目录
一、什么是Kafka,如何学习
二、如何整合SpringBoot
三、Kafka的优势

一、什么是Kafka,如何学习
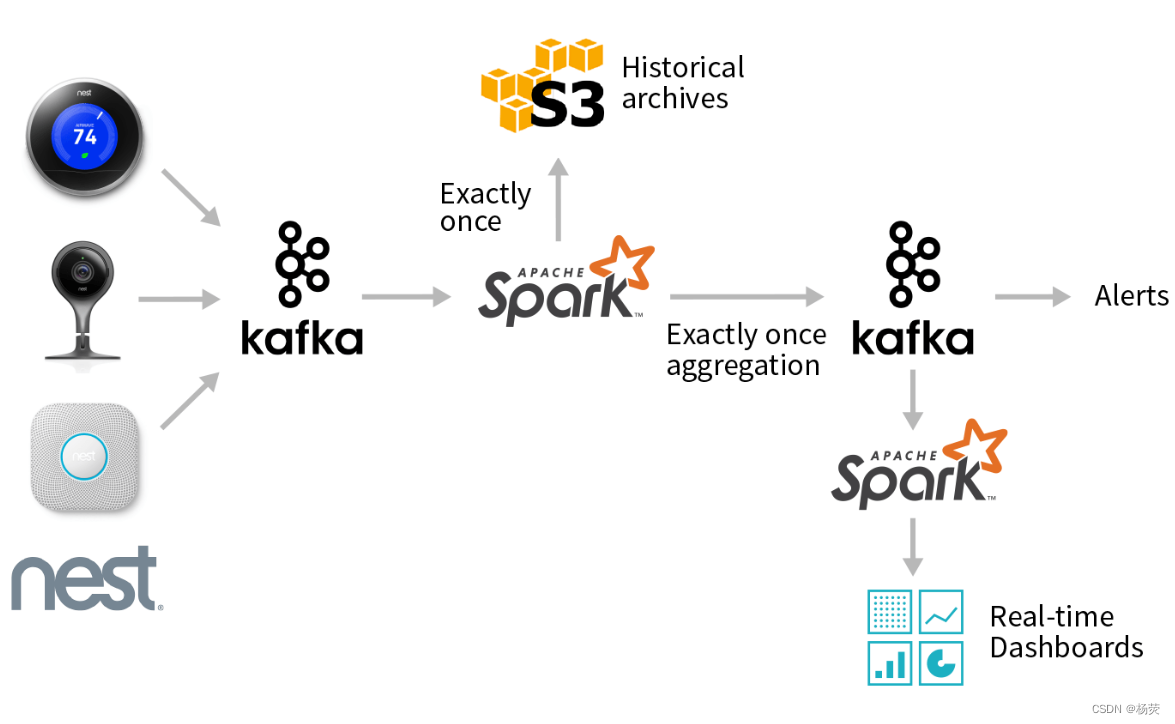
Kafka是一种分布式的消息队列系统,它可以用于处理大量实时数据流。学习Kafka需要掌握如何安装、配置和运行Kafka集群,以及如何使用Kafka API编写生产者和消费者代码来读写数据。此外,还需要了解Kafka的基本概念和架构,包括主题(topics)、分区(partitions)、消费者组(consumer groups)等。
学习Kafka可以通过以下步骤进行:
-
学习Kafka基础知识:你可以通过阅读官方文档或参考Kafka的相关书籍来学习Kafka的基本概念和架构。
-
安装Kafka:你需要在本地或远程服务器上安装Kafka集群,并了解如何配置和启动Kafka。
-
编写Kafka生产者代码:你需要使用Kafka提供的API编写生产者代码,以便将数据写入Kafka集群中的主题(topics)。
-
编写Kafka消费者代码:你需要使用Kafka提供的API编写消费者代码,以便从Kafka集群中的主题(topics)中读取数据。
-
实践应用场景:你可以将Kafka应用到实际场景中,例如日志收集、数据传输、事件处理等。
总之,学习Kafka需要一定的专业知识和实践经验,但是只要认真学习和实践,你就能够掌握Kafka的基本用法。

