基于深度学习的车牌识别(YOLOv5和CNN)
目录
一、综述
二、车牌检测
一、综述
本篇文章是面向的是小白,想要学习深度学习上的应用,本文中目前应用了YOLO v5和CNN来对车牌进行处理,最终形成一个完整的车牌信息记录,如果我写的有什么不对或者需要改进的地方,可以私信给我。
我们假设已经获得包含有车牌的照片,那么我们
第一步:是车牌的检测获取车牌的那部分。
第二步:就是对车牌进行拆分成各个字符。
第三步:对于一张车牌的每个字符我们使用CNN得到的模型去预测每个字符
最终得到车牌信息。
二、车牌检测
概括
车牌检测的方法有许多,最初我用的是原始的图像形态学对图像的处理(基于opencv的形态学操作),发现这样的方法不能很好的应用到所有的车牌中。那么我在学习的过程中,其实已经有许多其他方法来实现。比如目标检测,它就是一个很好的方法,主要是可以把这样的方法应用到更多更广泛的应用场景。
在目标领域中主要分为如下两个——One-stage和two-stage算法
他们的区别可以查看 目标检测算法基础介绍
首先YOLO系列下的模型都是属于One-stage,在One-stage包括SSD也是很常用的一种方法。
YOLOv5学习视频查看 火爆全网的YOLOv5目标检测项目 从P41开始学习就可以了。
我们这部分有几个前提必须准备好。
1.训练需要的车牌图片数据
车牌数据 我的来自于 中科大建立的CCPD数据集,其他的不要说,总之在学习阶段说一个不错的数据,论文和数据集下载地址:github.com/detectRecog… 以下说数据说明
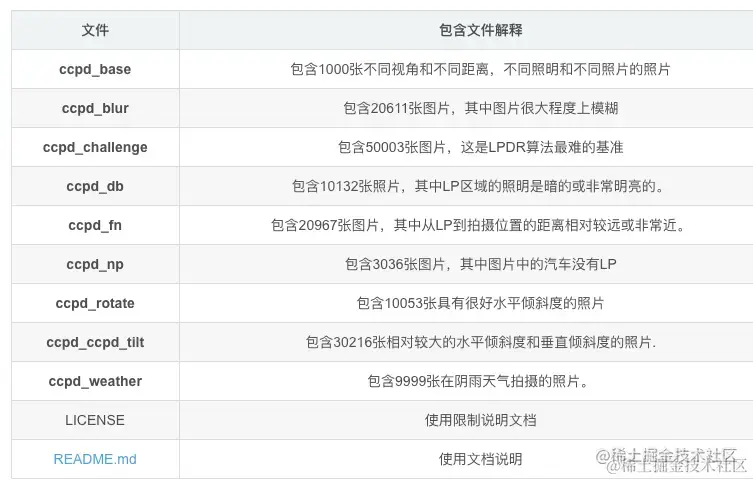
2.安装YOLOv5模型 YOLO的安装可以直接 去GitHub上下载:github.com/ultralytics… 如果是第一次使用其他人模型,第一次都会有不知所措,但一旦掌握了其中一个,其他是类似的。比如图像分割中的U-net,ocr模型中PaddlePaddleOCR都是差不多的用法。
(1) YOLO文件中需要修改某些文件
在我的目录中,我将YOLO下载到与car文件夹的同目录下
我们需要关注YOLO文件夹下的几个文件,这是我的文件目录
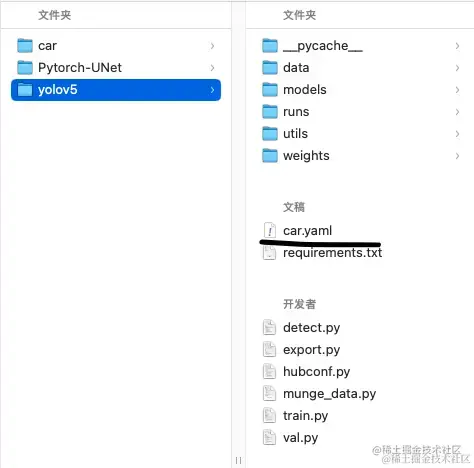
我们要自己首先一个yaml文件来配置YOLO模型,图中化横线的文件 car.yaml
以下是我的简单的配置
 path:图片数据的根目录
path:图片数据的根目录
train:训练集的绝对路径,这里存放是所有图片的绝对路径
val: 验证集的绝对路径,与train一样
nc:分类个数
names:列表类型 所有类别名字 license plate 车牌
(2)预使用模型 YOLO已经给出以下模型 我们可以在他们这些模型的基础上进行训练自己的模型

我使用的是占内存比较小,准确率不错的yolov5s.yaml 详细其他模型有什么区别可以去官网去查看:github.com/ultralytics…
yolo5s.yaml 文件我们需要简单的进行修改,从而满足我们自己项目的需求
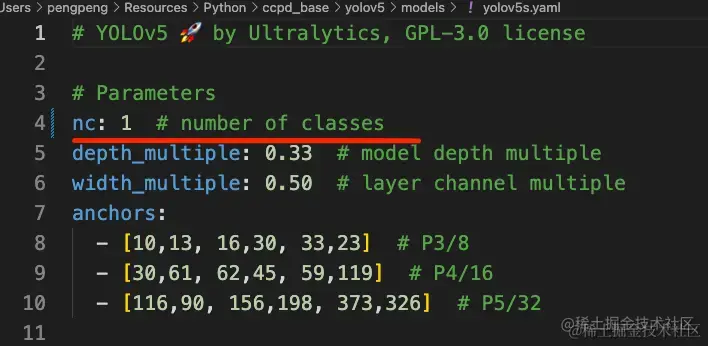
在我的项目中只有一个车牌需要关注,所以我们需要将nc的个数改为1,其他参数我们不需要修改。
好,YOLO文件夹下内容,暂时不需要修改了。
图片数据分析
数据的目录是如图

我们简单的使用 ccpd_base 文件夹,图片很多,考虑电脑实际情况,我只选取其中任意的5000张照片来作为数据源。
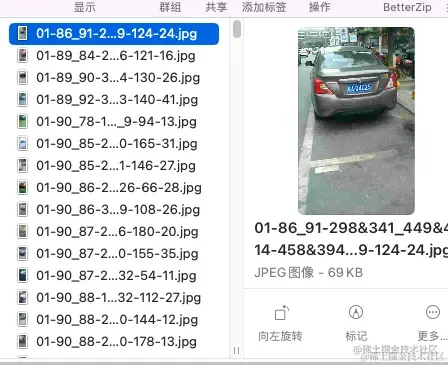
ccpd_base文件内容如下
先建立文件夹结构

markdown
复制代码
carimages放入数据集照片5000张labels等会儿说到
详细查看第一个图片名字
数据中有详细的解释文件名字的意思 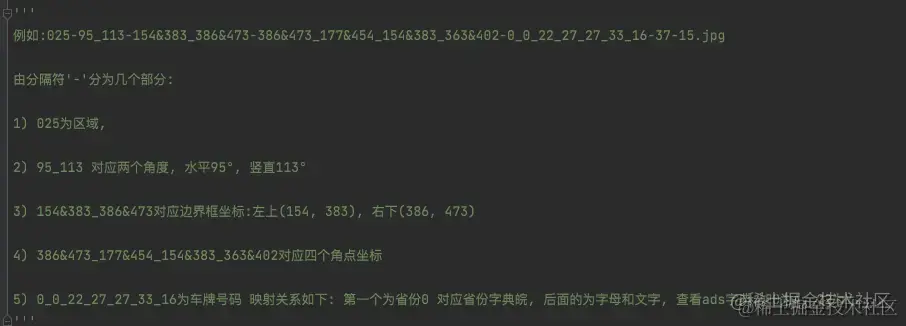
第一张图片名字是:01-86_91-298&341_449&414-458&394_308&410_304&357_454&341-0_0_14_28_24_26_29-124-24.jpg
less
复制代码1) 01为区域,2) 86_91 对应两个角度, 水平86°, 竖直91°3) 298&341_449&414对应边界框坐标:左上(298, 341), 右下(449, 414)4) 458&394_308&410_304&357_454&341对应四个角点坐标5) 0_0_14_28_24_26_29-124-24为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y....
现在对于我们这个阶段我们用到四个点的坐标。
代码如下 Car_Model:
ini
复制代码
import os
import numpy as np
