在前面的文章中,我们了解了Python爬虫的一些内容。截止到现在,我们已经可以将需要的数据通过爬虫获取,并保存到CSV文件中。
在有了数据集后,接下来我们就开始了解如何将数据集的内容加载到Python中。虽然在之前也有了解简单的读取csv数据。但是存在两个问题:
- 只能读取csv文件,但数据分析的数据除了可能来自 csv,也可能来自 Excel,甚至可以来自 html 的表格。
- 读取到的结果一般是字典列表,并不利于分析,比如虽然我们每个字典就代表一行记录,但一旦我们想拿某一列的数据的时候就会非常复杂。
Python 作为数据分析领域的头号种子选手,自然不会只有 csv 模块这样的初级工具。这个部分我们将会学习表格类型的大数据处理神器:pandas.
pandas 不仅可以从多种不同的文件格式读取数据,还有各种各样的数据处理的功能。可以说学好了pandas,就基本已经算踏上了数据分析之路。话不多说,我们这就开始 pandas 之旅。
1、安装pandas
打开开始菜单 → Anaconda3 → Anaconda Prompt, 并输入 conda install pandas 回车执行, 如下图所示。
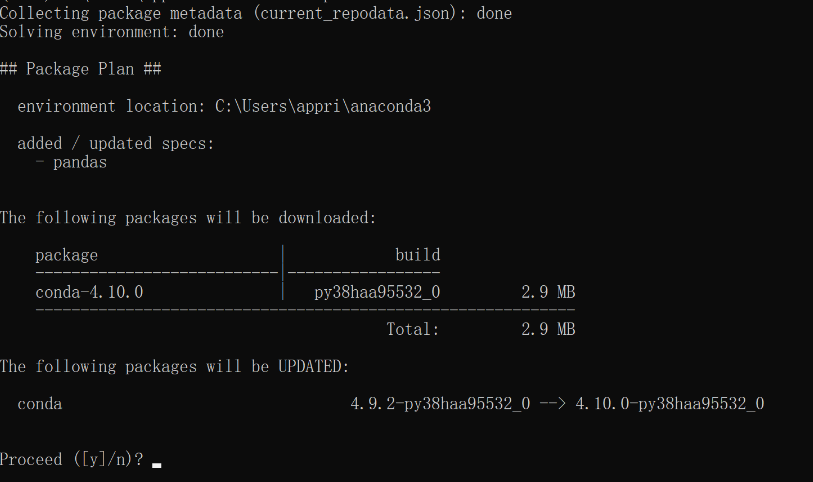
输入y完成安装即可。
2、使用pandas读取csv文件
首先我们来了解如何使用 pandas 来读取 csv 文件。
pandas 模块提供了一个 read_ csv 的方法,可以直接读取 csv 文件,并返回一个 DataFrame 对象。DataFrame 对象是 pandas 模块的核心,pandas 的所有表格都是通过 DataFrame 对象来存储的,并且 DataFrame 还提供了非常多查看数据、修改数据的方法。我们在之后的文章中会逐渐了解 DataFrame 的用法。
现在只需要知道,pandas 可以直接从一个 csv 文件中,将数据读到 Python 中,并且以DataFrame 对象的形式返回,我们拿到这个对象就可以查看其中的数据就可以了。
(1)实战 read_ csv
新建 Cell, 输入如下的代码。
# 使用 pandas 模块的 read_ csv 函数,读取 csn 文件。并将结果存在 df_rating 变量中df_rating = pd.read_ csv("tv_rating. csv")# 打印 df_rating 变量print("df_rating:")print(df_rating)# 打印 df_rating 变量的类型print("df_rating type:")print(type(df_rating))运行之后输出如下所示。

从上面的输出中可以看到,df_rating 变量中包含了我们 csv 文件中的所有数据,并且还有形状的描述:9720 行 x 3列,这个也和我们下载的数据一致。通过打印 df_rating 的类型,可以看到 df_rating 的类型就是我们上文提到的 DataFrame。
