文章目录
- 前言
- 题目
- 1 解决方案一
- 1.1 思路阐述
- 1.2 源码
- 2 解决方案二
- 2.1 思路阐述
- 2.2 源码
- 总结
前言
在接触了BM4的两个链表合并的情况,对于k个已排序列表,其实可以用合并的方法来看待问题。
这里第一种方法就是借用BM4的操作,只不过是多个合并的情况。
第二种方法是把所有的链表变成一个链表,再排序输出。调用STL库的话,这题就很取巧了。
题目
描述
合并 k 个升序的链表并将结果作为一个升序的链表返回其头节点。
数据范围:节点总数 0≤n≤5000,每个节点的val满足 ∣val∣<=1000
要求:时间复杂度 O(nlogn)
示例1
输入:[{1,2,3},{4,5,6,7}]
返回值:{1,2,3,4,5,6,7}
示例2
输入:[{1,2},{1,4,5},{6}]
返回值:{1,1,2,4,5,6}
1 解决方案一
1.1 思路阐述
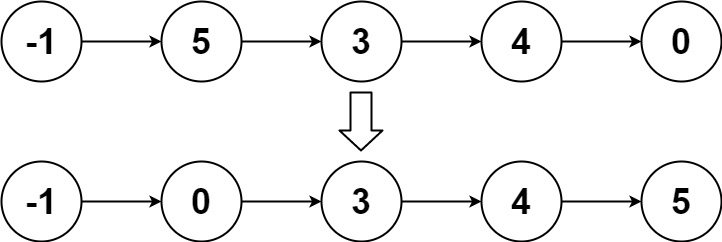
这个方案主要就是借助BM4的解法,无论哪一种都行。将原来两个链表的表变成,一个链表与一个存放链表容器中的每一个链表合并的过程。
比如对于vector容器lists,存放链表。对于lists[0]和lists[1]两个链表,在BM4中就是对应的两个有序链表合并;合并后的链表这里简称finalList,接下来就是这个finalList和lists容器中的下一个链表进行合并。重复上面的操作,直到容器内取完所有链表。
这里finalList是一个哨兵节点,是为了保证实际链表中的每一个节点都有前驱结点。
1.2 源码
#include <cstdlib>
#include <vector>
class Solution {public:ListNode* mergeKLists(vector<ListNode*>& lists) {//如果为空则返回空if(!lists.size())return nullptr;ListNode* finalList=new ListNode(-1);finalList->next=lists[0];//这里i为什么从1开始,是因为lists[0]作为finalList的初始链表了for(int i=1;i<lists.size();i++){//int j=i+1;finalList->next=Merge(finalList->next,lists[i]) ; }return finalList->next;}//下面的这个Merge函数就是BM4的一个解法,BM4有两个解法,这里我挑了一个比较好理解的。ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {ListNode* rec = new ListNode(-1);if (!pHead1 && !pHead2) {return nullptr;}if (!pHead1 && pHead2) {return pHead2;}if (pHead1 && !pHead2) {return pHead1;}//比较链表大小bool firstListBig = true;if (pHead1->val > pHead2->val) {firstListBig = true;rec->next = pHead2;} else {firstListBig = false;rec->next = pHead1;}//第二个链表大的情况if (!firstListBig) {while (pHead2 && pHead1) {if (!pHead1->next) {pHead1->next = pHead2;break;}ListNode* tempNode = pHead2->next;if (pHead2->val <= pHead1->next->val) {pHead2->next = pHead1->next;pHead1->next = pHead2;pHead2 = tempNode;pHead1 = pHead1->next;} else {pHead1 = pHead1->next;if (!pHead1->next) {pHead1->next = pHead2;break;}}}} else { //第二个链表小的情况while (pHead2 && pHead1) {if (!pHead2->next) {pHead2->next = pHead1;break;}ListNode* tempNode = pHead1->next;if (pHead1->val <= pHead2->next->val) {pHead1->next = pHead2->next;pHead2->next = pHead1;pHead1 = tempNode;pHead2 = pHead2->next;} else {pHead2 = pHead2->next;if (!pHead2->next) {pHead2->next = pHead1;break;}}}}return rec->next;}};
2 解决方案二
2.1 思路阐述
不考虑BM4的解法,这道题拿到手的第一反应,有一堆链表要合并成一个升序链表。
那最简单的方法不就是把所有链表接到一起,再用排序算法做一下咯。
这里的难点吧,我个人绝对就是对stl的使用熟练与否,以及对于特殊情情况空链表的话,怎么判断。
在C++中,std::vector 是标准模板库(STL)提供的动态数组容器。它提供了动态大小的数组,可以在运行时动态地增加或减少其大小。std::vector 是一个非常灵活和常用的容器,用于存储一系列元素。
std::vector 是一个非常常用的容器,特别适合需要频繁访问元素、动态改变大小的情况。需要注意的是,由于在中间或头部插入/删除元素的代价相对较高,如果需要频繁在中间插入或删除元素,可能需要考虑其他容器,比如 std::list。
2.2 源码
#include <cstdlib>
#include <vector>
#include <algorithm>
class Solution {public:ListNode* mergeKLists(vector<ListNode*>& lists) {//用来返回的容器vector <int> vec;//如果传入的链表容器为空则直接返回if (lists.size() == 0)return NULL;//将链表容器的链表中的所有值插入到返回容器vec中for (int i = 0; i < lists.size(); ++i) {ListNode* p = lists[i];while (p) {vec.push_back(p->val);p = p->next;}}//使用stl容器库的sort(这个是快排)sort(vec.begin(), vec.end());//对于链表容器是空的情况,虽然size>0,但是插入到vec的值其实还是空的,所以这里还要返回NULLif (vec.size() == 0)return NULL;//把vec的所有值全部放到新的链表中去,返回一个新的链表即可。ListNode* head = new ListNode(vec[0]);ListNode* p = head;for (int i = 1; i < vec.size(); ++i) {p->next = new ListNode(vec[i]);p = p->next;}return head;}};
总结
这道题是BM4的延伸,主要是多了一个两两合并的思想,对于解法二,就是有点取巧的意思了,就题论题这种。
对于解法2的sort,涉及到的是排序算法:快速排序。这个后面还是要自己手写一遍快排。