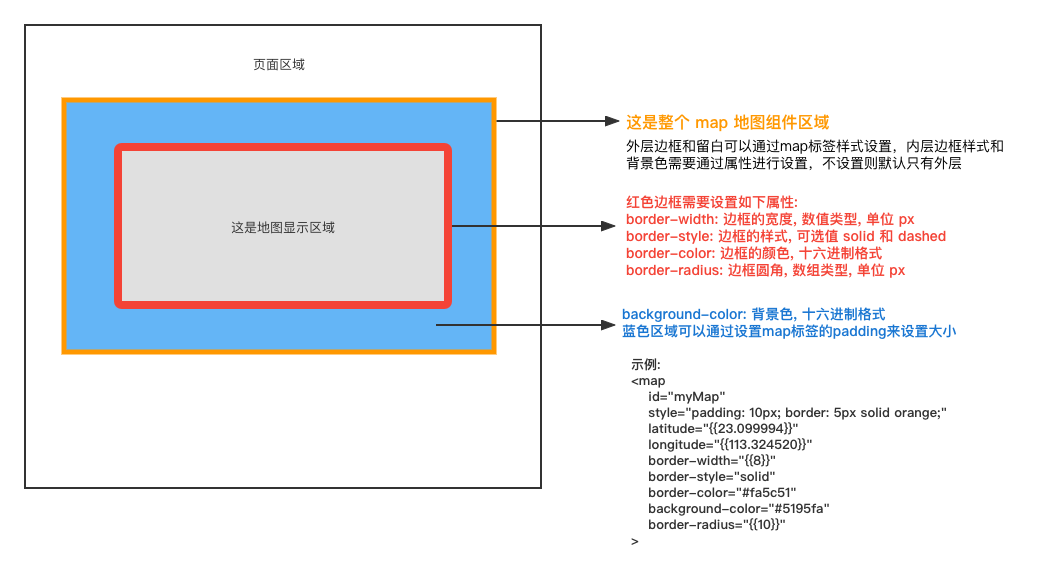
Kafka的安装、管理和配置
1.Kafka安装
官网: https://kafka.apache.org/downloads 下载安装包,我这里下载的是https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
Kafka是Java生态圈下的一员,用Scala编写,运行在Java虚拟机上,所以安装运行和普通的Java程序并没有什么区别(需要配置java环境)。
在Kafka 2.8之后,引入了基于Raft协议的KRaft模式,支持取消对Zookeeper的依赖。
支持两种启动方式:
- Kafka with ZooKeeper
启动Zookeeper
进入Kafka目录下的bin\windows,编辑启动、停止脚本,注意最好不要将解压的安装包放在桌面,否则可能会由于目录层级太深或者是目录名字太长导致无法正确启动zookeeper,Linux下与此类似,进入bin后,执行对应的sh文件即可
start_ZK.bat
zookeeper-server-start.bat ../../config/zookeeper.properties
start_Kafka.bat
kafka-server-start.bat ../../config/server.properties
stop_Kafka.bat
kafka-server-stop.bat ../../config/server.properties
- Kafka with KRaft
1.生产集群id
./kafka-storage.sh random-uuid

2.格式化存储目录
# vAB7_ADZTc6vsKrBLI1qmA上面指令生成的集群id
./kafka-storage.sh format -t vAB7_ADZTc6vsKrBLI1qmA -c ../config/kraft/server.properties

3.启动服务
./kafka-server-start.sh ../config/kraft/server.properties
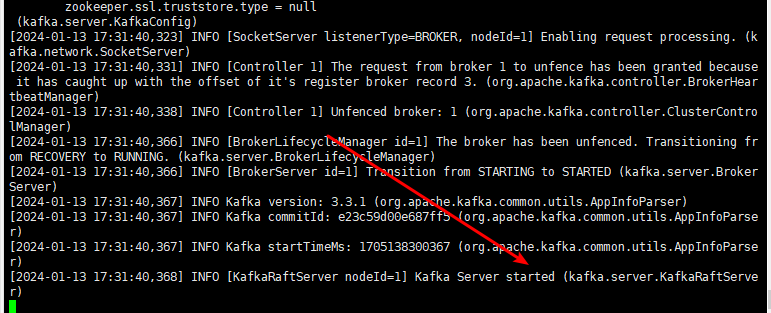
2.kafka基本的操作和管理
- 列出所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list

- 列出所有主题的详细信息
./kafka-topics.sh --bootstrap-server localhost:9092 --describe

- 创建主题主题名 my-topic ,1副本,8分区
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-topic --replication-factor 1 --partitions 8
- 增加分区,注意:分区无法被删除
./kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic my-topic --partitions 16
- 创建生产者(控制台)
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic

- 创建消费者(控制台)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning --consumer.config ../config/consumer.properties

