这篇论文探讨了大型语言模型(LLM)的成功对自然语言处理(NLP)领域的影响,并提出了在这一新时代中继续做出有意义贡献的方向。作者回顾了2005年机器翻译中大型语法模型的第一个时代,并从中汲取教训和经验。他们强调硬件进步对于塑造规模的重要性和可获得性的重要性,并指出了质量评估的紧迫挑战,包括自动化和人类评估。此外,作者认为数据仍然是许多有意义应用的瓶颈,而实际使用情况下的有意义评估仍然是一个开放问题。最后,作者指出,在大规模差距是暂时的情况下,研究人员可以努力减少它们,并且仍然有空间进行推测性的方法。总之,本文为NLP领域的未来发展提供了有益的思考和指导。

论文方法
方法描述
该论文提出了两种方法来应对自然语言处理中的数据和计算规模问题。首先,建议利用硬件的进步,因为随着计算机性能的提高,可以更容易地训练更大规模的语言模型。其次,强调研究者应该关注那些数据而不是计算成为瓶颈的小型问题,并通过国际协作、非盈利资源等方式为这些语言提供技术支持。
方法改进
论文没有提到具体的方法改进,而是着重于指出在当前的大规模语言模型时代,如何通过硬件进步和关注小规模问题来缓解数据和计算规模带来的挑战。
解决的问题
论文主要探讨了自然语言处理中数据和计算规模所带来的挑战以及如何应对这些问题。具体来说,论文指出了数据量和计算规模对于系统性能的影响,以及大规模语言模型的发展历程和现状。同时,论文也提到了如何通过利用硬件进步和关注小规模问题来缓解数据和计算规模带来的挑战。

论文实验
本文主要介绍了关于自然语言处理(NLP)中的模型训练和评估的问题,并提出了几个重要的建议。首先,文章指出了评估方法对于模型性能的影响,因此应该更加关注提高评估指标的质量。其次,文章认为人类评估存在一些问题,例如难以提供一致的评价标准和容易受到个人偏好的影响等,因此建议使用更具体的任务来衡量模型的表现。最后,文章提到了硬件对研究方向的影响,因此建议研究人员不仅要开发和利用新的硬件,还要预测未来可能的技术发展,并为此做好准备。
具体来说,本文提出了以下几个对比实验:
- 对比不同评估指标的效果:本文指出自动评估指标往往无法准确反映人类的评价,因此需要更加重视人工评估的作用。然而,人工评估也存在着一些问题,例如难以提供一致的标准和容易受到个人偏好的影响等。因此,本文建议将注意力放在具体的任务上,以便更好地评估模型的表现。
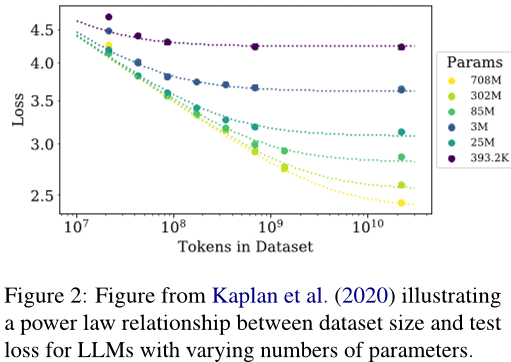
- 对比不同类型的模型:本文提到在SMT时代,大规模的词袋模型曾经是主流,但随着GPU的发展,神经网络模型逐渐成为主流。这表明硬件对于研究方向的影响非常大,因此研究人员需要考虑如何设计硬件以适应未来的科技发展趋势。
总之,本文提出了一些有关NLP中模型训练和评估的重要建议,这些建议有助于改进当前的研究方法并推动该领域的进一步发展。
论文总结
文章优点
本文回顾了大型语言模型(LLM)的发展历程,并从中总结出了一些重要的经验教训。文章以机器翻译领域为例,阐述了大规模数据的重要性以及评价指标的局限性。同时,作者还强调了研究者需要持续探索新的方法和技术,以应对未来的挑战。
方法创新点
本文的主要贡献在于通过回顾历史经验,为当前的研究提供了有价值的参考。作者提出了“规模至上”、“评估瓶颈”、“没有黄金标准”等重要观点,并针对这些问题提出了解决方案。此外,文章还指出了研究中的不确定性因素,提醒研究者要保持开放的心态,不断尝试新的方法和技术。
未来展望
随着技术的不断发展,我们相信大型语言模型将在更多的应用场景中发挥重要作用。然而,在使用这些模型时,我们需要更加谨慎地考虑其局限性和潜在的风险。因此,我们需要继续深入研究,探索更好的解决方案,以确保人工智能的安全和可持续发展。