0. Outline

1. Graph Search Basis
Configuration Space等概念

机器人配置: 指机器人位置和所有点的表示。
DOF: 指用于表示机器人配置所需的最小的实数坐标的数量n。
C-space: 包含机器人n维所有配置的空间。
在C-space中机器人的pose是一个点。
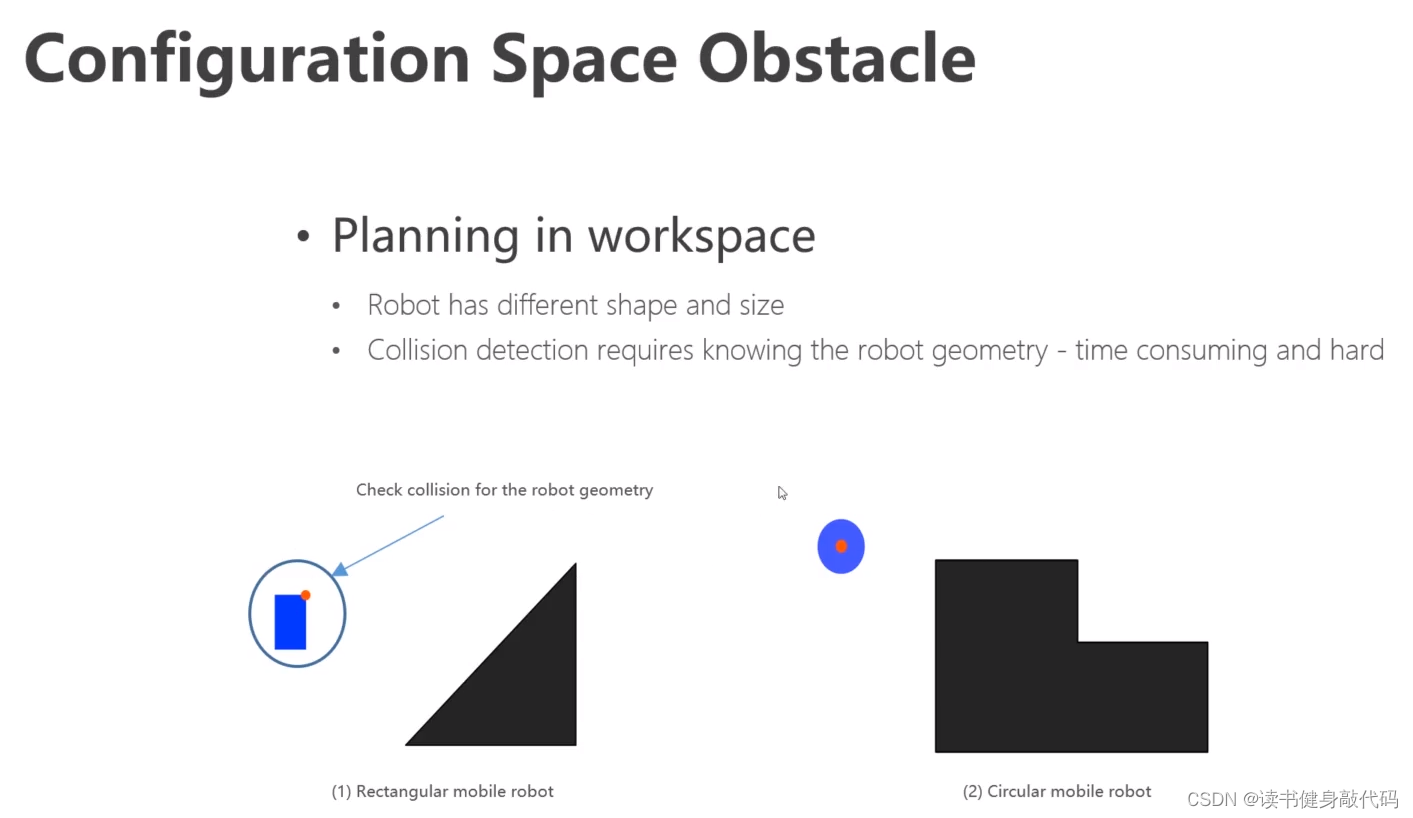

- 机器人在C-space中被表示为一个点,pose包含为R,t
- 空间中的障碍物也需要映射到C-space中,并且根据机器人的尺寸做膨胀(该过程是one-time work,可一次完成,因为如果点碰不到膨胀边缘,就不会碰到障碍物),叫做C-obstacle
- S-space=(C-obstacle) U (C-free)
- path是在C-free中从起点start到终点goal
eg:如果将机器人建模为一个半径为 δ r \delta_r δr的球,那么将obstacle向外膨胀 δ r \delta_r δr,即可对一个点进行palnning

2. Graph and Search Method
无向图,有向图,加权图(权值根据具体问题定义,可能是长度,可能是消耗的能量,可能是风险等等)

基于搜索的图有栅格,本身就包含关系,而基于采样的图则没有这种关系。
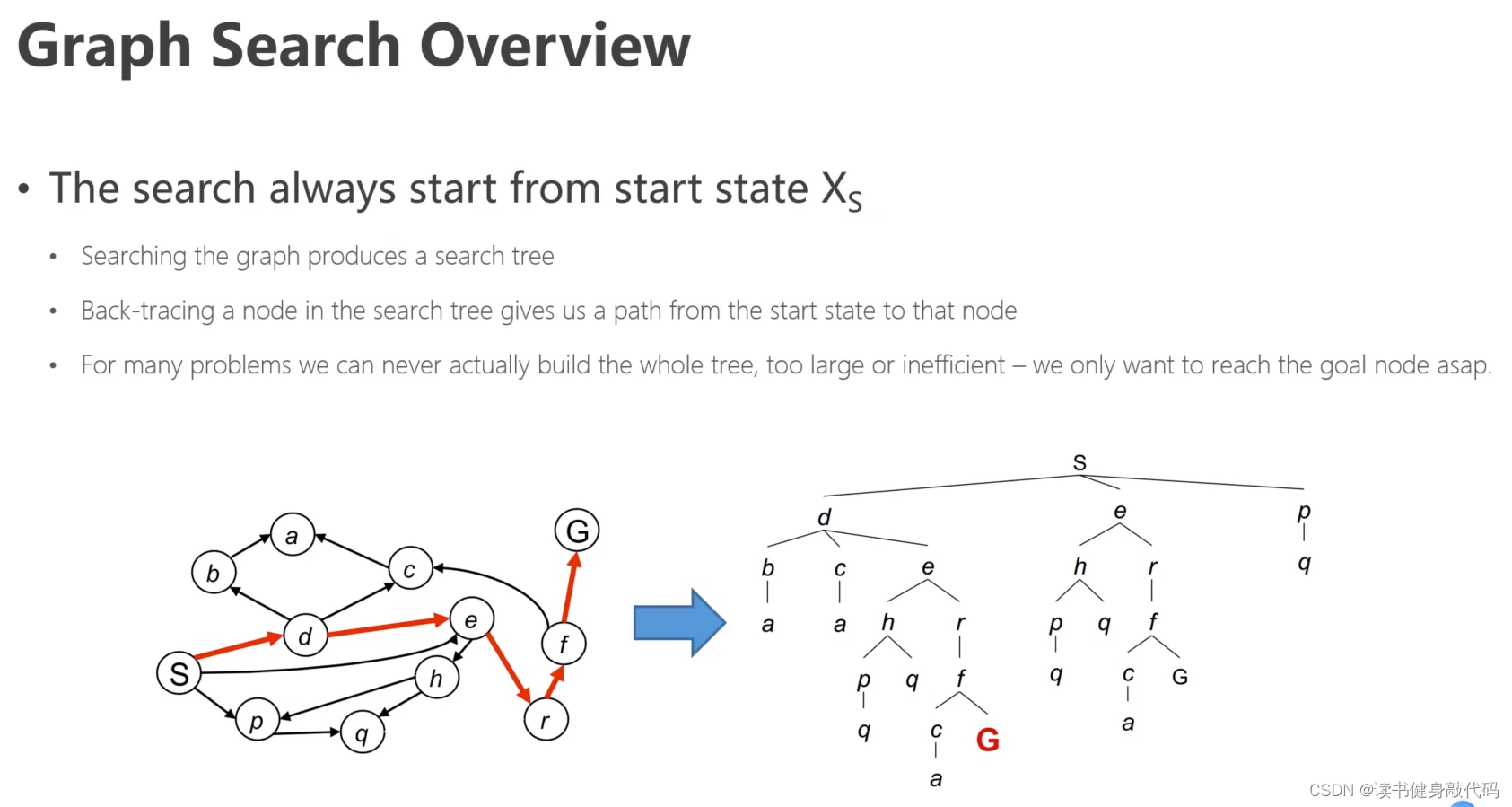
搜索的过程即构建搜索树的过程,但该过程往往代价较大,我们的目标是设计尽可能快且不失最优性的路径搜索算法。


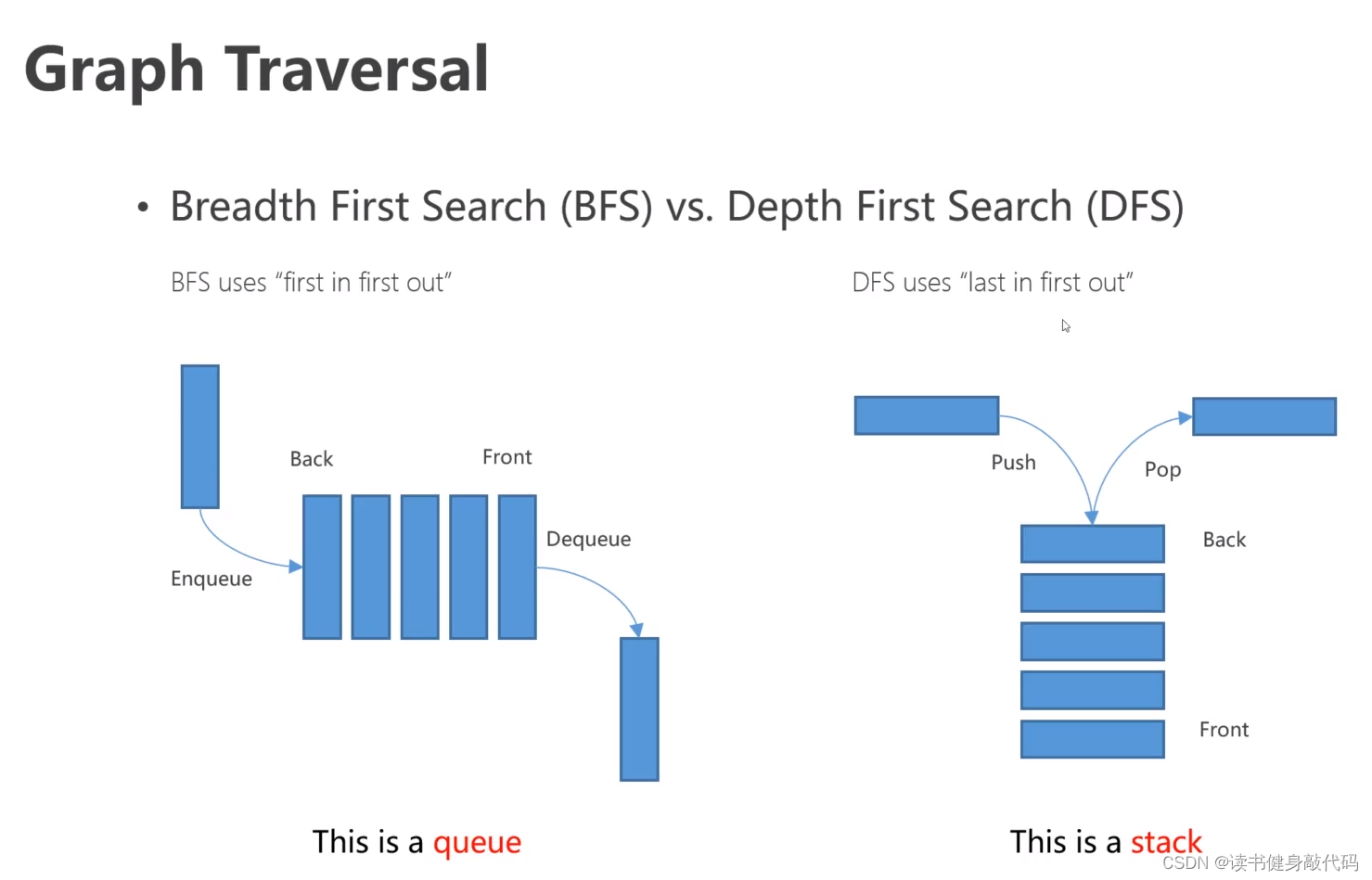
DFS容器是栈,BFS容器是队列。
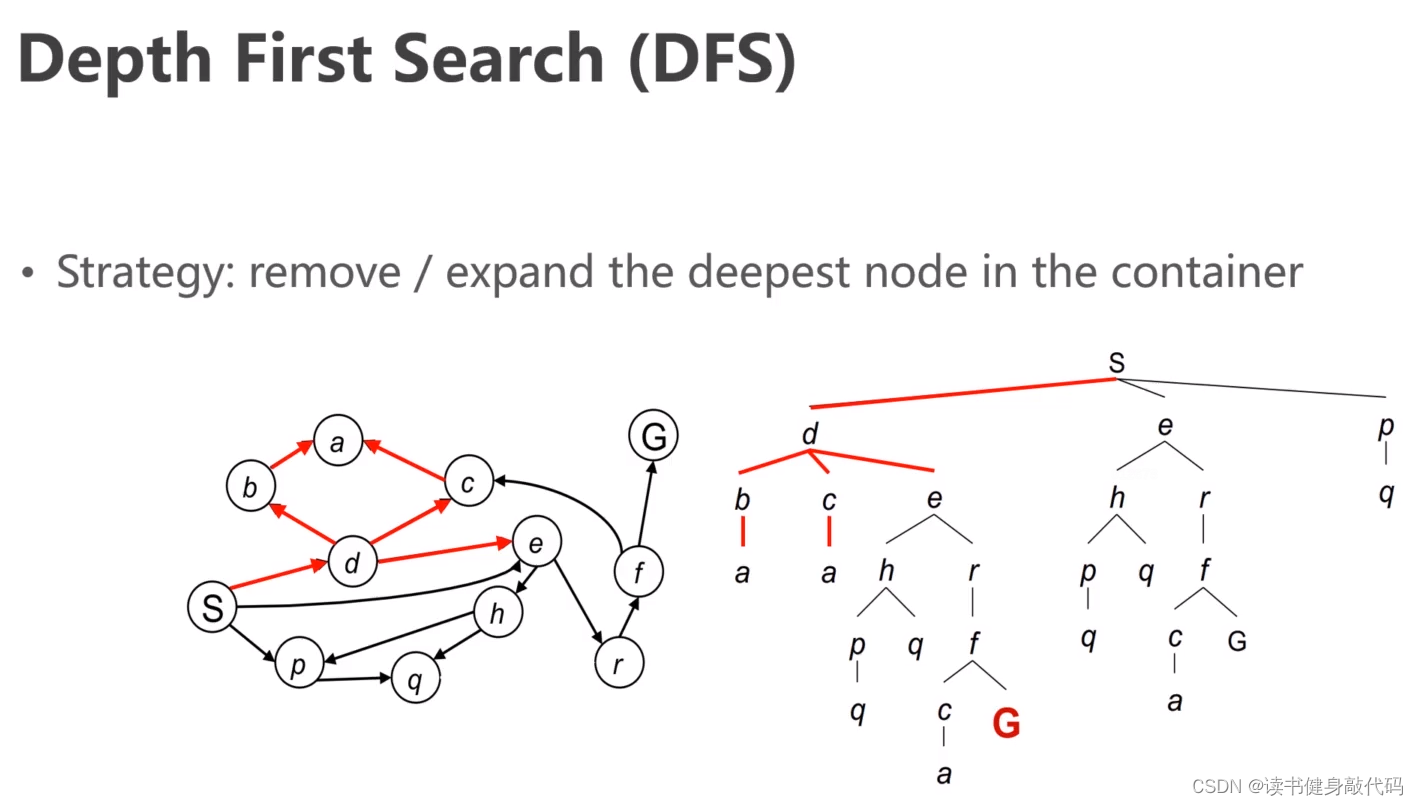
图示中DFS先顺时针,后逆时针,访问最大的,出栈,入栈。
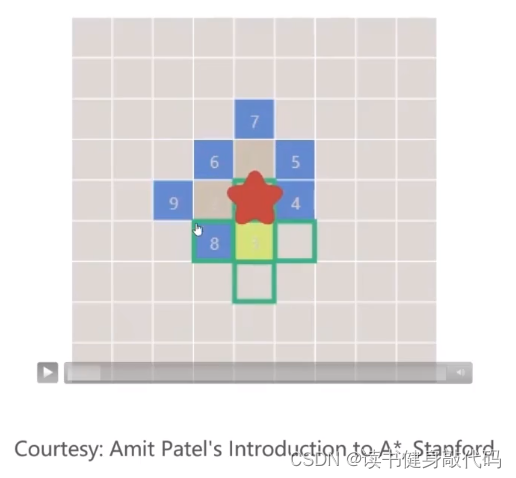
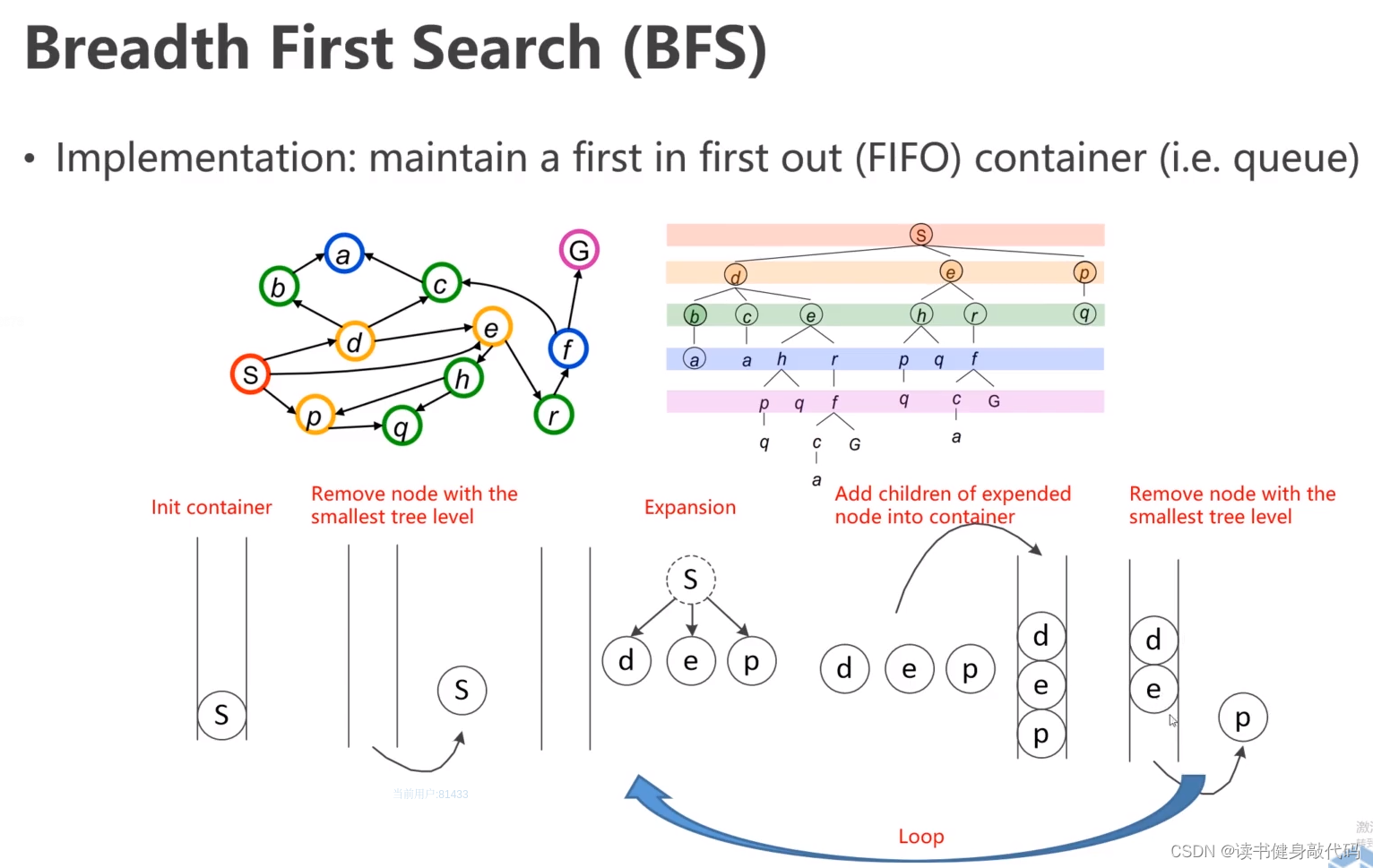
图始终BFS始终逆时针,从小到大依次访问,出队,入队,不断地一层一层地推进frontier。

