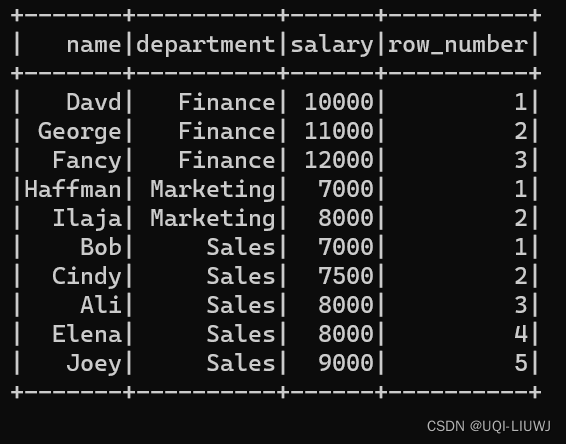
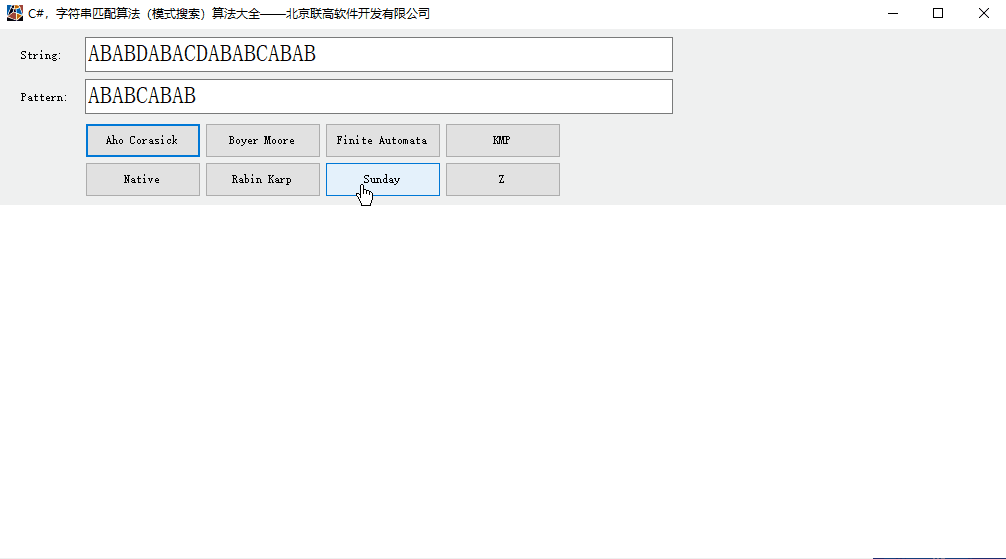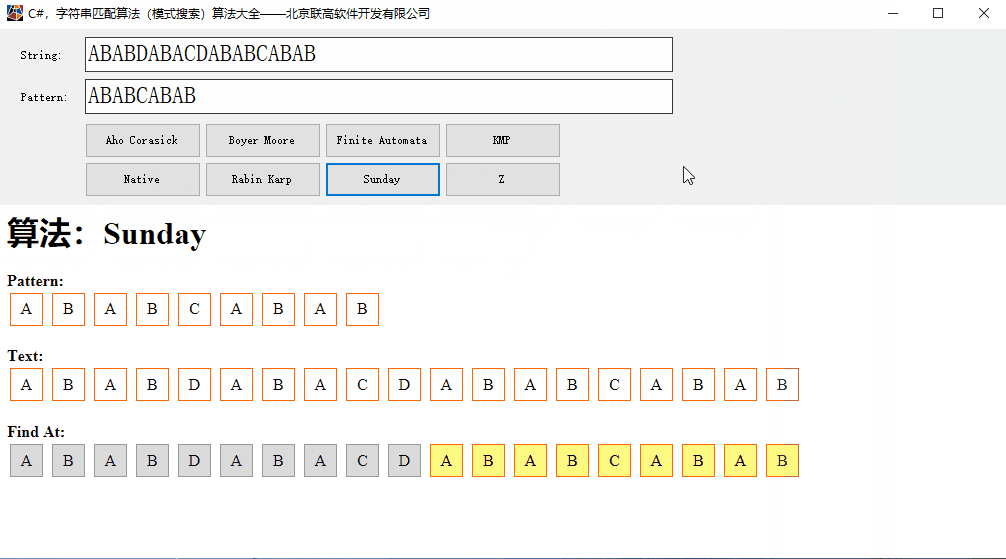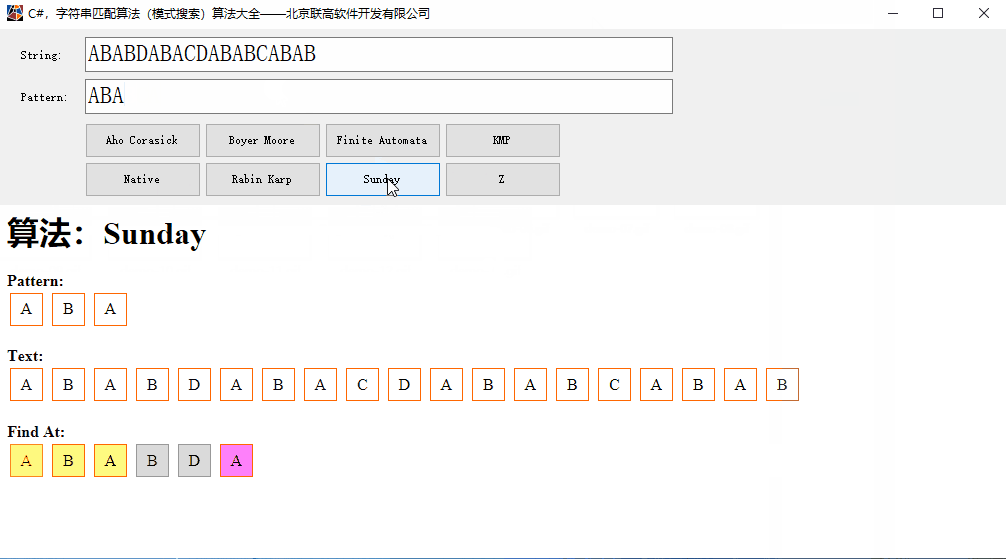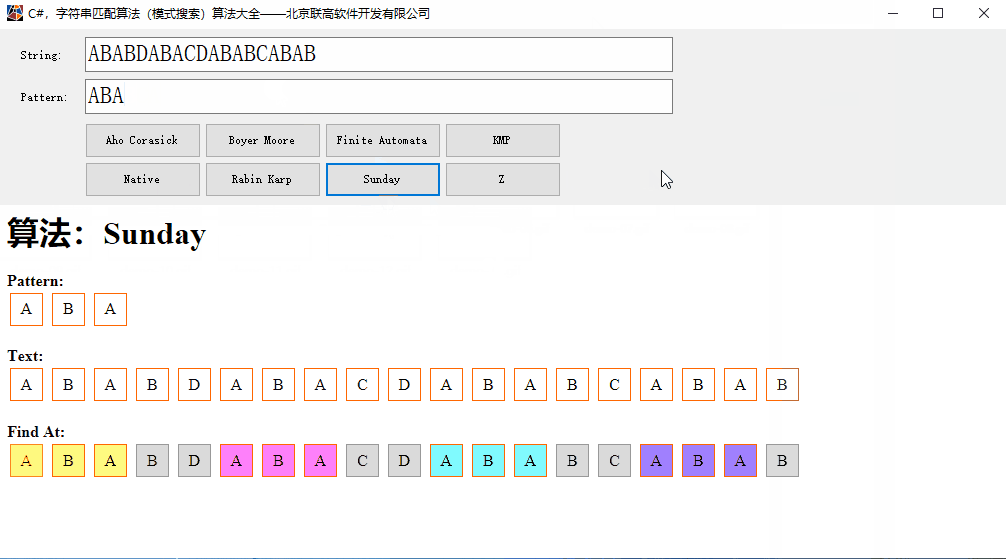
0 1 云原生技术的普及与发展
云原生技术是一种基于容器技术的轻量级、高可用的应用架构,具有弹性扩展、快速部署、统一管理等特点。随着企业对敏捷开发和快速迭代的需求不断增加,云原生技术的普及与发展已成为不可逆转的趋势。
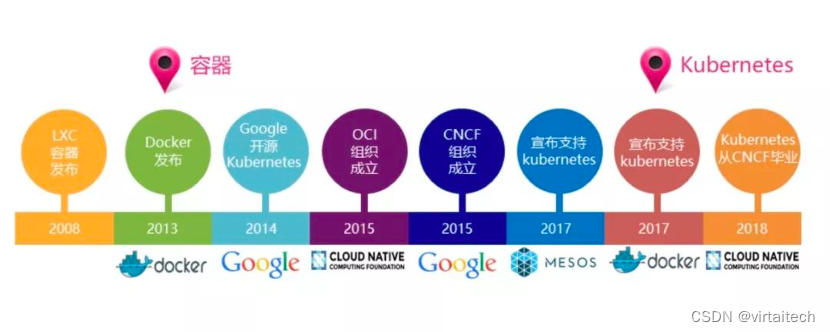 图1. 云原生技术发展之路
图1. 云原生技术发展之路
云原生技术通过将应用与底层基础设施解耦,实现了应用的快速部署和动态扩展。它采用了容器化、微服务、CICD等技术手段,使得应用可以更加高效地运行在云环境中。同时,云原生技术还提供了强大的监控和日志功能,帮助企业更好地管理和维护应用。

图2. 云原生三大特征
随着云原生理念的推广与技术的不断丰富,云原生已经进入成熟阶段,越来越多的企业开始采用云原生架构来构建和部署应用。当前云原生引领数字化转型升级已成为趋势,在人工智能、大数据、边缘计算、金融等领域崭露头角。云原生技术(例如:容器、微服务、DevOps等)提供的极致弹性能力和故障自愈能力已成为应用开发的最佳技术手段。原生理念及其技术以灵活性、敏捷性和便捷性已获得各行各业的广泛关注。云原生促使产业融合速度加快、网络业务迭代周期缩短。
