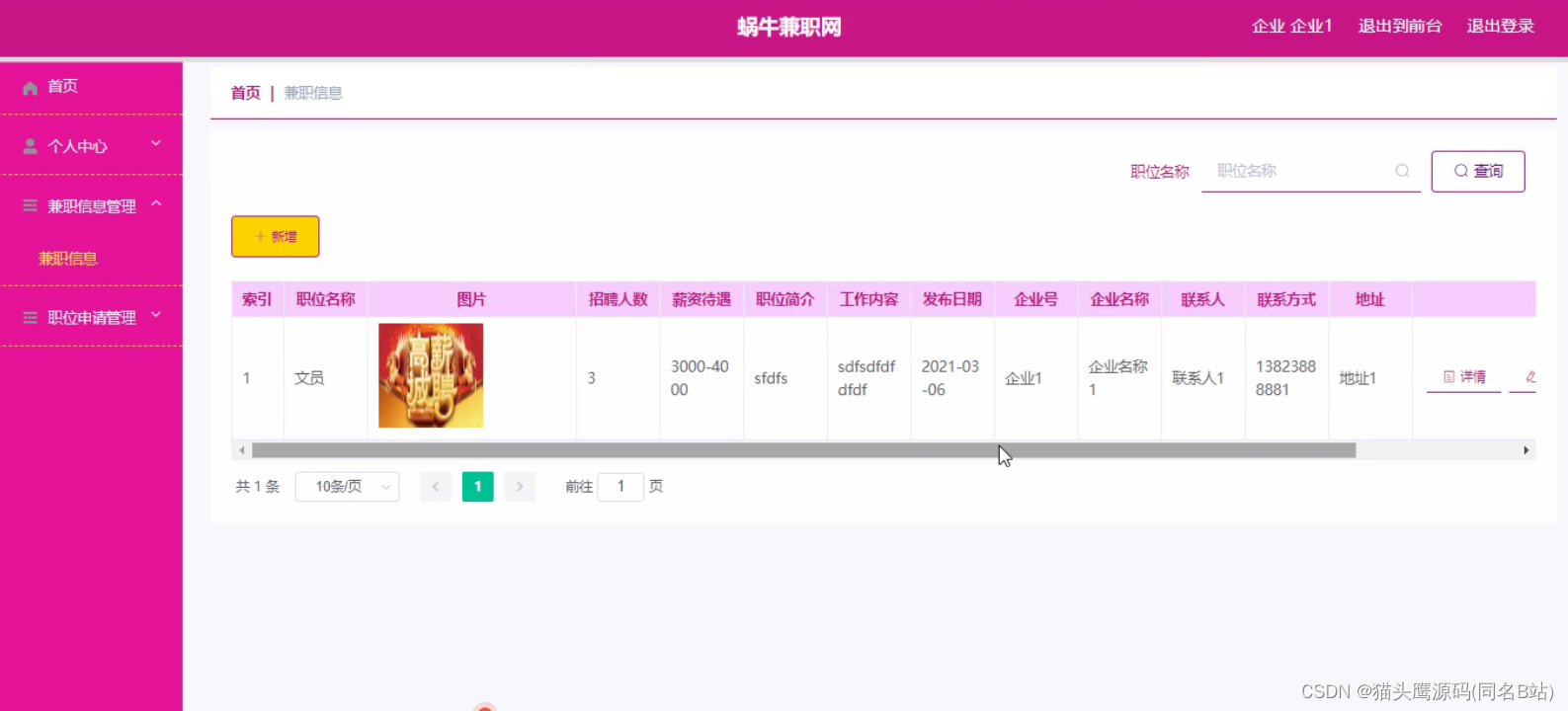
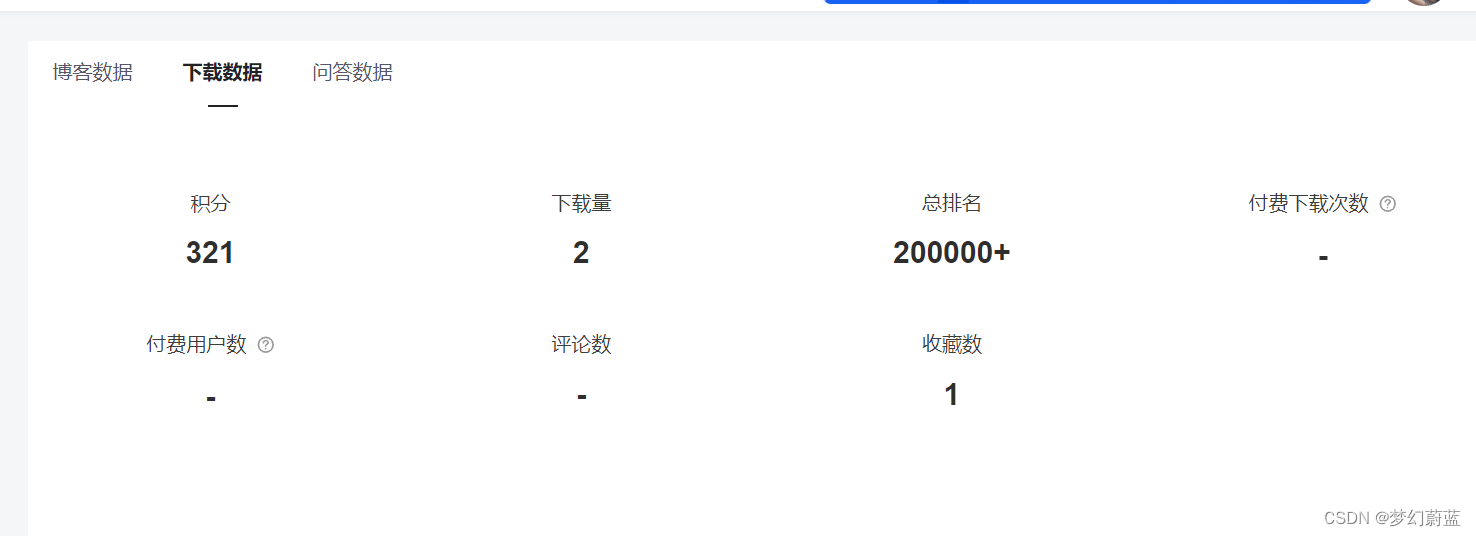
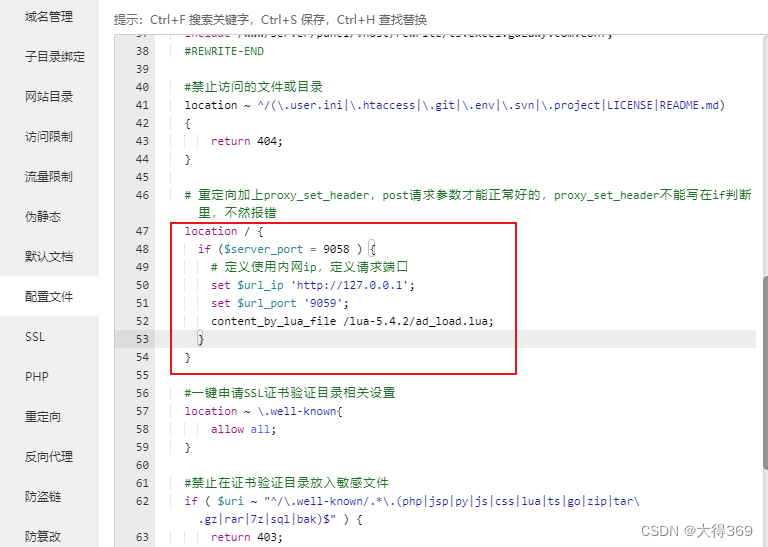
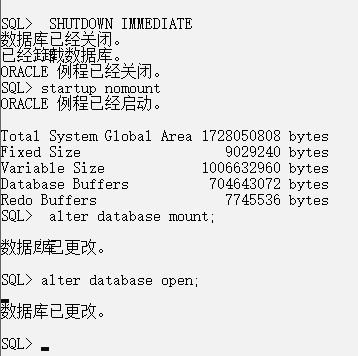
当下如火如荼的大模型,其中的关键技术就是注意力机制(Attention),于2015年提出。2017年的“Attention is all you need”一文提出了Transformer模型,去掉RNN,只保留注意力,性能吊打所有机器翻译模型,是NLP发展的一个里程碑。
Attention的最主要的用途是自然语言处理,比如机器翻译、情感分析;也有学者将其用于图像处理,比如Vision Transformer(ViT),用了自注意力机制进一步提高了模型在ImageNet的分类性能。
目录
- 含义
- 计算步骤
- 输入x映射到三元组(q,k,v)
- 计算权重向量 α
- 计算输出向量 c
- 注意力的意义
- 公式总结
- 多头自注意力
- 多头的意义
含义
注意力机制(Attention)最初用于改进循环神经网络(RNN),提高Sequence-to-Sequence (Seq2Seq) 模型的表现,主要是为了缓解模型对于长序列的遗忘问题。注意力机制允许模型在处理数据时,动态地关注数据的某些部分,而非静态地处理整个输入。
自注意力机制 (Self-Attention) 是注意力机制的一种扩展,不局限于 Seq2Seq 模型,可以用于任意的 RNN。它允许模型在处理一个序列时,计算序列内各个元素之间的相互关系。
后来 Transformer 模型将 RNN 剥离,只保留注意力机制。 与 RNN + 注意力机制相比,只用注意力机制居然表现更好,在机器翻译等任务上的效果有大幅提升。
自注意力层的输入是序列(x1,…,xm),其中向量的大小都是din * 1。
其有两个显著优点,
第一,序列的长度 m 可以是不确定的,可以动态变化。但是神经网络的参数数量保持不变。
第二,输出的向量 ci 不是仅仅依赖于向量 xi,而是依赖于所有的输入向量 (x1, …, xm)。
自注意力层有三个参数矩阵,分别表示query、key、value:

