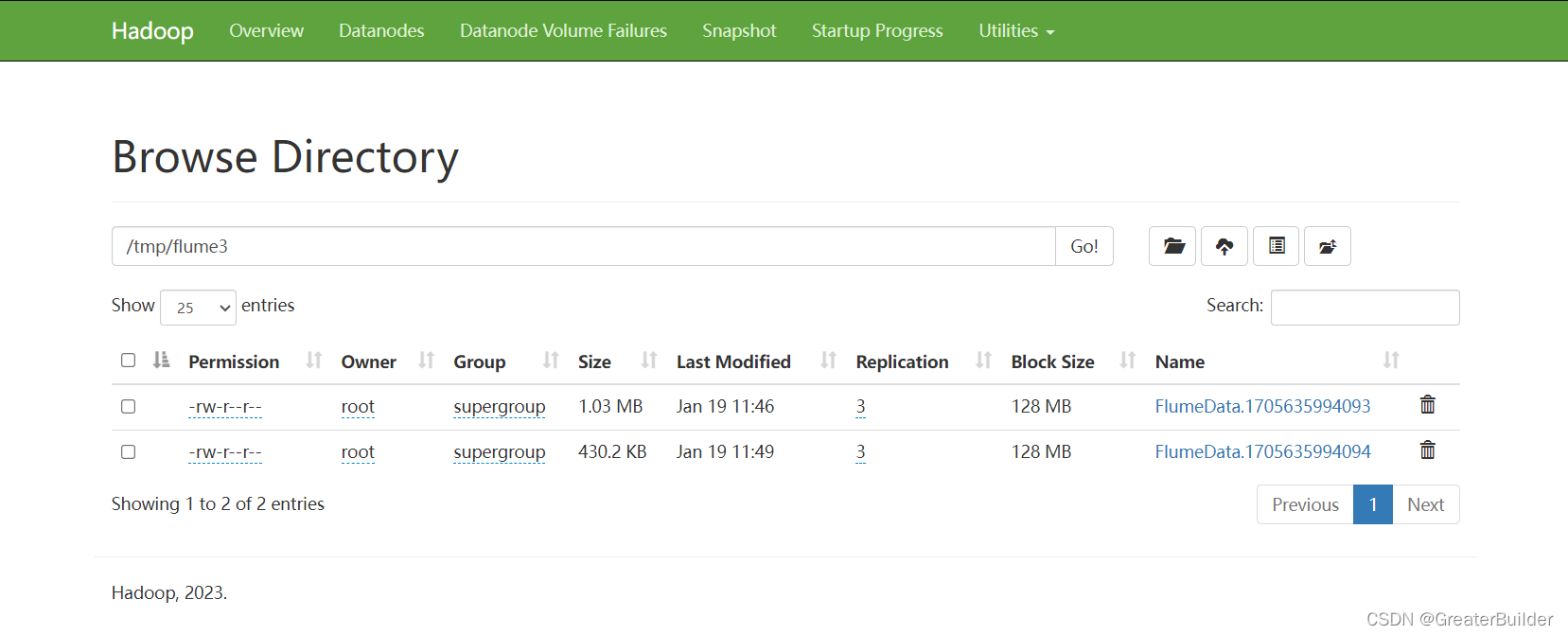
无标签人群技术,作者引入了一种排名。
利用的是一个图的人群数量一定小于等于包含这个图的图
生成排名数据集
作者提出了一种自监督任务,利用的是一个图的人群数量一定小于等于包含这个图的图

流程:
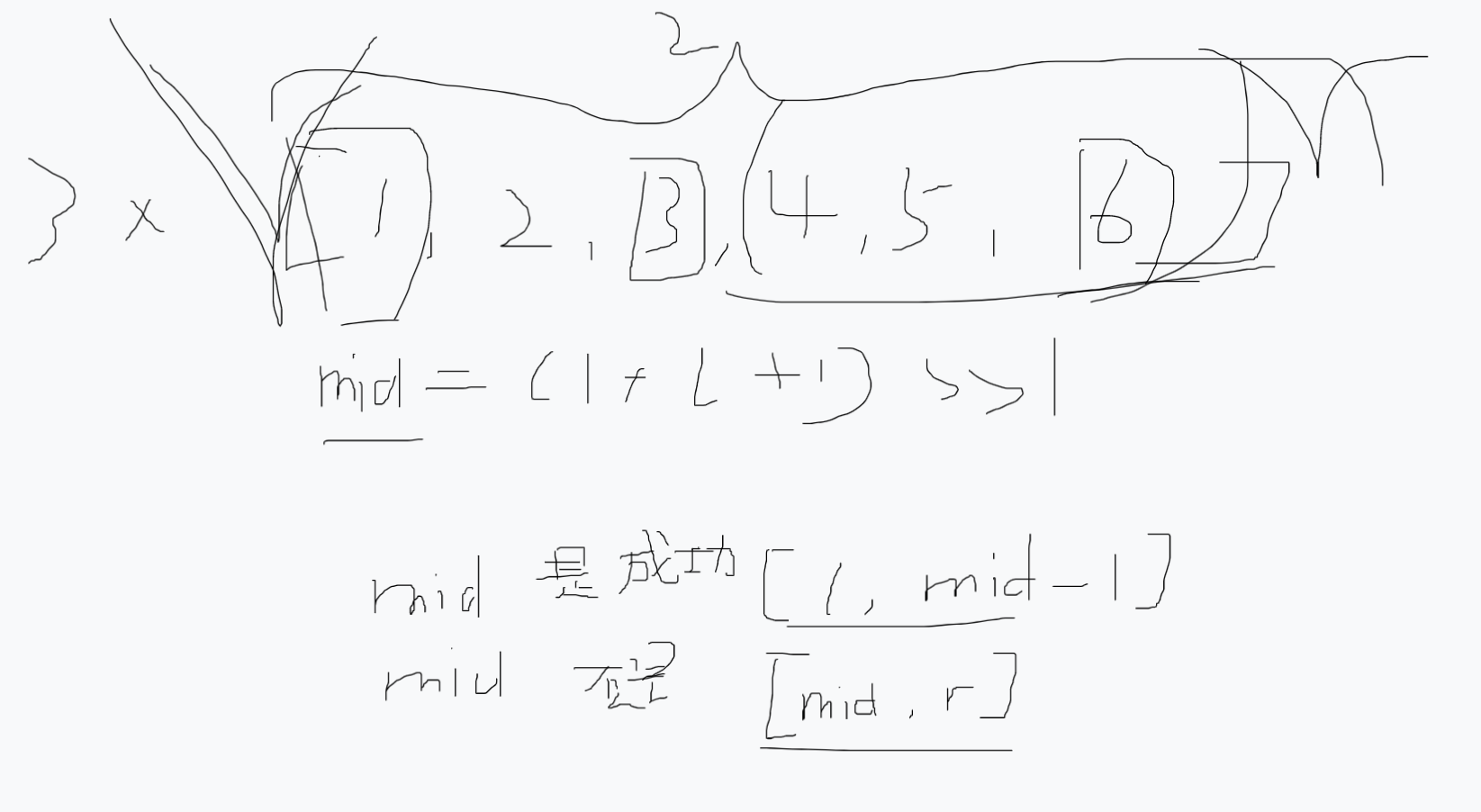
1.以图像中心为中心,划分一个 1 / r 1/r 1/r图像大小的矩形(但是这里没写是面积的还是长宽的)
在这个矩形中,随机选择一个点当作锚点
2.以锚点为中心,找到一个不超过图像边界的正方形
3.重复 k − 1 k-1 k−1次,每次生成一个正方形,大小是上一个正方形的 1 / s 1/s 1/s(也没说是面积还是长宽)
目测代码是这样写的
def generate_ranking(img, k, s, r):h, w, _ = img.shapecenter_h = h // 2center_w = w // 2region_h = int(h // (r**0.5))region_w = int(w // (r**0.5))left_h = center_h - region_h // 2left_w = center_w - region_w // 2right_h = left_h + region_hright_w = left_w + region_wanchor_h = np.random.randint(left_h, right_h)anchor_w = np.random.randint(left_w, right_w)radius = min(anchor_h, h - anchor_h, anchor_w, w - anchor_w)res = []for _ in range(k):res.append(img[anchor_h - int(radius):anchor_h + int(radius),anchor_w - int(radius):anchor_w + int(radius)])radius *= float(s)return res
为了收集一个大的数据集,作者用了两种方法
Keyword query:google里搜索Crowded, Demonstration, Train station, Mall, Studio,
Beach