(2)更好看的表格
DataFrame 很强大,它甚至针对 notebook 有专门优化。回到 DataFrame, 当我们不是直接用 print 打印它,而是把 DataFrame 变量放在 Cell 的末尾时, notebook 就会用一种更好看的格式来打印它。我们马上来试一下,直接新建一个 Cell,输入如下的代码运行。
df_rating
输出如下:
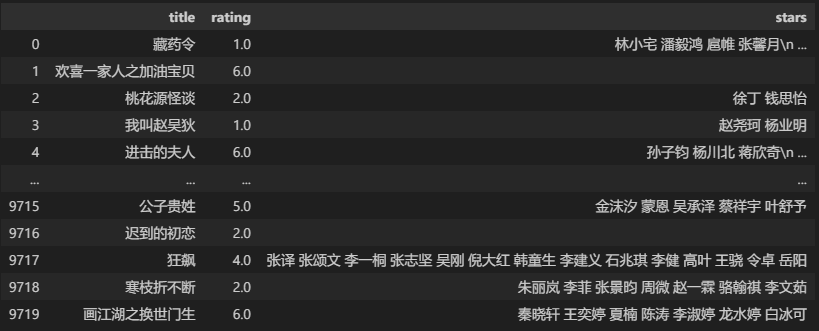
可以看到这一次的格式可比上一次好看多了,更像一个表格,对应的也更加整齐。
3、使用 pandas 读取 excel 文件
在 Python 还没有兴起之前,大量的数据分析是通过 Excel 完成的。这也造就了在很多传统行业中,还有大量的数据是保存在 Excel 中,所以读取 Excel 也是进行分析也是 Python 数据分析领域的常见任务。
Excel 的 .xls/.xlsx 文件格式是微软针对表格开发的,只能使用 Excel 来打开,比如用记事本打开往往会看到有乱码。那 Python 是怎么读取 Excel 里面的内容呢?那自然是我们本模块的 Super Star:pandas。
类似 csv 的读取,pandas 也提供了 read_excel 函数来实现读取 excel 文件中的内容,但是使用方法比 read_ csv 稍微复杂一些。
(1)数据准备
打开 Excel ,将第一个表格(sheet)的名字改为:基本信息,并添加下述内容

再新建一个sheet,表格名字改为:绩效,并添加如下内容

(2)读取数据
数据准备完毕了,现在我们来读取我们刚才创建的表格。形式类似刚才的 read_ csv。
代码如下:
# 使用 read_excel 函数,读取 info.xlsx 的内容并存储在 df_info 变量中df_excel = pd.read_excel("info.xlsx")# 不用 print,直接将 df_info 放在最后一行,让notebook用表格形式打印df_excel输出如下:
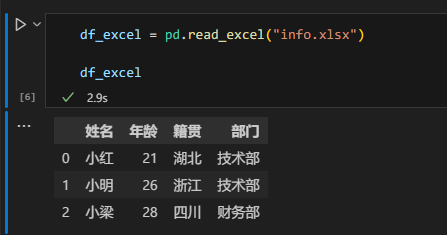
可以看到,Excel 中的数据被成功的打印了出来,和 read_ csv 一样,read_excel 返回的也是一个 DataFrame。
不过内容虽然打印出来了,但是只打印出了第一个表格,也就是“基本信息”这个表格,我们后面添加的“绩效”表格并没有打印出来。这是 pandas 的机制导致的,read_excel 默认读取 excel 文件中的一个表格。
一个 Excel 中包含多个表格还是很常见的,pandas 不可能坐视不理,如何读取更多的表格呢?
