FlinkSQL处理如下实时数据需求:
实时聚合不同 类型/账号/发布时间 的各个指标数据,比如:初始化/初始化后删除/初始化后取消/推送/成功/失败 的指标数据。要求实时产出指标数据,数据源是mysql cdc binlog数据。
代码实例
--SET table.exec.state.ttl=86400s; --24 hour,默认: 0 ms
SET table.exec.state.ttl=2592000s; --30 days,默认: 0 ms
--MiniBatch 聚合
SET table.exec.mini-batch.enabled = true;
SET table.exec.mini-batch.allow-latency = 1s;
SET table.exec.mini-batch.size = 10000;
--Local-Global 聚合
SET table.optimizer.agg-phase-strategy = TWO_PHASE;CREATE TABLE kafka_table (mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map<string,string>,cur map<string,string>,cus map<string,string>,account_id AS IF(cur['account_id'] IS NOT NULL , cur['account_id'], src ['account_id']),publish_time AS IF(cur['publish_time'] IS NOT NULL , cur['publish_time'], src ['publish_time']),msg_status AS IF(cur['msg_status'] IS NOT NULL , cur['msg_status'], src ['msg_status']),send_type AS IF(cur['send_type'] IS NOT NULL , cur['send_type'], src ['send_type'])--event_time as cast(IF(cur['update_time'] IS NOT NULL , cur['update_time'], src ['update_time']) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)--WATERMARK FOR event_time AS event_time - INTERVAL '1' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't1','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','properties.group.id' = 'g1','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset-- 'properties.enable.auto.commit',= 'true' -- default:false, 如果为false,则在发生checkpoint时触发offset提交'format' = 'json'
