RandomAccessFile来获取FileChannel,它们都有getChannel方法
- 通过FileInputStream获取channel只能读
- 通过FileOutputStream获取的channel只能写
- 通过RandomAccessFile是否能读写根据构造RandomAccessFile时的读写模式决定
读取
会从channel读取数据填充到ByteBuffer,返回值表示读了多少字节,-1表示到达文件末尾
int readBytes = channel.read(buffer);写入
在while中调用channel.write是因为write方法并不能保证一次性将buffer中的内容全部写入channel,所以要循环判断有没有。

关闭
channel必须关闭,不过调用了FileInputStream的close方法也会间接的调用channel的close方法
强制写入
操作系统出于性能考虑,会将数据缓存,当最终channel关闭的时候才会将这些数据同步到磁盘,不是立刻写入磁盘,可以调用force(true)方法将文件内容和元数据立刻写入磁盘
2、两个Channel传输数据
transferTo方法,就是将一个channel的数据传输到另一个channel上,第一个参数就是启始位置,第二个参数就是传输数据的大小,第三个参数就是目标位置。

用这种方式的效率会比输出流去写效率要高(操作系统底层的零拷贝进行优化)
传输的数据大小是有限制的2g,所以我们一次可能传输不完,要改进一下:
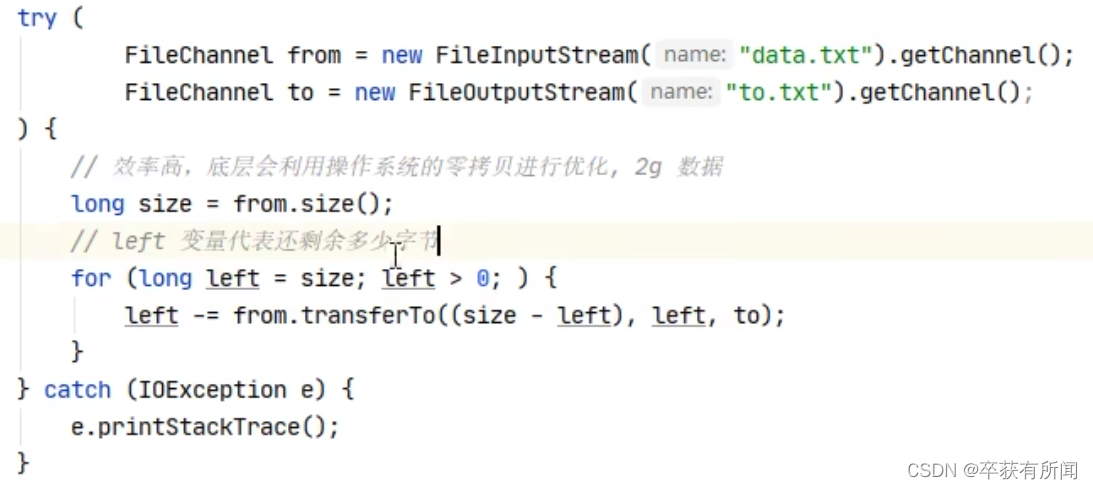
这样就可以多次传输大于2g的数据了
3、Path
jdk7引入了Path和Paths类
- Path用来表示文件路径
- Paths是工具类,用来获取Path实例

- . 代表了当前路径
- .. 代表上一级路径
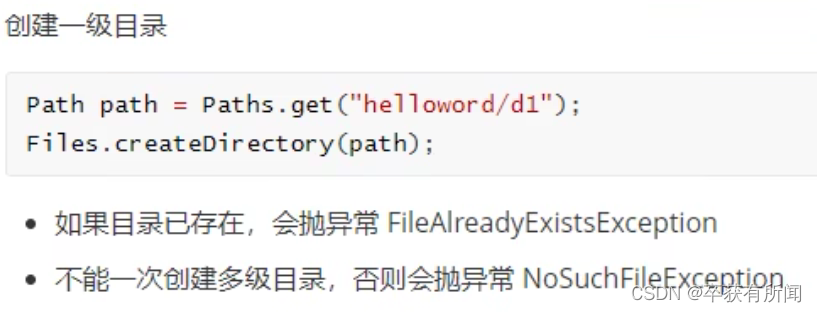
4、Files
也是1.7新增的类,检查文件是否存在







![强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient-Cart pole游戏展示](https://img-blog.csdnimg.cn/img_convert/7172e31965f4a38632ef542815a3cbf2.png)