目录
- SparkSQL
- 01.快速入门
- 什么是SparkSQL
- 为什么学习SparkSQL
- SparkSQL的特点
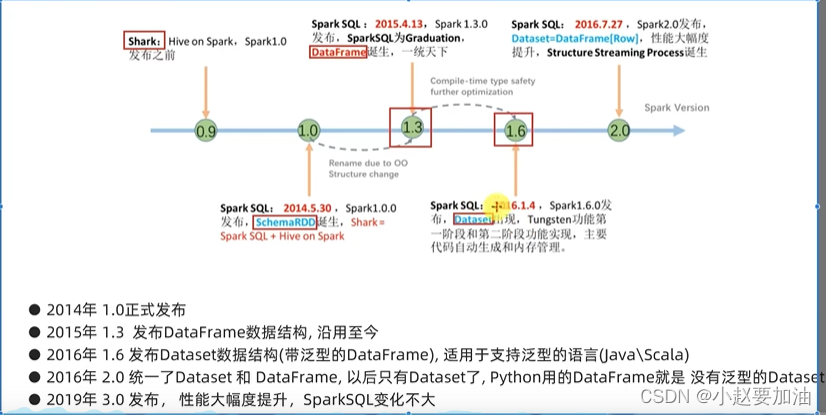
- SparkSQL发展历史-前身Shark框架
- SparkSQL发展历史
- 02.SparkSQL概述
- SparkSQL和Hive的异同
- SparkSQL的数据抽象
- DataFrame概述
- SparkSession对象
- 03.DataFrame入门和操作
- DataFrame的组成
- DataFrame的代码构建-基于RDD-1
- DataFrame的代码构建-基于RDD-2
- DataFrame的代码构建-基于RDD-3
- DataFrame的代码构建-基于Pandas的DataFrame
- DataFrame的代码构建-读取外部数据-text
- DataFrame的代码构建-读取外部数据-json
- DataFrame的代码构建-读取外部数据-csv
- DataFrame的代码构建-读取外部数据-parquet
- DataFrame的入门操作
- SparkSQL数据清洗API
- DataFrame数据写出
- 04.SparkSQL函数定义
- SparkSQL定义UDF
- SparkSQL使用窗口函数
- 05.SparkSQL的运行流程
- SparkSQL的自动优化
- Catalyst优化器
- SparkSQL的执行流程
- 06.SparkSQL整合Hive
- Hive执行流程
- SparkOn Hive
- 07.分布式SQL引擎配置
SparkSQL
01.快速入门
什么是SparkSQL
SparkSQL是Spark的一个模块,用于处理海量结构化数据
为什么学习SparkSQL
SparkSQL是非常成熟的海量结构化数据处理框架:
学习SparkSQL主要在2个点:
- SparkSQL本身十分优秀,支持SQL语言、性能强、可以自动优化、API简单、兼容HIVE等等
- 企业大面积在使用SparkSQL处理业务数据
1、离线开发
2、数仓搭建
3、科学计算
4、数据分析
SparkSQL的特点
- 融合性:SQL可以无缝集成在代码中,随时用SQL处理数据
- 统一数据访问:一套标准API可读写不同数据源
- Hive兼容:可以使用SparkSQL直接计算并生成Hive数据表
- 标准化连接:支持标准化JDBC/ODBC连接,方便和各种数据源进行数据交互
SparkSQL发展历史-前身Shark框架

SparkSQL发展历史
02.SparkSQL概述
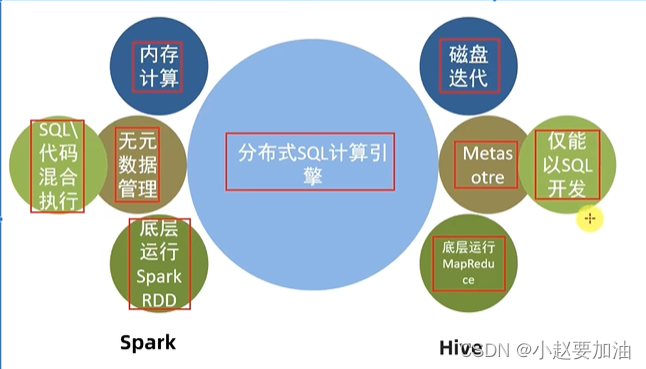
SparkSQL和Hive的异同
相同点:
1、分布式SQL计算引擎
2、构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能
不同点:
SparkSQL的数据抽象
1、SparkSQL-DataFrame
- 二维表数据结构
- 分布式结构集合(分区)
2、SparkSQL FOor JVM-DataSet【可用于Java\Scala\语言】
3、SparkSQL For Python\R-DataFrame【可用于Java\Scale\Python\R】
DataFrame概述
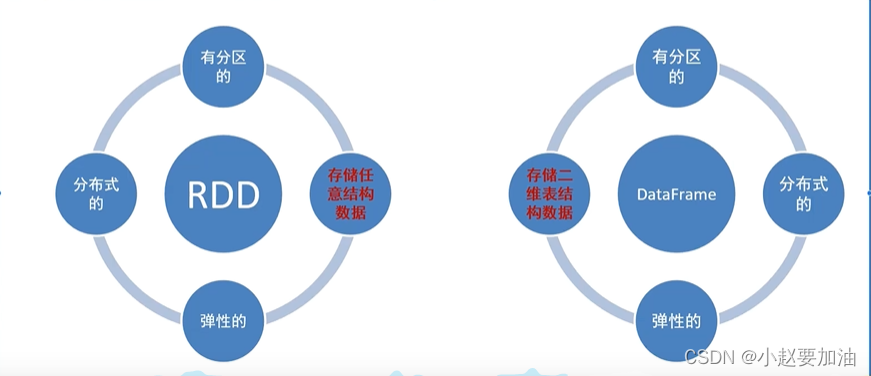
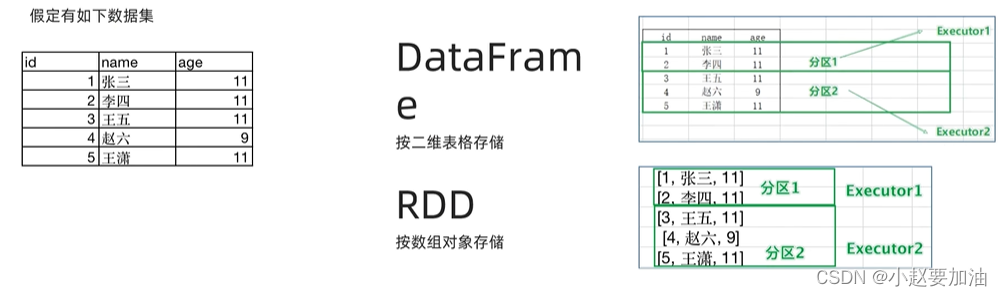
DataFrame是按照二维表格的形式存储数据
RDD则是存储对象本身
SparkSession对象
在RDD阶段,程序的执行入口对象是SparkContext
在Sparke2.0后,推出SparkSeaaion对象,作为Spark编码的统一入口对象
SparkSession对象可以:
1、用于SparkSQL编程作为入口对象
2、用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