);CREATE TABLE es_sink(send_type STRING,account_id STRING,publish_time STRING,grouping_id INTEGER,init INTEGER,init_cancel INTEGER,push INTEGER,succ INTEGER,fail INTEGER,init_delete INTEGER,update_time STRING,PRIMARY KEY (group_id,send_type,account_id,publish_time) NOT ENFORCED
)
with ('connector' = 'elasticsearch-6','index' = 'es_sink','document-type' = 'es_sink','hosts' = 'http://xxx:9200','format' = 'json','filter.null-value'='true','sink.bulk-flush.max-actions' = '1000','sink.bulk-flush.max-size' = '10mb'
);CREATE view tmp as
selectsend_type,account_id,publish_time,msg_status,case when UPPER(opt) = 'INSERT' and msg_status='0' then 1 else 0 end AS init,case when UPPER(opt) = 'UPDATE' and send_type='1' and msg_status='4' then 1 else 0 end AS init_cancel,case when UPPER(opt) = 'UPDATE' and msg_status='3' then 1 else 0 end AS push,case when UPPER(opt) = 'UPDATE' and (msg_status='1' or msg_status='5') then 1 else 0 end AS succ,case when UPPER(opt) = 'UPDATE' and (msg_status='2' or msg_status='6') then 1 else 0 end AS fail,case when UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0' then 1 else 0 end AS init_delete,event_time,opt,ts