# 访问图片获得图片名字的字符
def load_files(path, cuted=False): # cuted=False 可以不需要写total_info = []car_numbers = [] # 车牌号码angels = [] # 倾斜角度areas = [] # 区域positions = [] # 车牌四个角的位置areas_positions = [] # 车牌左上和右下区域位置for i, j, names in os.walk(path):# 假设现在已经获得了路径# 首先要删除前面没有用的路径,现在获得的是一个strfor name in names:if len(name) < 50:continueif cuted is True:path = name.split("-", 5)areas.append(path[0])angels.append(path[1])areas_positions.append(path[2])positions.append(path[3])car_numbers.append(path[4])else:total_info.append(name)if cuted is True: # 其他情况下可能需要得到每段信息,可以不需要total_info.append(areas)total_info.append(angels)total_info.append(areas_positions)total_info.append(positions)total_info.append(car_numbers)total_info.append(names)return total_info
因为YOLO对于图片有要求,我们要对图片相关对文件进行一定的改变。
通常我们需要对图片进行标注,通常使用labelme工具来进行图片标注 以下是常用图片标注工具的对比,对于目标检测我们使用labelme就可以了。
这个标注是把图片中的车牌框选出来,从而成为一个json文件

框中的数据就是一个车牌左上点(x1,y1)和右下点数据(x2,y2),我们需要取出这些数据出来。
但对于我们的中科大CCPD数据而言,这些数据已经写在文件名字中了,我们只需对名字进行处理,满足YOLO的一个要求。
文件名Car_data.py
ini
复制代码
import os
import Car_Model
import numpy as np
from PIL import Image
DATA_PATH = "/Users/pengpeng/Resources/Python/ccpd_base/car"# 处理文件名中的4个点坐标,并且满足YOLO要求
def process_position(data, data_name):for name, title in zip(data[3], data_name):yolo_data = []bounding_boxes = name.split("_", 4)real_positions = []image_name = []title1 = title.split('.', 2)image_name.append(title1[0])# 获得4个点数据for bbox in bounding_boxes:values = bbox.split("&", 1)for index in range(len(values)):values[index] = int(int(values[index]))real_positions.append(values)real_positions = np.int0(np.array(real_positions))# 得到整个最大的值Xs = [i[0] for i in real_positions]Ys = [i[1] for i in real_positions]x1 = abs(min(Xs))x2 = abs(max(Xs))y1 = abs(min(Ys))y2 = abs(max(Ys))'''YOLO要求这个框满足以下要求(1)需要这个框的中心坐标位置,宽度(width)和高度(height)(2)每个值必须在0-1之间的小数,所以需要进行归一化(3)还需要对每个框进行标注属于哪一个分类, 按照 分类 x, y,w,h 这五个值进行写入(4)需要对一张照片所有的框进行新建一个txt文件,存取以上内容'''# 获得图片信息,获得图片大小分别是width和heightimg_path = DATA_PATH+"/images/"+titleimg = Image.open(img_path)imgSize = img.sizeimg_width = imgSize[0]img_height = imgSize[1]# 进行归一化,直接把这些内容copy就可以了dw = 1. / img_width # 1/wdh = 1. / img_height # 1/hx = (x1 + x2) / 2.0 - 1 # 物体在图中的中心点x坐标y = (y1 + y2) / 2.0 - 1 # 物体在图中的中心点y坐标w = x2 - x1 # 物体实际像素宽度h = y2 - y1 # 