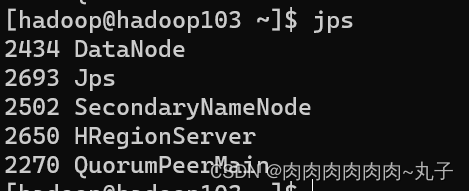
| 任务一:搭建HBase集群 1.1 搭建Zookeeper 1. 官网下载Linux环境的tar包 (1)官网地址:Apache ZooKeeper (2)下载Linux环境的tar包
2. 拷贝安装包到Linux系统下并解压到指定目录 [hadoop@hadoop101 software]$tar -zxvf apache-zookeeper-3.5.7 -bin.tar.gz -C /opt/module
(1)配置zoo_sample.cfg (2)在/opt/module/zookeeper-3.5.7/目录下创建zkData文件
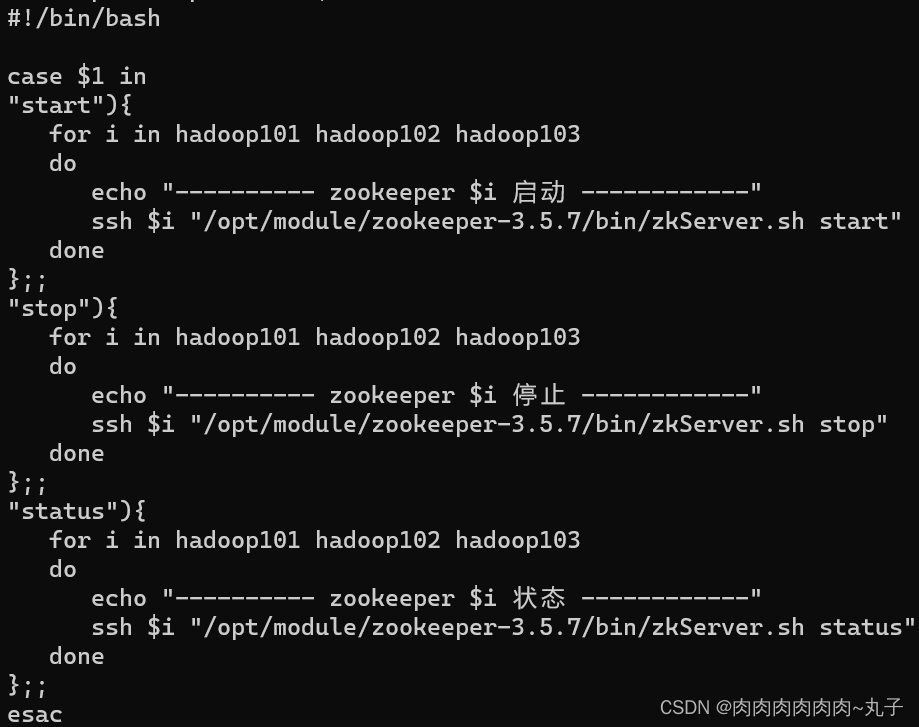
[hadoop@hadoop101 module ]$ xsync zookeeper-3.5.7 5. 创建集群启动停止脚本 [hadoop@hadoop101 bin]$ vim zk.sh
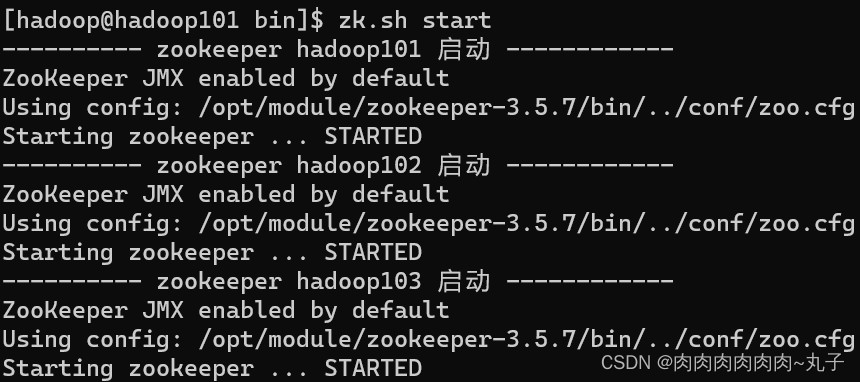
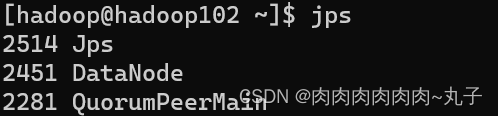
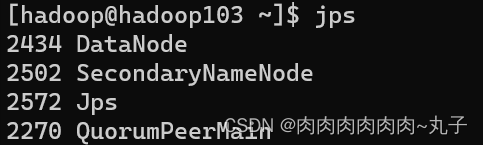
6. 群起Zookeeper [hadoop@hadoop101 bin]$ zk.sh start
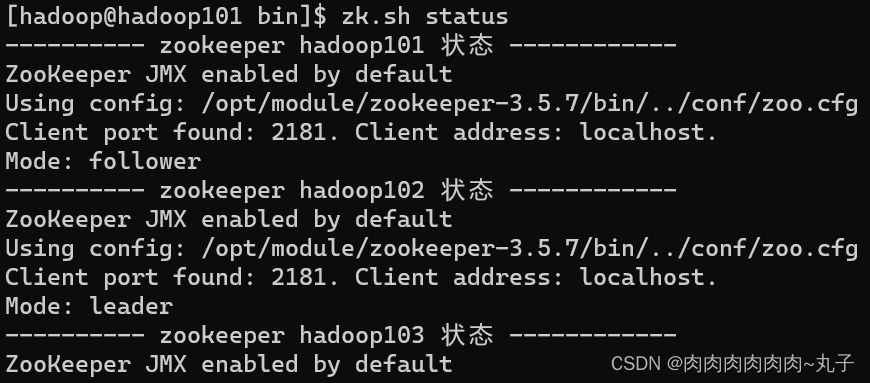
7. 查看启动状态 [hadoop@hadoop101 bin]$ zk.sh status