0 2 人工智能通过容器实现最佳表现
2.1 容器非常适合人工智能应用的部署和管理
首先,容器可以帮助人工智能应用实现快速部署和动态扩展。由于容器具有轻量级、可移植性和快速部署的特性,人工智能应用可以轻松地在不同的云平台之间进行迁移和部署。同时,容器还可以根据需求动态地扩展或缩减应用,从而确保人工智能应用能够高效地应对突发流量或节省资源。
其次,容器可以帮助人工智能应用实现高可用性和容错性。容器可以在多个节点之间自动进行负载均衡和容错处理,从而确保人工智能应用的可用性和稳定性。当某个节点出现故障时,容器可以快速地将应用切换到其他节点上,从而保证应用的正常运行。
此外,容器还可以帮助人工智能应用实现数据安全和隐私保护。由于容器具有隔离性,可以限制对底层资源的访问权限,从而防止数据泄露和攻击。同时,容器还可以通过加密通信、访问控制和安全审计等手段来保护数据的安全性和隐私性。
最后,容器可以帮助人工智能应用实现高效的资源利用和管理。容器可以对CPU、内存和存储等资源进行精细化管理,从而确保人工智能应用能够高效地利用资源并降低成本。
综上所述,容器是一种非常适合人工智能应用的部署和管理方式。通过容器化人工智能应用,可以实现快速部署、动态扩展、高可用性、数据安全和资源高效利用等多种优势。
据统计,目前AI容器化场景是最常见的部署形态。这也佐证了云原生是AI应用开发、部署的最好形式。
2.2 AI应用转换为容器的好处
将整个 AI 应用程序开发到部署转换为容器的好处如下:
· 针对不同版本的框架、操作系统和边缘设备/平台,为每个 AI 模型提供单独的轻量容器。
· 每个 AI 模型可以都有一个容器,用于自定义部署。例如:一个容器对开发人员友好,而另一个容器对用户友好且无需编码即可使用。
