IO是什么?
IO分为两类,它们之间是有区别的,而且有很大的区别;1. 文件系统的IO
也叫本地io,就是和磁盘或者外围存储设备进行读写操作,外围设备有USB、移动硬盘等等;2. 网络的IO
将数据发送给对方 和 读取对方的数据就称为网络IO;
网络IO是如何连接的?
网络IO就是本机的应用程序对着内核的缓冲区读写的过程,发送数据时应用程序会将数据复制到内核态的写队列中,再由内核将数据复制到网卡,然后进行发送;读取数据则反过来,网卡接受到数据后将数据复制到内核态的读队列中,在通知应用程序来获取数据;
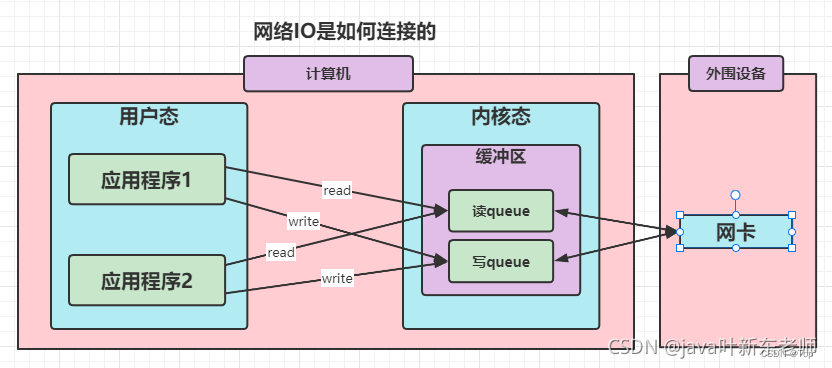
下面是一次网络读取内容的I/O示意图,数据先从外设(网卡)到内核空间,再到用户空间(JVM),最后到应用程序的一个过程。
上述一次I/O读取,所谓的阻塞和非阻塞体现在哪里呢?
Java最早期的版本的I/O就是这样实现的。当程序调用到读取I/O的时候,同步阻塞住程序,直到数据从网卡写入内核空间,在写入用户空间才返回数据,程序才可以继续进行。
BIO
BIO为同步阻塞IO,blocking queue的简写,也就是说多线程情况下只有一个线程操作内核的queue,当前线程操作完queue后,才能给下一个线程操作;
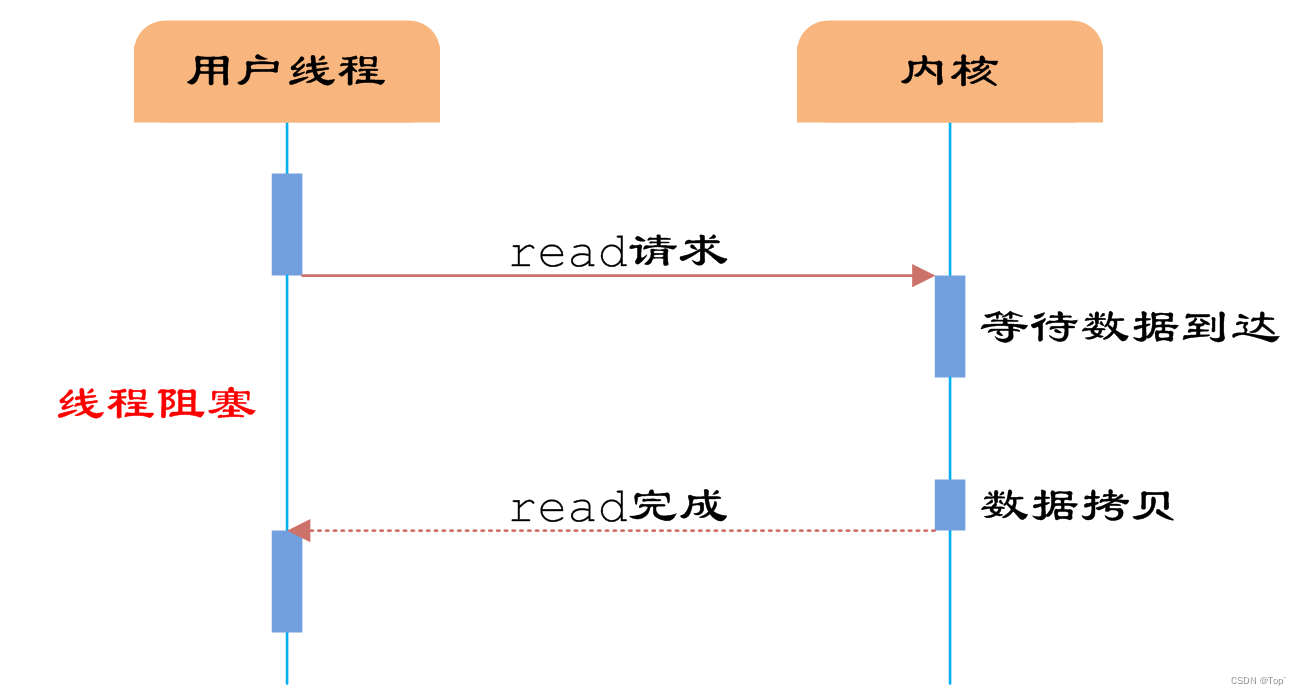
如图1所示,用户线程通过系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接收的数据拷贝到用户空间,完成read操作。