BFS回溯可以找到最短路径,而DFS不可以,所以常用DFS。(先有一个直观的印象)
贪心算法:
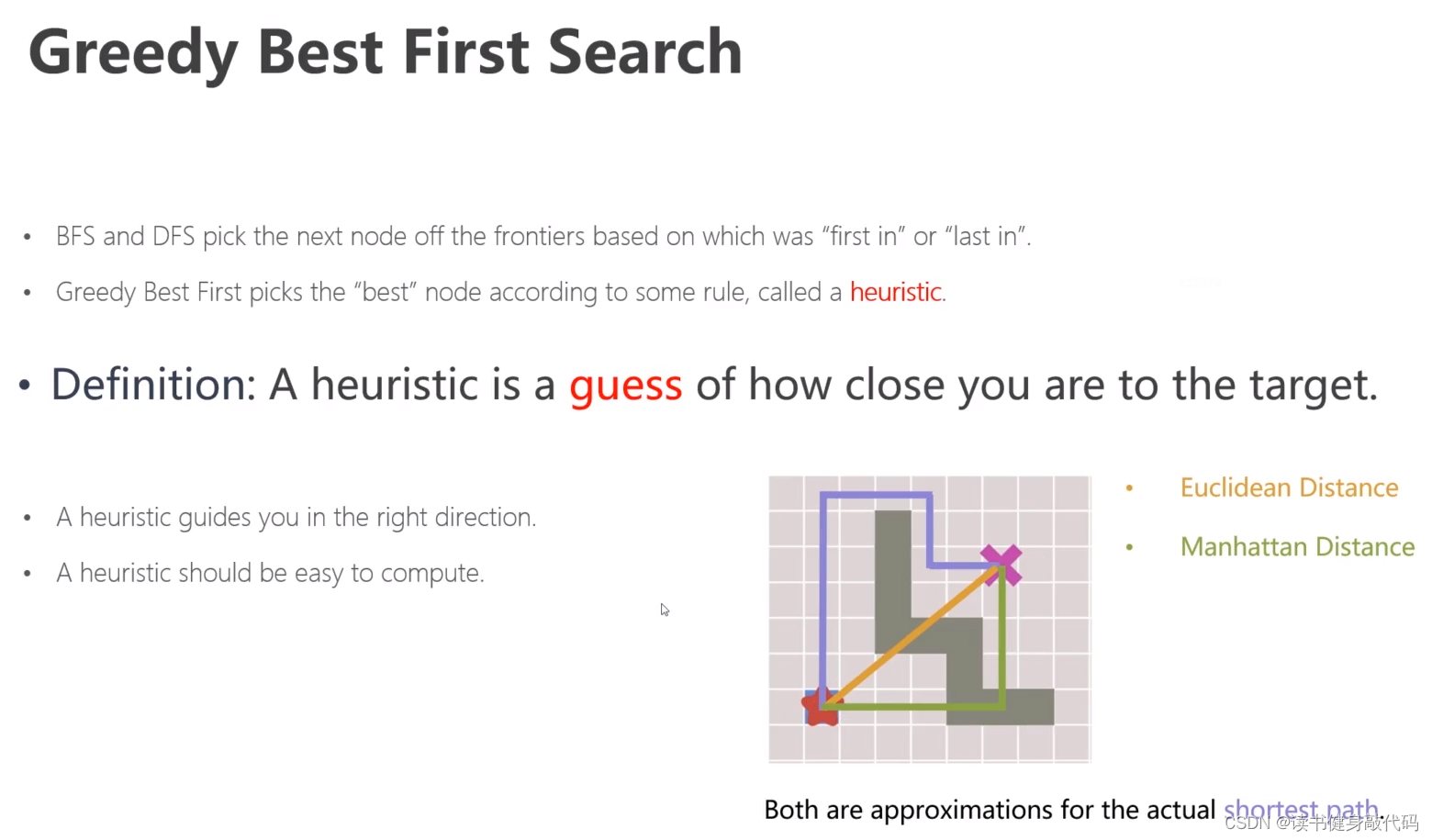
贪心算法依靠某种规则来挑选最优的节点,叫做启发。启发即对于最近节点的一个猜测,比如图中红色到紫色的距离有两种猜测:欧式距离和曼哈顿距离。
-
无障碍物时贪心算法与BFS对比:
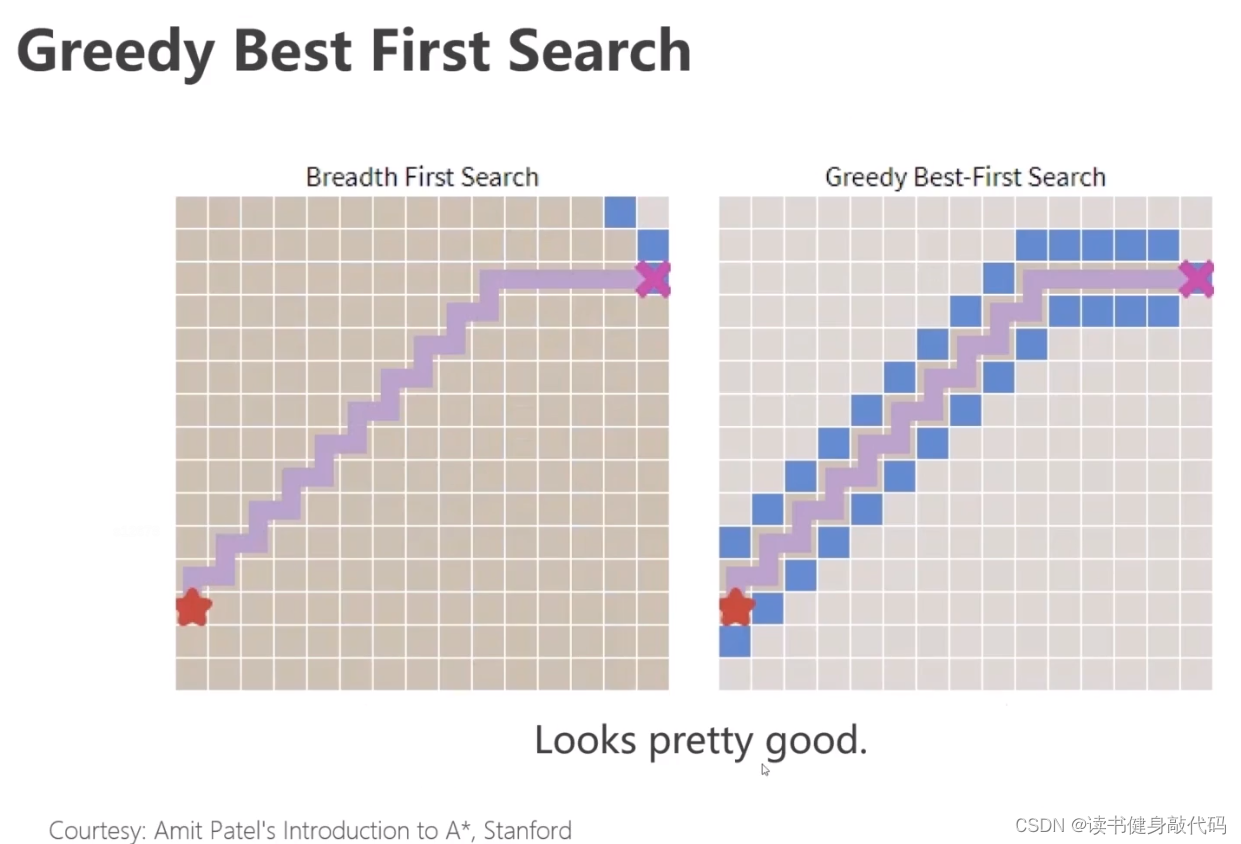
贪心算法又快又准。 -
有障碍物时对比
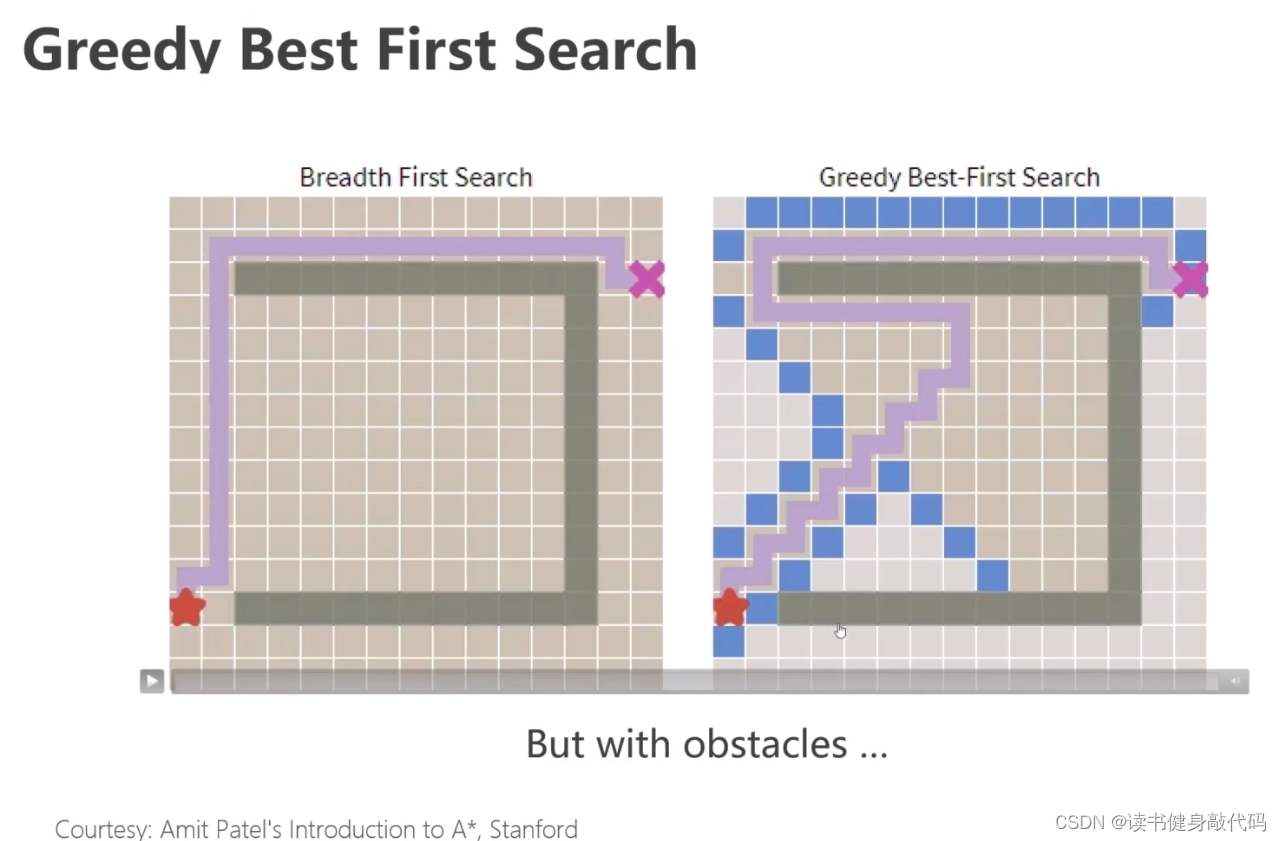
贪心算法虽然快,但是陷入局部最优,而BFS虽然慢,但是路径确实全局最优。
虽然贪心算法有时不是最优,但仍然有很多我们可以借鉴的性质。
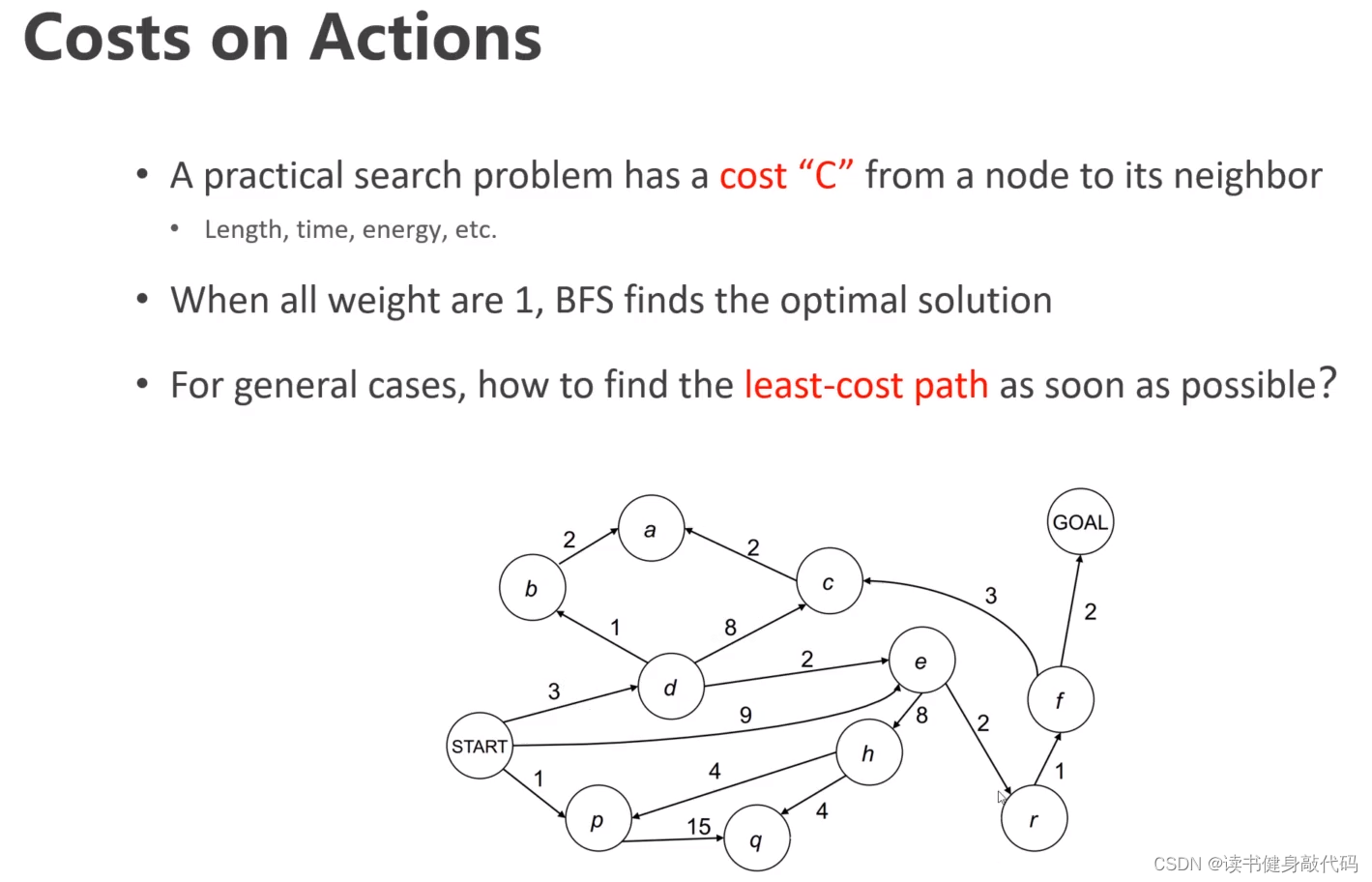
实际中需要考虑每小段路径的cost,即C,当每个C=1时,BFS最优,但通常情况C不为1,于是引入了Dijkstra和A*。
3. Dijkstra
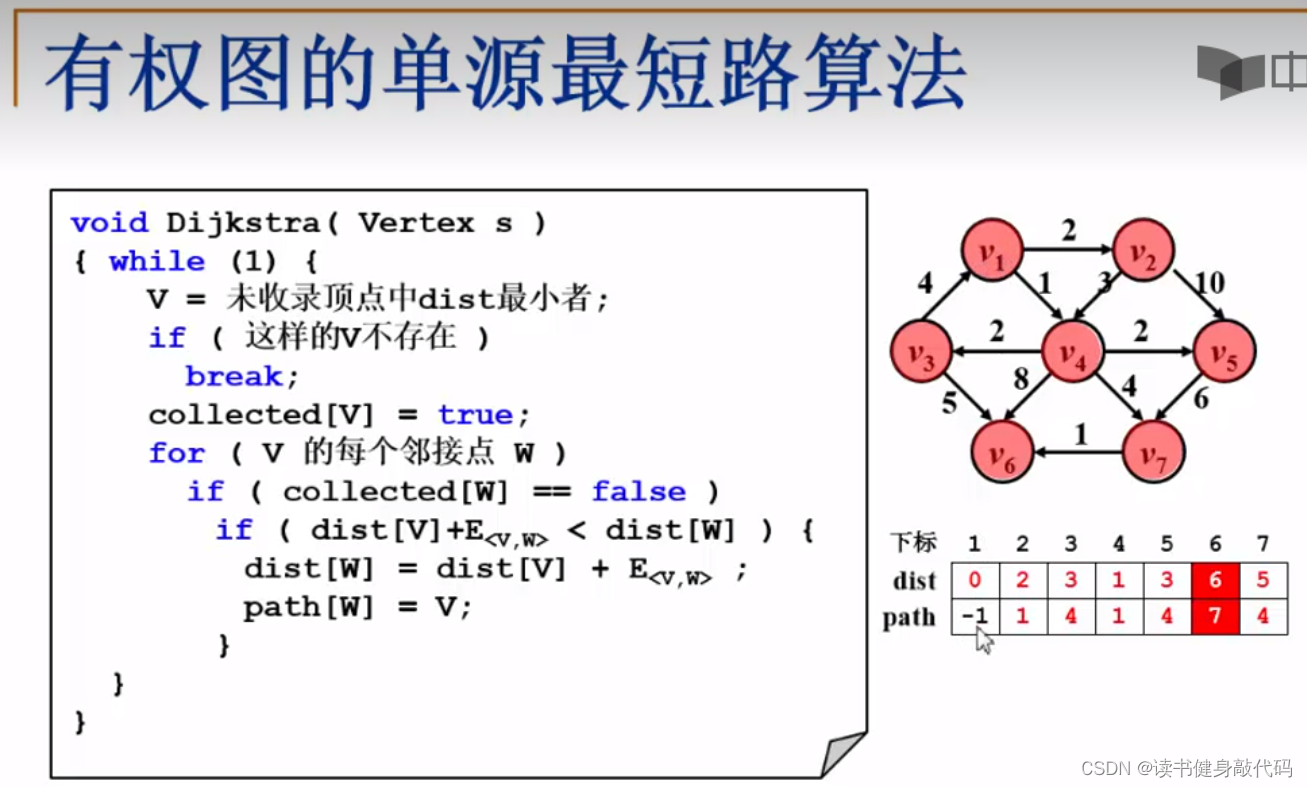
算法流程可以看浙大的这节视频
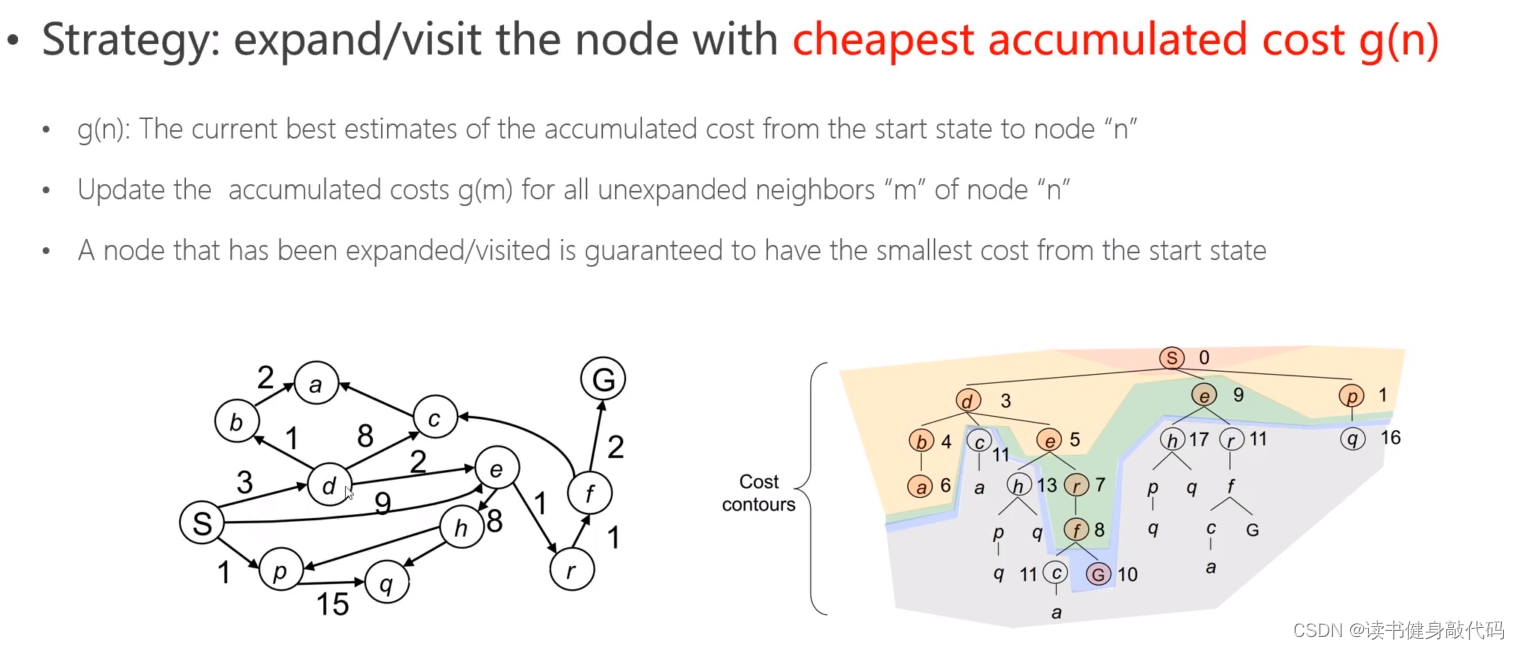
dist最小可以使用priority_queue来实现,按照键值来排序,弹出键值最小的。