物体实际像素高度x = x * dw # 物体中心点x的坐标比(相当于 x/原图w)w = w * dw # 物体宽度的宽度比(相当于 w/原图w)y = y * dh # 物体中心点y的坐标比(相当于 y/原图h)h = h * dh # 物体宽度的宽度比(相当于 h/原图h)# 把这五个值写入到文件中yolo_data.append([0, x, y, w, h])yolo_data = np.array(yolo_data)# 保存bbox的图片信息np.savetxt(os.path.join(DATA_PATH, f'labels/{title1[0]}.txt'),yolo_data,fmt=['%d', '%f', '%f', '%f', '%f'])if __name__ == '__main__':total_infos = Car_Model.load_files(DATA_PATH, True)title = Car_Model.load_files(DATA_PATH, False)process_position(total_infos, title)
另一文件processing_character.py
目的是将图片的绝对路径写入train.txt 和test.txt中
ini
复制代码
import os
import random# train所占的比例 70%
train_percet = 0.7# 文件绝对路径 Mac电脑与windows电脑的地址不同,它类似与Linux的地址
path = "/Users/pengpeng/Resources/Python/ccpd_base/car"# car文件夹下的images文件夹
images = "images"# 新建的train.txt和test.txt
names = ["train", "test"]# 访问images文件夹并把绝对地址写入train和test文件中
images_path = os.path.join(path, images)
images_path = os.listdir(images_path)
total_labels = []
for label in images_path:# 因为Mac电脑比较特殊,在每个文件中都有一个名字叫.DS_Store的隐藏文件,必须排除掉这个文件if label ==".DS_Store":continuetotal_labels.append(label)# 按照之前的概率,对数据进行随机
num = len(total_labels)
digit = range(num)
trd = int(num * train_percet)
ted = int(num * (1-train_percet))
trdr = random.sample(digit, trd) # train_digit_random
tedr = random.sample(trdr, ted) # test_digit_random# 分别写入以下两个文件中
ftrain = open(path+'/train.txt', 'w')
ftest = open(path+'/test.txt', 'w')# 根据随机进行分成train和test比例 这个是按照机器学习对train和test进行安排,当然可以按照自己对要求进行调整
for i in digit:name_path = path + "/" + images + "/" + total_labels[i] + "\n"print(name_path)if i in trdr:ftrain.write(name_path)else:ftest.write(name_path)
# 写完文件,要关闭文件
ftrain.close()
ftest.close()
按照顺序执行完以上三个,我们可以得到以下文件包含它的相应内容
完成到这里,我们车牌的检测就已经完成了大半了。
接着是打开我们的terminal或cmd 找到yolo的根目录,我这使用的是anconda的虚拟环境
在命令行上输入以下命令
css
复制代码
python train.py --data car.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 10 --epochs 3
# --data 后面是刚刚写的配置文件 以yolo为根本目录找的文件
# --cfg 使用配置,然后对这个文件进行修改
# --weights 使用模型的权制
# --batch-size 批量大小
# --epochs 简单理解为运行次数
因为使用的是mac m1pro 不能使用pytorch的gpu ,按照现在的2022 6月份 是不能使用的,只能使用cpu。计算时间很长,计算3次的时间是2个小时吧(不记得了)
最终进行简单的炼丹,也能达到一个还行的结果 
这些结果会最终得到一个文件夹存在以下中
这样我们简单的得到一个自己的车牌检测模型。
接着我们要做的就是预测我们检测车牌的结果。