Two Stage目标检测算法
R-CNN
R-CNN有哪些创新点?
使用CNN(ConvNet)对 region proposals 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题。
注:ILSVRC其实就是众所周知的ImageNet的挑战赛,数据量极大;PASCAL数据集(包含目标检测和图像分割等),相对较小。
R-CNN 介绍
R-CNN作为R-CNN系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用selective search提取region proposals,使用SVM实现分类。
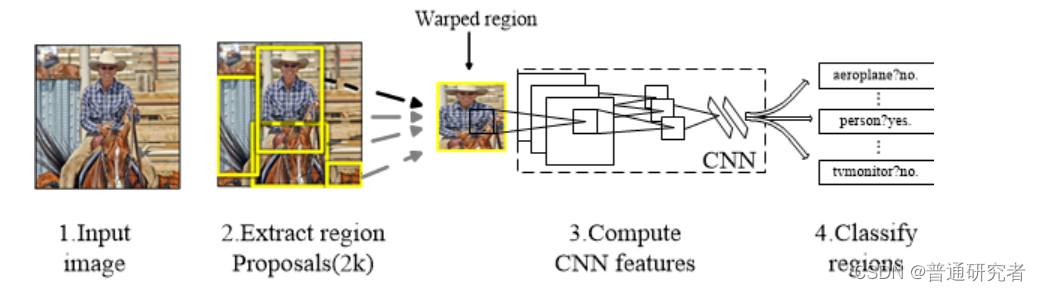
原论文中R-CNN pipeline只有4个步骤,光看上图无法深刻理解R-CNN处理机制,下面结合图示补充相应文字
1、预训练模型。选择一个预训练 (pre-trained)神经网络(如AlexNet、VGG)。
2、重新训练全连接层。使用需要检测的目标重新训练(re-train)最后全连接层(connected layer)。
3、提取 proposals并计算CNN 特征。利用选择性搜索(Selective Search)算法提取所有proposals(大约2000幅images),调整(resize/warp)它们成固定大小,以满足 CNN输入要求(因为全连接层的限制),然后将feature map 保存到本地磁盘。
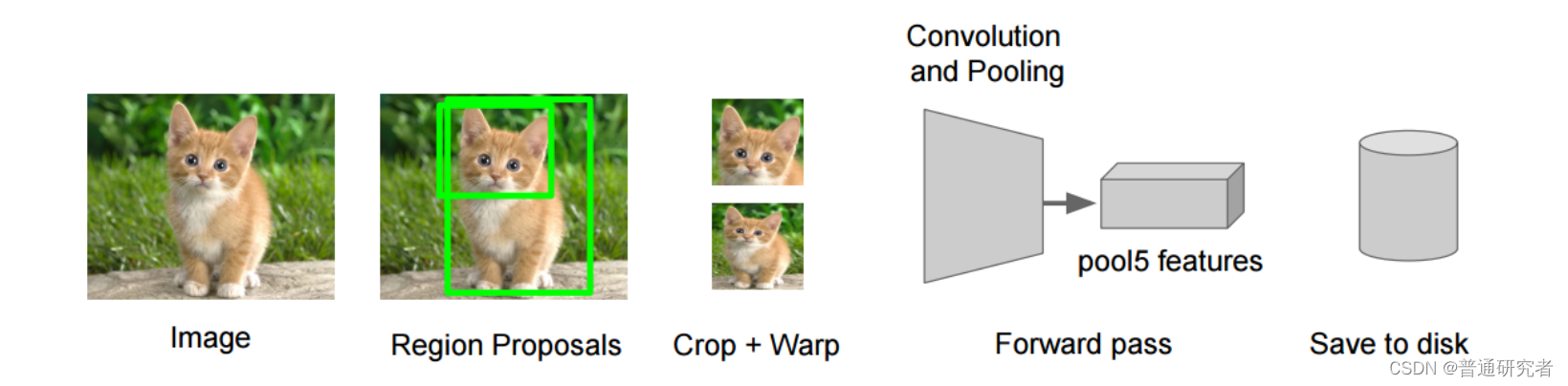
5、训练SVM。利用feature map 训练SVM来对目标和背景进行分类(每个类一个二进制SVM)
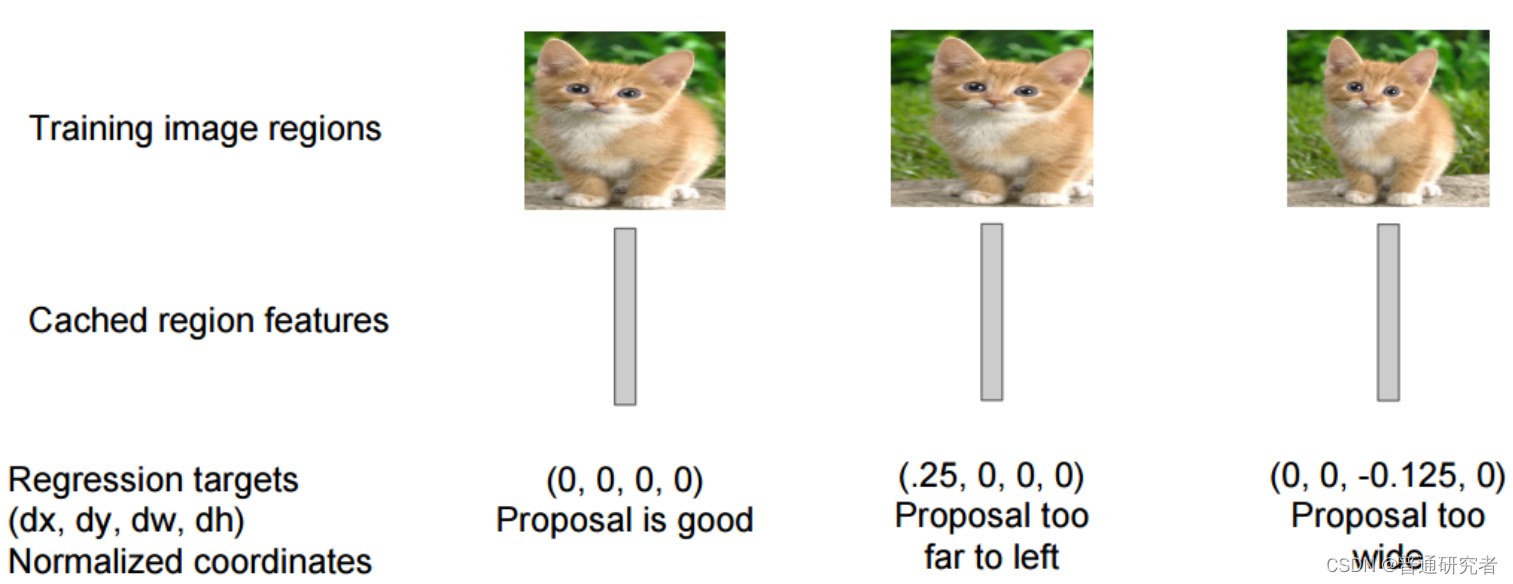
