Elasticsearch 索引分片的分配策略说明

在上一篇《索引生命周期管理ILM看完不懂你锤我
》(https://mp.weixin.qq.com/s/ajhFp-xBU1dJm8a1dDdRQQ)中,我们已经学会了索引级别的分片分配过滤属性,也就是在配置文件中指定当前节点的属性值node.attr.node_type: hot,这个你还记得吗,不记得的话可以回去在复习一下哦。
这一篇文章中,我们主要学习一下索引分片的分配策略,也就是分片时是根据什么规则进行分配的呢?
版本:Elasticsearch 8.1
一、索引级自定义属性分片分配策略
我们有 5 个节点,node-1,node-2,node-3 增加属性 node.attr.role: master,node-4,node-5 增加属性 node.attr.role: slave。
elasticsearch.yml 文件中配置如下:
node-1,node-2,node-3
# node-1,node-2,node-3
node.attr.role: master
node-4,node-5
# node-4,node-5
node.attr.role: slave
定义索引zfc-doc-000013,指定index.routing.allocation.include.role为slave,意思就是该索引分片只分配到node.attr.role的值为slave的节点上。
PUT zfc-doc-000013
{"settings": {"number_of_replicas": 0,"number_of_shards": 3,"index.routing.allocation.include.role":"slave"}
}
当前集群为 5 个节点的集群,其中只有 node-4、node-5 的 role 为 slave ,所以创建的索引 zfc-doc-000013 只会在这两个节点 node-4、node-5 中进行分配,而不会在 node-1、node-2、node-3中进行分配。
二、节点离开时触发分配
当集群中的节点由于未知的原因或者已知的原因离开集群时,主节点会做出以下反应:
- 如果当前离开的节点上有主分片,会将其它的副本分片提升为主分片以替换该节点上的主分片;
- 如果有足够多的节点,分配副本分片来替代当前节点丢失的副本分片;
- 在剩余的节点之间进行重新平衡分片。
通过上述的操作可以让我们尽可能的防止数据丢失,但是如果离开的节点很快就恢复那么这可能就是没有必要的操作了。所以哪怕我们在节点级别和集群级别限制并发恢复,这种重新分配分片仍然会给系统带来大量的额外负载。
想象一下以下场景:
- 节点
node-3离开集群 - 主节点将节点
node-3上的主分片的副本分片提升为主分片 - 主节点将新的副本分配给集群中的其它节点
- 每个新副本都会通过网络创建主分片的完整副本
- 更多的分片被移动到不同的节点以重新分片分配达到平衡
- 几分钟之后节点
node-3返回加入集群 - 主分片将分片分配给节点
node-3以重新平衡集群
集群初始分配状态

停掉节点 node-3
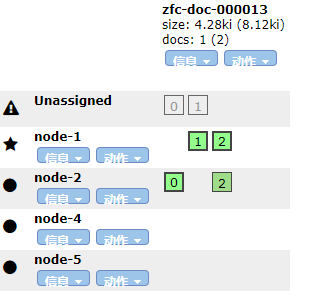
默认等待一分钟之后,系统自动进行分片的重新分配

节点恢复之后进行分片重新分配
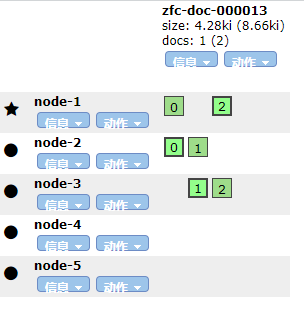
由于节点离开造成的未分配分片可以通过修改参数 index.unassigned.node_left.delayed_timeout 动态设置延迟时间,默认 1m。
可以在单个索引或者全部索引上进行设置该参数。
PUT zfc-doc-000013/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "2m"}
