PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象RDD全称为弹性分布式数据集(Resilient Distributed Datasets),PySpark针对数据的处理,都是以RDD对象作为载体,即:
•数据存储在RDD内
•各类数据的计算方法,也都是RDD的成员方法
•RDD的数据计算方法,返回值依旧是RDD对象
PySpark的编程模型(左图)可以归纳为:准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等,即:源数据 -> RDD -> 结果数据
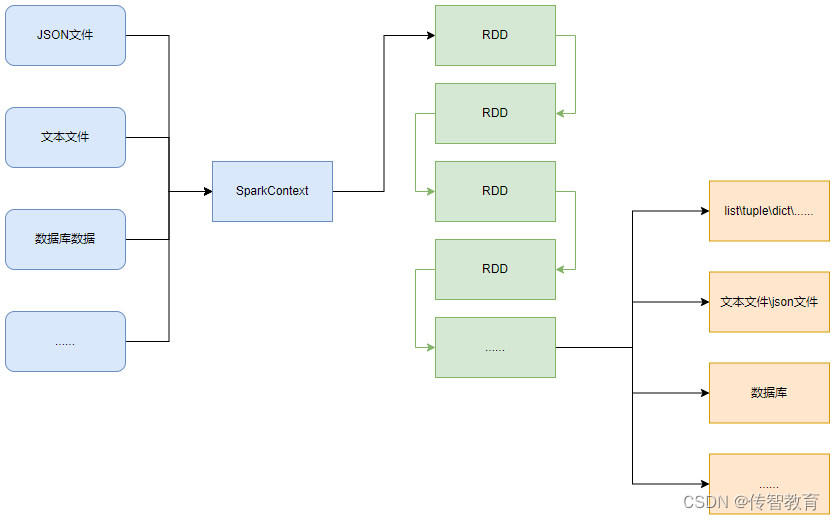
PySpark支持通过SparkContext对象的parallelize成员方法,将list、tuple、set、dict、str转换为PySpark的RDD对象,示例代码如下:
from pyspark import SparkConf,SparkContextconf = SparkConf(.setMaster("local[*]").\setAppName("test_spark_app")
sc = SparkContext(conf=conf)rdd=sc.para1lelize(数据容器对象)# 输出RDD的内容
print(rdd.collect(0)
注意:字符串会被拆分出1个个的字符,存入RDD对象,字典仅有key会被存入RDD对象。
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象,示例代码如下:
from pyspark import SparkConf,SparkContextconf = SparkConf().setMaster("loca][*]").\setAppName("test_spark_app")
sc = SparkContext(conf=conf)rdd=sc.textFile(文件路径)#打印RDD内容
print(rdd.collect())