6、边界框回归(Bounding boxes Regression)。训练将输出一些校正因子的线性回归分类器
Fast R-CNN
Fast R-CNN有哪些创新点?
1、只对整幅图像进行一次特征提取,避免R-CNN中的冗余特征提取
2、用RoI pooling层替换最后一层的max pooling层,同时引入建议框数据,提取相应建议框特征
3、Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中的特征需要保持到本地,来供SVM和Bounding-box regression进行训练】
4、采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
Fast R-CNN 介绍
Fast R-CNN是基于R-CNN和SPPnets进行的改进。SPPnets,其创新点在于计算整幅图像的the shared feature map,然后根据object proposal在shared feature map上映射到对应的feature vector(就是不用重复计算feature map了)。当然,SPPnets也有缺点:和R-CNN一样,训练是多阶段(multiple-stage pipeline)的,速度还是不够"快",特征还要保存到本地磁盘中。
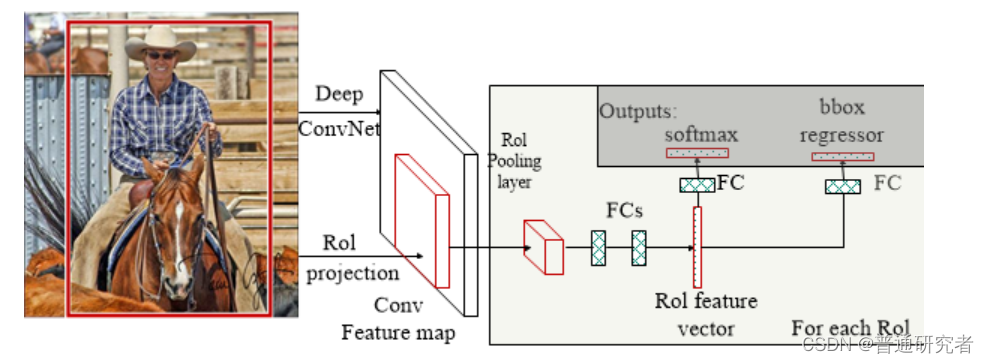
将候选区域直接应用于特征图,并使用RoI池化将其转化为固定大小的特征图块。以下是Fast R-CNN的流程图。
RoI Pooling层详解
因为Fast R-CNN使用全连接层,所以应用RoI Pooling将不同大小的ROI转换为固定大小。
RoI Pooling 是Pooling层的一种,而且是针对RoI的Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定(如7x7)。
什么是RoI呢?