用户线程使用同步阻塞IO模型的伪代码描述为:
{read(socket, buffer);process(buffer);}
即用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
在BIO下,一个连接就对应一个线程,如果连接特别多的情况下,就会有特别多的线程,很费线程;在早期的时候,世界上的计算机还很少,网站也少,会上网的人更是寥寥无几,并发最高的时候也就几十上百个,所以当并发量不高的情况下,BIO也够用了;
NIO (流程图)
Non-blocking IO的简写,同步非阻塞IO,内核发生了变化,app访问内核的缓冲区时不会阻塞,但是返回值需要用户自己判断;如果连接数特别多的i情况下,就需要应用程序不停遍历,一个个进行状态的判断,询问是否有数据到达;
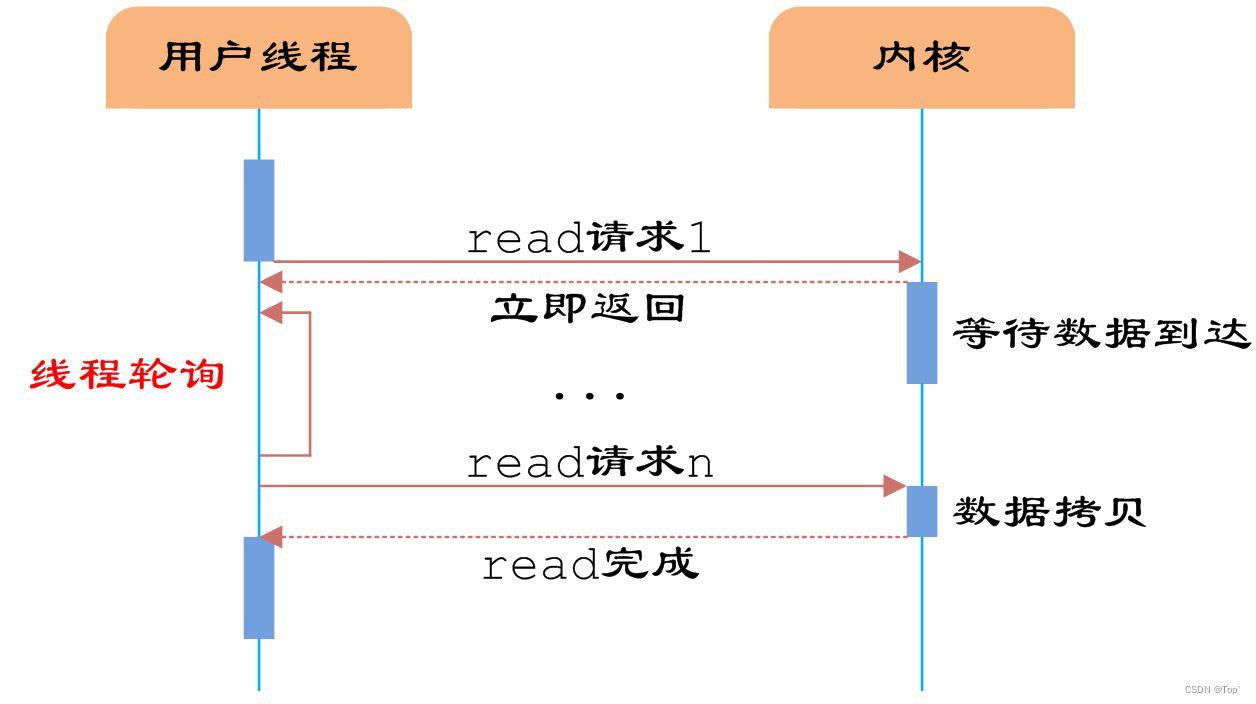
如图2所示,由于socket是非阻塞的方式,因此用户线程发起IO请求时立即返回。但并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。
用户线程使用同步非阻塞IO模型的伪代码描述为:
{while(read(socket, buffer) != SUCCESS);process(buffer);
}
即用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
IO 多路复用
多路是指网络连接,复用指的是同一个线程
为什么有IO多路复用机制?