1.2 启动Hadoop集群 [hadoop@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
1.3 搭建HBase 1. 官网下载Linux环境的tar包 2. 上传至Linux并解压到指定目录 3. HBase的配置文件 (1)hbase-env.sh (2)hbase-site.xml (3)regionservers (4)软连接hadoop配置文件到HBase [hadoop@hadoop101 module]$ ln -s /opt/module/hadoop-2.7.2/et c/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml [hadoop@hadoop101 module]$ ln -s /opt/module/hadoop-2.7.2/et c/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
[hadoop@hadoop101 module]$ xsync hbase/
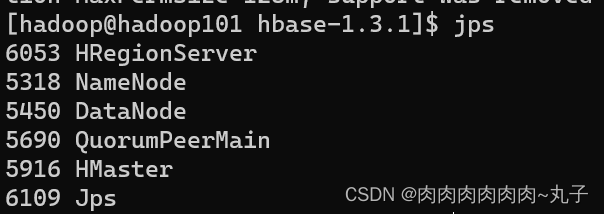
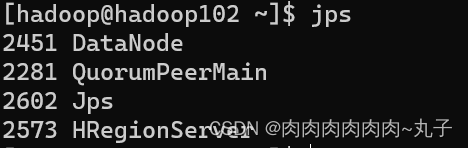
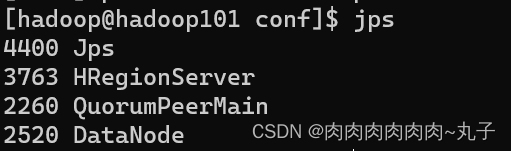
[hadoop@hadoop101 hbase-1.3.1]$ bin/hbase-daemon.sh start ma ster [hadoop@hadoop101 hbase-1.3.1]$ bin/hbase-daemon.sh start reg ionserver