FROM kafka_table
where (UPPER(opt) = 'INSERT' and msg_status='0' )
or (UPPER(opt) = 'UPDATE' and msg_status in ('1','2','3','4','5','6'))
or (UPPER(opt) = 'DELETE' and send_type='1' and msg_status='0');--send_type=1 send_type=0
--初始化->0 初始化->0
--取消->4
--推送->3 推送->3
--成功->1 成功->5
--失败->2 失败->6CREATE view tmp_groupby as
selectCOALESCE(send_type,'N') AS send_type
,COALESCE(account_id,'N') AS account_id
,COALESCE(publish_time,'N') AS publish_time
,case when send_type is null and account_id is null and publish_time is null then 1when send_type is not null and account_id is null and publish_time is null then 2when send_type is not null and account_id is not null and publish_time is null then 3when send_type is not null and account_id is not null and publish_time is not null then 4end grouping_id
,sum(init) as init
,sum(init_cancel) as init_cancel
,sum(push) as push
,sum(succ) as succ
,sum(fail) as fail
,sum(init_delete) as init_delete
from tmp
--GROUP BY GROUPING SETS ((send_type,account_id,publish_time), (send_type,account_id),(send_type), ())
GROUP BY ROLLUP (send_type,account_id,publish_time); --等同于以上INSERT INTO es_sink
selectsend_type,account_id,publish_time,grouping_id,init,init_cancel,push,succ,fail,init_delete,CAST(LOCALTIMESTAMP AS STRING) as update_time