(3)读取不同的表格
read_excel 比 read_ csv 复杂的地方就在于,read_excel 支持非常多的参数。比如要实现读取后面的表格,我们只需要给 read_excel 函数的 sheet_name 参数赋值即可。
代码如下:
df_excel = pd.read_excel("info.xlsx", sheet_name="绩效")df_excel
输出如下:
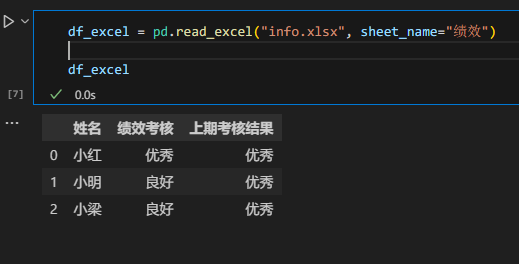
可以看到,这次输出的就是我们增加的“绩效”表格中的内容。
简单来说,我们可以在 read_excel 中,通过给 sheet_name 赋值来决定要加载文件哪个表格,如果不指定,pandas 则默认加载第一个表格。
(4)选择性读取
excel 文件的数据很多,全部加载到 Python 中可能会卡,而且有时候我们只对其中某几列感兴趣,全部加载显示也不容易看。read_excel 提供了 usecols 参数,可以指定要加载哪几列。
举个例子,刚才的“绩效”表格,我们对上期考核结果不感兴趣,只想加载姓名和绩效考核这两列的内容。那我们可以这么做,新建 Cell,输入如下代码。
df_excel = pd.read_excel("info.xlsx", sheet_name="绩效", usecols="A,B")df_excel
输出如下:
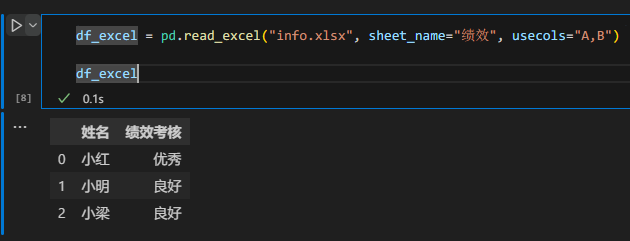
在上面的代码里,我们通过字母 A 和 B 指定了加载第一列和第二列。字母和列的对应关系其实就是 Excel 里面的对应关系。(具体大家可以看看excel文件中名称和绩效考核字段上面的字母)
4、使用 pandas 读取 html 文件
有的时候数据并不是整理好的 csv 表格或者 Excel 表格,而是以网页中的表格的形式存在,最常见的就是各类股票财经网站,比如像同花顺的股票涨跌幅数据中心或者像招行银行的外汇行情页面:

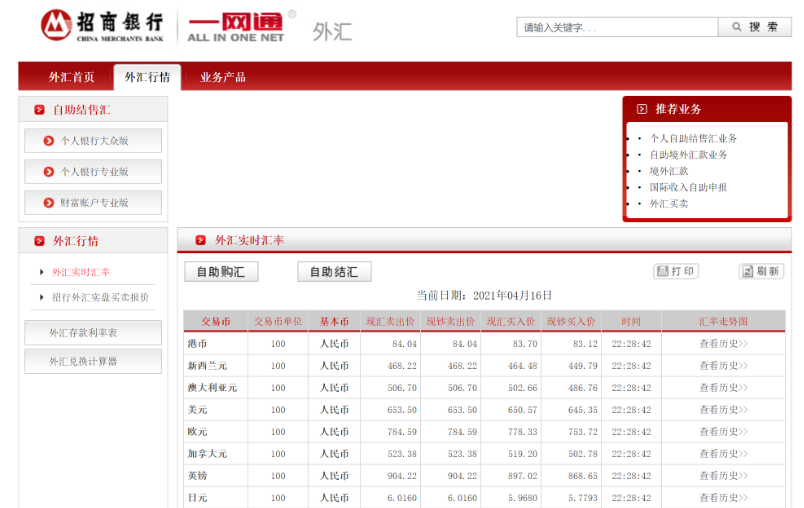
如果我们希望将这些网页中的表格“导入”到 Python 进行处理,那自然也是可以的。根据我们上一个部分的爬虫技术,我们只需要将这个页面的 html 下载下来,然后用 BeautifulSoup 分析表格的标签结构,然后把内容一行一行的提取出来,再一步一步拆分成列。
做是可以做,但只听这个流程,只看这个复杂的页面,都让人觉得工作量很大。而对于提取网页中的表格,其实存在一个非常简单的方法:使用强大的 pandas。
和 read_ csv、read_excel 类似,pandas 也提供了一个 read_html 的方法,来智能的提取网页中的所有表格,并以 DataFrame 列表的形式返回,一个表格对应一个 DataFrame。看到这里,是否有感触到 pandas 的强大之处?
