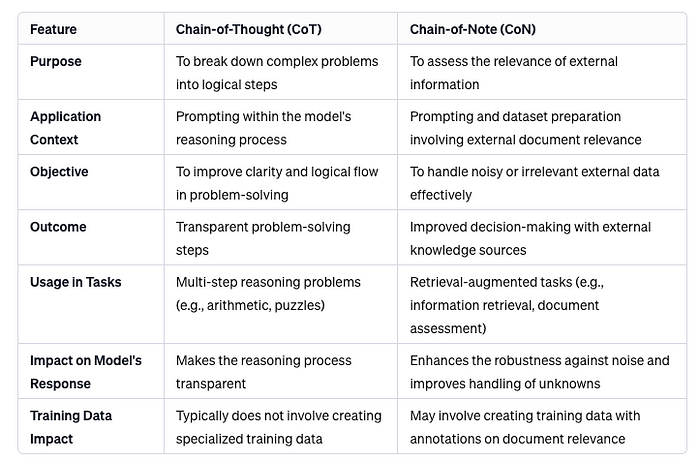
当我学习到这个知识点的时候十分困惑,因为从名字中我完全无法理解这个什么东西。于是呢我就去问了一下维基百科,下面是他的回答:
特征工程(英语:feature engineering)又称特征提取(英语:feature extraction)或特征发现(英语:feature discovery)是使用领域知识从原始数据中提取特征(特征、属性、特性)的过程。 与仅向机器学习提供原始数据相比,其动机是使用这些额外的功能来提高机器学习过程的结果质量。
说实话,当我看完段文字后,我心情是复杂的,因为我觉得这不但没有解决我原有的困惑,反而更加迷糊了。如果你和我有一样的困扰,那么我试试用通俗点的语言和一些小例子来让我们一起理解什么是特征工程。
一、什么是特征?
要理解特征工程必须先知道什么是特征。在我之前的文章中我详细的介绍过什么是特征,你可以去瞧瞧看,在这里我简单用几个例子给大家说明。
【机器学习300问】6、什么是机器学习中的特征量?![]() http://t.csdnimg.cn/WKohN
http://t.csdnimg.cn/WKohN
例一:一个人有两只手、两只腿、一个头、能使用工具、会奔跑。在这句话中,这些用来描述人的词语就是特征。
例二:一套房子的信息中有房屋宽度、房屋深度、房间数量、楼层数量、地理位置、房屋年限。这些用来描述房子的词语就是特征。
把上述的例子用一个二维表格来表示的话就可以画成这样:
| 房屋宽度 | 房屋深度 | 房间数量 | 楼层数量 | 地理位置 | 房屋年限 | |
| 房1 | 10 | 10 | 4 | 1 | 市中心 | 10 |
| 房2 | 8 | 12 | 4 | 1 | 市中心 | 5 |
| 房3 | 9 | 9 | 3 | 1 | 郊区 | 2 |
特征就是这样的表格中的每一列,一列就是一个特征!
二、什么是特征工程?
上面的这个表中有很多列,这些原本就在表中的列,我们叫他原始数据,或者叫他原始特征。特征工程其中的“工程”两个字就是说要对这个特征做写什么操作。那么做什么操作呢?做这些操作的目的是什么呢?如果搞懂了这两个问题,那么你就真正了解了什么是特征工程。
(1)特征工程要处理的数据常见的形式
- 结构化数据,结构化数据类型可以看做关系型数据库的一张表(就像上面这张表),每一列都有很清晰的定义,包含了数值型、类别型两种基本类型。每一行数据表示一个样本信息。
- 非结构化数据,非结构化数据主要包括文本、图像、音频、视频数据,其中包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每一条数据的大小各不相同。
(2)特征工程具体要做哪些操作
-
数据清洗:去除无效、缺失、重复的数据,处理异常值,填充缺失值等。
-
特征选择:确定哪些特征对模型预测目标变量最有价值,剔除冗余、无关或者噪声特征。
-
特征构造:基于领域知识或数据分析结果创建新的特征,例如在上面表中,我们只知道房屋的宽度和深度两个特征,但如果我想预测房屋的房价,那么面积 = 宽度 * 深度就更贴合我需要分析的问题。“面积”这个特征就是我构造出来的。
-
特征缩放:对特征进行归一化或标准化处理,确保不同尺度的特征在模型训练中具备可比性。
-
特征组合:将多个特征通过数学运算(如乘法、加法、逻辑运算等)组合成更高阶的特征。
(3)特征工程的目的是什么
特征工程是从原始数据中提取、转换、构建具有代表性和预测能力的新特征的过程。特征工程的主要目的是提取出对预测模型有用的信息,这些信息以特征的形式表现出来。特征在机器学习模型中被用来预测或分类数据,因此它们必须包含足够的有用信息,以帮助模型做出准确的预测或分类。