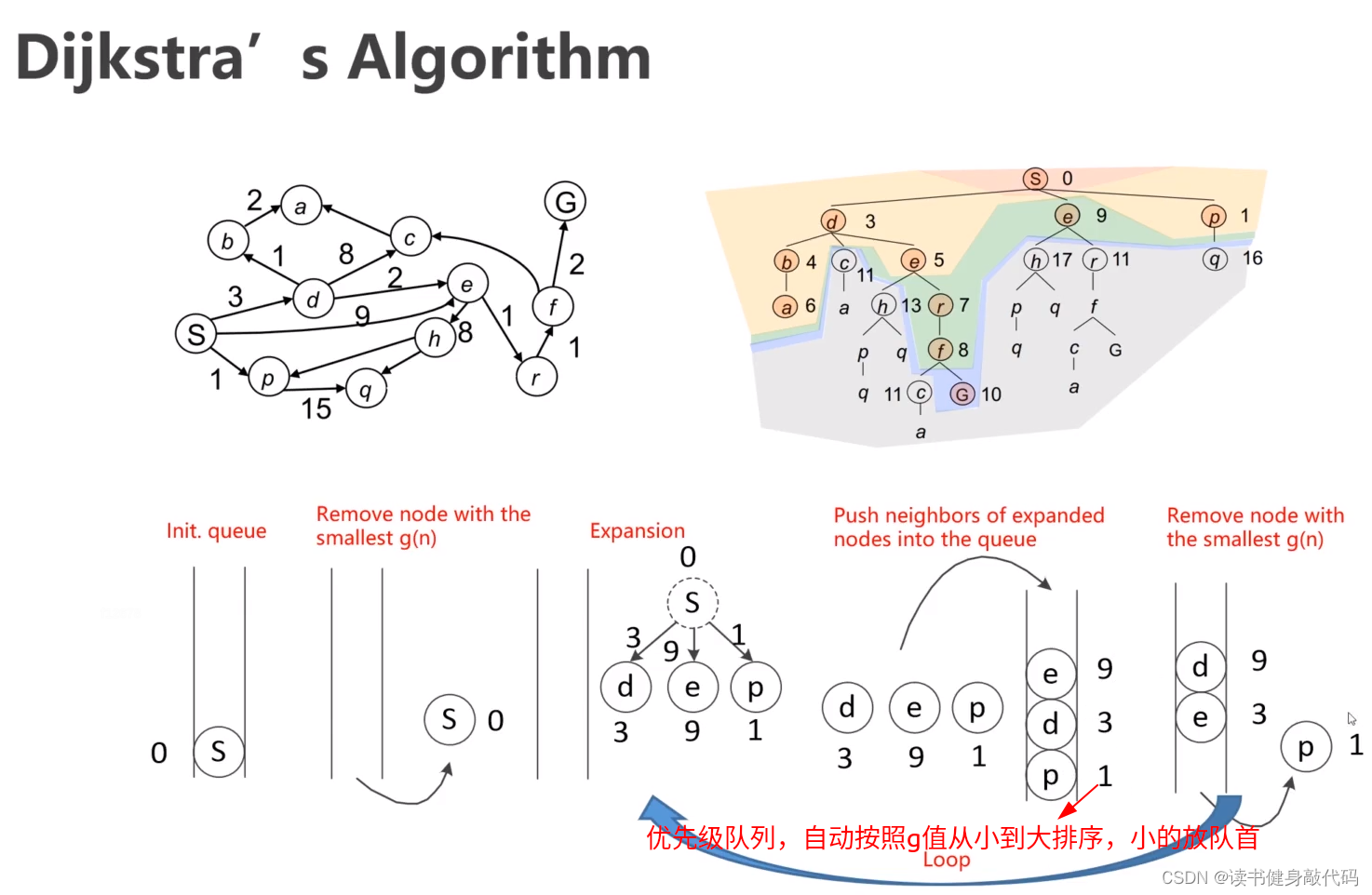
这里的priority queue就是open list,已经扩展过的(已经收录的node)放在close list中(实际上不是方node本身,只需使用容器管理这些node的下标)。
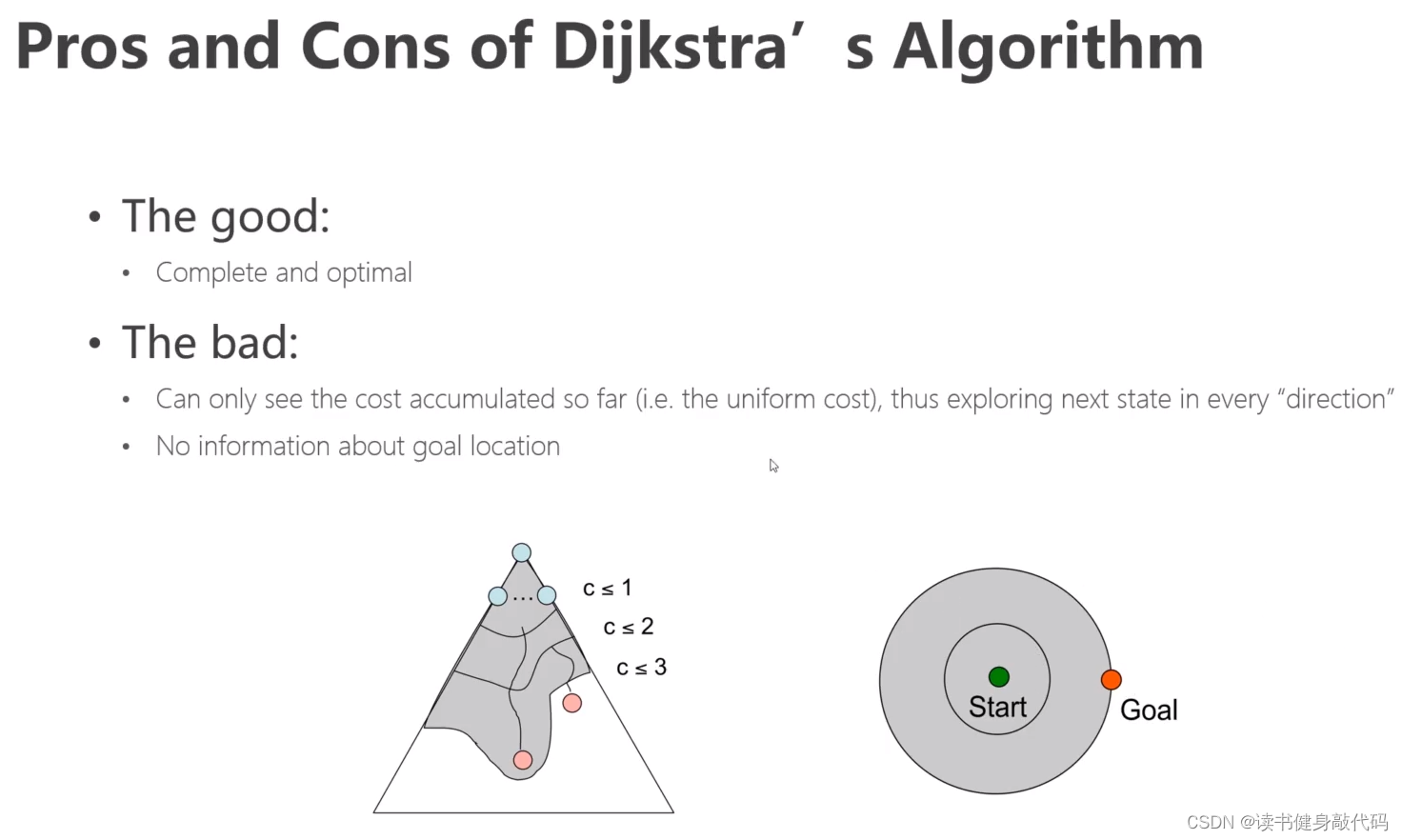
Pros:Dijkstra算法是完备且最优的:完备即一定能找到解;最优即解一定是最优的。
Cons:由于没有goal的任何信息,所以是盲目地,均匀地向各个方向扩散的。
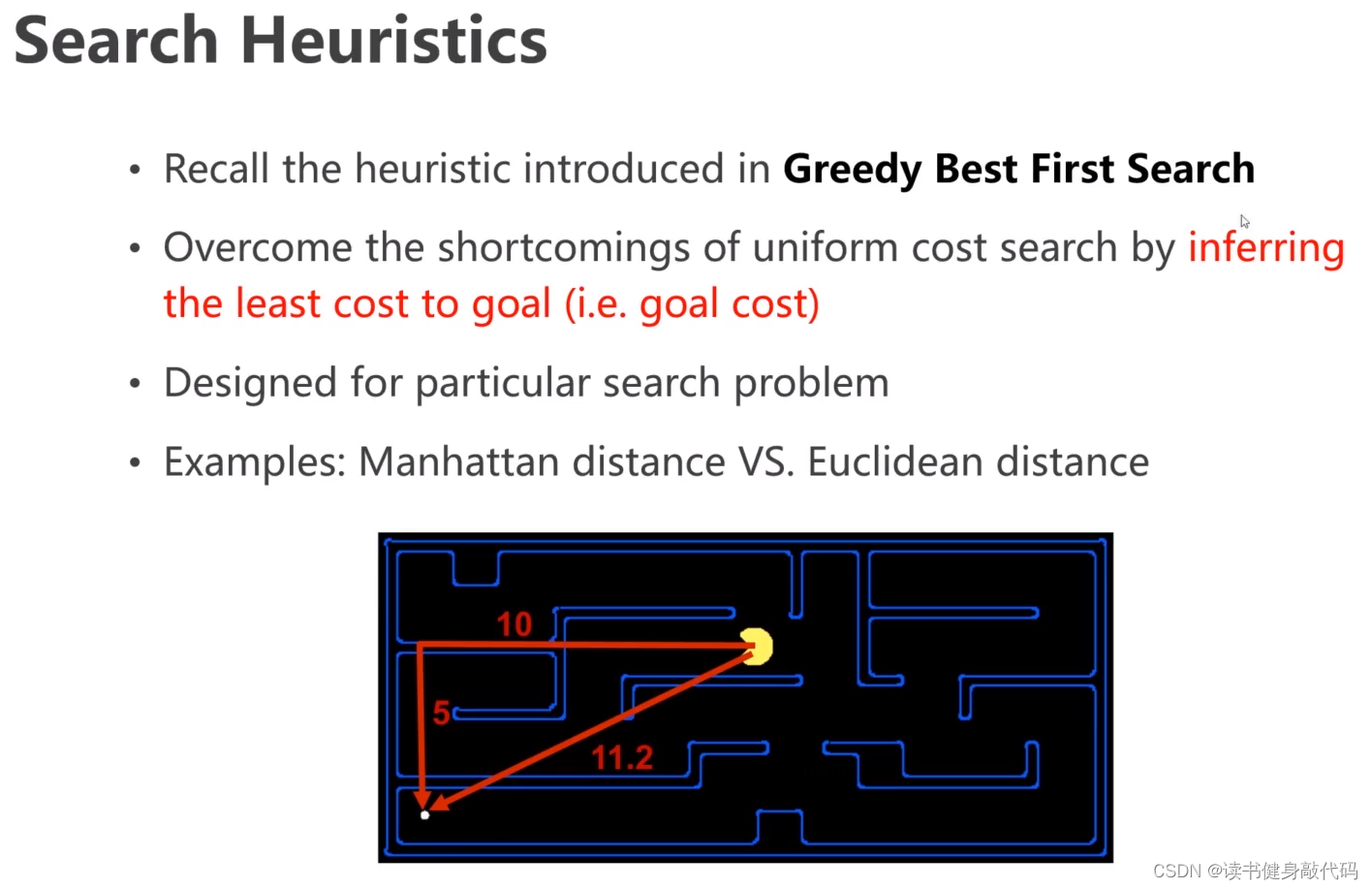
结合贪心算法和info和Dijkstra的单源带权搜索,将二者的优点结合,引出了A*,相较于Dijkstra,在g值的计算方面添加了对goal的估计h,类似于DL中为loss添加正则项。
4. A*
4.1 算法介绍

