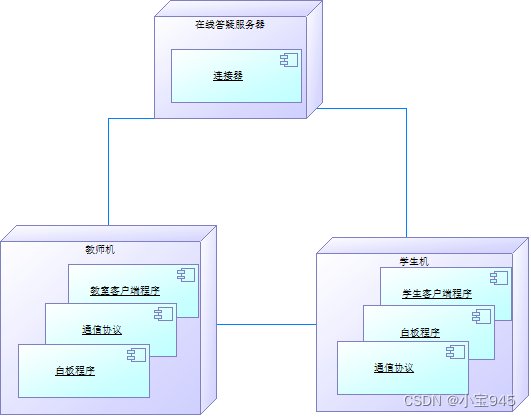
最近在写论文的实验部分,由于latex需要pdf格式的文档,审稿专家需要对pdf图片进行裁剪放大,以保证图片质量。
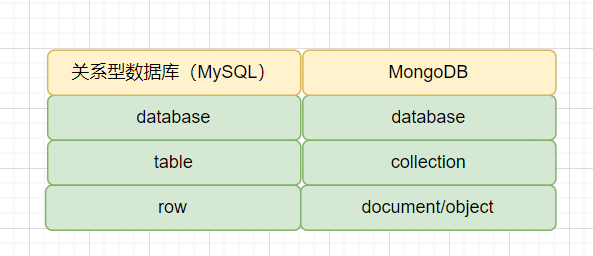
原图:

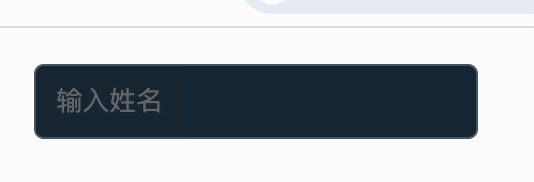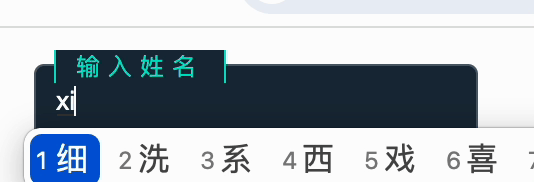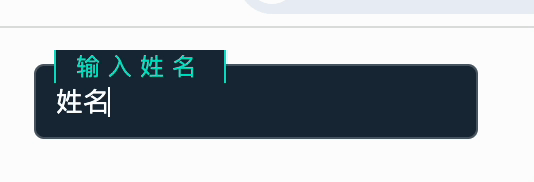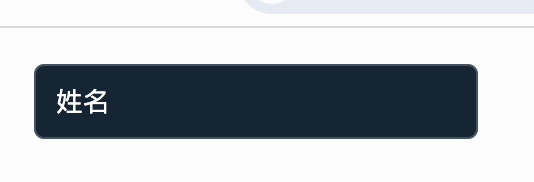
裁剪后的图像:
代码粘贴如下。将input_folder和output_folder替换即可。(x1, y1),
(x2, y2) 分别代表裁剪框的像素位置。
import os
import PyPDF2
from PIL import Imagedef crop_and_save_pdf(input_folder, output_folder, x1, y1, x2, y2):# Ensure output folder existsif not os.path.exists(output_folder):os.makedirs(output_folder)# Process each PDF file in the input folderfor filename in os.listdir(input_folder):if filename.endswith(".pdf"):input_pdf_path = os.path.join(input_folder, filename)output_png_path = os.path.join(output_folder, os.path.splitext(filename)[0] + ".png")output_pdf_path = os.path.join(output_folder, os.path.splitext(filename)[0] + ".pdf")with open(input_pdf_path, 'rb') as file:pdf_reader = PyPDF2.PdfReader(file)pdf_writer = PyPDF2.PdfWriter()for page_num in range(len(pdf_reader.pages)):page = pdf_reader.pages[page_num]page.cropbox.lower_left = (x1, y1)page.cropbox.upper_right = (x2, y2)pdf_writer.add_page(page)with open(output_pdf_path, 'wb') as output_file:pdf_writer.write(output_file)# Convert the first page to PNG format for visualization# first_page = Image.open(output_pdf_path)# first_page.save(output_png_path, 'PNG')# Specify input and output folders, and crop coordinates
input_folder = '/home/lxy/data_link2/evaluate/clip/HU_Compare'
output_folder = '/home/lxy/data_link2/evaluate/clip/HU_Compare2'
x1, y1 = 50, 400 # Left bottom coordinates
x2, y2 = 130, 550 # Right top coordinates# Call the function to crop and save PDF pages as PNG
crop_and_save_pdf(input_folder, output_folder, x1, y1, x2, y2)