RoI是Region of Interest的简写,一般是指图像上的区域框,但这里指的是由Selective Search提取的候选框。
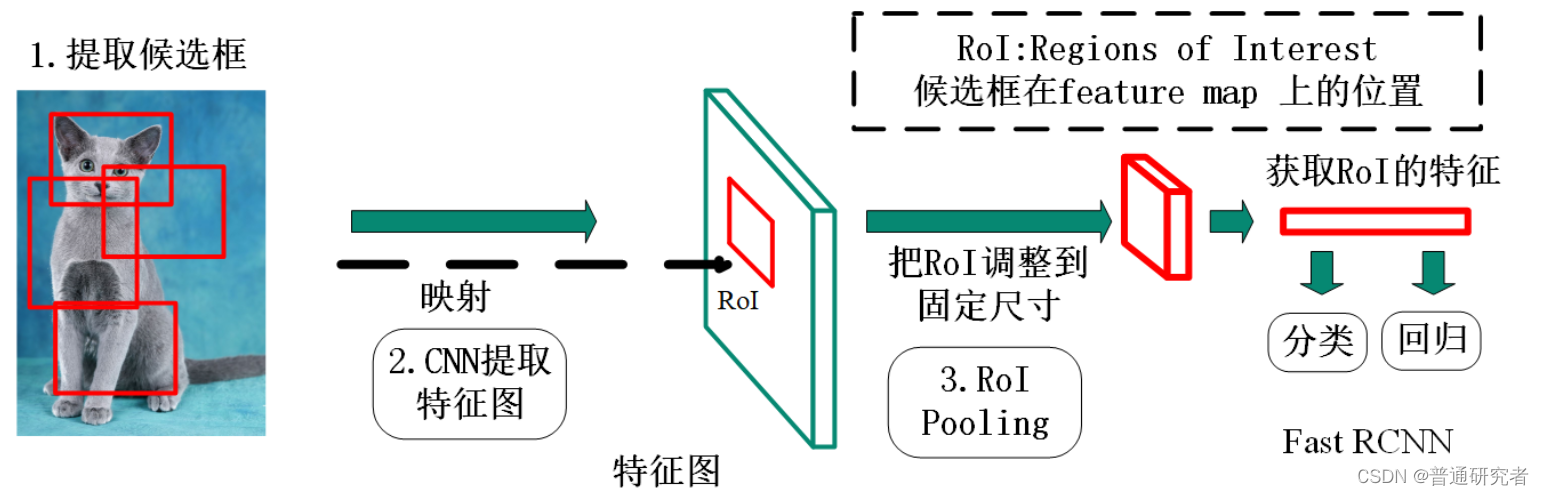
往往经过RPN后输出的不止一个矩形框,所以这里我们是对多个RoI进行Pooling。
RoI Pooling的输入
输入有两部分组成:
1、特征图(feature map):指的是上面所示的特征图,在Fast RCNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享那个特征图,通常我们常常称之为“share_conv”;
2、RoIs,其表示所有RoI的N*5的矩阵。其中N表示RoI的数量,第一列表示图像index,其余四列表示其余的左上角和右下角坐标。
在Fast RCNN中,指的是Selective Search的输出;在Faster RCNN中指的是RPN的输出,一堆矩形候选框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)。其实关于ROI的坐标理解一直很混乱,到底是根据谁的坐标来。其实很好理解,我们已知原图的大小和由Selective Search算法提取的候选框坐标,那么根据"映射关系"可以得出特征图(featurwe map)的大小和候选框在feature map上的映射坐标。至于如何计算,其实就是比值问题,下面会介绍。所以这里把ROI理解为原图上各个候选框(region proposals),也是可以的。
注:说句题外话,由Selective Search算法提取的一系列可能含有object的bounding box,这些通常称为region proposals或者region of interest(ROI)。
RoI的具体操作
1、根据输入image,将ROI映射到feature map对应位置
注:映射规则比较简单,就是把各个坐标除以“输入图片与feature map的大小的比值”,得到了feature map上的box坐标
2、将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同)
3、对每个sections进行max pooling操作
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。RoI Pooling 最大的好处就在于极大地提高了处理速度。
RoI Pooling的输出
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框。