目录
1、堆的概念和结构
1.1、堆的概念
1.2、堆的性质
1.3、堆的逻辑结构和存储结构
2、堆的实现
2.1、堆的初始化和初始化
2.2、堆的插入和向上调整算法
2.3、堆的删除和向下调整算法
2.4、取堆顶的数据和数据个数
2.5、堆的判空和打印
2.6、测试
3、堆的应用
3.1、堆排序
3.1.1、建堆
3.1.2、排序
4、TOP-K问题
1、堆的概念和结构
1.1、堆的概念
简单理解堆是一个数组,可以把数组看成一个完全二叉树,根节点最大的堆是大根堆,根节点最小的堆是小根堆
1.2、堆的性质
堆中某个结点的值总是不大于或者不小于其父结点的值
(即树中所有的父亲都是<=孩子或者>=孩子)
堆是一棵完全二叉树
1.3、堆的逻辑结构和存储结构
堆的逻辑结构是一个完全二叉树,存储结构是数组

2、堆的实现
2.1、堆的初始化和初始化
void HeapInit(HP* php);
void HeapDestory(HP* php);//堆的初始化
void HeapInit(HP* php)
{assert(php);php->a = NULL;//扩容errorphp->size = php->capacity = 0;
}
//堆的销毁
void HeapDestory(HP* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}2.2、堆的插入和向上调整算法
在堆尾插入数据后,在插入的位置开始向上调整,依然保持堆结构

void HeapPush(HP* php,HPDataType x);void AdjustUp(HPDataType* a, int child)
{assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}void HeapPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){//扩容int NewCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HP* temp = (HP*)realloc(php->a, NewCapacity*sizeof(HPDataType));if (temp == NULL){printf("realloc fail\n");exit(-1);}php->a = temp;php->capacity = NewCapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size-1);
}2.3、堆的删除和向下调整算法
堆要删除一个数据,一般是删除堆顶的数据,如果直接删除堆顶的数据,那么堆的结构全部乱了,要重新建堆,时间复杂度高,并且没有用到堆的特性,具体做法是将堆顶的数据和堆尾的数据进行交换,再采用向下调整算法重新生成一个堆。
向下调整算法的前提是左右子树都是堆
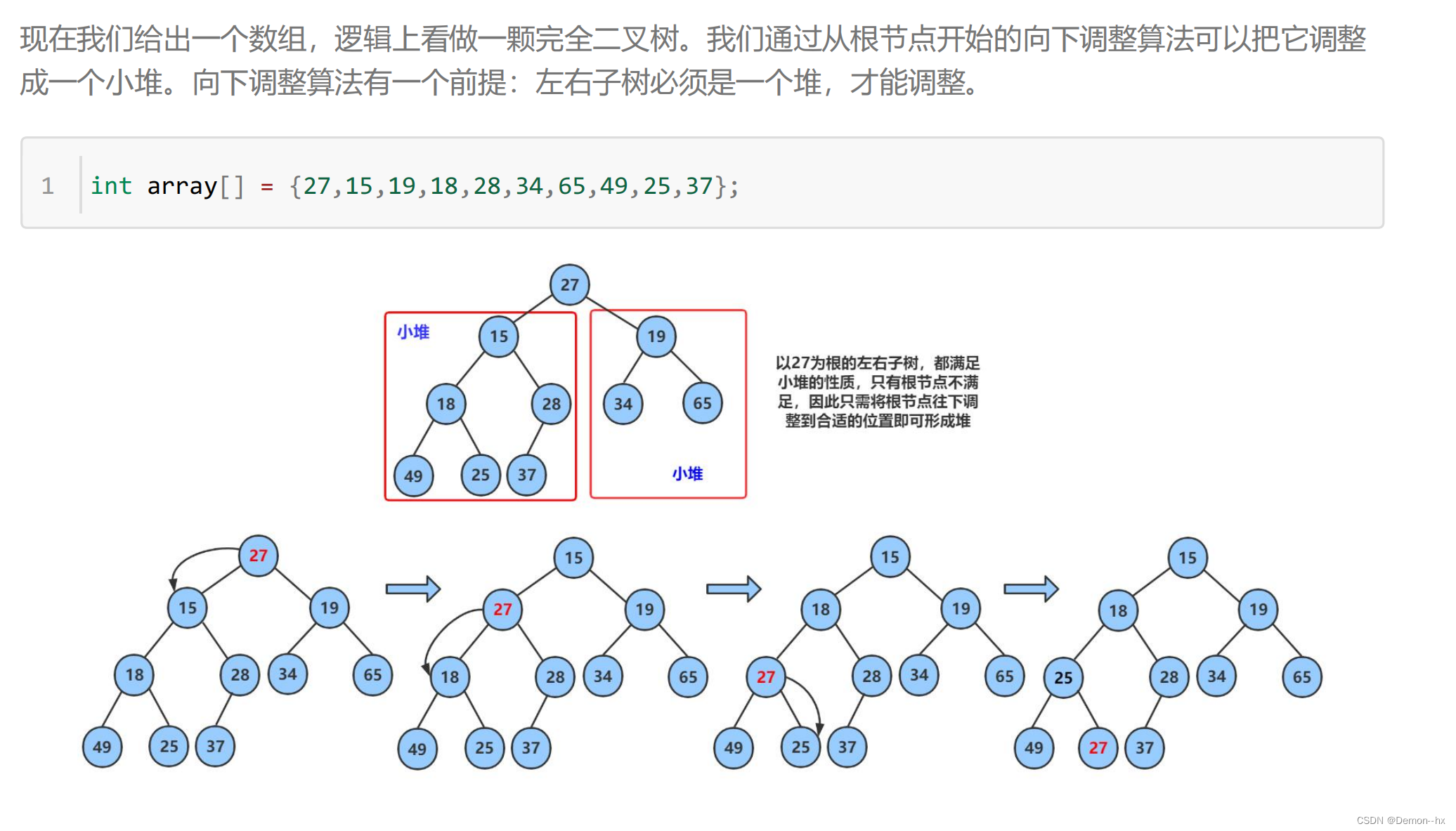
void HeapPop(HP* php);// 删除小堆堆顶的元素
//思路:选出左右孩子小的一个
// 小的孩子比父亲小,交换数据,继续向下调整,孩子如果比父亲大,调整结束
void AdjustDown(HPDataType* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){
//右孩子下标要小于数组的范围sizeif (child + 1 < size && a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}
}//删除堆里的数据 还要保持大小堆
void HeapPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&(php->a[0]), &(php->a[php->size-1]));php->size--;AdjustDown(php->a, php->size, 0);