03.DataFrame入门和操作
DataFrame的组成
DataFrame是一个二维表结构,那么表格结构就有无法绕开的三个点:
-
行
-
列
-
表结构表述
比如MySQL中的一张表: -
由许多行组成
-
数据也可以被分成多个列
-
表也有表结构信息(列、列名、列类型、列约束等)
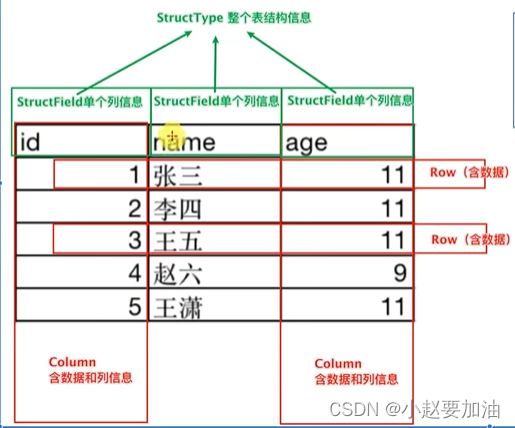
在结构层面上: -
StructType对象描述整个DataFrame的表结构
-
StructField对象描述一个列的信息
在数据层面上: -
Row对象记录一行数据
-
Column对象记录一列数据并包含列的信息
在表结构层面,DataFrame的表结构由:
StructType描述:
struct_type = StructType().\add("id",IntegerType(),False).\add("name",StringType(),True).\add("age",IntegerType(),False)
一个StructField记录:列名、列类型、列是否运行为空
多个StructField组成一个StructedType对象
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空
一行数据描述为Row对象,如Row(1,张三,11)
一列数据描述为Column对象,Column对象包含一列数据和列的信息
DataFrame的代码构建-基于RDD-1
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContextrdd = sc.testFile("../data/input/sql/people.txt).map(lambda x:x.spalit(",")).map(lambda x:(x[0],int(x[1])))#2.构建DataFrame对象## 参数一:被转换的rdd## 参数二:指定列名,通过list的形式指定,按照顺序依次提供字符串名称即可df = spark.createDataFrame(rdd,schema=['name','age'])df.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf.show(20,False)DataFrame的代码构建-基于RDD-2
#coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StringType,IntegerTypeif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContextrdd = sc.testFile("../data/input/sql/people.txt).map(lambda x:x.spalit(",")).map(lambda x:(x[0],int(x[1])))schema=StructType().add('name',StringType(),True).add('age'IntegerType(),False)df = spark.createDataFrame(rdd,schema)df.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf.show(20,False)
DataFrame的代码构建-基于RDD-3
该方法用于对数据类型不敏感
#coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StringType,IntegerTypeif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContextrdd = sc.testFile("../data/input/sql/people.txt).map(lambda x:x.spalit(",")).map(lambda x:(x[0],int(x[1])))# toDF的方式构建DataFramedf1 = rdd.toDF(['name','age'])# 方法二schema=StructType().add('name',StringType(),True).add('age'IntegerType(),False)rdd.toDF(schema)df1.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf1.show(20,False)DataFrame的代码构建-基于Pandas的DataFrame
#coding:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StringType,IntegerTypeif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# 基于Pandas的DataFrame构建SparkSQL的DataFrame对象pdf = pd.DataFrame({'id':[1,2,3],'name':['张大仙','王小小','王大锤'],'age':[11,11,11]})# 将Pandas的DF对象转换成SparkDFdf1 = spark.createDataFrame(pdf)df1.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf1.show(20,False)DataFrame的代码构建-读取外部数据-text
构建StructType,text数据源,读取数据的特点是,是将一整行只作为一个列读取,默认列名是value 类型是String
spark session.read.format(“text|csv|json|parquet|orc|avro|jdbc…”)
.option(“k”,“v”)#option可选
.schema(StructType|String)#STRING的语法如。Schema(“name STRING”,“age INT” )
.load(“被读取文件的路径,支持本地文件系统和HDFS”)
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# 构建StructType,text数据源,读取数据的特点是,是将一整行只作为一个列读取,默认列名是value 类型是Stringschema = StructType().add('data',StirngType(),True)df = spark.read.format('text').schema(schema=schema).load('../data/input/sql/people.txt')df.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf.show(20,False)DataFrame的代码构建-读取外部数据-json
json类型自带有Schema信息
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# json类型自带有Schema信息schema = StructType().add('data',StirngType(),True)df = spark.read.format('json').load('../data/input/sql/people.txt')df.printSchema()## 参数一:表示 展示出来多少条数据,默认不传的话是20## 参数二:表示是否对列进行截断,如果列的数据长度超过20个字符串长度,后续的内容不显示以。。。代替## 如果给False,表示不截断全部显示,默认是Truedf.show(20,False)
DataFrame的代码构建-读取外部数据-csv