- kafka终止命令
./kafka-server-stop.sh
3.Kafka broker配置
配置文件放在Kafka目录下的config目录中,主要是server.properties文件
3.1常规配置
broker.id
在单机时无需修改,但在集群下部署时往往需要修改。它是个每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
listeners
监听列表(以逗号分隔 不同的协议(如plaintext,trace,ssl、不同的IP和端口)),hostname如果设置为0.0.0.0则绑定所有的网卡地址;如果hostname为空则绑定默认的网卡。如果没有配置则默认为java.net.InetAddress.getCanonicalHostName()。
如:PLAINTEXT://myhost:9092,TRACE://:9091或 PLAINTEXT://0.0.0.0:9092,
zookeeper.connect
zookeeper集群的地址,可以是多个,多个之间用逗号分割。(一组hostname:port/path列表,hostname是zk的机器名或IP、port是zk的端口、/path是可选zk的路径,如果不指定,默认使用根路径)
log.dirs
Kafka把所有的消息都保存在磁盘上,存放这些数据的目录通过log.dirs指定。可以使用多路径,使用逗号分隔。如果是多路径,Kafka会根据“最少使用”原则,把同一个分区的日志片段保存到同一路径下。会往拥有最少数据分区的路径新增分区。
num.recovery.threads.per.data.dir
每数据目录用于日志恢复启动和关闭时的线程数量。因为这些线程只是服务器启动(正常启动和崩溃后重启)和关闭时会用到。所以完全可以设置大量的线程来达到并行操作的目的。注意,这个参数指的是每个日志目录的线程数,比如本参数设置为8,而log.dirs设置为了三个路径,则总共会启动24个线程。
auto.create.topics.enable
是否允许自动创建主题。如果设为true,那么produce(生产者往主题写消息),consume(消费者从主题读消息)或者fetch
metadata(任意客户端向主题发送元数据请求时)一个不存在的主题时,就会自动创建。缺省为true。
delete.topic.enable=true
删除主题配置,默认未开启
3.2 主题配置
新建主题的默认参数
num.partitions
每个新建主题的分区个数(分区个数只能增加,不能减少 )。这个参数一般要评估,比如,每秒钟要写入和读取1000M数据,如果现在每个消费者每秒钟可以处理50MB的数据,那么需要20个分区,这样就可以让20个消费者同时读取这些分区,从而达到设计目标。(一般经验,把分区大小限制在25G之内比较理想)
log.retention.hours
日志保存时间,默认为7天(168小时)。超过这个时间会清理数据。bytes和minutes无论哪个先达到都会触发。与此类似还有log.retention.minutes和log.retention.ms,都设置的话,优先使用具有最小值的那个。(提示:时间保留数据是通过检查磁盘上日志片段文件的最后修改时间来实现的。也就是最后修改时间是指日志片段的关闭时间,也就是文件里最后一个消息的时间戳)
log.retention.bytes
topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限制。log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除。(注意如果是log.retention.bytes先达到了,则是删除多出来的部分数据),一般不推荐使用最大文件删除策略,而是推荐使用文件过期删除策略。
log.segment.bytes
分区的日志存放在某个目录下诸多文件中,这些文件将分区的日志切分成一段一段的,我们称为日志片段。这个属性就是每个文件的最大尺寸;当尺寸达到这个数值时,就会关闭当前文件,并创建新文件。被关闭的文件就开始等待过期。默认为1G。
如果一个主题每天只接受100MB的消息,那么根据默认设置,需要10天才能填满一个文件。而且因为日志片段在关闭之前,消息是不会过期的,所以如果log.retention.hours保持默认值的话,那么这个日志片段需要17天才过期。因为关闭日志片段需要10天,等待过期又需要7天。

log.segment.ms
作用和log.segment.bytes类似,只不过判断依据是时间。同样的,两个参数,以先到的为准。这个参数默认是不开启的。
message.max.bytes
表示一个服务器能够接收处理的消息的最大字节数,注意这个值producer和consumer必须设置一致,且不要大于fetch.message.max.bytes属性的值(消费者能读取的最大消息,这个值应该大于或等于message.max.bytes)。该值默认是1000000字节,大概900KB~1MB。如果启动压缩,判断压缩后的值。这个值的大小对性能影响很大,值越大,网络和IO的时间越长,还会增加磁盘写入的大小。
Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好(LinkedIn的kafka性能测试)
4.硬件配置对Kafka性能的影响
为Kafka选择合适的硬件更像是一门艺术,就跟它的名字一样,我们分别从磁盘、内存、网络和CPU上来分析,确定了这些关注点,就可以在预算范围之内选择最优的硬件配置。
磁盘吞吐量/磁盘容量
磁盘吞吐量(IOPS 每秒的读写次数)会影响生产者的性能。因为生产者的消息必须被提交到服务器保存,大多数的客户端都会一直等待,直到至少有一个服务器确认消息已经成功提交为止。也就是说,磁盘写入速度越快,生成消息的延迟就越低。(SSD固态贵单个速度快,HDD机械偏移可以多买几个,设置多个目录加快速度,具体情况具体分析)
磁盘容量的大小,则主要看需要保存的消息数量。如果每天收到1TB的数据,并保留7天,那么磁盘就需要7TB的数据。
内存
Kafka本身并不需要太大内存,内存则主要是影响消费者性能。在大多数业务情况下,消费者消费的数据一般会从内存(页面缓存,从系统内存中分)中获取,这比在磁盘上读取肯定要快的多。一般来说运行Kafka的JVM不需要太多的内存,剩余的系统内存可以作为页面缓存,或者用来缓存正在使用的日志片段,所以我们一般Kafka不会同其他的重要应用系统部署在一台服务器上,因为他们需要共享页面缓存,这个会降低Kafka消费者的性能。

网络
网络吞吐量决定了Kafka能够处理的最大数据流量。它和磁盘是制约Kafka拓展规模的主要因素。对于生产者、消费者写入数据和读取数据都要瓜分网络流量。同时做集群复制也非常消耗网络。
CPU
Kafka对cpu的要求不高,主要是用在对消息解压和压缩上。所以cpu的性能不是在使用Kafka的首要考虑因素。
总结
我们要为Kafka选择合适的硬件时,优先考虑存储,包括存储的大小,然后考虑生产者的性能(也就是磁盘的吞吐量),选好存储以后,再来选择CPU和内存就容易得多。网络的选择要根据业务上的情况来定,也是非常重要的一环。