计算步骤
输入x映射到三元组(q,k,v)
首先,对于所有的 i = 1, · · · , m,把输入的 xi 映射到三元组 (qi, ki, vi):


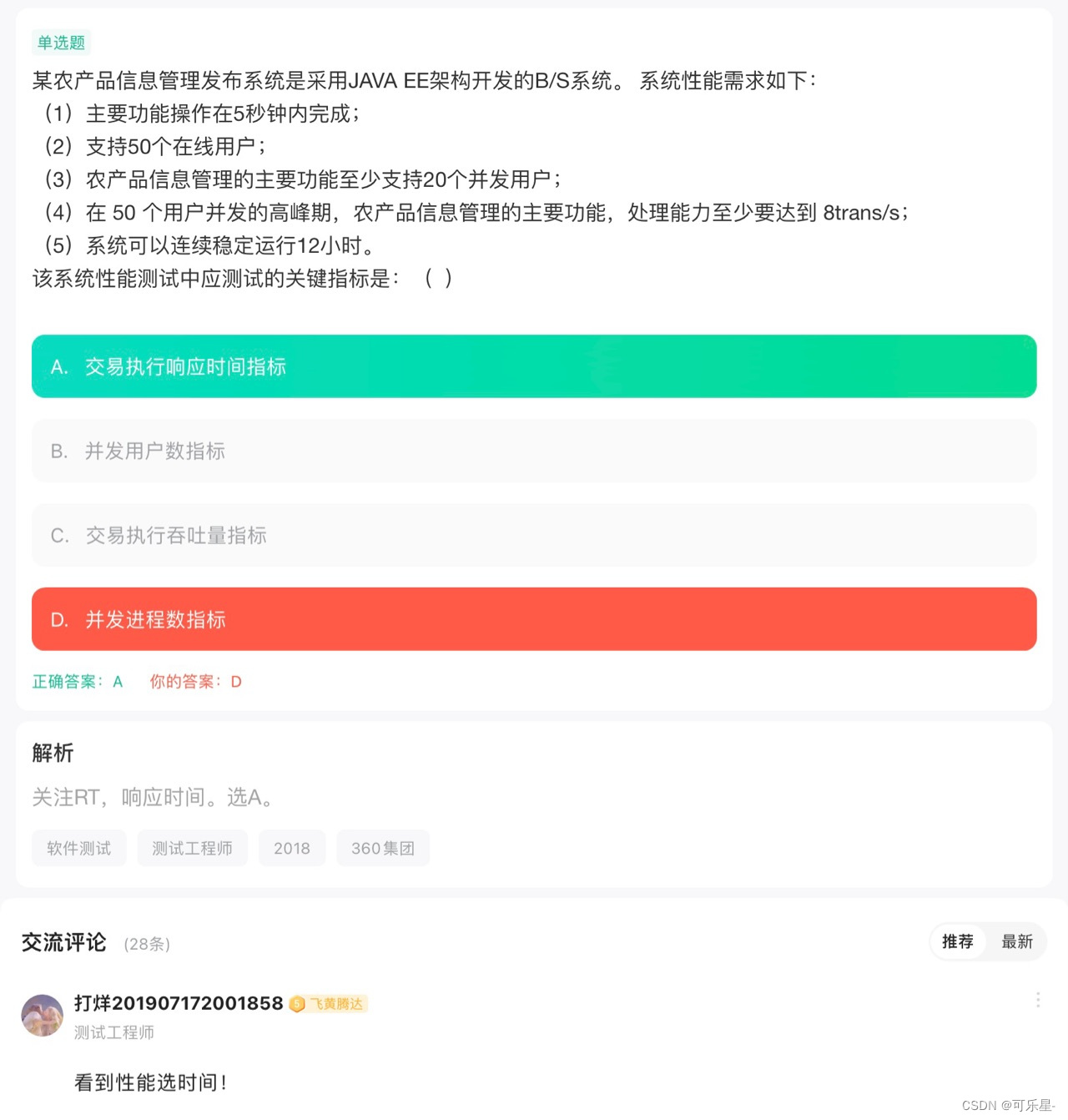
计算权重向量 α

计算输出向量 c

注意力的意义

公式总结

dk是K的维度,用来缩放点积,避免得到太大的数值。
非常推荐大家去阅读一个白话解释这个公式的博客,讲得非常好,包括为什么要有Q、K、V三个矩阵,为什么Transformer能做到并行数据处理等。《Self-attention 公式解释》
多头自注意力
上面介绍的是单头自注意力层,实践中更常用的是多头自注意力层,它是多个单头的组合。
设多头由 l 个单头组成。每个单头有自己的 3 个参数矩阵,所以多头一共有 3l 个参数矩阵。它们的输入都是序列 (x1, · · · , xm),它们的输出都是长度为 m 的向量序列。


