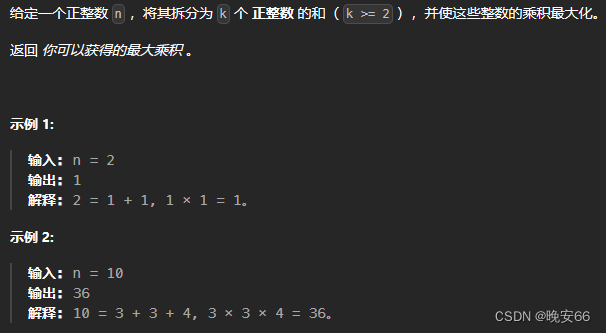
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
一、hoare版本
该算法的大体框架为:假设取数组的头为key同时保存索引变量begin的值在此处,取key的另一端为索引变量end,end不断向左移动,直至处于一个小于key的值的位置,此时再让索引变量begin不断向右移动,直至处于一个大于key的值的位置,交换两个值。由此不断循环往复,最终肯定会在一个大于key值的位置处end和begin相遇,最终交换该值与key所在的位置,即可得到一个左边比key小,右边比key大的一个数组。
由于数组是以key为基准,左右两边分别小于和大于key,所以该数组又可分为[left,key-1] , [key+1,right],然后递归调用上面的算法,左右子序列重复该过程,直至所有元素都排列在相应位置上即可。
下图为单趟快速排序的过程

程序源代码
//单趟排序
int PartSort1(int* a, int begin, int end)
{int key = a[begin];//选取左边做keyint keyindex = begin;while (begin < end){while (begin < end && a[end] >= key)//此处必须要在此判断begin<end,防止end越界{end--;}while (begin < end && a[begin] <= key){begin++;}Swap(&a[end], &a[begin]);}//此时begin == endSwap(&a[end], &a[keyindex]);//此处不能跟key交换,因为key是局部变量return begin;
}
void QuickSort(int* a, int left , int right)
{assert(a);if (left >= right){return;}int div = PartSort1(a, left, right);//[left,div - 1] div [div + 1 , right]QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}注意事项
1.若选取右边的值做key,那么一定要让左边的begin先走,这样能保证他们性欲的位置一定是一个比key大的位置...(选取左边值做key同理)
2.注意在移动begin和end的时候每次都需要判断begin<end,防止begin和end相遇之后错过,无法进行正确的排序
优化
经过分析我们发现:快速排序的最坏情况是每次选择的基准元素都是当前子数组的最大或最小值,导致每次划分只能减少一个元素的规模。在这种情况下,算法的时间复杂度接近于O(N*N),快速排序也就没有什么优势了,因此我们要做出优化。
为避免选取到最大值或者最小值,出现了三数取中法。即选取三个数的中间值作为基准,就可以很好地避免这种情况。改进后的代码变为:
//三数取中法
int GetMidIndex(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[right] < a[left]){return left;}else if (a[right] > a[mid]){return mid;}else{return right;}}else//a[left] > a[mid]{if (a[left] < a[right]){return left;}else if (a[mid] > a[right]){return mid;}else{return right;}}}
//单趟排序
int PartSort1(int* a, int begin, int end)
{int midindex = GetMidIndex(a, begin, end);Swap(&a[midindex], &a[begin]);int key = a[begin];//选取左边做keyint keyindex = begin;while (begin < end){while (begin < end && a[end] >= key){end--;}while (begin < end && a[begin] <= key){begin++;}Swap(&a[end], &a[begin]);}//此时begin == endSwap(&a[end], &a[keyindex]);//此处不能跟key交换,因为key是局部变量return begin;
}
void QuickSort(int* a, int left , int right)
{assert(a);if (left >= right){return;}int div = PartSort1(a, left, right);//[left,div - 1] div [div + 1 , right]QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}二、挖坑法
挖坑法是最主流的快速排序的方法,因为其易于理解。挖坑法,顾名思义,就是要把数据挖出来,假设以最左端位置为坑,把它的值保存在一个变量key内,定义索引变量begin和end,使end不断向左边移动,直至a[end]的值小于key,把它放在坑内,然后begin再向右移动,直至a[begin]的值大于key,把它放在a[end]的坑内。由此循环往复,我们可以得到一个与上面排序相同的结果。
程序源代码
/挖坑法
int PartSort2(int* a, int begin, int end)
{int midindex = GetMidIndex(a, begin, end);Swap(&a[midindex], &a[begin]);int key = a[begin];//坑while (begin < end){while (begin < end && a[end] >= key){end--;}a[begin] = a[end];while (begin < end && a[begin] <= key){begin++;}a[end] = a[begin];}//begin == enda[begin] = key;return begin;
}
void QuickSort(int* a, int left , int right)
{assert(a);if (left >= right){return;}int div = PartSort3(a, left, right);//[left,div - 1] div [div + 1 , right]QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}注意事项
在移动begin和end的时候,同样要每次判断begin是否小于end,防止begin和end错过
三、双指针法
双指针法相对来说较难理解一点。我们要取最后一个元素为key,定义两个变量cur,prev,其中cur是数组的首元素的索引(begin),prev位于数组首元素的前一个位置,即begin - 1。算法的思想是:cur向右不断移动,直至找到a[cur] < key,++prev,然后让prev所在位置与cur所在位置的值进行交换。依次重复这个过程,我们也可以得到跟上面两种方法相同的结果。
程序源代码
//双指针法
int PartSort3(int* a, int begin, int end)
{int midindex = GetMidIndex(a, begin, end);Swap(&a[midindex], &a[begin]);int key = a[end];int cur = begin;int prev = begin - 1;while (cur <= end){while (cur<= end && a[cur] >= key)//注意!!!{cur++;}if (cur <= end){prev++;Swap(&a[cur], &a[prev]);cur++;}}Swap(&a[++prev], &a[end]);return prev;
}
void QuickSort(int* a, int left , int right)
{assert(a);if (left >= right){return;}int div = PartSort3(a, left, right);//[left,div - 1] div [div + 1 , right]QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}
代码也可以换一种形式来呈现:
//双指针法
int PartSort3(int* a, int begin, int end)
{int prev = begin - 1;int cur = begin;int keyindex = end;while (cur <= end){if (a[cur] < a[keyindex] && a[cur] != a[keyindex]){Swap(&a[cur], &a[++prev]);}cur++;}Swap(&a[keyindex], &a[++prev]);return prev;
}
void QuickSort(int* a, int left , int right)
{assert(a);if (left >= right){return;}int div = PartSort3(a, left, right);//[left,div - 1] div [div + 1 , right]QuickSort(a, left, div - 1);QuickSort(a, div + 1, right);
}
注意事项
在初始化prev的值时,不能将其初始化为-1,要初始化为begin-1。初始化为-1,会导致子数列在进行递归时出现问题。
今天的分享到这就结束了,欢迎持续关注,有问题可以私信交流~


![[笔记]深度学习入门 基于Python的理论与实现(四)](https://img-blog.csdnimg.cn/direct/0f6664b3bb094ad5b7158a828cca73a0.png)
![O(1)插入、删除和随机元素[中等]](https://img-blog.csdnimg.cn/direct/b8aa7a047fe5435db83ed80b3f877043.jpeg)