A*与Dijkstra的唯一不同就是g值的计算,由单纯的 g ( n ) g(n) g(n)变为 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n),其中所有节点的 h ( n ) h(n) h(n)是在初始化阶段one-time计算好的(如所有节点到goal的欧氏距离)。

4.2 A*最优性讨论

上例说明A* 不一定是最优的,
f A = 7 , f G = 5 f_A=7,f_G=5 fA=7,fG=5,A*找到的路径为S->G
而实际cost, g S G = 5 , g S A G = 4 g_{SG}=5,g_{SAG}=4 gSG=5,gSAG=4,显然SAG最优。
A*满足最优的条件:当所有节点的guess的h ≤ \leq ≤ 真实g。
用实际数据来验证:
-
设 h s = 6 , h A = 5 h_s=6,h_A=5 hs=6,hA=5,则
S : f = g + h = 0 + 6 = 6 S: f=g+h=0+6=6 S:f=g+h=0+6=6
A : f = g + h = 1 + 5 = 6 A: f=g+h=1+5=6 A:f=g+h=1+5=6
G : f = g + h = 5 + 0 = 5 G: f=g+h=5+0=5 G:f=g+h=5+0=5
输出S->G,非最优。 -
设 h s = 5 , h A = 4 h_s=5,h_A=4 hs=5,hA=4,则
S : f = g + h = 0 + 5 = 5 S: f=g+h=0+5=5 S:f=g+h=0+5=5
A : f = g + h = 1 + 4 = 5 A: f=g+h=1+4=5 A:f=g+h=1+4=5
G : f = g + h = 5 + 0 = 5 G: f=g+h=5+0=5 G:f=g+h=5+0=5
输出方式涉及到路径对称性问题,在5.3节tie breaker中会详细讨论。 -
设 h s = 5 , h A = 3 h_s=5,h_A=3 hs=5,hA=3,均满足小于等于actual g g g,则
S : f = g + h = 0 + 5 = 5 S: f=g+h=0+5=5 S:f=g+h=0+5=5
A : f = g + h = 1 + 3 = 4 A: f=g+h=1+3=4 A:f=g+h=1+3=4
G : f = g + h = 5 + 0 = 5 G: f=g+h=5+0=5 G:f=g+h=5+0=5
pop A;
pop G;
输出S->A->G,最优。
于是重点就转移到了如何设计heuristic guess函数h

启发式函数需要满足 h ( n ) ≤ h ∗ ( n ) h(n)\leq h^*(n) h(n)≤h∗(n)
我们称这种启发式函数为admissible(可接受的、可容许的)的。
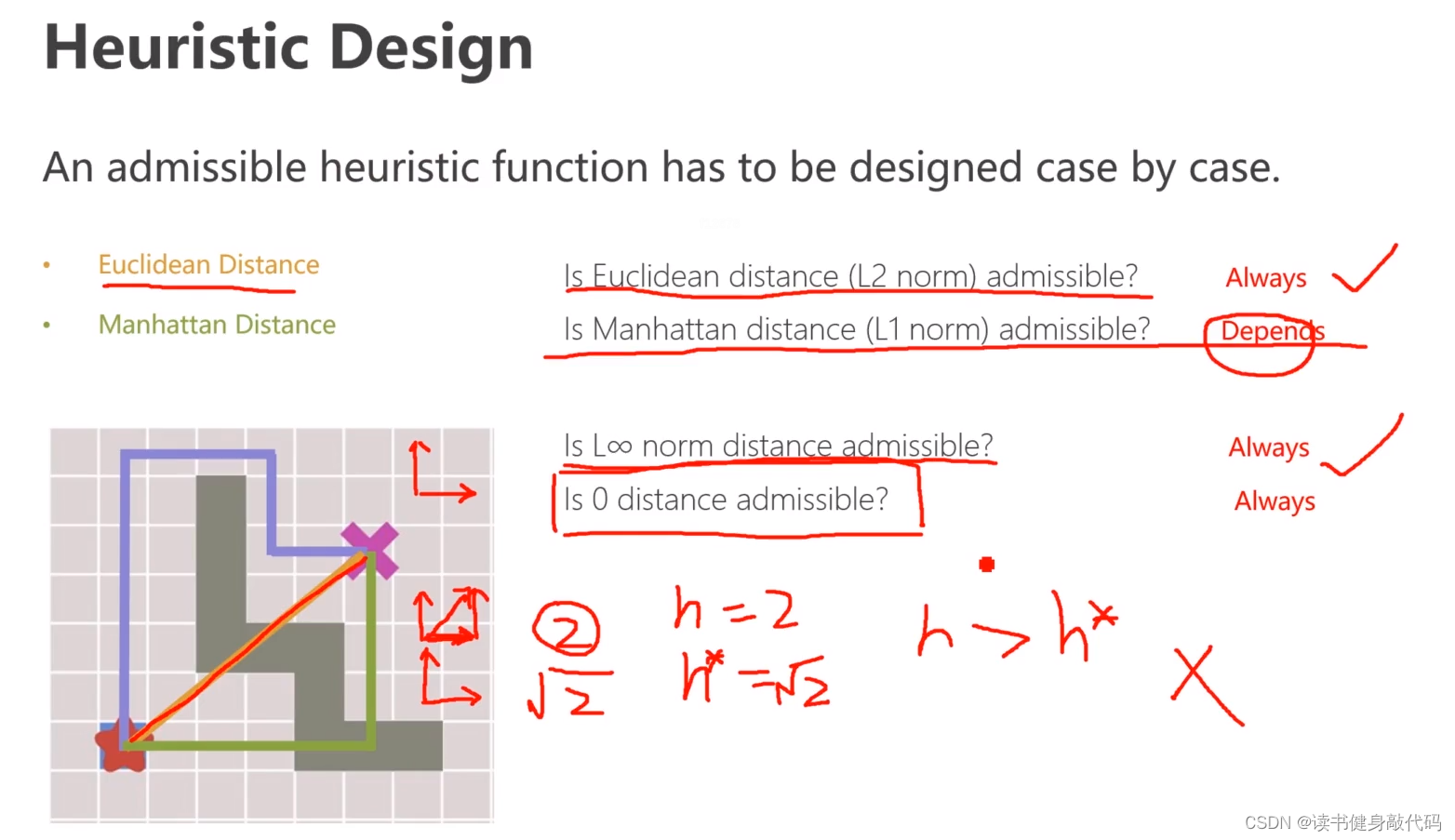
admissible heuristic function的本质为向量的范数,以下为一些admissible heuristic function的列举:
- 欧式距离(向量2范数): ∣ ∣ x ∣ ∣ 2 = ∑ i = 1 n ∣ x i ∣ 2 ||x||_2=\sqrt{\sum\limits_{i=1}^{n} |x_i|^2} ∣∣x∣∣2=i=1∑n∣xi∣2,always admissible
- 曼哈顿距离(向量1范数): ∣ ∣ ∣ x ∣ ∣ 1 = ∑ i = 1 n ∣ x i ∣ |||x||_1=\sum\limits_{i=1}^{n} |x_i| ∣∣∣x∣∣1=i=1∑n∣xi∣,Depends admissible
- 向量的无穷范数: ∣ ∣ x ∣ ∣ ∞ = m a x i ( x i ) ||x||_{\infty}=\mathop{max}\limits_{i} (x_i) ∣∣x∣∣∞=imax(xi),always admissible
- Octile distance: 基于8个方向的直线移动和对角线移动的最短路径进行计算。具体而言,Octile距离考虑了水平、垂直和对角线方向的移动。在直角移动(水平或垂直)时,距离为1;在对角线移动时,距离为根号2(即1.414)。这样设计是为了模拟在规定的移动方向上的最短路径。在路径规划算法(如A*算法)中,Octile距离经常用于启发式估计,以帮助算法找到最优路径。
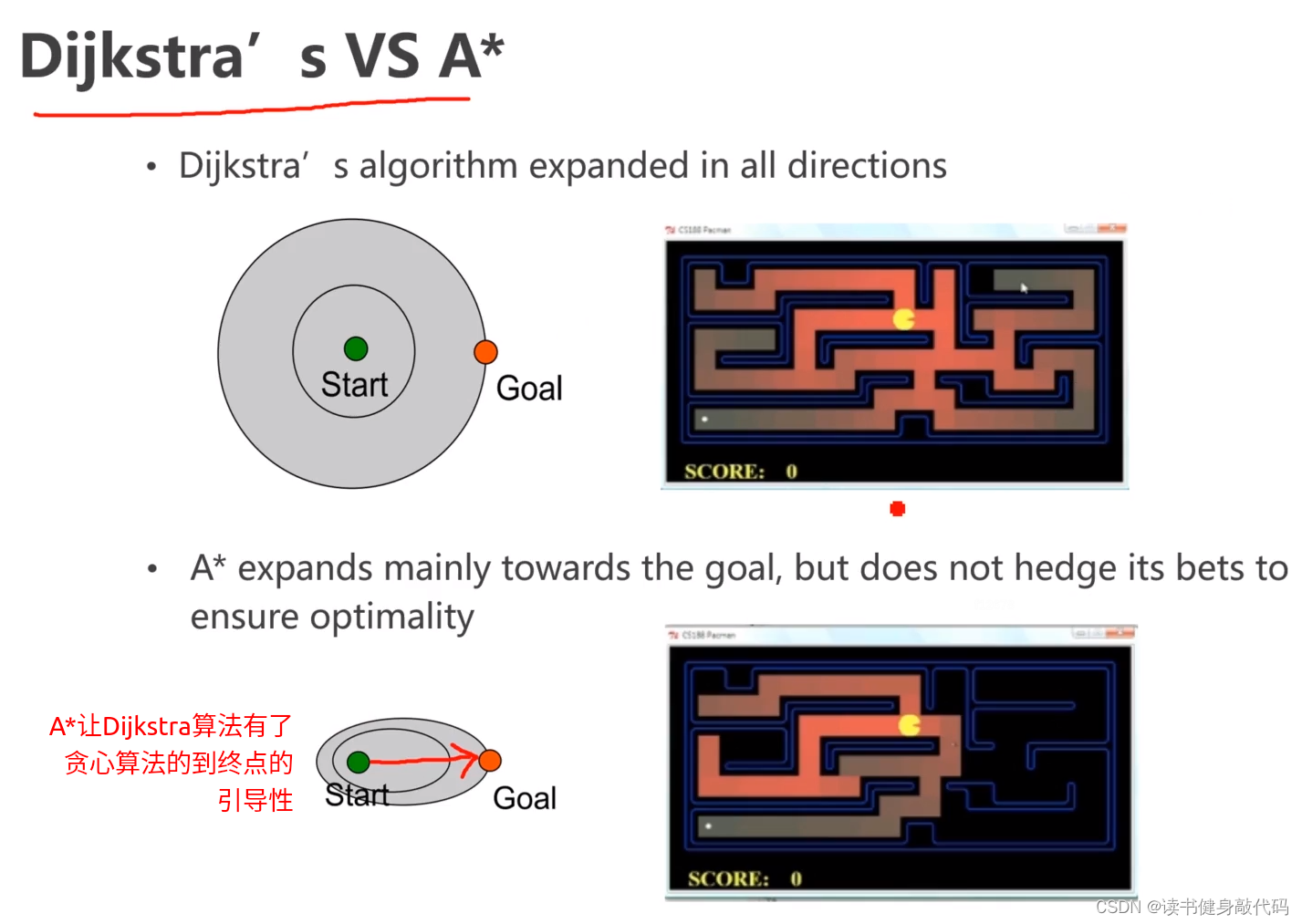
上例说明A*有了贪心算法的对于目标的引导性。
4.3 A*的改进
由 f f f中引入 h h h的结果可知,h的引入也引入了贪心算法的特性:强目的性,faster。如果对h赋予权值则可以改变该引入特性的比重,于是出现了weighted A*,给h增减权重 ϵ ( ϵ > = 0 ) \epsilon(\epsilon>=0) ϵ(ϵ>=0),即 f = g + ϵ h f=g+\epsilon h f=g+ϵh
- 当 ϵ > 1 \epsilon>1 ϵ>1时,贪心占比大,算法强suboptimal,faster; ϵ = + ∞ \epsilon=+\infty ϵ=+∞时,忽略 g g g,算法退化为贪心算法
- 当 ϵ = 1 \epsilon=1 ϵ=1时,为正常A*,solution suboptimal
- 当 0 < ϵ < 1 0<\epsilon<1 0<ϵ<1时,Dijkstra占比大,更接近optimal,slower;极端情况 ϵ = 0 \epsilon=0 ϵ=0退化为Dijkstra算法,solution optimal
weighted A*改进的点:
- ϵ > 1 \epsilon>1 ϵ>1实际上是使用solution的optimality来换取speed,速度提升是A*的数量级等级(几十倍等级别)
- 学界已证明weighted A*的 ϵ \epsilon ϵ-suboptimal,即 c o s t ( s o l u t i o n ) ≤ ϵ ∗ c o s t ( o p t i m a l c o s t ) cost(solution)\leq\epsilon*cost(optimal \ cost) cost(solution)≤ϵ∗cost(optimal cost)
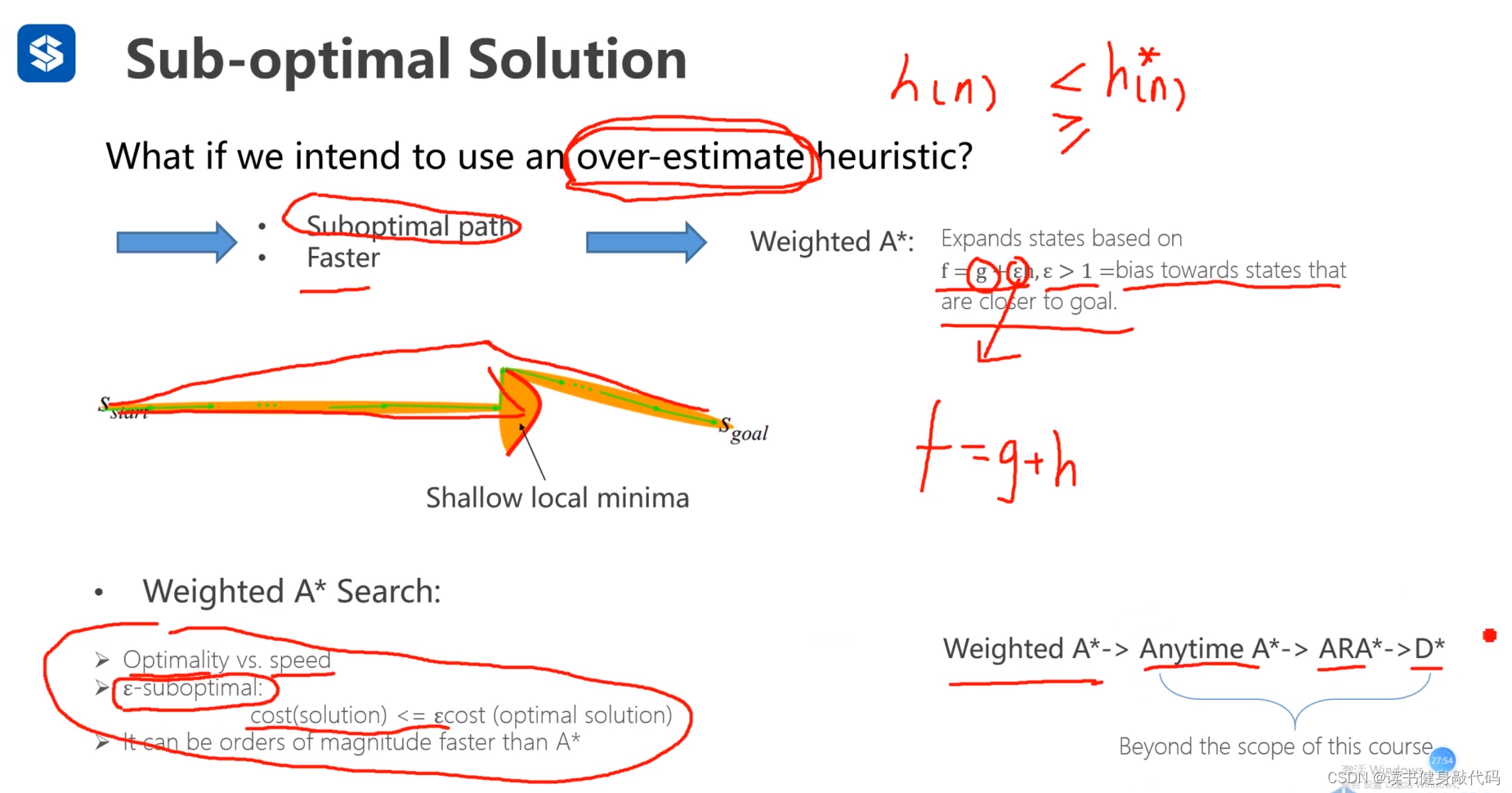
还有weight A的改进Anytime A,ARA*,D*等研究,本课程不做介绍,可自行拓展。
更改权值的对比:

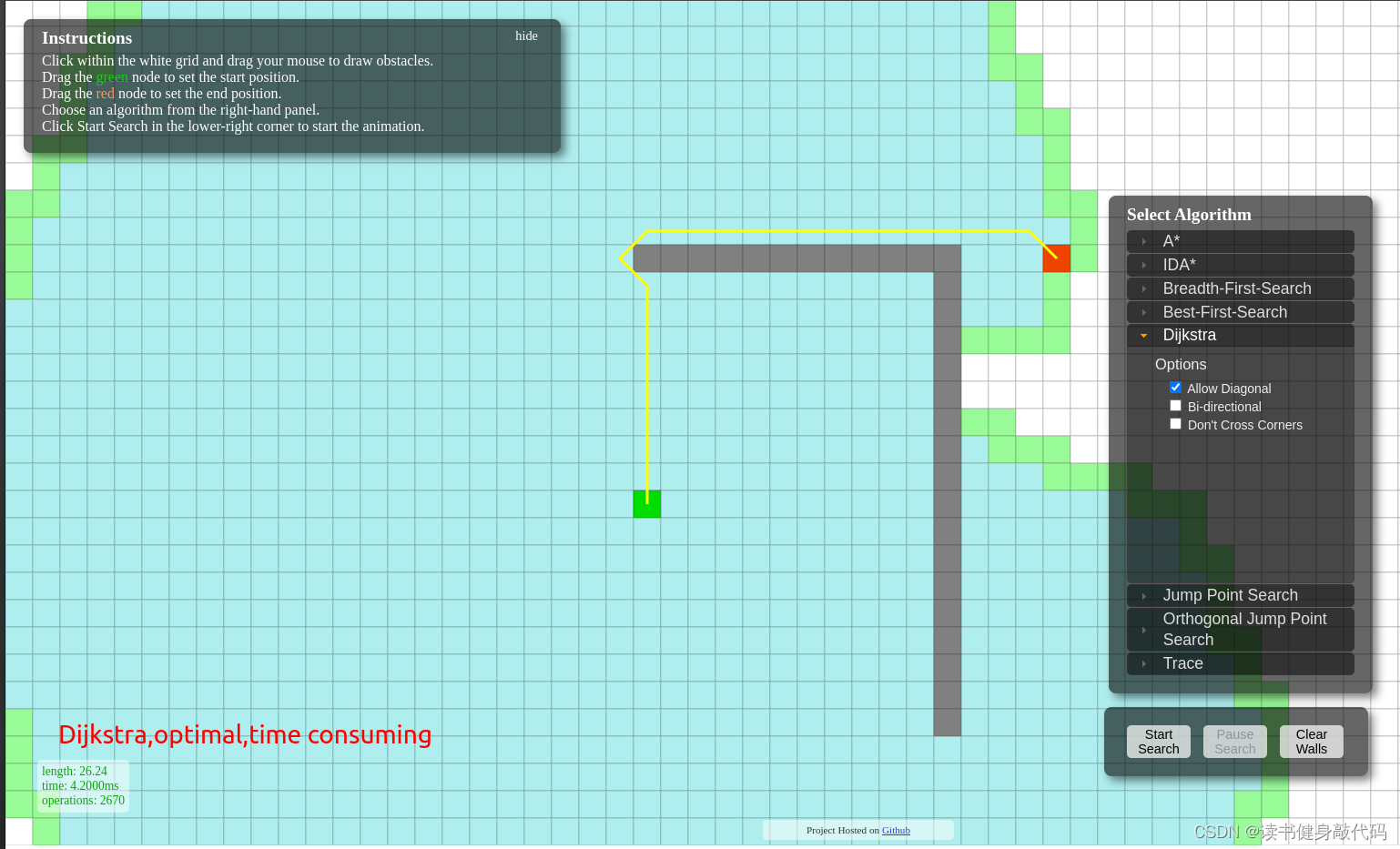
该网页可以调参进行对比: http://qiao.github.io/PathFinding.js/visual/
以下是我的实验结果:
| Algorithm | Length | Time(ms) | Operations |
|---|---|---|---|
| Best-First-Search(a=0,b=1) | 29.56 | 1200 | 340 |
| weightedA*(a=1,b=5) | 27.07 | 17000 | 370 |
| weighted A*(a=1,b=1) | 26.24 | 13000 | 495 |
| Dijkstra(a=1,b=0) | 26.24 | 42000 | 2670 |
可以看出贪心算法operation最少,耗时最短,但solution为suboptimal(path较长),Weight A*(a=1,b=1)和Dijkstra的solution为optimal,但Weight A*(a=1,b=1)明显耗时更少,此实验中耗时提升了2.23倍,大规模问题上提升应该会更大。



5. Engineering considerations
工程实现对于算法性能影响可能有10倍,100倍都不止。
5.1 地图表示
以Occupancy grid map为例:
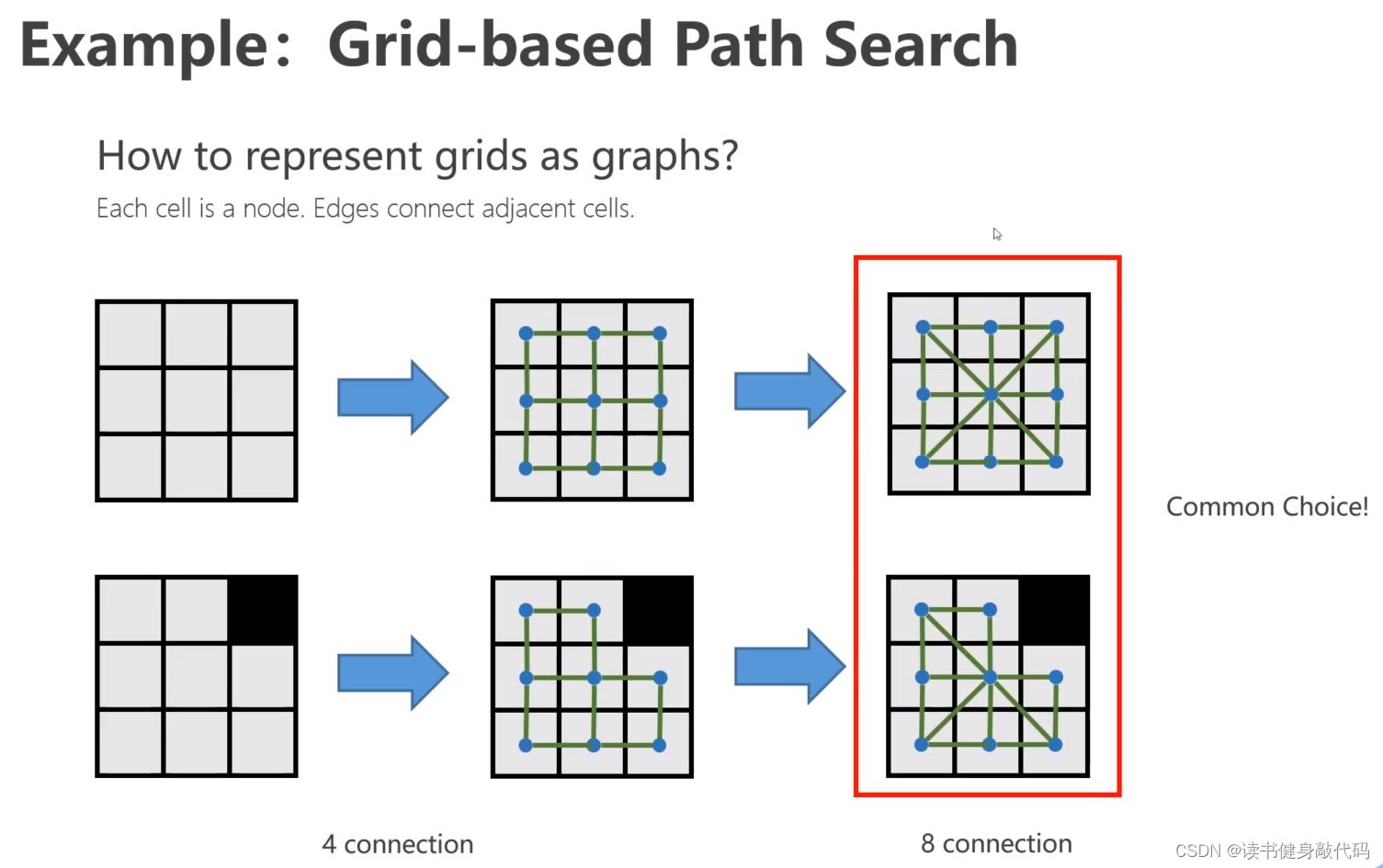
2Dgrid-map的表示,8连通( 2 3 − 1 2^3-1 23−1),3D为26连通( 3 3 − 1 3^3-1 33−1)
数据结构在搜索过程中其实就是在找到该节点的相邻节点时需要用到。
推荐使用stl中的priority_queue和multimap,对vector排序可以使用make_heap方法。(VINS-MONO中用unordered_map较多)。
5.2 the best heuristic
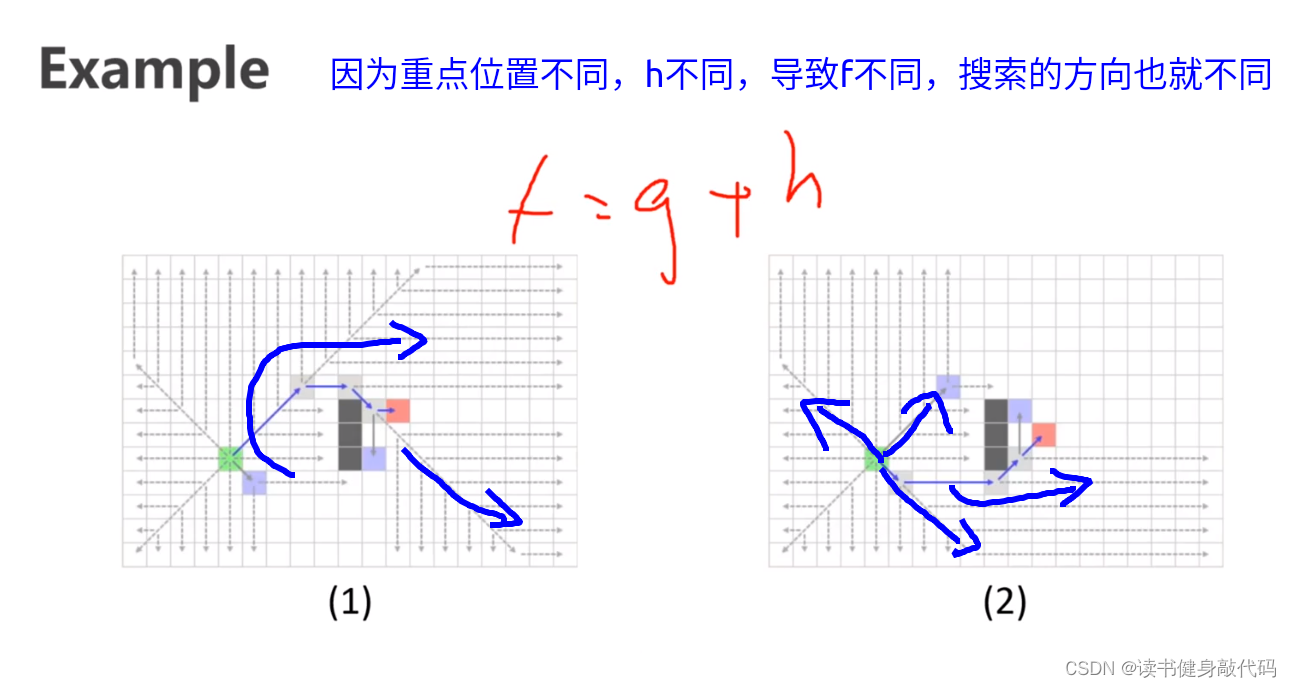
前面降到可以使用Euclidean distance作为heuristic,尽管Euclidean distance满足 h ( n ) ≤ h ∗ ( n ) h(n)\leq h^*(n) h(n)≤h∗(n)即可找到optimal solution,但是在搜索过程中会扩展很多不必要的节点, h ( n ) ≤ h ∗ ( n ) h(n)\leq h^*(n) h(n)≤h∗(n)小于的非常多,即Euclidean distance不够tight

