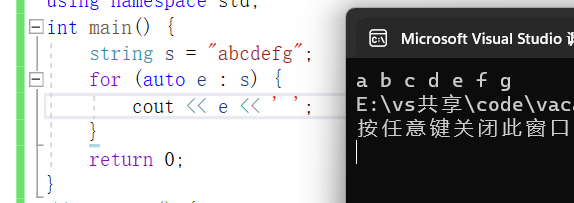
贝叶斯定理对于机器学习来说是经典的概率模型之一,它基于先验信息和数据观测来得到目标变量的后验分布。具体来说,条件概率(也称为后验概率)描述的是事件A在另一个事件B已经发生的条件下的发生概率,公式表示为P(A|B),读作“在B条件下A的概率”。
最常用的贝叶斯机器学习模型
-
朴素贝叶斯模型:这是一个基于贝叶斯定理的分类算法,其核心思想是:对于给定的输入特征,假设每个特征之间都是独立的。尽管这个假设在实际应用中可能不成立,但朴素贝叶斯模型在许多场景下都表现出了很好的性能。
-
贝叶斯网络模型:这是一个用于表示变量之间复杂关系的概率图模型。贝叶斯网络可以用于推断、学习和推理,广泛应用于各种机器学习任务中。
基本原理
公式:
其中:
:表示在B发生的情况下,A发生的概率,即得自B的取值而被称作A的后验概率
:表示在A发生的情况下,B发生的概率,即得自A的取值而被称作B的后验概率
:表示A发生的概率,也称A的先验概率
:表示B发生的概率,也称B的先验概率
例1
现分别有 A、B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,那么从这两个容器里任意抽出了一个红球,问这个球来自容器 A 的概率是多少?
首先我们先定义事件:
- A:为选中A容器
- B:为抽出红球
已知:
求:从这两个容器里任意抽出了一个红球,问这个球来自容器 A 的概率是多少?
套入公式:
解得: 从这两个容器里任意抽出了一个红球,这个球来自容器 A 的概率87.5%
例2
假设新冠状病毒测试,用于检测是否感染了新冠状病毒。这个测试不是100%准确,会有假阳性和假阴性的情况。那么,测试结果为阳性的概率(阳性率)是98%,测试结果为阴性的概率(阴性率)是95%,实际感染新冠状病毒的人的概率(患病率)是1%,现在,有一个人的测试结果为阳性,根据以上信息判断这个人是否真的感染了新冠状病毒。
| 阳性率 | 阴性率 | 患病率 |
| 98% | 95% | 1% |
首先我们先定义事件:
:测试结果为阳性
:实际感染了病毒
:未感染病毒
根据以上信息已知:
:在未感染病毒患病的情况下,测试结果为阳性的概率,即假阳性率。这个值是2%(100%-98%)
:实际未感染新冠状病毒的概率,即99%
使用全概率公式计算:
其中,表示事件A发生的概率,
表示对所有可能的状态
求和,
表示状态
的概率,
表示在状态
下事件
发生的概率。
代入贝叶斯公式计算:
即测试结果为阳性,是否真的感染了新冠状病毒的概率
解得: 测试结果为阳性,确认感染了新冠状病毒的概率约为33%。
朴素贝叶斯
朴素贝叶斯是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。朴素贝叶斯在文本分类、垃圾邮件过滤、情感分析等领域有广泛应用。朴素贝叶斯的基本原理是:对于给定的训练数据集,计算每个类别的概率,然后根据输入的特征计算属于每个类别的概率,最后选择概率最大的类别作为预测结果。
示例
使用sklearn库的朴素贝叶斯分类器
from sklearn.datasets import fetch_openml # 导入fetch_openml函数,用于加载Fashion MNIST数据集
from sklearn.model_selection import train_test_split # 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.naive_bayes import GaussianNB # 导入GaussianNB类,用于创建朴素贝叶斯分类器
from sklearn.metrics import accuracy_score # 导入accuracy_score函数,用于计算预测准确率# 加载Fashion MNIST数据集
fashion_mnist = fetch_openml('fashion_mnist', version=1)
X = fashion_mnist.data # 获取数据集的特征
y = fashion_mnist.target # 获取数据集的标签# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建朴素贝叶斯分类器
gnb = GaussianNB()# 训练模型
gnb.fit(X_train, y_train)# 预测测试集结果
y_pred = gnb.predict(X_test)# 输出预测准确率
print("朴素贝叶斯分类器预测准确率:", accuracy_score(y_test, y_pred))