下面我们来通过Python的read_html方法来加载招商银行网页中的数据。
(1)准备网页
首先要做的第一件事,就是要拿到网页的内容。在前面的文章中,我们已经写过了一个拿网页内容的函数。,直接复制过来,代码如下:
import urllib3def download_content(url):# 创建一个 PoolManager 对象,命名为 httphttp = urllib3.PoolManager()# 调用 http 对象的 request 方法,第一个参数传一个字符串 "GET"# 第二个参数则是要下载的网址,也就是我们的 url 变量# request 方法会返回一个 HTTPResponse 类的对象,我们命名为 responseresponse = http.request("GET", url)# 获取 response 对象的 data 属性,存储在变量 response_data 中response_data = response.data# 调用 response_data 对象的 decode 方法,获得网页的内容,存储在 html_content # 变量中html_content = response_data.decode()return html_contenthtml_content = download_content("http://fx.cmbchina.com/Hq/")执行上述代码之后,网页内容就已经存储在 html_content 变量中。
(2)读取数据
在准备好了网页的内容之后,我们就可以调用 read_html 函数来获取表格了。
# 调用 read_html 函数,传入网页的内容,并将结果存储在 cmb_table_list 中# read_html 函数返回的是一个 DataFrame 的listcmb_table_list = pd.read_html(html_content)# 打印 list 的长度,看看抽取出了几个表格print(len(cmb_table_list))执行代码,输出结果为 2。这说明找到了两个表格。现在我们来从列表中找出我们要的表格,首先查看第一个 DataFrame。
新建 Cell, 输入以下代码并运行。
# 直接写变量,利用 notebook 的特性打印表格cmb_table_list[0]执行后,输出如下:
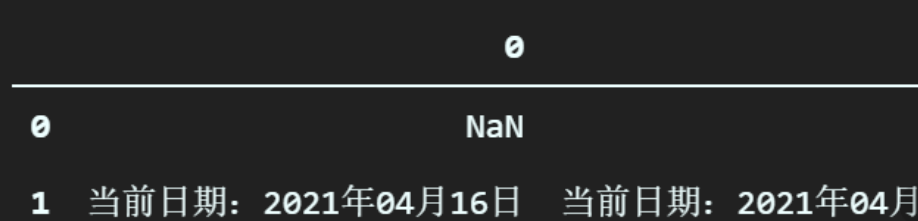
很明显,这不是我们要的表格,现在我们看第二个。
新建 Cell,输入如下的代码。
cmb_table_list[1]执行之后,输出如下所示。
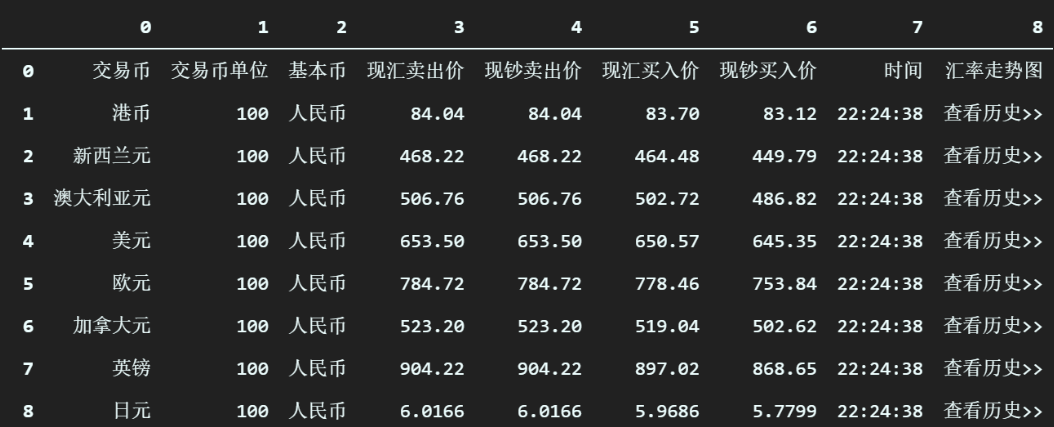
很明显,这个就是我们要的表格了。可以看到我们在招行官网上看到的汇率表格已经完整的被加载到了 pandas 的 DataFrame 中,并且能够以表格的形式打印出来。是不是感觉到非常神奇?
如果我们用 BeautifulSoup 来解析这个网页然后提取出表格的内容,恐怕代码都要写大几十行,而 pandas 却一个函数搞定了。
更多内容欢迎关注微信公众号:服务端技术精选