下载并配置好DolphinDB,同时添加vscode的插件,我们就在vscode上进行操作
创建xxx.dos文件后,就会被识别为DolphinDB的运行文件,非常方便
文章目录
- 登录
- 数据库的操作
- 创建数据库
- 查找与删除数据库
- 示例
登录
如果是vscode,已经连接上了就不需要login,而在其他语言的接口中,需要先登录,对应的代码是:
login("admin","123456")
// DolphinDB的注释与函数命名规则与c、java这种常用的编程语言类似
数据库的操作
完整的内容这里我们就不罗列了,咱们就简单直接的几种方法,完整内容请参考:https://github.com/dolphindb/Tutorials_CN/blob/master/database.md
创建数据库
由于是分布式的数据库,因此从一开始就考虑分区的依据是最好的,分区可以加速数据库的运行效率,而常用的分区依据最好来源于主键,比如时间、股票代码这种大概率唯一的数据,就可以作为分区的依据(可以理解分区就是分开文件夹存放东西,这样我们只需要知道某个值的特征,就能一下子知道去哪个文件夹里找)
比如,创建一个以日期(年月日)作为分区依据的数据库:
database("dfs://check_db", VALUE, 2000.01.01..2001.01.01) // 创建分布式数据库
也可以创建一个以年-月作为分区依据的数据库
db=database("dfs://check_db", VALUE, 2000.01M..2016.12M) // 创建分布式数据库
我们拆解这个函数:
database("dfs://数据库的名称", 哪种类型的分区依据, 分区的数据大概长什么样子举个例子)
-
第一个参数:数据库的名称随心所欲
-
第二个参数:这里如果没有特殊需要固定VALUE就可以,它是指,按照取值的不同进行分区(分文件夹)
-
第三个参数:给个例子就行,
xxx..xxx是DolphinDB生成一个数组/列表(数据库语言叫vector)的写法,而2000.01.01是特有的年月日的写法,2000.01M是特有的年月的写法。传一个任意长度的列表进去,数据库就知道大概要按照这样的值类型分区比如
2000.01.01..2001.01.01生成的列表长这样: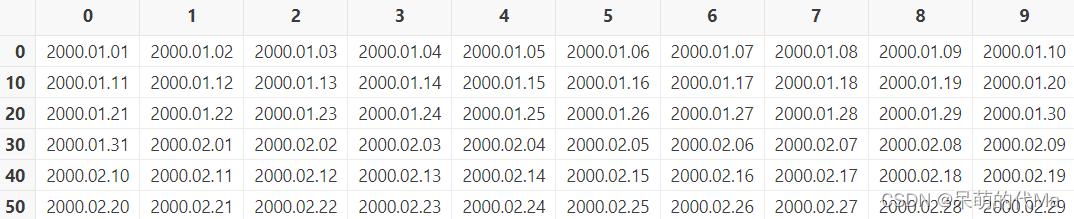
2000.01M..2016.12M生成的列表长这样:

同样1..10生成的列表长这样:

查找与删除数据库
查找数据库使用:
getAllDBs() // 返回节点上的数据库
getClusterDFSDatabases() // 返回集群中所有的数据库,单节点时,结果和getAllDBs()一致
判断数据库是否存在使用:
existsDatabase("dfs://check_db")
删除数据库使用:
dropDatabase("dfs://check_db")
示例
比如我们希望定义一个数据库叫check_db,如果存在就把它删了重新创建:
dbPath = "dfs://MyTestDB" // 变量赋值的写法
if (existsDatabase(dbPath)){ // 判断数据库是否存在dropDatabase(dbPath) // 删除数据库
}db=database(dbPath, VALUE, 2000.01M..2001.12M) // 创建一个数据库

![[C#]winform部署openvino官方提供的人脸检测模型](https://img-blog.csdnimg.cn/direct/3ba91b7e5e204a1681ee6dd9815e4af4.jpeg)