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# json类型自带有Schema信息schema = StructType().add('data',StirngType(),True)df = spark.read.format('csv').\option('sep',';').\option('header',True).\option('encoding','utf-8').\schema('name STRING age INT,job STRING').\load('../data/input/sql/people.txt')df.printSchema()df.show(20,False)
DataFrame的代码构建-读取外部数据-parquet
parquet:是spark中常用的一种列式存储文件格式,和Hive中ORC差不多,他俩都是列存储格式
parquet对比普通文本文件的区别
- parquet内置schema(列名、列类型、是否为空)
- 存储是以列作为存储格式
- 存储时序列化存储在文件中的,有压缩属性体积小
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# parquet类型自带有Schema信息schema = StructType().add('data',StirngType(),True)df = spark.read.format('parquet').load('../data/input/sql/people.txt')df.printSchema()df.show(20,False)
DataFrame的入门操作
DataFrame支持两种风格进行编程,分别是:
- DSL风格:DataFrame的特有API,调用API的方式来处理Data
#coding:utf8from pyspark.sql import SparkSessionif __name__ == '__main__':# 0.构建执行环境入口对象SparkSessionspark = SparkSesion.builder.\appName("test").\master("local[*]").\getOrcreate()#1.基于RDD转换成DataFramesc = spark.sparkContext# parquet类型自带有Schema信息df = spark.read.format('csv').load('../data/input/sql/people.txt')# column对象的获取id_column = df['id']subject_column = df['subject']# DSL风格演示df.select(["id","subject"]).show()df.select ("id","subject").show()df.select(id_column,subject_column) # filter APIdf.filter("score < 99").show()df.filter(df['score'] < 99).show()# where APIdf.where("score < 99").show()df.where(df['score'] < 99).show()# group by APIdf.groupBy("subject").count().show()df.groupBy(df['subject']).count().show()- SQL风格:spark.sql(“select * from XXX”)
使用sparj.sql()来执行SQL语句查询,结果返回一个DataFrame
df.createTempView("score") #注册一个临时视图
df.createOrReplaceTempView("socre") #注册一个临时表,如果存在,进行替换
df.createGlobalTempView("score") # 注册一个全局表
全局表:跨sparksession对象使用,在一个程序内的多个sparkSession中均可调用,查询前带上前缀
global_temp.