二、如何整合SpringBoot
以下是一个简单的Kafka整合Spring Boot的样例代码:
首先,在pom.xml文件中添加以下依赖:
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>${spring.kafka.version}</version>
</dependency>
其中,${spring.kafka.version}是你使用的Spring Kafka版本号。
创建一个Kafka配置类:
@Configuration
@EnableKafka // 开启Kafka支持
public class KafkaConfiguration {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;@Beanpublic Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);return props;}@Beanpublic ProducerFactory<String, Object> producerFactory() {return new DefaultKafkaProducerFactory<>(producerConfigs());}@Beanpublic KafkaTemplate<String, Object> kafkaTemplate() {return new KafkaTemplate<>(producerFactory());}@Beanpublic ConsumerFactory<String, Object> consumerFactory() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);return new DefaultKafkaConsumerFactory<>(props, new StringDeserializer(),new JsonDeserializer<>(Object.class));}@Beanpublic ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());return factory;}@Beanpublic KafkaAdmin admin() {Map<String, Object> configs = new HashMap<>();configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);return new KafkaAdmin(configs);}
}
在上面的代码中,我们配置了生产者和消费者的参数,并创建了相应的Bean。
接下来,创建一个Kafka生产者:
@RestController
public class ProducerController {private final KafkaTemplate<String, Object> kafkaTemplate;@Autowiredpublic ProducerController(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}@PostMapping("/send")public void sendMessage(@RequestParam("message") String message) {kafkaTemplate.send("test_topic", message);}
}
在上面的代码中,我们通过@Autowired注入了之前定义的KafkaTemplate Bean,并使用它来发送消息到名为“test_topic”的Kafka主题。
最后,创建一个Kafka消费者:
@Component
public class Consumer {@KafkaListener(topics = "test_topic", groupId = "group1")public void consume(String message) {System.out.println("Received message: " + message);}
}
在上面的代码中,我们使用@KafkaListener注解指定了要监听的Kafka主题名称和消费者组ID,并编写了一个consume()方法来处理接收到的消息。
以上就是一个简单的Kafka整合Spring Boot的样例代码。

三、Kafka的优势
Kafka的应用场景主要涵盖以下几个方面:
-
日志收集:Kafka可以作为一个高效的日志收集系统来使用,通过将各种不同来源的日志数据写入到Kafka中,并让多个消费者去并发地读取和处理这些日志数据,从而实现了实时、可靠的日志收集功能。
-
流式数据处理:Kafka能够支持流式数据处理,它可以将不同来源的数据流按照某种规则进行分区存储,并允许用户实时地对这些数据流进行处理、计算和聚合等操作。
-
数据传输:由于Kafka的高吞吐量和低延迟特性,因此它可以作为一种高效的数据传输工具,用于在不同的应用之间传输数据。
-
事件处理:Kafka可以作为一个事件驱动型的消息队列系统来使用,在各种事件产生的时候,通过向Kafka发送事件消息来触发后续的处理逻辑,从而使得整个事件处理过程更加简单和可控。
Kafka的优势主要体现在以下几个方面:
-
高吞吐量和低延迟:Kafka通过实现基于文件的存储方式和批量发送机制,来实现了极高的吞吐量和极低的延迟,从而能够满足大规模实时数据处理的需求。
-
可靠性保证:Kafka的主题和分区机制可以提供高可靠性的消息传输保障,即使某一个Broker节点出现故障,也不会影响整个集群的运行。
-
可扩展性:Kafka具有良好的可扩展性,可以支持数百甚至数千个Broker节点组成的大规模集群,并支持动态添加和删除节点。
-
灵活性:Kafka提供了丰富的API接口和各种配置选项,可以根据用户的需求进行自定义设置和使用。