[hadoop@hadoop101 hbase-1.3.1]$ bin/start-hbase.sh 对应的停止服务: [hadoop@hadoop101 hbase-1.3.1]$ bin/stop-hbase.sh
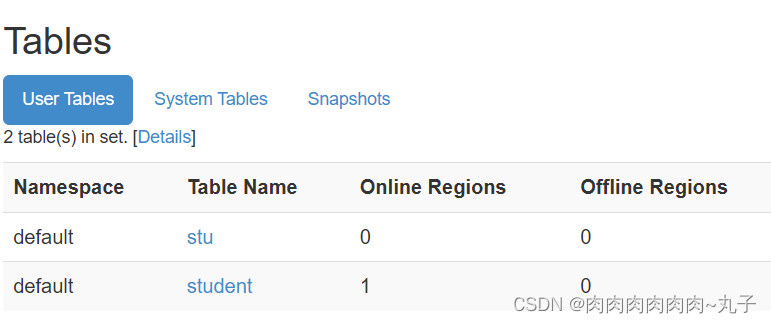
1.4 查看HBase页面 启动成功后,可以通过“host:port”的方式来访问 HBase 管理页面,例如:http://hadoop102:16010
1.5 进入HBase Shell客户端命令行 [hadoop@hadoop101 hbase-1.3.1]$ bin/hbase shell
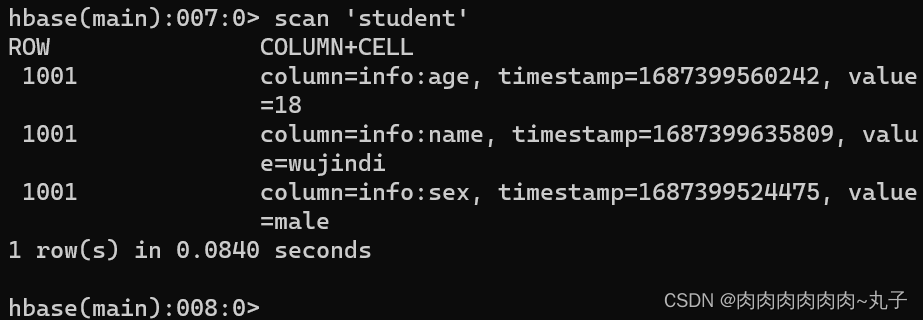
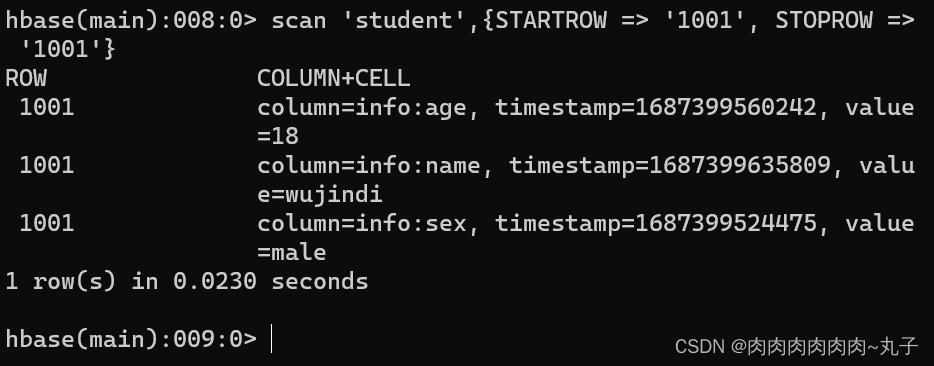
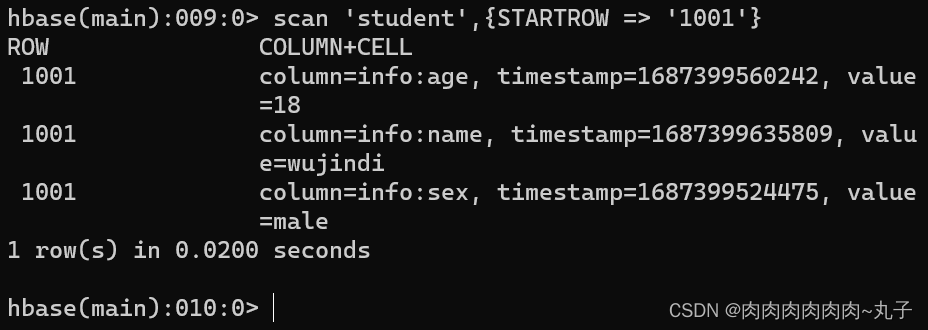
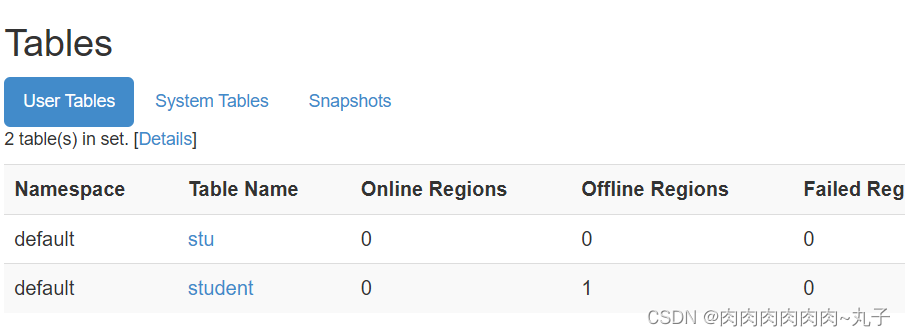
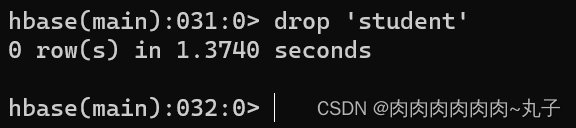
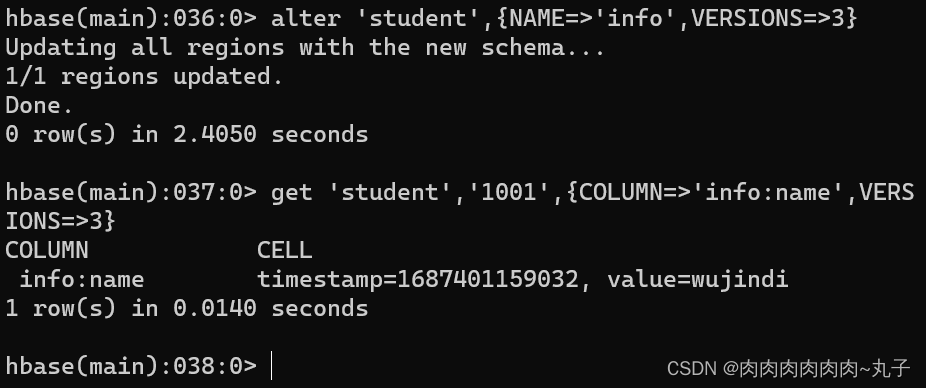
任务二:进入HBase Shell,练习创建表、插入数据到表、扫描查看表数据、查看表结构、更新指定字段数据、查看指定数据、删除指定数据、删除表。
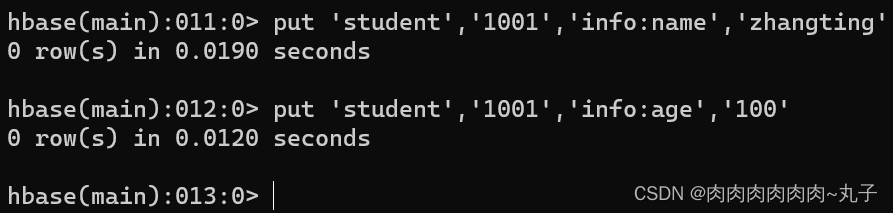
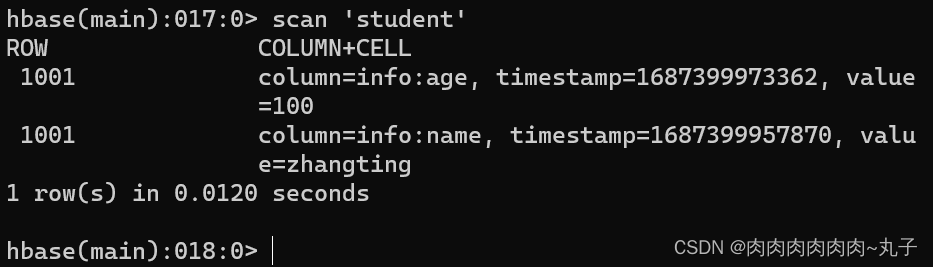
增加记录