SparkSQL数据清洗API
- 去重方法:dropDuplicates
- 缺失值处理:
- dropna 是可以对缺失值进行删除;只要列中有null 就删除这一行数据
参数:thread=3表示,至少满足3个有效列,不满足就删除当前数据 - fillna(“loss”) 对缺失值的列进行填充
- fillna(“N/A”,subset=[‘job’])指定列进行填充
- fillna({‘name’:‘未知姓名’,‘age’:1,‘job’:‘worker’})设定一个字典,对所有的列提供填充规则
- dropna 是可以对缺失值进行删除;只要列中有null 就删除这一行数据
DataFrame数据写出
SparkSQL 统一API写出DataFrame数据
df.write.mode().format().option(K,V).save(PATH)
- mode,传入模式字符串可选:append追加,overwrite覆盖,ignore忽略,error重复就报异常(默认的)
- format,传入格式字符串,可选:text,csv,json,parquet,orc,avro,jdbc
- save 写出的路径,支持本地文件和HDFS
04.SparkSQL函数定义
SparkSQL定义UDF
pyspark UDF
SparkSQL使用窗口函数
-
聚合开窗函数
-
排序开窗函数
– ROW_NUMBER() OVER()
–DENSE_RANK() OVER()
–RANK() OVER() -
NTILE分组窗口
05.SparkSQL的运行流程
SparkSQL的自动优化