对于结构化的地图和结构化的移动rule,在2D情况下可以推导出任何一个节点到终点的heuristic的estimate,可直接用作我们的heuristic,我们称之为Diagonal Heuristic(对角Heuristic)
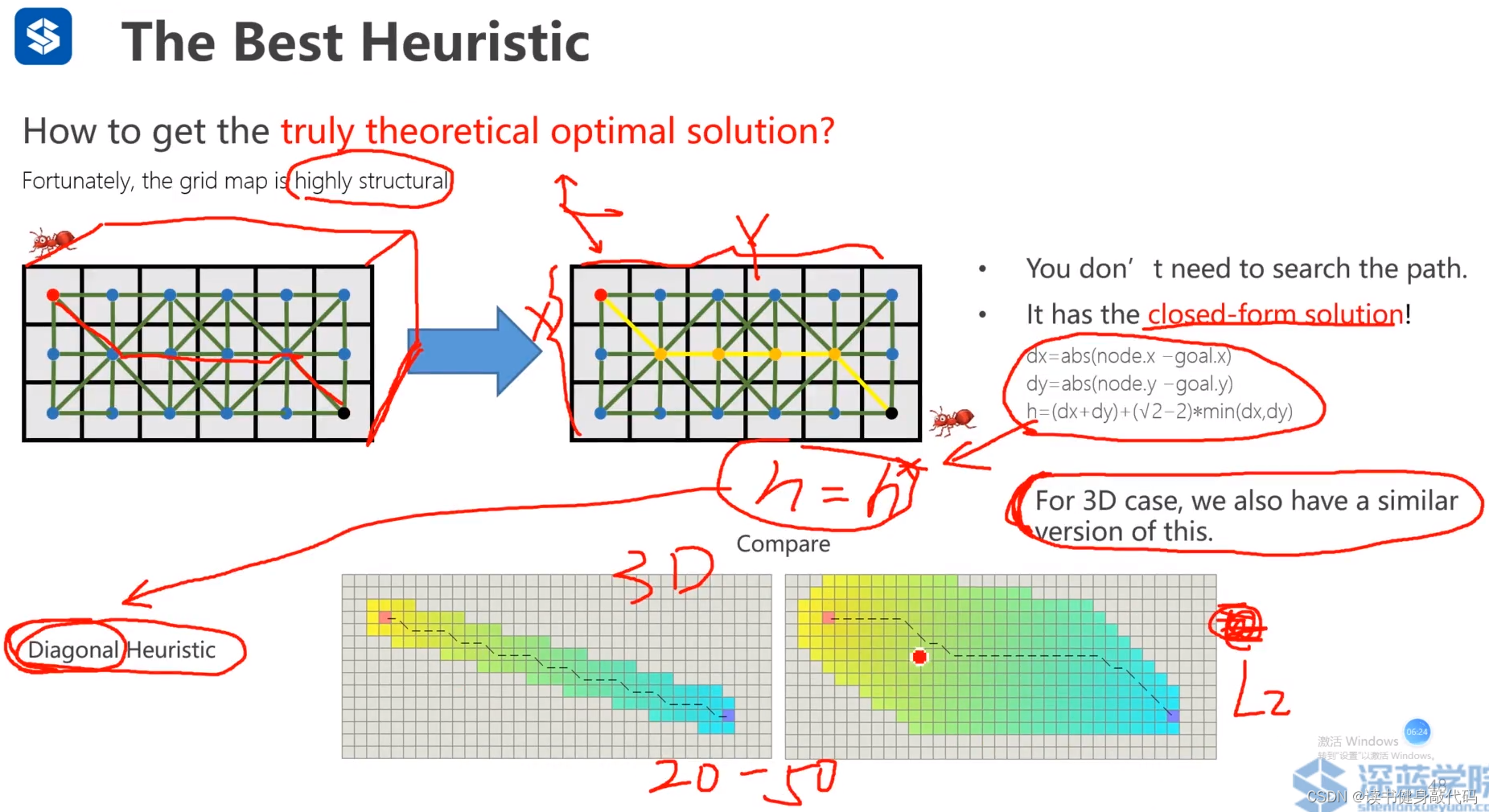
TODO:这个2D Heuristic estimate结果怎么推出来的?
上例中DIagonal Heuristic和L2 Heuristic的solution path的cost(即f)相同,即出现了路径对称性问题,因为在计算f时他们之间没有difference,于是引入了Tie breaker。
5.3 Tie breaker
直观理解是打破等号。
Tie breaker用于打破5.2上述的对称性问题,核心思想是 在cost相同的path中找到preference。
目的是减少不必要的node的拓展,提高搜索效率。
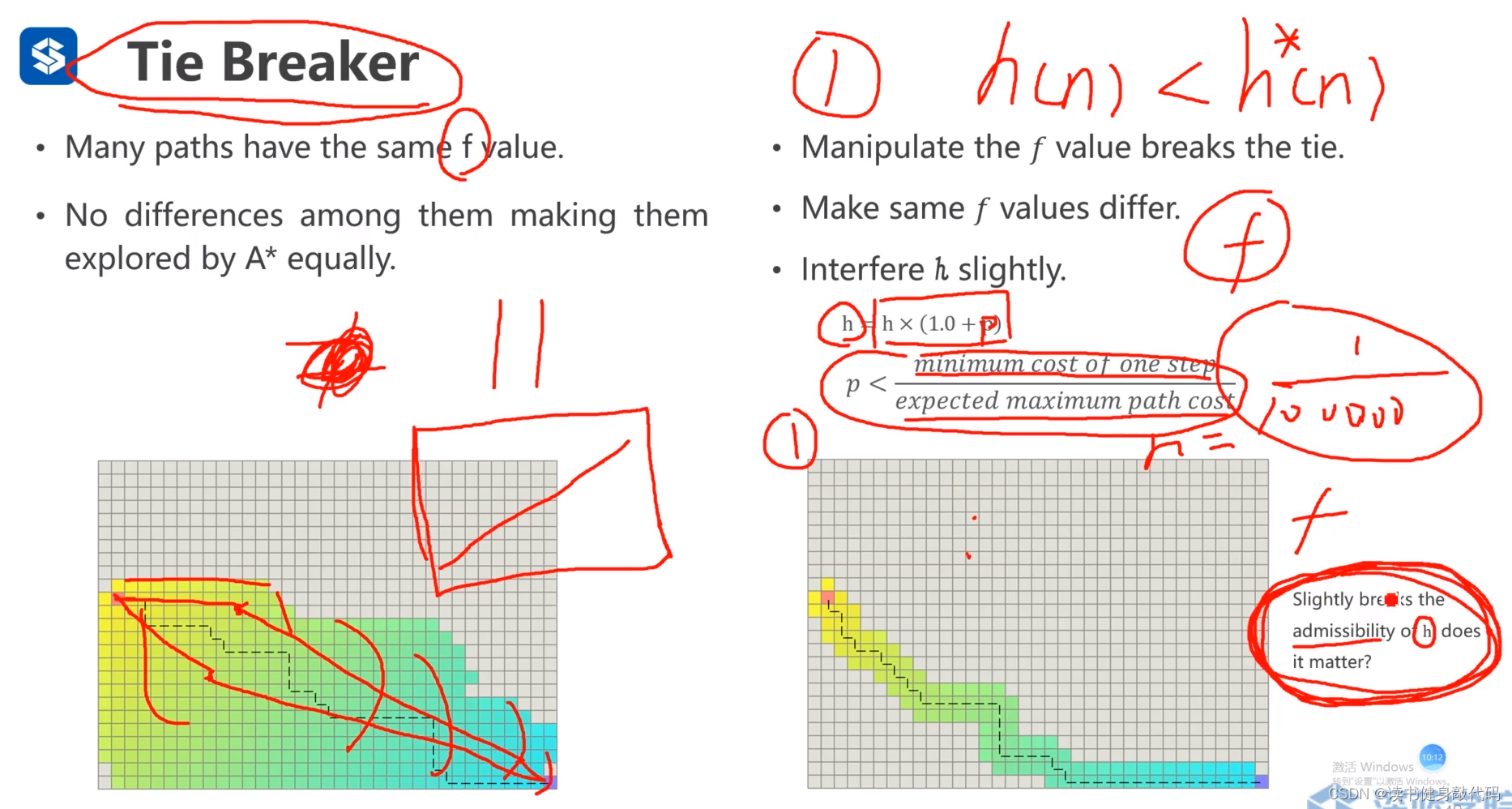
-
方法1:在计算Heuristic时加入一个系数 p = 一步的最小 c o s t 可能的 p a t h 的最大 c o s t ( 比如矩形地图的斜对角线 c o s t ) p=\frac{一步的最小cost}{可能的path的最大cost(比如矩形地图的斜对角线cost)} p=可能的path的最大cost(比如矩形地图的斜对角线cost)一步的最小cost(这里还不是很理解为什么加入一个 p p p就能使f不同,需要结合代码具体理解。)
这样会轻微打破admissible条件,因为h有小幅的增大,admissible heuristic取等号时是在没有任何障碍物情况下,而实际工程中由于存在较多obstacle,计算出来的h通常不会达到tight heuristic。 -
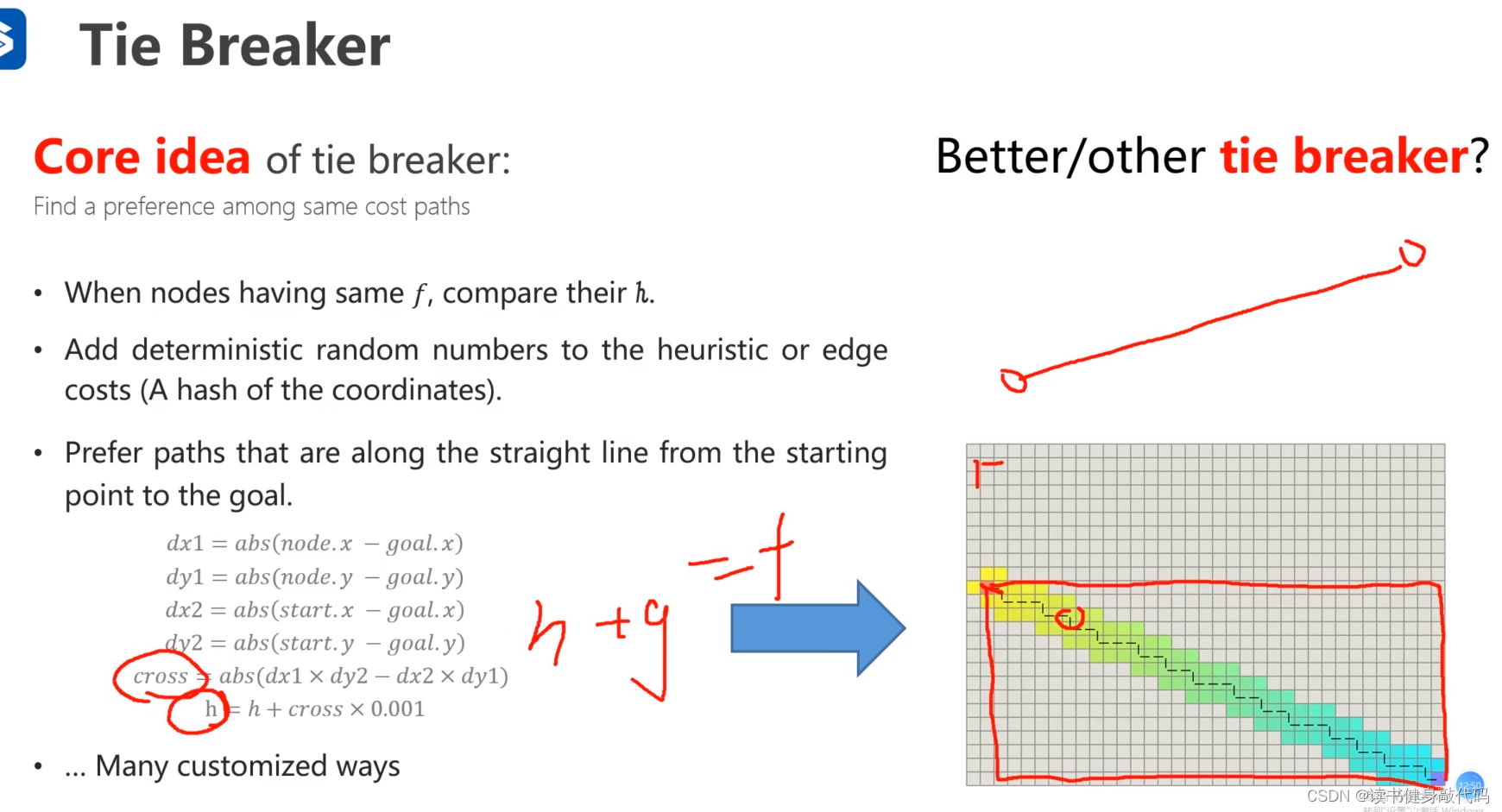
方法2:定义rule:当f相同时,取h更小的。
-
方法3:在f或者g上加一个deterministic random numbers(提前确定好的随机数,确定之后不能变,使用hash映射),工程实现可能较复杂,但效果会比前面的好。
-
方法4:倾向于走直线,同样是slightly change heuristic,给heuristic加上一个corss,让其更倾向走符合直观感受的对角线path。
还有很多其他方法,可以看论文。
但是Tie breaker也会带来一些负面影响,我们最终给到robotic的是一条可执行的轨迹trajectory,trajectory是由我们的规划出的path来生成的,会涉及到traj光滑的处理,如下图,当我们使用Tie breaker在有obsacle的情况下生成了一条path,理想的trajectory是如图所示的红色光滑曲线,使用tie breaker生成了虚线所示的path,在trajectory generation过程中就比较难得到红色光滑traj,反而是矩形的path更易得到光滑traj,所以使用什么tie breaker是有讲究的,针对这种情况,引入了本章的第3块内容:JPS。
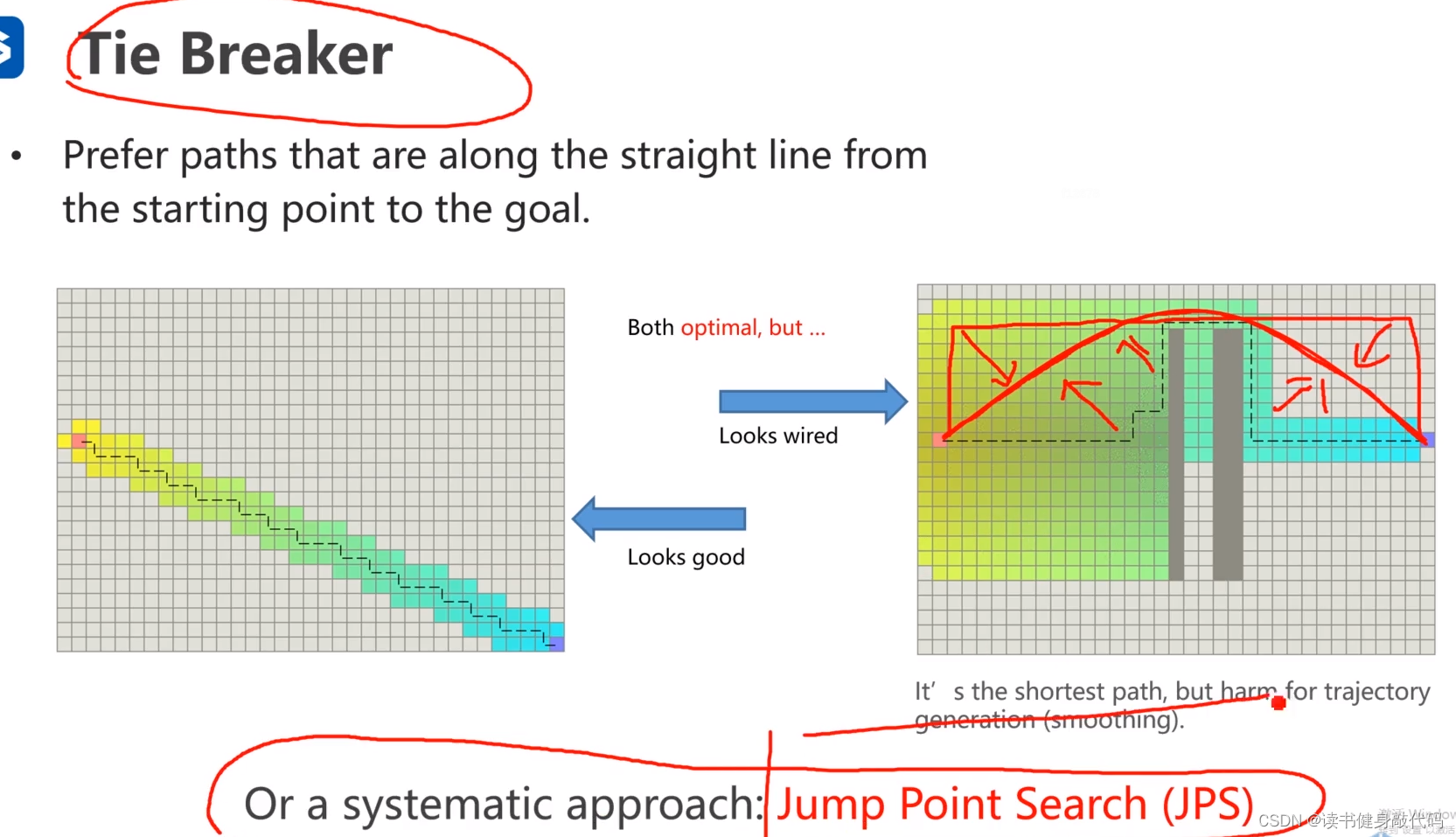
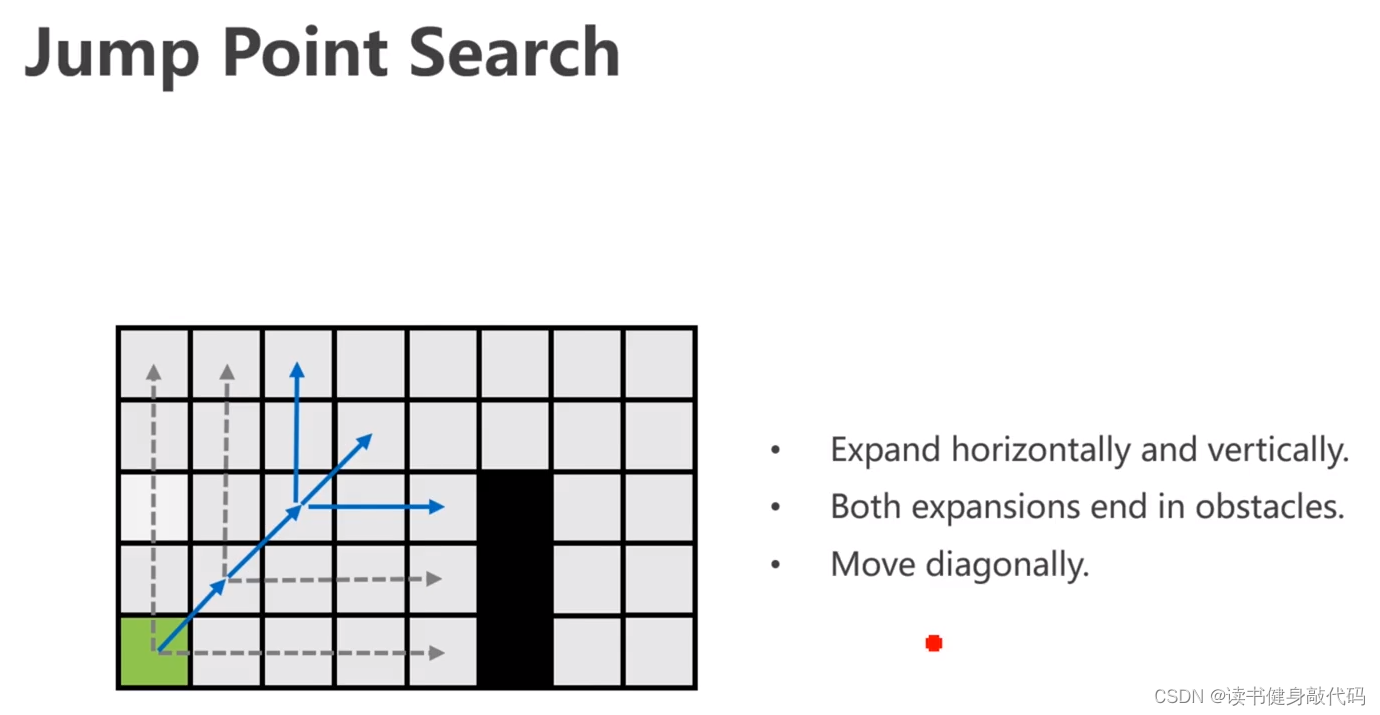
6. JPS(Jump Point Search)
JPS是一种系统性的打破路径平衡性的图搜索方法,其core idea是找到对称性并打破它。
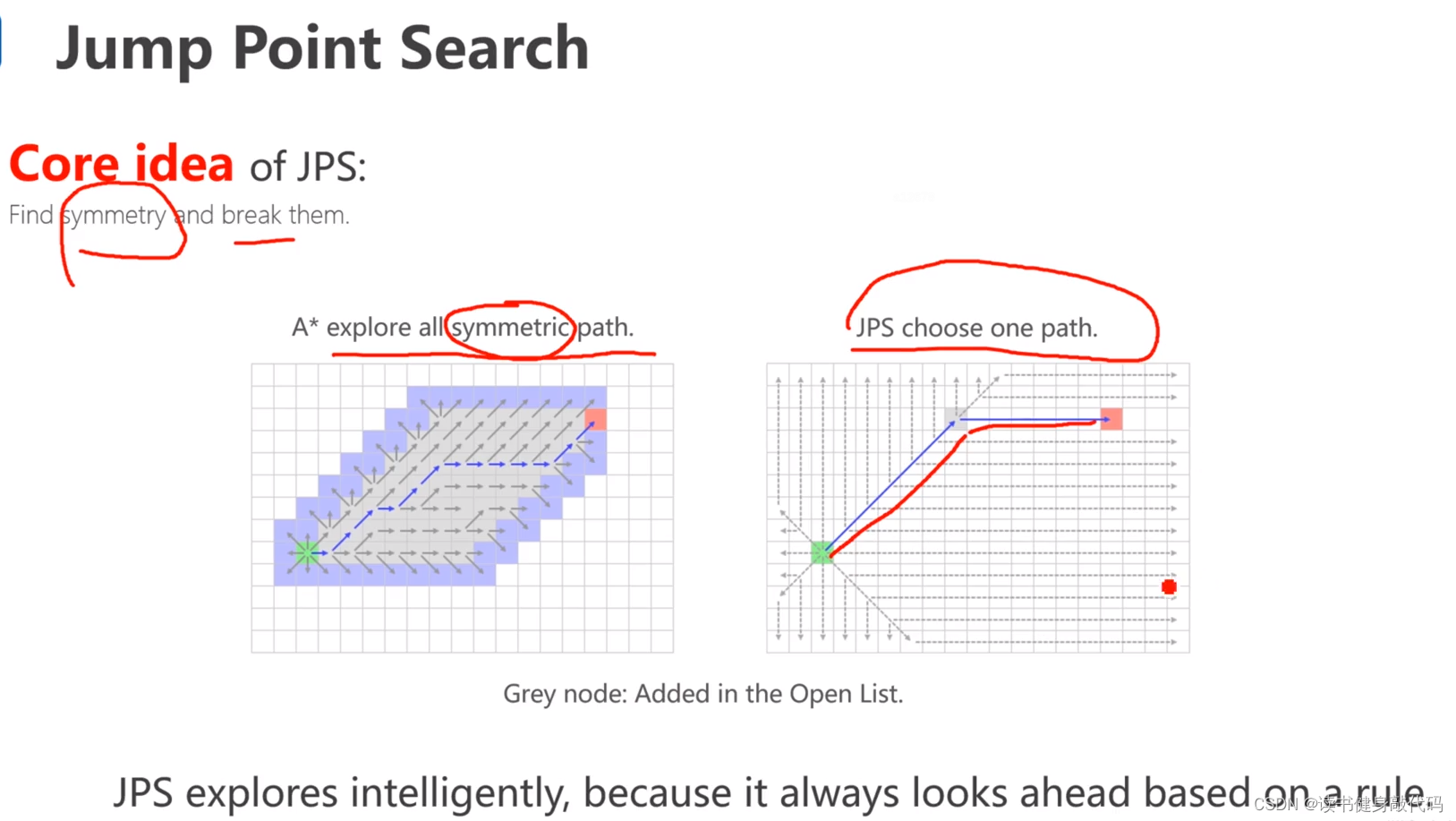
6.1 look ahead rule(pruning rule)
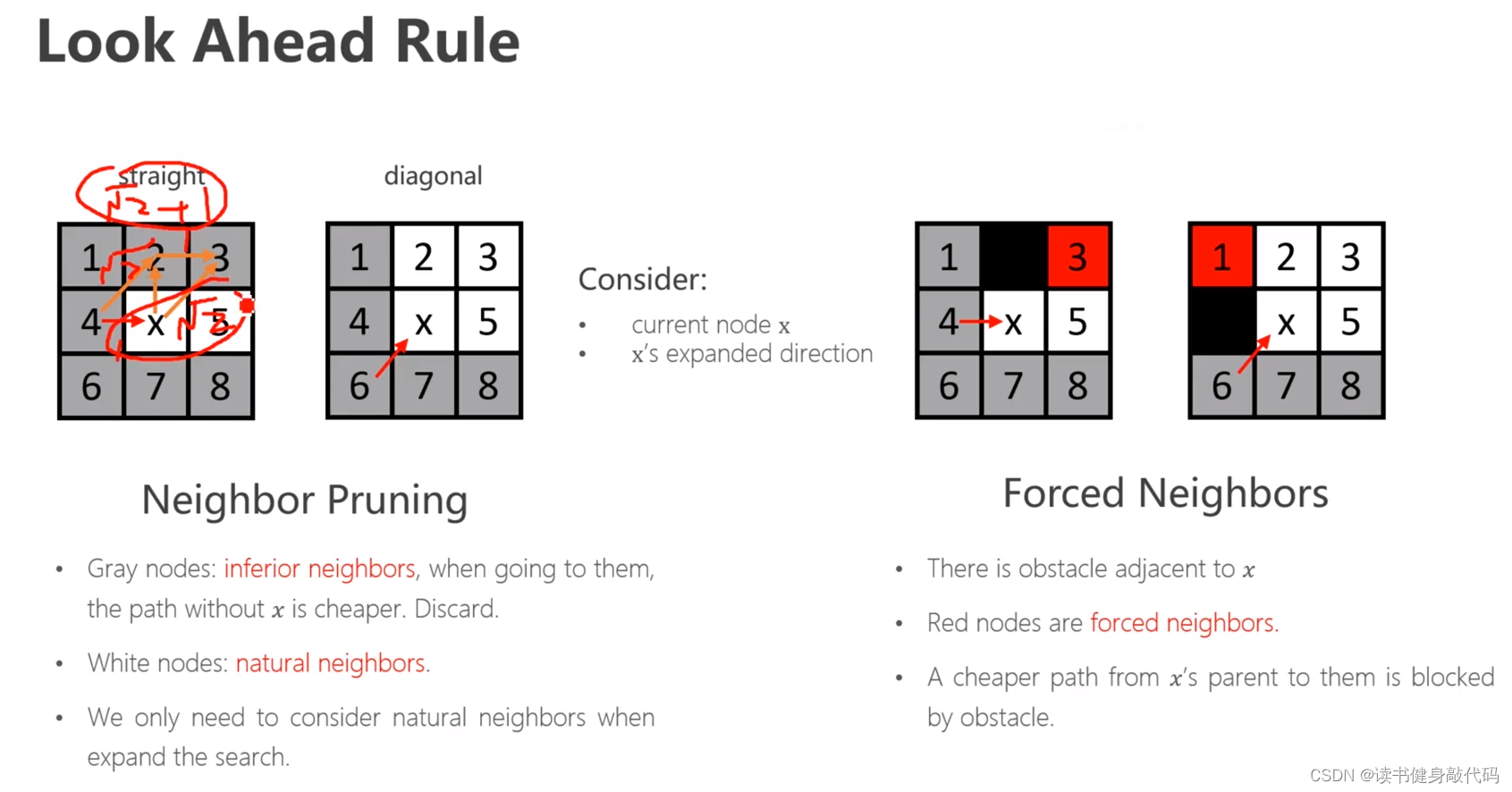
Look ahead rule,以例子来介绍这样一个规则:
- 对于无障碍物,straight到达儿子节点的情况:
从某点(4)到达另一点(1),不需要经过儿子节点(x)时的path cost为 f A f_A fA,经过儿子节点的path cost为 f B f_B fB,则
- 当 f B < f A f_{B}<f_{A} fB<fA时,才考虑从儿子节点到达该节点,称该点为natural neighbors;
- 当 f B ≥ f A f_{B}\geq f_{A} fB≥fA,不考虑从x到达该节点(即neighbor pruning,discard),称该节点为inferior neighbors(劣性节点)。
按照上述定义, ( f B = f 4 → x → 1 = 1 + 2 ) > ( f A = f 4 → 1 = 1 ) (f_{B}=f_{4\to x \to 1}=1+\sqrt{2}) > (f_A = f_{4\to1}=1) (fB=f4→x→1=1+2)>(fA=f4→1=1)
所以扩展儿子节点 x x x时不考虑节点1;
从4走到3是否需要经过x:
( f B = f 4 → x → 3 = 1 + 2 ) = ( f A = f 4 → 2 → 3 = 2 + 1 ) (f_{B}=f_{4\to x \to 3}=1+\sqrt{2}) = (f_A = f_{4\to2\to3}=\sqrt{2}+1) (fB=f4→x→3=1+2)=(fA=f4→2→3=2+1)相等,所以不考虑节点3;
同理1,2,3,6,7,8均不需要考虑,只需要考虑5。
- 对于无障碍物,diagonal对角线到达儿子节点的情况,rule稍微有些改动:
- 当 f B < = f A f_{B}<=f_{A} fB<=fA时,consider
- 当 f B > f A f_{B}>f_{A} fB>fA时,discard
eg1:到达1
( f A = f 6 → 4 → 1 = 2 ) < ( f B = f 6 → x → 1 = 2 2 ) (f_A=f_{6\to4\to1}=2)<(f_B=f_{6\to x \to 1}=2\sqrt{2}) (fA=f6→4→1=2)<(fB=f6→x→1=22)故discard 1
eg2:到达2
( f A = f 6 → 4 → 2 = 2 + 1 ) = ( f B = f 6 → x → 2 = 2 + 1 ) (f_A=f_{6\to4\to2}=\sqrt{2}+1)=(f_B=f_{6\to x \to 2}=\sqrt{2}+1) (fA=f6→4→2=2+1)=(fB=f6→x→2=2+1)
相等,diagonal相等时需要consider,详细参考论文
http://users.cecs.anu.edu.au/~dharabor/data/papers/harabor-grastien-aaai11.pdf Equation 1/2
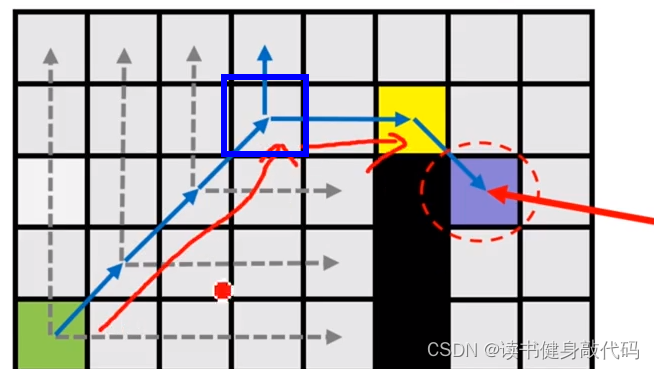
- 有障碍物,straight时,3号节点必须被考虑,称为forced neighbors
- 有障碍物,diagonal时,1号节点必须被考虑。
以上有/无障碍物的straight和diagonal情况可以涵盖所有情况,向上下左右,向左上,左下,右上,右下均类似。
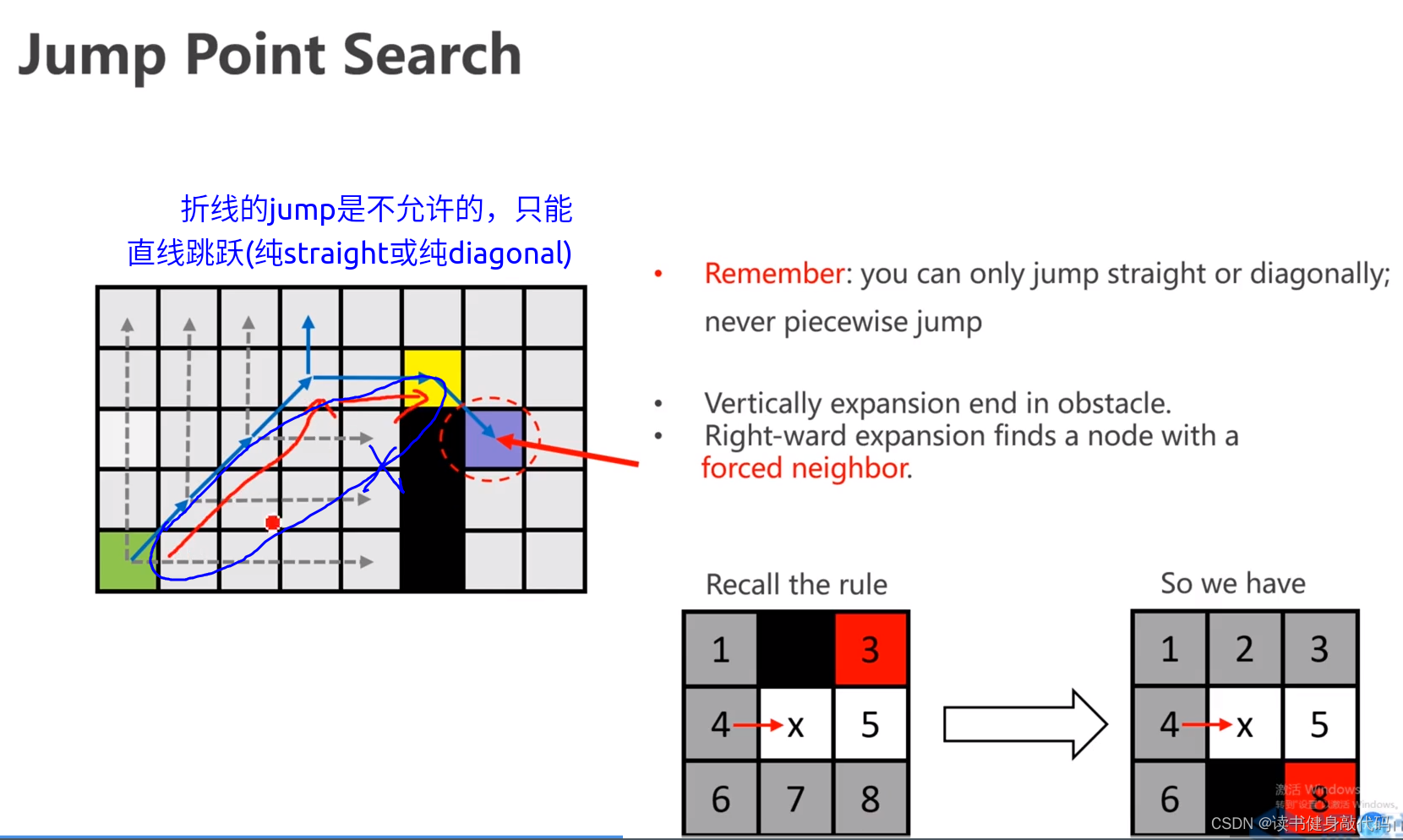
6.2 Jumping rule
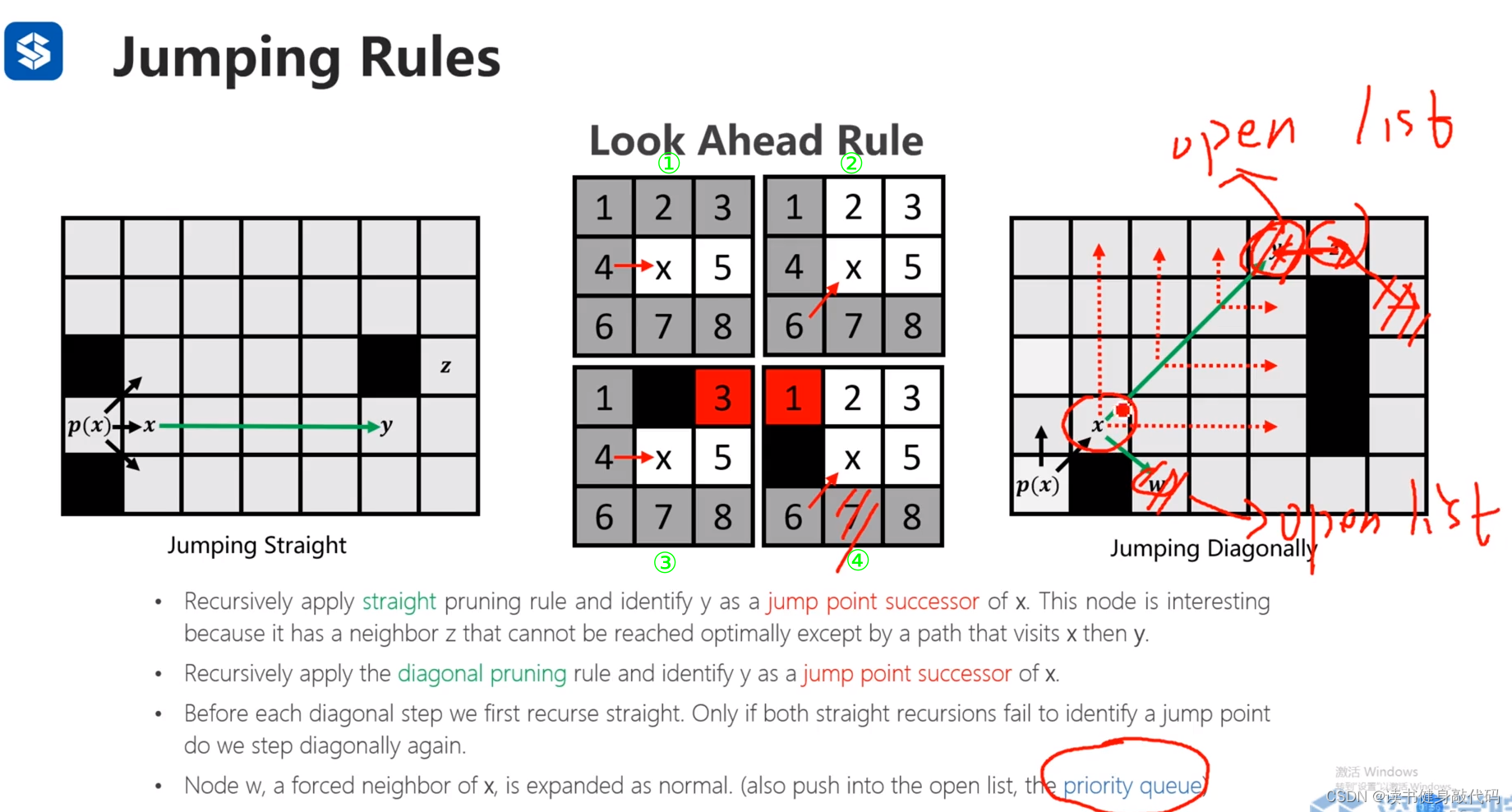
为方便说明,将look ahead rule标记为①~④,jumping的原则是先递归straight jump再递归diagonal jump,发现force neighbor则会递归直线recall最上面一个node(不允许折线recall)
例子1:
从 p ( x ) p(x) p(x)出发进行JPS扩展:
- 起始点使用④,绿框部分需要被consider,w为force beighbor
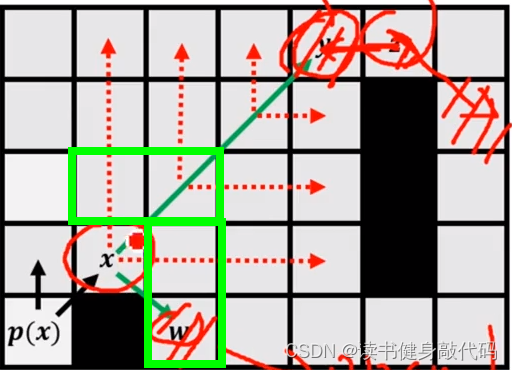
- 在x处向上,向右运用①最终都碰到障碍物(边界也算障碍物),jump失败
- 直到递归diagonal jump到y时,对y向右递归straight jump到z触发了③,绿框+蓝框是consider,蓝框为force neighbor,故z为特殊节点,jump成功,递归返回到最上层发现z的节点,即y,将y加入到open list
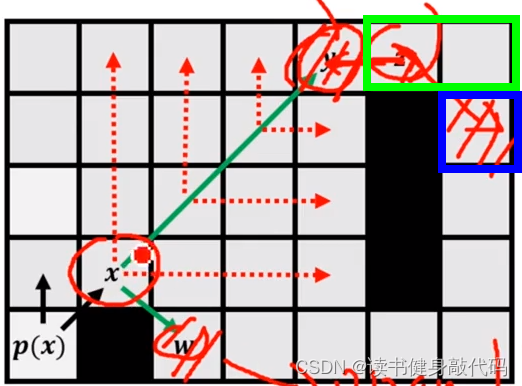
- 递归返回到x,结合第1步的图,x节点的上、右递归straight jump,以及右上递归diagonal结束,该右下的force neighbor的递归diagonal jump,w天然是x的force neighbor,所以将w加入到open list中。
至此,完成了对x节点的所有JPS扩展,将x节点加入到close list中。
例子2:
水平,竖直jump,无事发生,对角线跳一步
向右jump时发现了特殊,于是直线recall(不允许折线recall),将蓝框的点加入到open list,绿色的起点即可加入close list,退出历史舞台。
例子3:
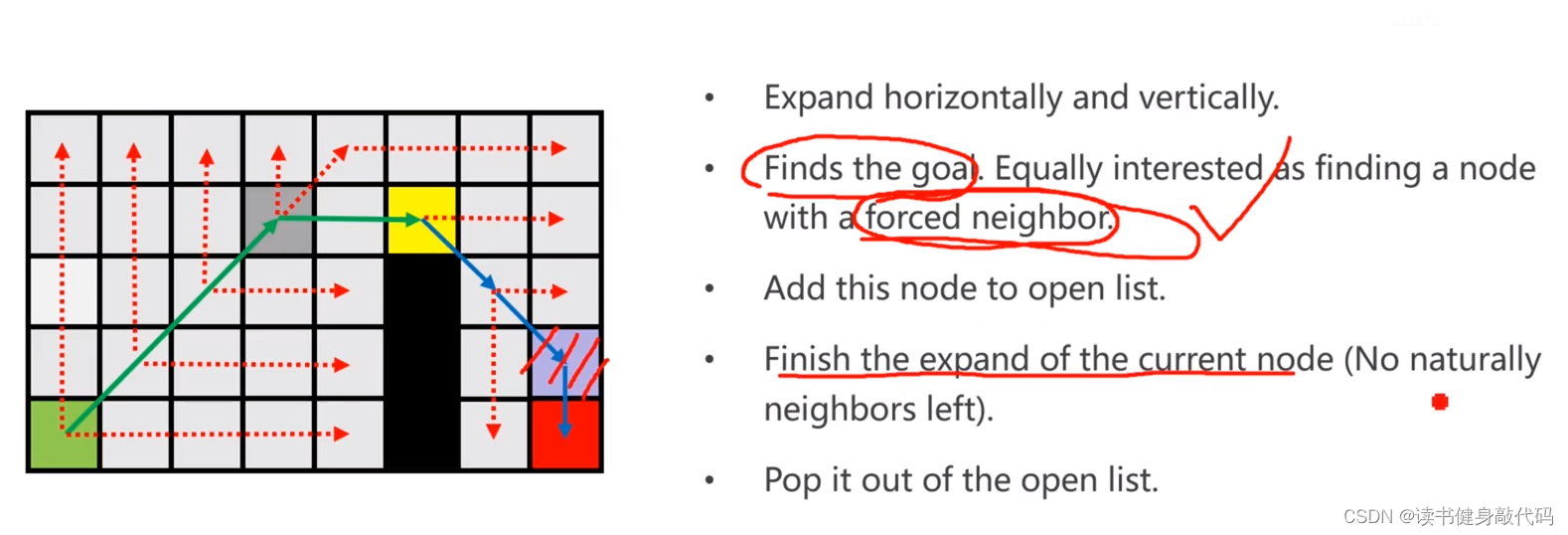
注意,当在扩展时发现了goal,视为发现了force neighbor,要recall并加入node到open list
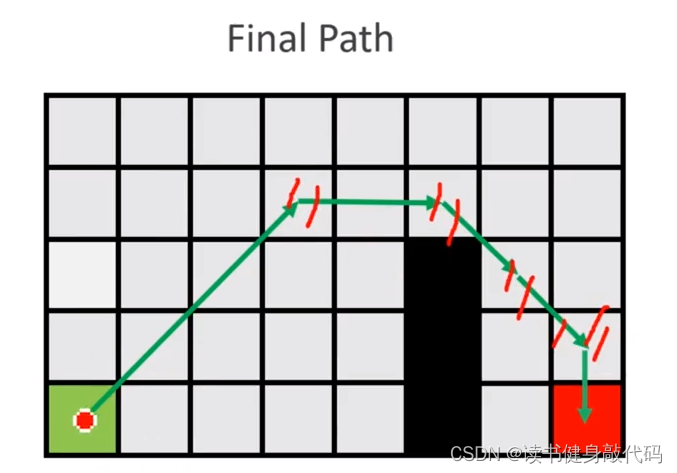
最终path
例子4:
6.3 Extension
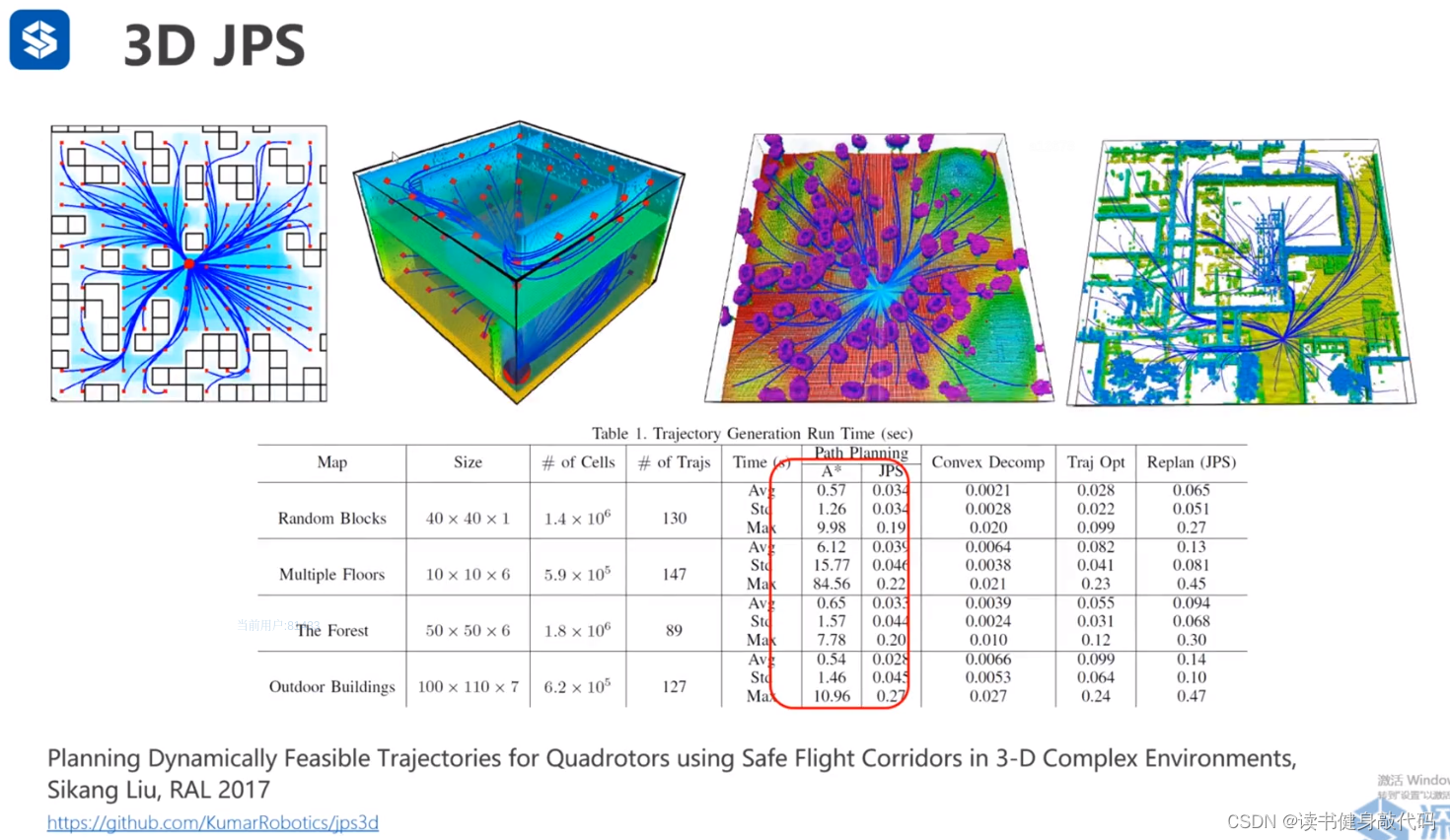
3D JPS,本质上和2D JPS相同,只是3D rules更复杂一些:Sikang之前在深蓝讲过公开课,可以看看。
大多数情况下JPS比A* 更优,因为JPS能够在复杂环境中迅速找到一个个jump point,省去了中间不必要的加入openlist的搜索过程。