}2.4、取堆顶的数据和数据个数
HPDataType HeapTop(HP* php);//取堆顶的数据
int HeapSize(HP* php); //堆的数据个数HPDataType HeapTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}int HeapSize(HP* php)
{assert(php);return php->size;
}2.5、堆的判空和打印
bool HeapEmpty(HP* php);//堆的判空
void HeapPrint(HP* php);//堆的打印bool HeapEmpty(HP* php)
{assert(php);return php->size == 0;
}void HeapInit(HP* php)
{assert(php);php->a = NULL;//扩容errorphp->size = php->capacity = 0;
}2.6、测试
#define _CRT_SECURE_NO_WARNINGS 1
#include"Heap.h"void HeapTest()
{HP hp;HeapInit(&hp);int a[] = { 27,15,19,18,28,34,65,49,25,37 };for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){HeapPush(&hp, a[i]);}printf("堆插入完成:");HeapPrint(&hp);//排升序 建小堆 将堆顶的数据回写到数组中//排降序 建大堆 将堆顶的数据回写到数组中int i = 0;while (!HeapEmpty(&hp)){//printf("%d ", HeapTop(&hp));//HeapPop(&hp);a[i++] = HeapTop(&hp);HeapPop(&hp);}printf("回写到数组的升序序列:");for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++){printf("%d ", a[i]);}printf("\n");
}
int main()
{HeapTest();
}//运行结果:
//堆插入完成:15 18 19 25 28 34 65 49 27 37
//回写到数组的升序序列:15 18 19 25 27 28 34 37 49 653、堆的应用
3.1、堆排序
3.1.1、建堆
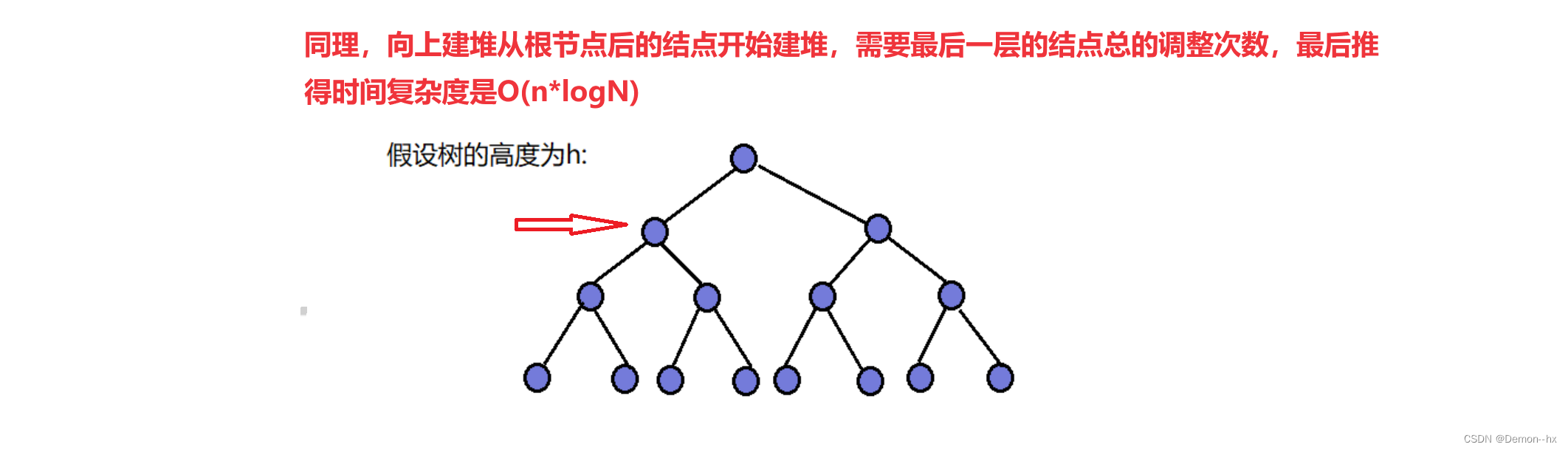
建堆有两种方式:向上建堆和向下建堆
向下建堆的时间复杂度是O(n)

向上建堆的时间复杂度是O(n*logN)
3.1.2、排序
建堆完成后,排升序,建大堆,排降序,建小堆
假设要排升序,需要建立大堆,将堆顶的数据和堆尾的数据交换,再用向下调整算法重新将次大的数排到堆顶位置,依次循环上述步骤,最后得到升序的序列
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){if (child + 1 < size && a[child + 1] > a[child]){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}elsebreak;}
}
void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2;i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
void HeapSortTest()
{int a[] = { 27,15,19,18,28,34,65,49,25,37 };HeapSort(a, sizeof(a) / sizeof(int));for (int i = 0; i < sizeof(a) / sizeof(int); i++){printf("%d ", a[i]);}