RDD的运行完全是按照开发者的代码执行,如果开发者水平有限,RDD的执行效率也会收到影响
而SparkSQL会对写完的代码,执行“自动优化”,以提升代码运行效率,避免开发者水平影响到代码执行效率;依赖于:Catalyst优化器
Catalyst优化器

STEP1:解析SQL,并生成AST(抽象语法树)
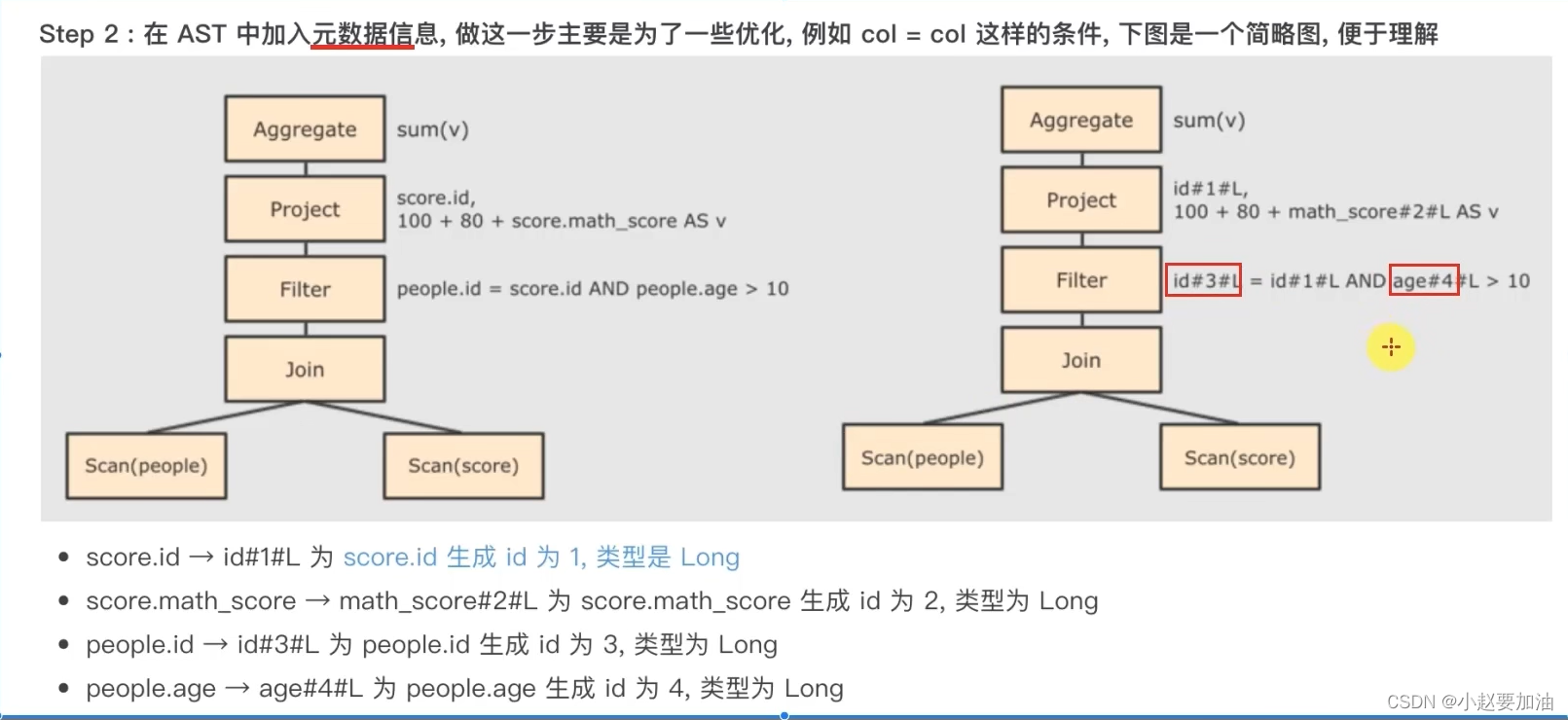
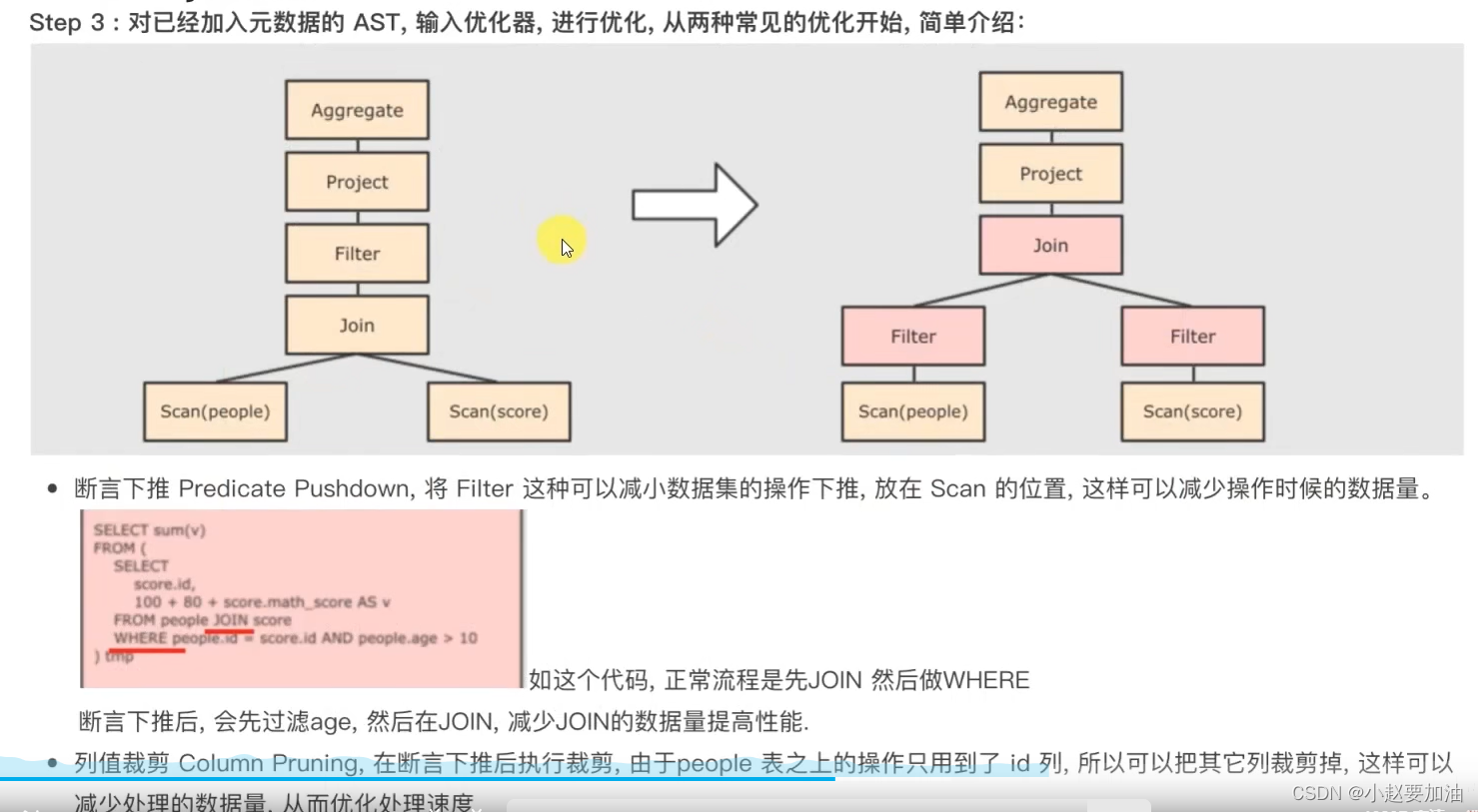

大方面的优化点有2个:
- 谓词下推、断言下推:将逻辑判断提前到前面,以减少shuffle阶段的数据量
- 列值剪裁:将加载的列进行剪裁,尽量减少被处理数据的宽度
SparkSQL的执行流程

06.SparkSQL整合Hive
