一 sql gateway
注意 之所以直接启动gateway 能知道yarn session 主要还是隐藏的配置文件,但是配置文件可以被覆盖,多个session 保留最新的applicationid
1 安装flink (略)
2 启动sql-gatway(sql-gateway 通过官网介绍只能运行在session 任务中)
2-1 启动gateway 之前先启动一个flink session ./bin/yarn-session.sh -d
2-2 启动命令 :
./bin/sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost
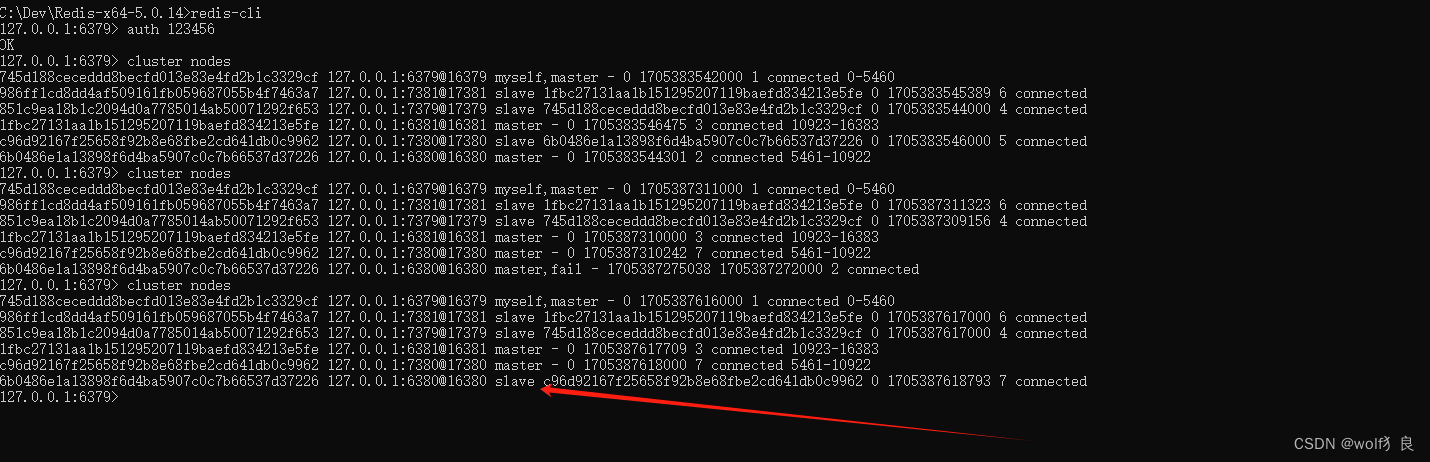
2-3 查看日志观察是否启动成功:
查看日志出现这个条信息就证明已经找到了flink session applicationId

可以观察到 yarn-properties-yarn 文件中存在一个session applicationId 这个applicationId是覆盖关系当启动多个session 的时候 这里只保存最新创建的那个
[图片]
Sql-gateway 默认端口是8083 启动成功后可以通过http 方式进行访问
[图片]
3 Flink 原生支持 REST Endpoint 和 HiveServer2 Endpoint。
SQL Gateway 默认集成 REST Endpoint。由于架构的可扩展性,用户可以通过指定 endpoint 来启动 SQL Gateway。我们测试是rest 加gateway jdbc方式。
4 Rest api 提交任务
4-1 获得一个 session 这里的session 的意思是当前连接草的人获取的一个唯一编码,当拿到这个sessionid后后续所有的所有操作都跟他关联。
[图片]
4-2 提交一个任务:黄色框 是上一步获取的sessionid 蓝色框是需要提供的sql 任务,绿色框是提交任务后获取结果的一个唯一编码
[图片]
4-3 获取结果:
[图片]
二 gateway jdbc
1 环境准备 flink-jdbc-driver-bundle-1.18.jar放到 {HIVE_HOME}/lib 目录中
2 beeline 连接 (地址为上一步启动的sql getewat 地址)
2-1 beeline
2-2 beeline> !connect jdbc:flink://xxx.xxx.xxx.xxx:8083
当出现这种日志连接成功
[图片]
3 创建一个 hdfs 表 并且插入数据
CREATE TABLE D(a INT, b VARCHAR(10)) WITH ('connector' = 'filesystem','path' = 'hdfs:///tmp/T.csv','format' = 'csv'
);
4 gatway jdbc 查看hive 数据
1 环境准备 将{HIVE_HOME}/ hive-exec-3.1.0.3.1.4.0-315.jar /hive-exec.jar /libfb303-0.9.3.jar 三个jar 移动到{flink_home}/lib 中
2 上传hive conf目录 配置文件到hdfs 中
[图片]
3 创建hive catalogs
CREATE CATALOG hive_catalog WITH ('type' = 'hive','default-database' = 'default','hive-conf-dir' = 'hdfs:///tmp/hiveconfig'
);
4 切换 catalogs
use catalog hive_catalog;
5 查看并查询hive 数据

[图片]