from tmp_groupby其他配置
- flink集群参数
state.backend: rocksdb
state.backend.incremental: true
state.backend.rocksdb.ttl.compaction.filter.enabled: true
state.backend.rocksdb.localdir: /export/io_tmp_dirs/rocksdb
state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
rest.flamegraph.enabled: true
pipeline.operator-chaining: false
taskmanager.memory.managed.fraction: 0.7
taskmanager.memory.network.min: 128 mb
taskmanager.memory.network.max: 128 mb
taskmanager.memory.framework.off-heap.size: 32mb
taskmanager.memory.task.off-heap.size: 32mb
taskmanager.memory.jvm-metaspace.size: 256mb
taskmanager.memory.jvm-overhead.fraction: 0.03
-
检查点配置
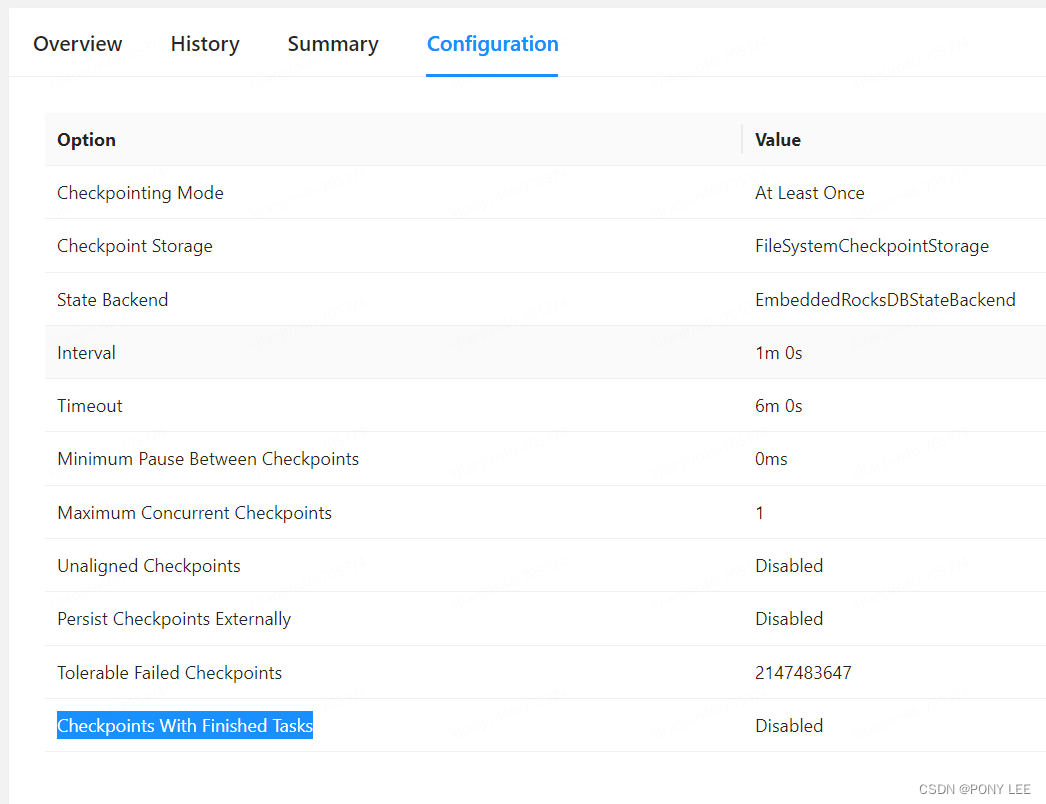
-
job运行资源
管理节点(JM) 1 个, 节点规格 1 核 4 GB内存, 磁盘 10Gi
运行节点(TM)10 个, 节点规格 1 核 4 GB内存, 磁盘 80Gi
单TM槽位数(Slot): 1
默认并行度:8 -
es mapping
#POST app_cust_syyy_private_domain_syyy_group_msg/app_cust_syyy_private_domain_syyy_group_msg/_mapping
{"app_cust_syyy_private_domain_syyy_group_msg": {"properties": {"send_type": {"type": "keyword","ignore_above": 256},"account_id": {"type": "keyword"},"publish_time": {"type": "keyword","fields": {"text": {"type": "keyword"},"date": {"type": "date","format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis","ignore_malformed":"true" # 