但是在机器人的FOV内看不到障碍物后的点,当存在大量空旷场景时,JPS为了搜索jump point,会不断地collision query,虽然对于open list的操作变少了,但是大量的collision query耗时会增加,可能不一定比A*更优。

我的实验结果:


这种情况下明显A* 更优。
6.4 JPS summary

JPS小结:
- look ahead rule:遵照①~④进行拓展,举一反三
- jumping rule:
- 先水平、竖直straight扩展,再diagonal扩展,
- 遇obstacle或map border都视为该方向上扩展失败,直至发现满足look ahead rule中的force neighbor,
- 直线recall到jump的起始节点(不允许折线recall),加入到open list中
- 当所有方向都扩展完毕之后,将source node加入close list中。
- 当在扩展时发现了goal,视为发现了force neighbor,要recall并加入node到open list
- A* 与JPS的唯一区别在于如何选取neighbors,前者选取几何neighbors,后者根据上述2条rules选取neighbors,故用在A*上的trick均可用于JPS(diagonal heuristic,Tie breaker等)
- JPS 和A* 都依赖的一个点是force point一定是最优路径需要经过的点,即jump point,将起点到终点过程中的所有jump points连接起来就得到了最优path,只不过JPS通过他的规则过滤掉了很多不需要拓展的点,而A* 是所有几何neighbors都拓展。(JPS的jump point和外层循环所维护的最小cost是不一样的,前者是JPS’s rules,后者是JPS和A* 的算法框架)。
- 在复杂环境中JPS通常博A* 更优,但远不是always更优
- JPS降低了对于open list的操作(修改键值,排序等),但增加了status query的次数
- JPS的局限性:仅仅在uniform grid map中才能使用(1,1, 2 \sqrt2 2这类几何特征的grid map),对于更general的图搜索问题(如带权值的非grid map),A* 可以用,而JPS无法使用。
7. 论文推荐
- http://users.cecs.anu.edu.au/~dharabor/data/papers/harabor-grastien-aaai11.pdf
- Planning Dynamically Feasible Trajectories for Quadrotors using Safe Flight Corridors in 3-D Complex Environments, Sikang Liu, RAL 2017