Hive执行流程
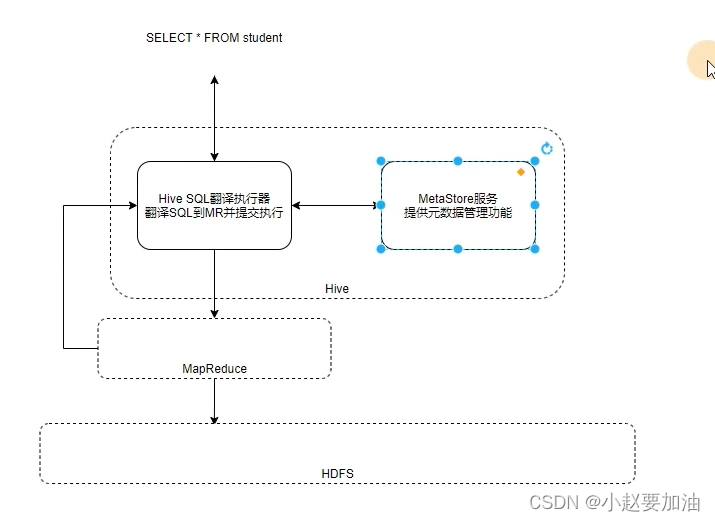
SparkOn Hive
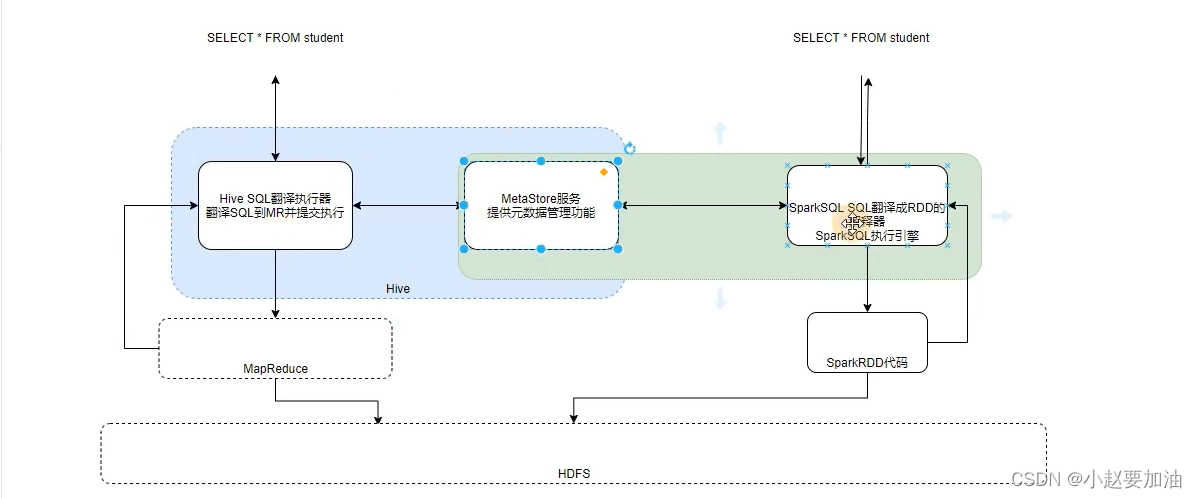
Spark On Hive就是因为Spark自身没有元数据管理功能,所以使用Hive的Metastore服务做为元数据管理服务。计算有Spark执行
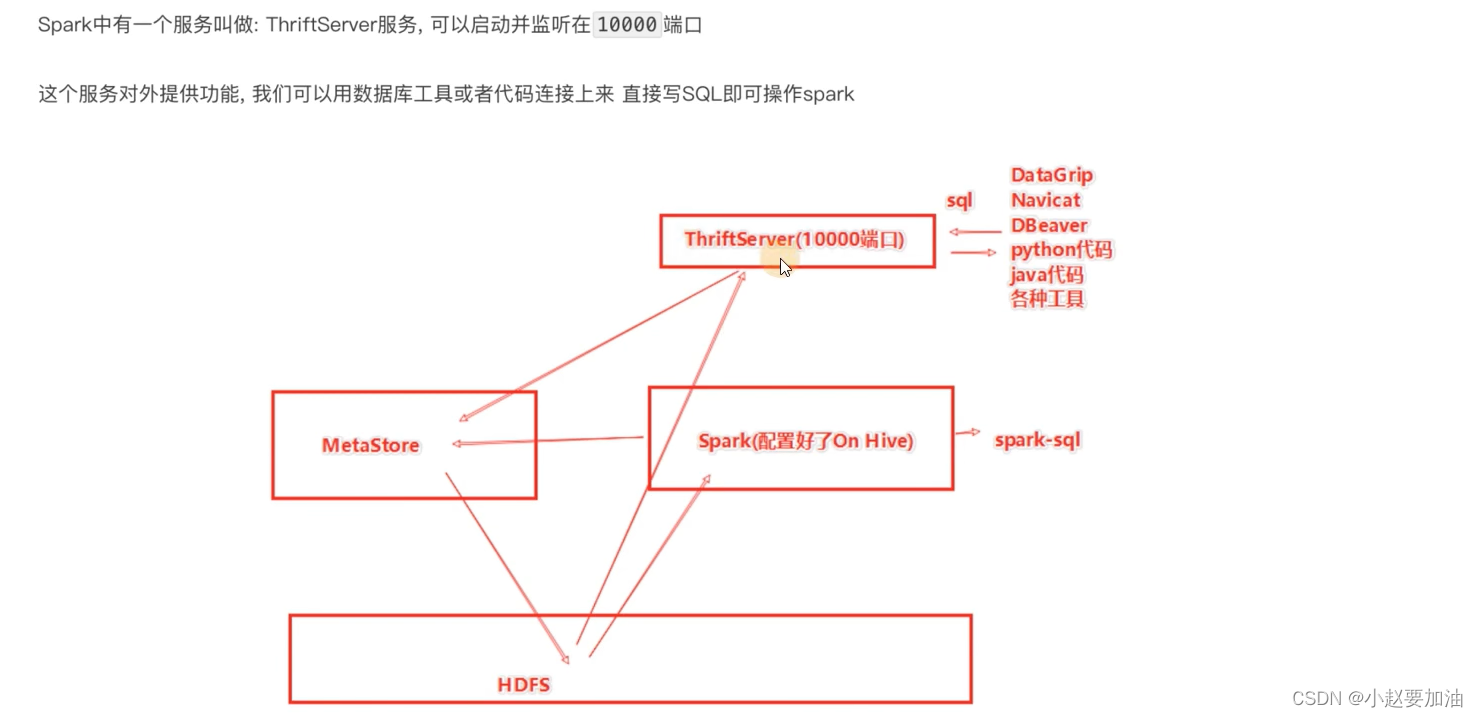
07.分布式SQL引擎配置



![[C++] external “C“的作用和使用场景(案例)](https://img-blog.csdnimg.cn/direct/782e2ee080d9426b94f36df8feebadcd.png)