Query-by-example image retrieval:利用UCF CC 50,ShanghaiTech Part A, ShanghaiTech Part B,在google图搜图,每一张图选10张

Learning from ranked image sets
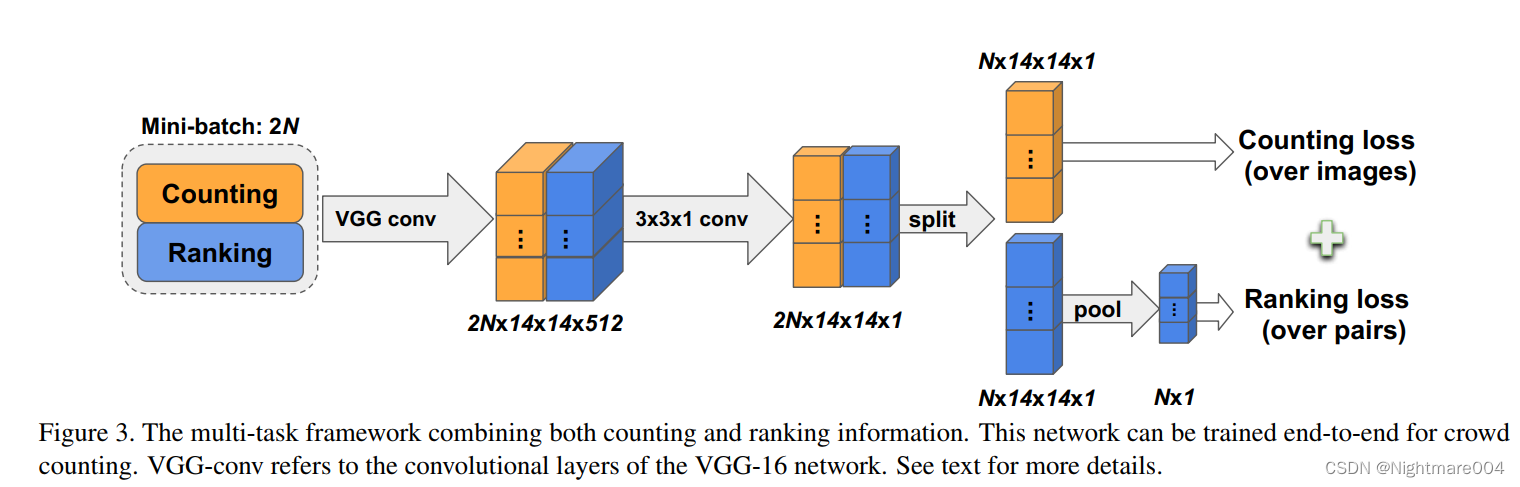
Crowd density estimation network
用的vgg16,去掉全连接,最后一个max pooling换成 3 ∗ 3 3*3 3∗3的卷积,把通道从512变为1,生成density map
模型就是图中的橙色部分
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import torch
from torch import nn
from torchvision.models import vgg16, VGG16_Weightsclass VGG(nn.Module):def __init__(self):super(VGG, self).__init__()vgg_16 = vgg16(weights=VGG16_Weights.DEFAULT)self.features = vgg16(weights=VGG16_Weights.DEFAULT).featurestemp = nn.Conv2d(512, 1, 3, 1, 1)nn.init.normal_(temp.weight, std=0.01)if temp.bias is not None:nn.init.constant_(temp.bias, 0)self.features[-1] = tempdef forward(self, x):return self.features(x)if __name__ == '__main__':model = VGG()B = 2a = torch.rand((B, 3, 224, 224))b = model(a)c = b.view(B, 1, -1)M = c.size(2)d = torch.mean(c, dim=-1)print(M)print(b.shape) # torch.Size([2, 1, 14, 14])print(c.shape) # torch.Size([2, 1, 196])print(d.shape) # torch.Size([2, 1])
标签的density map就是每一个点分别做一个标准差为1,大小为15的高斯核,损失用的MSE