忽略错误的各式}}},"grouping_id": {"type": "integer"},"init": {"type": "integer"},"init_cancel": {"type": "integer"},"query": {"type": "integer"},"succ": {"type": "integer"},"fail": {"type": "integer"},"init_delete": {"type": "integer"},"update_time": {"type": "date","format": "yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"}}}
}性能调优
是否开启【MiniBatch 聚合】和【Local-Global 聚合】对分组聚合场景影响巨大,尤其是在数据量大的场景下。
-
如果未开启,在分组聚合,数据更新状态时,每条数据都会触发聚合运算,进而更新StateBackend (尤其是对于 RocksDB StateBackend,火焰图上反映就是一直在update rocksdb),造成上游算子背压特别大。此外,生产中非常常见的数据倾斜会使这个问题恶化,并且容易导致 job 发生反压。
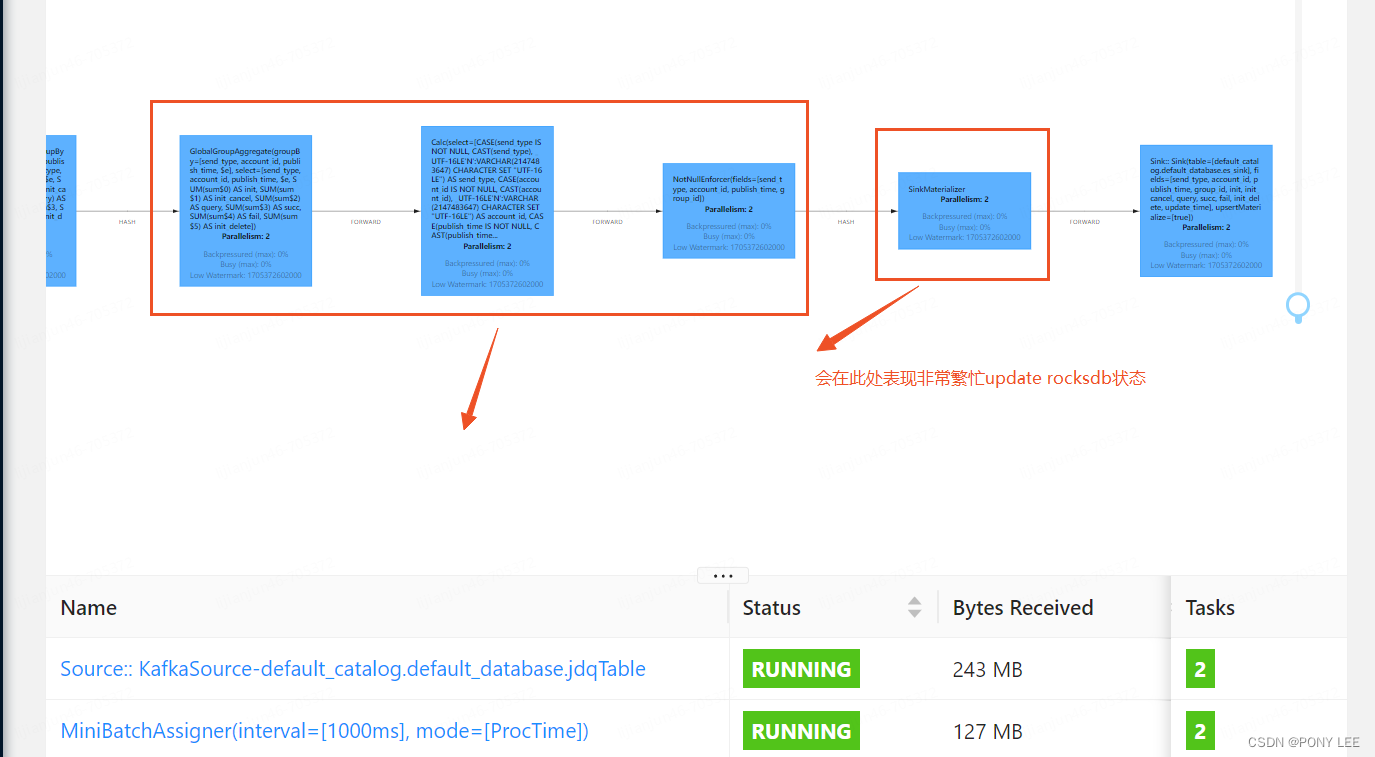
-
在开启【MiniBatch 聚合】和【Local-Global 聚合】后,配置如下:
--MiniBatch 聚合
SET table.exec.mini-batch.enabled = true;
SET table.exec.mini-batch.allow-latency = 1s;
SET table.exec.mini-batch.size = 10000;
--Local-Global 聚合
SET table.optimizer.agg-phase-strategy = TWO_PHASE;
开启配置好会在DAG上添加两个环节MiniBatchAssigner和LocalGroupAggregate
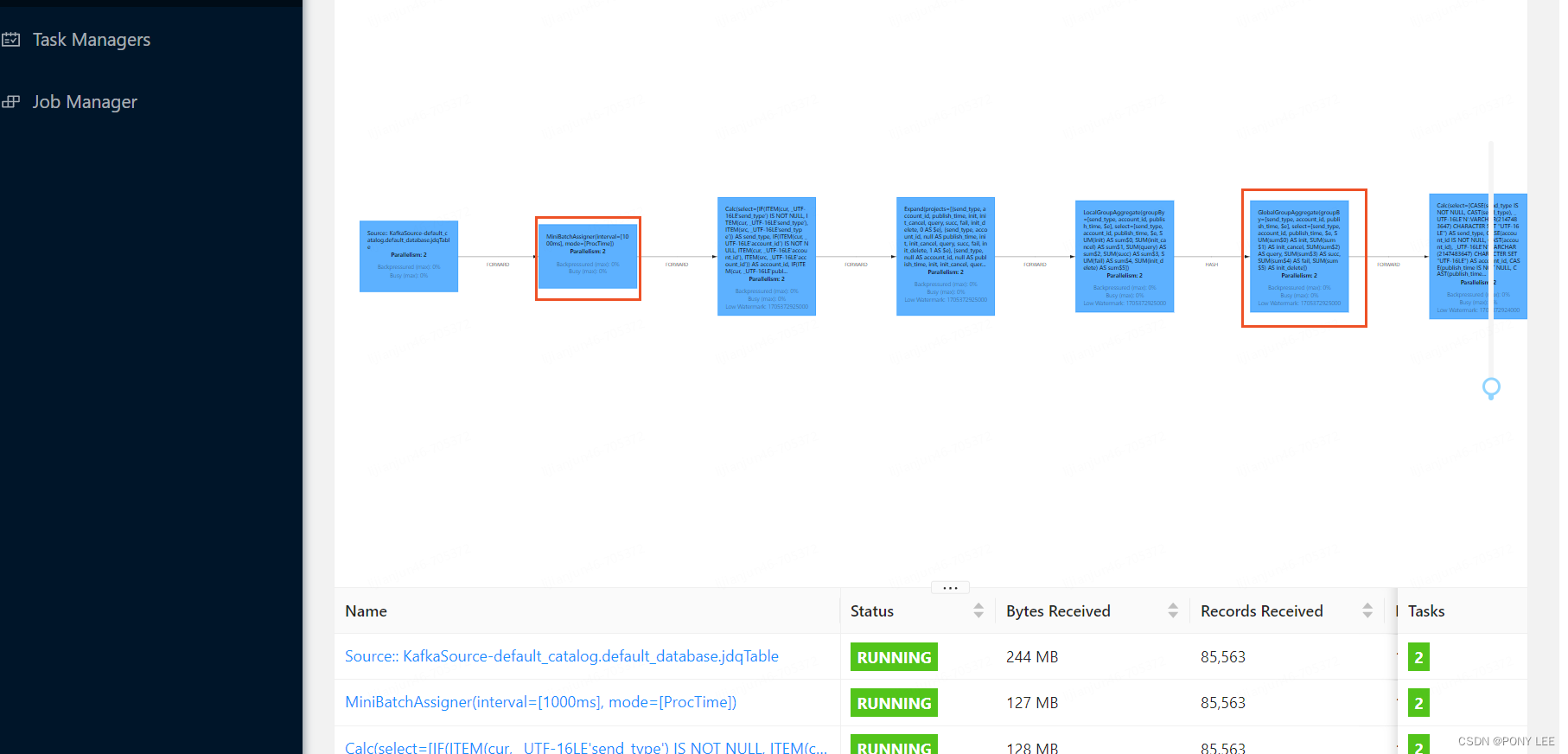
对结果的影响
开启了【MiniBatch 聚合】和【Local-Global 聚合】后,一天处理不完的数据,在10分钟内处理完毕
输出结果
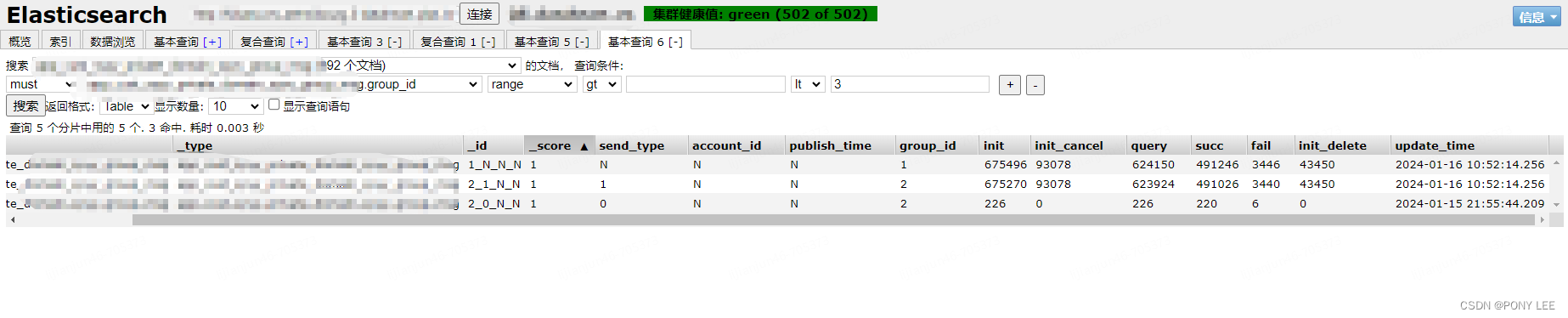
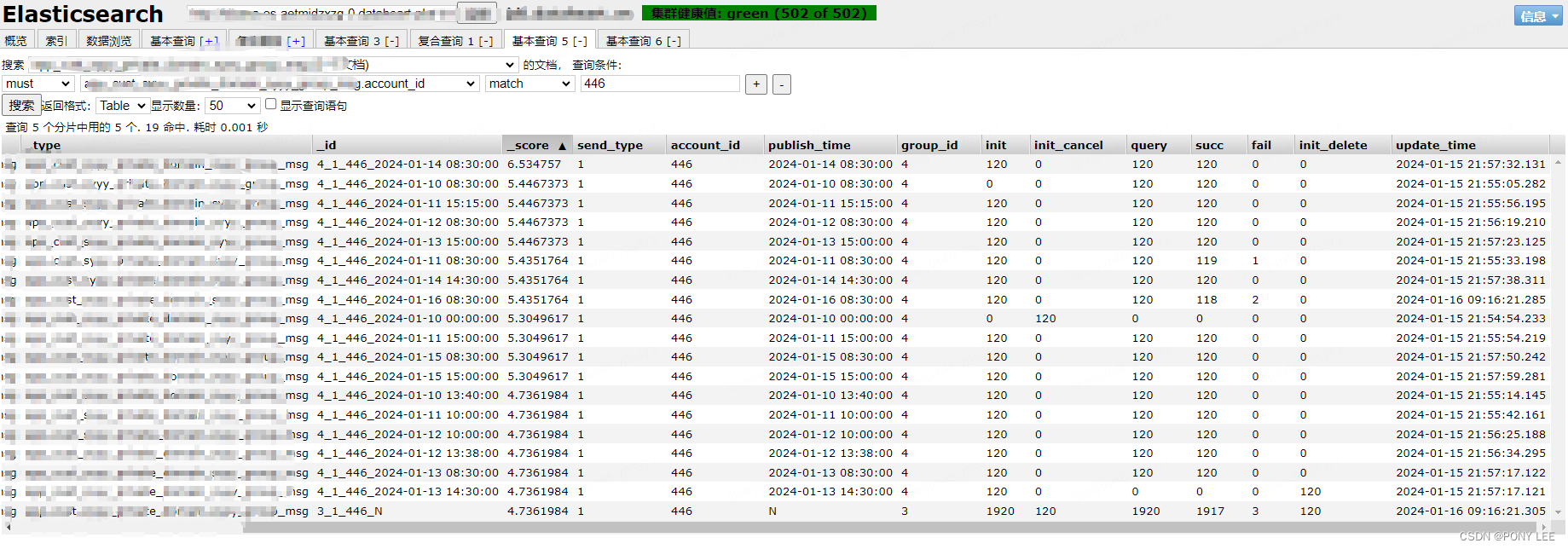
参考:
Group Aggregation
Streaming Aggregation Performance Tuning




![[AutoSar]BSW_OS 05 Autosar OS_schedule table](https://img-blog.csdnimg.cn/direct/5a830311df90423e8c7a3ff78e4eba5e.png)