· 每个 AI 模型的单独容器,用于 AI 项目中的不同版本或环境(开发团队、QA 团队、UAT(用户验收测试)等)。
· 容器应用程序真正更有效地加速了 AI 应用程序开发-部署,并有助于维护和管理用于多种用途的多个模型。
0 3 AI应用多种形态并存的现状
云原生技术发展之路并非一蹴而就,因为它不仅涉及到架构改变,也包括理念的变化,公司流程和人员配置的相应调整等。
此外,每个企业的IT基础设施水平是不一样的,甚至企业内部也可能存在多重基础设施形态。如KVM虚拟机,OpenStack虚拟机,VMWare虚拟机,裸服务器,虚拟化节点,docker,K8S等,不同应用在云原生进展中会存在进度不一致的现象。如果等所有云原生应用完成,则会无法尽快享受到软件定义AI算力的效益。
AI赋能千行百业,在AI浪潮席卷而来的背景下,所有人都希望尽快参与到AI的盛宴中,首先关注的是make it work,于是就不可避免的出现了多AI应用形态并存的局面。
目前主流使用AI算力的形态是最粗放的方式,即直通物理GPU或者简单切分后的vGPU直通。

图3. 常见的算力使用的方式
根据AI底层基础实施层的形态,也就有了如下的组合方式:
· 直通KVM/VMWare虚拟机。
· 直通Docker容器。
· 裸服务器直接使用。
· K8S通过device plugin挂载物理整卡使用。
· OpenStack 通过cyborg挂载物理或者虚拟GPU使用等。
0 4 OrionX赋能云原生
4.1 OrionX池化解决方案的部署灵活性
OrionX部署的灵活性可以通过3个关键字来概括:“一池多芯”、“一池多云”和“分离部署”:
“一池多芯”,即OrionX不仅支持Nvidia GPU卡,也支持国产加速卡。
“一池多云”,指软件可以部署在任何的云环境中,甚至是虚拟化节点,以及裸服务器中。
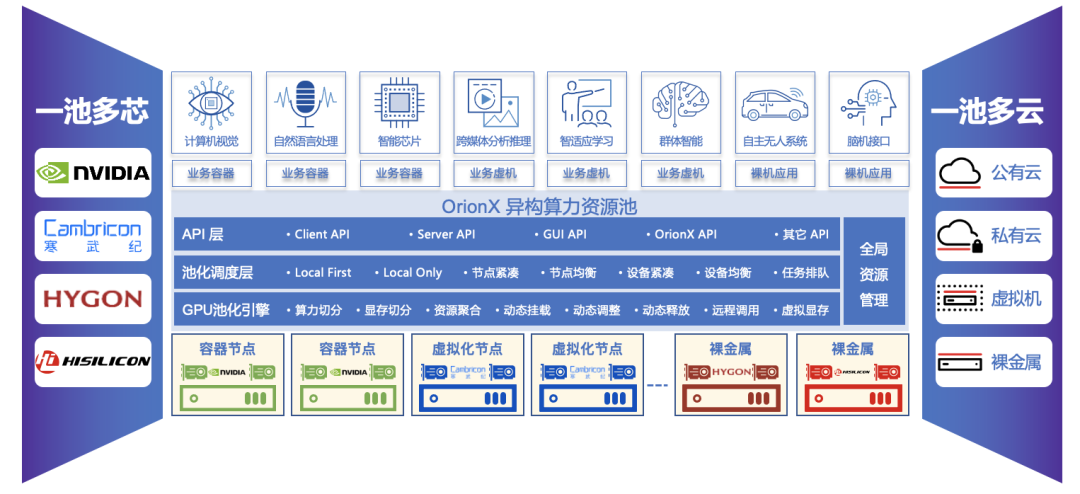
图4. OrionX支持“一池多芯,一池多云”的部署
“分离部署”,即OrionX通过远程调用,可以基于高速无损网络,跨节点甚至跨集群调取智算资源,使 AI应用与物理GPU服务器分离部署,从而进一步降低碎片化率。
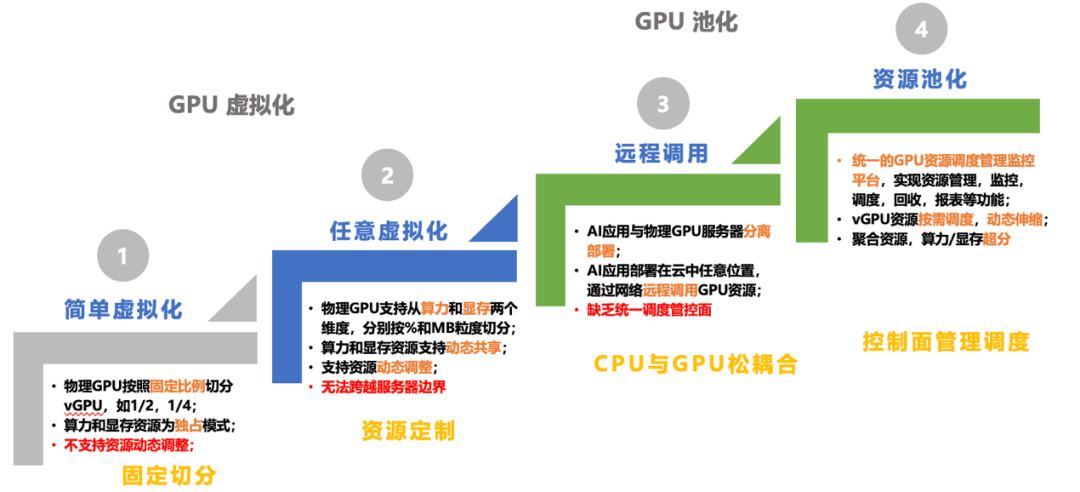
图5. 阶段3的“远程调用”能力
所以总体上,有如下两条路线可以解决云原生中多形态并存的池化算力使用问题:
· 通过“一池多云”提供“多应用-算力集群”部署。
· 通过“分离部署”提供“多应用集群-单算力集群”部署。
4.2 异构多云场景下的算力集群统一纳管
该方案是指,每种形态的应用维持原有AI算力资源拓扑使用,通过各自部署一套OrionX软件,进行AI算力的纳管和灵活高效的调度,并通过oCenter作为管理界面,进行多资源池的统一运维和管理。

图6. 异构多云算力集群统一纳管
这种方式不需要依赖于高速无损网络互联所有的服务器,部署和使用相对简单;缺点是由于每个应用环境独立维护,并由各自算力池化集群支持,所以维护成本较高、池化复用的效果没有发挥极致。
4.3 多应用集群下的算力底座
在该方案中,所有的AI算力通过部署了OrionX的智算容器云纳管,调度和分配,其它多个应用集群的应用都通过无损网络来使用这个算力集群的算力。随着时间推移,完成云原生改造的业务可以逐步向智算容器云中迁移。
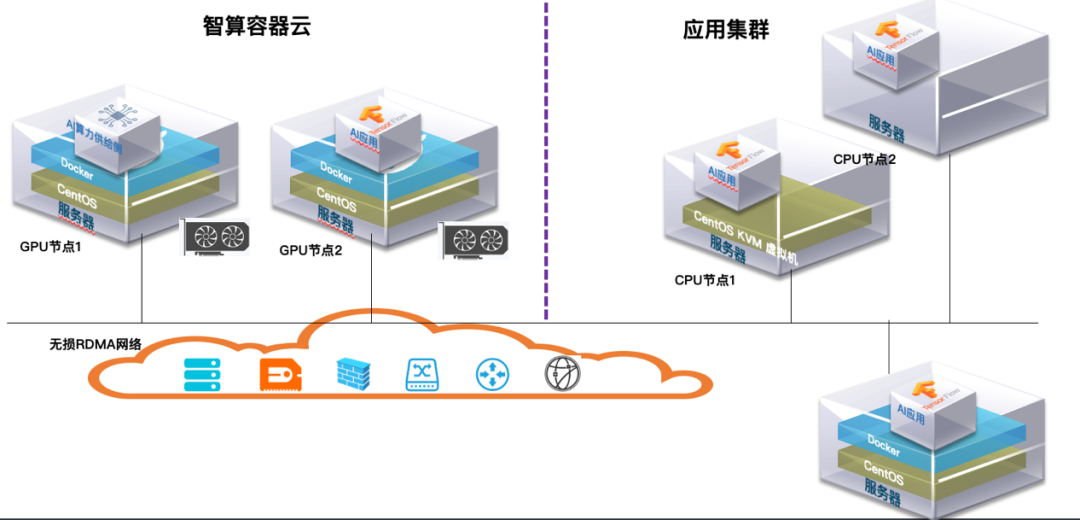