}
int main()
{HeapSortTest();return 0;
}//输出结果 15 18 19 25 27 28 34 37 49 654、TOP-K问题
TOP-K问题:即求数据结合中前K个最大元素或者最小元素,一般情况下数据量都比较大。
思路1:堆排序 时间复杂度O(N*logN)
思路2:将这N个元素建成大堆, Top和Pop K次 时间复杂度 O(O(n)+k*logN);
假设有N个元素,N非常大,有100亿个元素,k比较小,为100,求找出N中的前100大的元素。
前面两种思路当数据量特别大时求解不太容易现实,100亿个整数要占用40G的内存(1G=1024MB=1024*1024kb=1024*1024*1024byte 1G占10亿字节左右),明显不合适。
思路:
1、选取前K个数建小堆
2、剩下的N-K个数每次和小堆堆顶的数据比较,如果比堆顶的数据大,则交换堆顶的数据,比完后,最后堆里的K个数,就是最大的前K个数。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
#include<assert.h>
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//向下调整算法
void AdjustDown(int* a, int size, int parent)
{int child = parent * 2 + 1;while (child < size){if (child+1<size&&a[child + 1] < a[child]){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent*2+1;}else{break;}}
}
void TopK(int* a, int n, int k)
{int* KMinHeap = (int*)malloc(sizeof(int) * k);assert(KMinHeap);//选出n中前k个数for (int i = 0; i < k; i++){KMinHeap[i] = a[i];}//对前k个数进行建堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(KMinHeap, k, i);}//n-k个数依次和堆顶数据进行交换for (int i = k; i < n; i++){if (a[i] > KMinHeap[0]){//Swap(&KMinHeap[0], &a[i]);KMinHeap[0] = a[i];AdjustDown(KMinHeap, k, 0);}}//打印前k大的数for (int i = 0; i < k; i++){printf("%d ", KMinHeap[i]);}printf("\n");
}
void TestTopK()
{int n = 10000;int* a = (int*)malloc(sizeof(int) * n);srand(time(0));for (int i = 0; i < n; i++){a[i] = rand() % 100000;}a[5] = 100000 + 1;a[1231] = 100000 + 2;a[531] = 100000 + 3;a[5121] = 100000 + 4;a[115] = 100000 + 5;a[2335] = 100000 + 6;a[9999] = 100000 + 7;a[76] = 100000 + 8;a[423] = 100000 + 9;a[3144] = 100000 + 10;TopK(a, n, 10);
}
int main()
{TestTopK();return 0;
}
//输出结果:100001 100002 100003 100004 100005 100007 100009 100006 100008 100010