没有IO多路复用机制时,有BIO、NIO两种实现方式,但有一些问题
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。
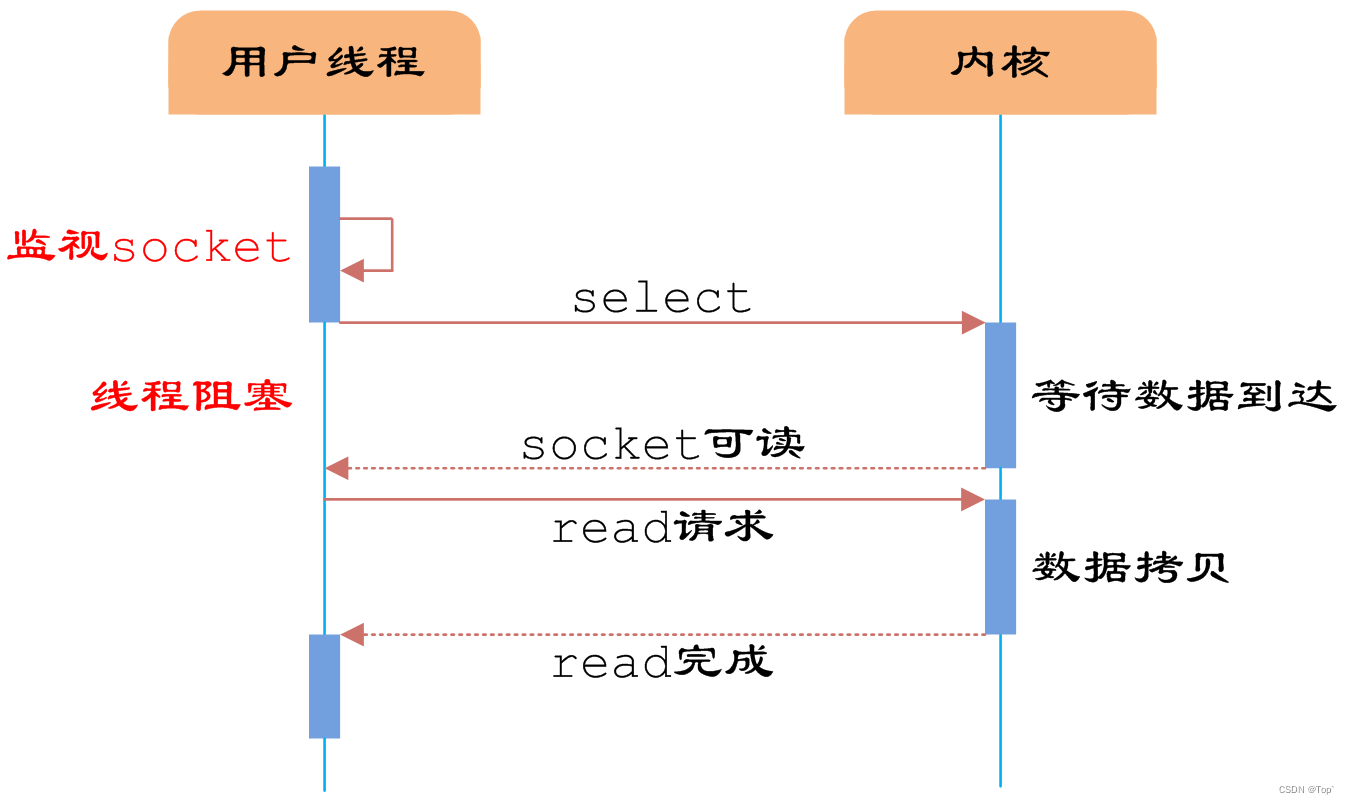
如图3所示,用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
用户线程使用select函数的伪代码描述为:
{select(socket);while(1) {sockets = select();for(socket in sockets) {if(can_read(socket)) {read(socket, buffer);process(buffer);}}}}
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦socket可读,便调用read函数将socket中的数据读取出来。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率。