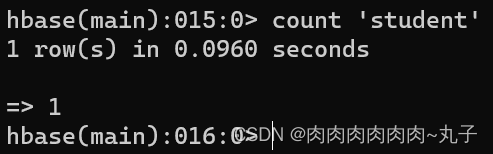
删除1001的所有数据
提示:删除表的操作顺序为先 disable,然后再 truncate。
任务三:举例说明HBase的行键设计原则
保证唯一性:HBase的行键必须保证唯一性,因为它是用来唯一标识一行数据的。因此,在设计行键时需要考虑如何构建能够保证唯一性的键值,例如可以使用时间戳或者在键值前面添加一些随机数。 稳定性:行键一旦确定,就不应该再次改变。因此,在设计行键时需要考虑到数据的稳定性。特别是在需要长期保存数据的场景下,行键设计的稳定性尤为重要。 可排序性:HBase的行数据默认是按照行键排序的,因此,在设计行键时应该考虑到排序的需要。一般可以采用一些有序的编码方式,如字典序或者时间戳,以便于快速进行检索和排序。 长度控制:HBase的行键长度不能太长,因为行键会占用内存资源。因此,在设计行键时需要控制其长度,一般建议不超过100个字符。 总之,行键的设计要综合考虑数据的唯一性、稳定性、排序性和长度控制等因素。在实践中,需要根据具体的应用场景和业务需求进行灵活调整。
首先,我们根据HBase行键设计原则,先确定行键的构成:时间戳+用户ID。在Shell中,可以使用“timestamp_userid”的命名方式,示例如下:
接下来,我们可以使用put命令将数据插入到HBase中。这里以2023年6月22日的用户“001”登录记录为例:
在上面的put命令中,“20230622010001”即为行键,代表了该用户在2023年6月22日10:00:01的登录记录。该行键由时间戳和用户ID拼接而成。同时,我们可以插入一些列族和对应的列,例如登录时间、用户ID和IP地址等。 注意,在实际生产环境中使用shell命令进行操作的效率和可靠性较低,最好使用HBase的API或者其他工具对HBase进行管理和操作。 |