图7. 多应用场景下的算力底座
这种部署需要依赖于高速无损网络,但对运维管理和后续的逐步迁移中比较友好。
4.4 总结
这两种情况各有优缺点,建议企业在云原生演进进程中,根据各自环境情况进行选择。实际方案选择依赖于现有基础设施的几个关键因素,比如包括但不限于:集群内的互联网络技术(包括现有网路互联方式、是否有后续组网改造计划),以及多种形态集群的规模等。
归纳一下:
· 异构多云场景下的算力集群统一纳管适合于多种形态应用并存且数量较多,不同形态应用之间没有高速无损互联网络的企业。通过异构多云部署,用户可以在统一界面管理多个应用,并尽可能发挥每个集群内的AI算力效能。
· 多应用集群下的算力底座适合配置了高速无损网络的企业,通过算力池化技术,用户可远程调用智算容器云中的AI算力给多个应用,避免为了某些极少应用单独配置基础设施的采购及运维成本。
展望未来,在长距离无损网络成为现实情况下,企业将内部所有算力基础设施整合为一朵的智算容器云,会是最理想的状态。现有的方案作为中间的演进方案都具备了未来平滑演进到最终形态的企业智算基础设施。
参考文献
1. 《云原生架构:构建高可用、可伸缩的现代互联网应用》
https://www.51cto.com/article/764431.html
2.《容器技术引领数字化转型:开启高效部署和可扩展的新时代》https://baijiahao.baidu.com/s?id=1769912365777860254&wfr=spider&for=pc
3. 《通过AI 应用程序容器化实现高效的MLOps》https://www.elecfans.com/d/1863258.html