}
此设置不会影响副本分片升级为主分片,也不会影响之前未分配的副本的分配。需要注意的是,该设置在集群重启之后会失效。
2.1、取消分片分配
如果延迟分配超时,主节点会将丢失的分片分配给另一个节点,该节点将开始恢复。
如果离开的节点重新加入集群,并且其分片仍然具有与主分片相同的 sync-id,分片的重新分配将被取消,同步分片将恢复。
因此默认超时设置为一分钟,即使分片重新分配已经开始,取消的成本也很低。
我们可以通过如下 API 查看集群健康状态。
GET _cluster/health
2.2、节点永久离开
如果一个节点离开集群之后确定不会在返回,我们可以通过设置参数 index.unassigned.node_left.delayed_timeout 为 0 来让 Elasticsearch 马上分配未分配的分片。
PUT _all/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "0"}
}
三、索引恢复优先级
对于索引分片的重新分配,对于索引来说是有优先级的。
1、index.priority最高的优先
2、其次是索引的创建时间
对于如下例子,我们可以自己测试一下:
PUT zfc-doc-index_1PUT zfc-doc-index_2PUT zfc-doc-index_3
{"settings": {"index.priority": 10}
}PUT zfc-doc-index_4
{"settings": {"index.priority": 5}
}
zfc-doc-index_3第一个被恢复,因为它的优先级index.priority最高。zfc-doc-index_4第二个被恢复,它的优先级仅次于索引zfc-doc-index_3。zfc-doc-index_2第三个被恢复,它是最近创建的。zfc-doc-index_1最后被恢复。
四、节点总分片数限制
Elasticsearch 的集群在分配分片的时候,Elasticsearch 会尽可能的将单个索引的分片尽可能的分配在尽可能多的节点上,但是有时不是那么的均匀。我们可以通过以下设置修改允许每个节点上单个索引的分片总数的限制,index.routing.allocation.total_shards_per_node 分配给单个节点的最大分片数,默认没有限制。
PUT zfc-doc-000013/_settings
{"settings":{"index.routing.allocation.total_shards_per_node": 2}
}
也可以在不考虑索引的情况下限制节点可以拥有的分片数量 cluster.routing.allocation.total_shards_per_node 分配给每个节点的主分片和副本分片的最大数量,默认 -1 没有限制。
PUT _cluster/settings?flat_settings=true
{"transient":{"cluster.routing.allocation.total_shards_per_node":2}
}
Elasticsearch 会在分片的重新分配期间进行校验该参数,有如下场景:
一个 Elasticsearch 集群,有三个节点,cluster.routing.allocation.total_shards_per_node 设置为100,并且具有如下的分片分布情况
- 节点1:100个分片
- 节点2:98个分片
- 节点3:1个分片
如果节点3发生故障,Elasticsearch 会将其分片重新分配到节点2,并不会分配到节点1,因为分配到节点1会超过设置的100分片限制。