| 出现问题:启动HBase时,如果HMaster无法启动 问题原因:NameNode 挂了:如果HDFS中的NameNode挂了,则HMaster无法启动。可以查看HDFS日志以检查NameNode 错误。
解决方案:检查NameNode的日志,以了解连接被拒绝或出现其他问题的原因。如果需要,修复NameNode故障并重新启动hadoop集群,启动HBase成功。
|
| 无 |
| HBase是一个分布式的、可扩展的、稳定的NoSQL数据库,可以用于存储和处理海量数据。它的数据模型类似于一个多维表格,可以轻松地存储和访问大量结构化数据。 需要学习如何安装和配置Hadoop和HBase集群,并了解HBase的整体架构、主要组件及其功能。同时,熟练运用HBase的Java API,掌握HBase的基本操作和常用命令。 HBase的存储架构是基于HDFS的,HBase表格中的每一行都会被分割成多个存储单元(Cell)来存储,每个存储单元都有行键、列族、列限定符和时间戳等属性。掌握存储结构和存储过程,有助于提升HBase应用的性能。 在实际应用中,需要考虑并发访问和数据一致性问题。HBase提供了多版本控制(MVCC)机制,在并发访问时可以避免数据读写冲突,同时还可以选择数据一致性级别来满足不同的业务需求。 总的来说,HBase是一个非常强大和灵活的NoSQL数据库,可以广泛应用于各种大数据应用场景。但是,在实践中需要仔细考虑数据模型的设计、存储结构的优化和性能调优等方面,熟练掌握HBase的各种功能才能更好地发挥其威力。 |