为了进一步提升效果,我们随机采样一个正方形(56-448像素)
Crowd ranking network
这里针对的是没有标注的部分
简单来说就是对density map做average pooling,得到 c ^ i \hat{c}_i c^i, 人群数量就是 C ^ ( I i ) = M × c ^ ( I i ) \hat{C}\left(I_i\right) = M \times \hat{c}\left(I_i\right) C^(Ii)=M×c^(Ii)
损失是一个排名hinge loss
L r = max ( 0 , c ^ ( I 2 ) − c ^ ( I 1 ) + ε ) L_r = \max \left(0, \hat{c}\left(I_2\right) - \hat{c}\left(I_1\right) + \varepsilon\right) Lr=max(0,c^(I2)−c^(I1)+ε)
这里的 ε = 0 \varepsilon=0 ε=0
这个loss就是要大的图片比小的图片排名靠前(人数更多)
损失只针对比他小
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import torch
from torch import nn
import torch.nn.functional as Fclass RankingLoss(nn.Module):def __init__(self, k, eps=0, reduction='sum'):super(RankingLoss, self).__init__()self.k = kself.eps = epsself.reduction = reductiondef forward(self, x):B = x.size(0)assert B % self.k == 0loss = 0.cnt = 0for start in range(0, B, self.k):end = start + self.kfor i in range(start, end):for j in range(i + 1, end):loss += F.relu(x[j] - x[i] + self.eps)cnt += 1if self.reduction == 'mean':return loss / cntreturn loss