需要注意的是,如果我们设置了该参数,可能会导致部分分片无法进行分配。
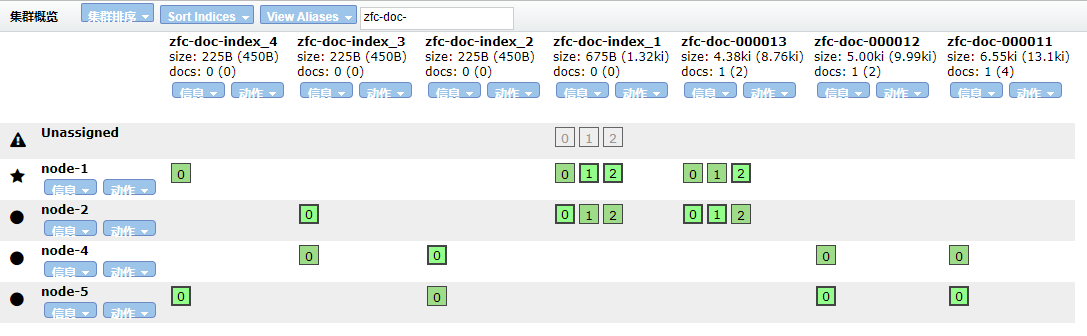
下面我们用个例子来说明,首先看如下是我本地 Elasitcsearch 集群的部分索引
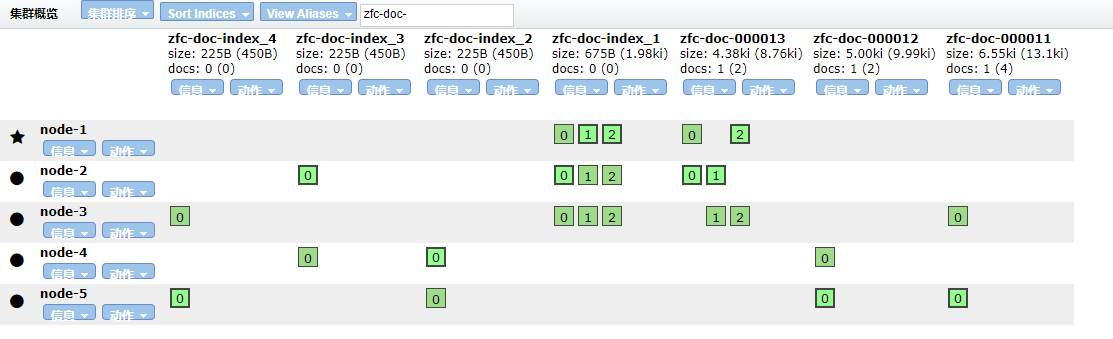
我们通过使用 API 动态修改参数之后,让其重新进行分片分配会发生什么情况呢?
如下语句意思就是每个节点主分片加副本分片数量不能大于 2,所以在下次发生分片的重新分配时肯定会无法进行分配。
PUT _cluster/settings?flat_settings=true
{"transient":{"cluster.routing.allocation.total_shards_per_node":2}
}
停止 node-3 节点之后,分片无法分配。
在上面更改集群的设置时,我们可能已经注意到了,使用的是
transient,还可以使用persistent,他俩的区别就是transient的配置会在集群重启之后失效,persistent会持久化保存。
不过这几个配置的优先级如下:
1、transient
2、persistent
3、elasticsearch.yml
4、设置的默认值
五、索引级别数据层过滤
索引级别过滤与前面的自定义属性分片分配类似,不过索引级别使用的是_tier_preference 来控制索引分配到哪个数据层。
这块不是特别了解的可以参考文章开头引用的索引生命周期那篇文章,该文章内通过例子展示了索引的生命周期。
我们还是用一个例子来说明
首先在elasticsearch.yml 定义角色
node-1,node-2中定义 node.roles: ["data_hot", "data_content"]
node-3,node-4中定义 node.roles: ["data_warm","data_content"]
node-5中定义 node.roles: ["data_cold","data_content"]
关于节点角色的定义,可以参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-node.html#master-node
集群按照上面的配置完成之后,启动如下
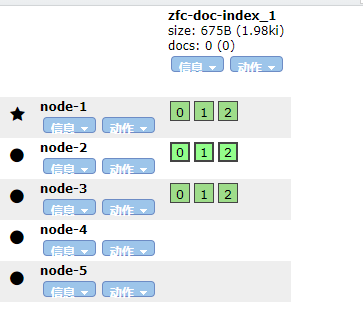
通过 API 定义索引 zfc-doc-index_1 的分片分配策略在 data_warm 层
PUT zfc-doc-index_1
{"settings": {"number_of_replicas": 2,"number_of_shards": 3,"index.routing.allocation.include._tier_preference": "data_warm"}
}
按照预期的设定,索引的分片应该是分布在 node-3,node-4 中,结果如下:

可以看到,有分片是没有进行分配的,所以这也是修改分片分配策略时需要特别注意的一点。
总结
通过上面的学习,我们知道了:
- 可以通过自定义属性
node.attr.[]控制分片的分配 - 可以通过索引级别的角色
index.routing.allocation.include._tier_preference进行数据层的过滤分配 - 分片的分配过程中是可以通过
index.priority指定优先级的 - 可以通过
index.routing.allocation.total_shards_per_node控制每个节点上单个索引的分片数量 - 可以通过
cluster.routing.allocation.total_shards_per_node控制每个节点上所有主分片加副本分片的总数量