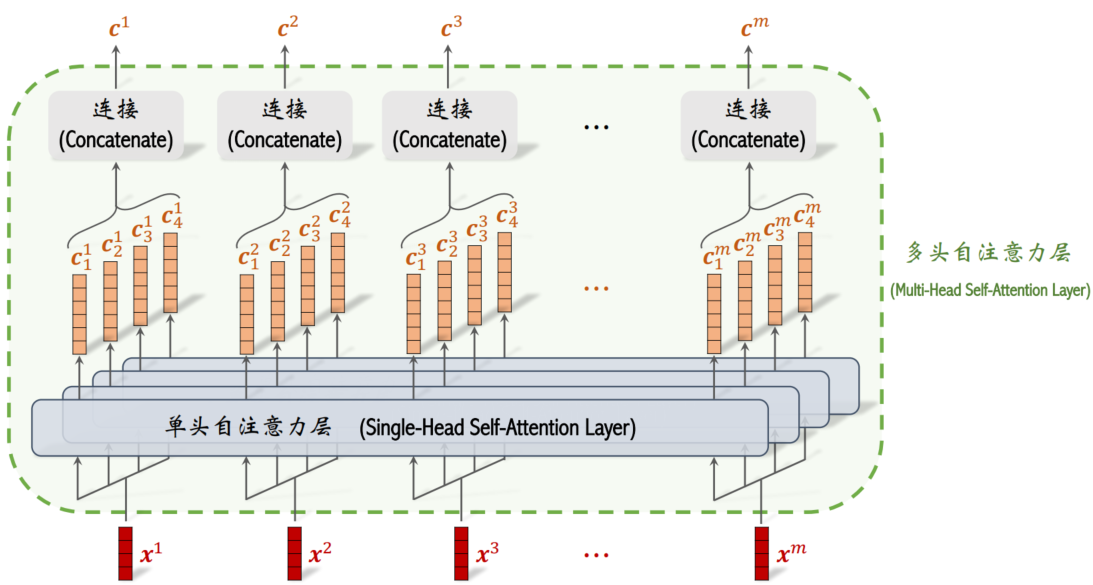
多头的意义
1、并行学习多种关系:
多头自注意力通过 并行地运行多个自注意力“头” 来实现。每个“头”学习序列中不同的特征或关系。这允许模型在不同的表示子空间中同时捕获序列的多种方面,学习更多样化的特征,如不同类型的语义和句法信息。
2、提高模型的表达能力:
多头机制增加了模型的表达能力。不同的注意力头可以关注序列的不同部分,使模型能够更全面地理解和表示数据。
总的来做,与单头相比,多头能提供更丰富的信息捕获能力和更好的泛化能力,提高了模型在处理复杂序列数据时的表达能力和性能。
本文内容为看完王树森和张志华老师的《深度强化学习》一书的学习笔记,十分推荐大家去看原书!