1. 用赋值语向给定一个包含学生姓名和成绩的字典:{“lili”:80,“xiaoqiang”:75,“yunyun”:89,“yuanyuan”:90,“wanghao”:85},统计其中分数最高的三个同学(假设不存在同分的情况)的成绩,并将它们的成绩和分数打印在屏幕上。屏幕输出:
yuanyuan 90
yunyun 89
wanghao 85
score = { "lili":80,"xiaoqiang" : 75,"yunyun" : 89,"yuanyuan" : 90,"wanghao" : 85 }
ls = list(score.items())
ls.sort(key = lambda x : x[1], reverse = True)
for i in range(3):print("{} {}".format(ls[i][0],ls[i][1]))
ls.sort(key=lambda x:x[1],reverse=True)
- key=lambda x: x[1]是一个关键参数,它指定了排序的规则。在这里,使用了一个匿名函数(lambda函数),它接受列表中的每个元素x,然后返回x[1]。这表示排序将根据每个元素的索引为1的值进行。
如果ls是一个列表的列表(二维列表),例如 [[a, b], [c, d], [e, f], …],那么x[1]表示每个子列表的第二个元素。
如果ls是一个列表的元组(二维元组),例如 [(a, b), (c, d), (e, f), …],同样,x[1]表示每个元组的第二个元素。
这种方式允许你按照子列表或元组的特定位置的值进行排序。- reverse=True是一个可选参数,如果设置为True,则表示降序排序;如果设置为False或省略,默认是升序排序。
2. 考生文件夹下存在2个Python源文件和2个文本文件。其中,2个Python源文件对应2个问题,2个文本文件分别摘自2019年和2018年的政府工作报告。请分别补充2个Python源文件,实现以下功能。
问题1:数据统计。要求:修改PY301-1.py文件中代码,分别统计两个文件中出现次数最多的10词语,作为主题词,要求词语不少于2个字符,打印输出在屏幕上,输出示例如下:
2019:改革:10,企业:9…(略),深化:2
2018:改革:11.效益:7…(略),深化:1
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语间用逗号分隔,最后一个词语后无逗号。
import jiebadef fenci(txt):f = open(txt, 'r')datas = f.read()f.close()data = jieba.lcut(datas) #分词d = {}for i in data :if len(i) >= 2 : #词语不少于2个字符d[i] = d.get(i, 0) + 1 #统计频次lt = list(d.items()) #降序排序lt.sort(key = lambda x:x[1],reverse = True)return ltdef show(lt):for i in lt[:9]:print(i[0], ':', i[1], end = ',', sep = '')print(lt[9][0], ':', lt[9][1], sep = '') #最后一个词语后无逗号
l1 = fenci('data2018.txt')
l2 = fenci('data2019.txt')
print('2019:', end = '', sep = '') #输出保持在同一行,'2019:'后无分隔符
show(l2)
print('2018:', end = '', sep = '')
show(l1)
sep参数:sep用于指定在打印多个值时,各个值之间的分隔符。
end参数:end用于指定在打印完所有值后的行尾符。
问题2:数据关联。要求:修改PY301-2.py文件中代码,对比两组主题词的差异,输出两组的共有词语和分别的特有词语。输出示例如下:
共有词语:改革…(略),深化
2019特有:企业,…(略),加强
2018特有:效益,…(略),创新
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语间用逗号分隔,最后一个词语后无逗号
import jiebadef fenci(txt):f = open(txt, 'r')datas = f.read()f.close()data = jieba.lcut(datas)d = {}for i in data :if len(i) >= 2 :d[i] = d.get(i, 0) + 1lt = list(d.items())lt.sort(key = lambda x:x[1],reverse = True)ls = [x[0] for x in lt[:10]] #把频次最高的主题词提取出来return lsdef show(lt):print(','.join(lt)) #将序列中的元素使用指定的分隔符连接成一个字符串l1 = fenci('data2018.txt')
l2 = fenci('data2019.txt')
l3 = []
for i in l1:if i in l2:l3.append(i) #共有词语加入空列表l3
for i in l3:l1.remove(i) #移除共有词语,保留特有词语l2.remove(i)print('共有词语:',end = '',sep = '')
show(l3)
print('2019特有:',end = '',sep = '')
show(l2)
print('2018特有:',end = '',sep = '')
show(l1)
3. 考生文件夹下,存在2个Python源文件和1个文本文件。其中,2个Python源文件对应2个问题,文本文件“data.txt”中包含一篇从互联网上下载的关于“德国工业4.0战略规划实施建议摘要”的文章。请分别补充2个Python源文件,完成以下功能:
问题1:文件内容清洗。要求:在文件PY301-1.py中补充代码,对文件data.txt的内容进行清理,去除中文标点符号,只保留中文、英文、数字、英文标点符号等字符,将结果输出到文件clean.txt中。示例如下:
德国工业4.0战略计划实施建议摘编机械工业信息研究院战略与规化研究所一德国实施工业… (略)
f = open('data.txt', 'r', encoding = 'utf-8')
data = f.read()
f.close()
f = open('clean.txt', 'w')
s = ''
x = ',。?、‘’“”;:、 )\n——(!'
for i in data:if i not in x:s += i
f.write(s)
f.close()
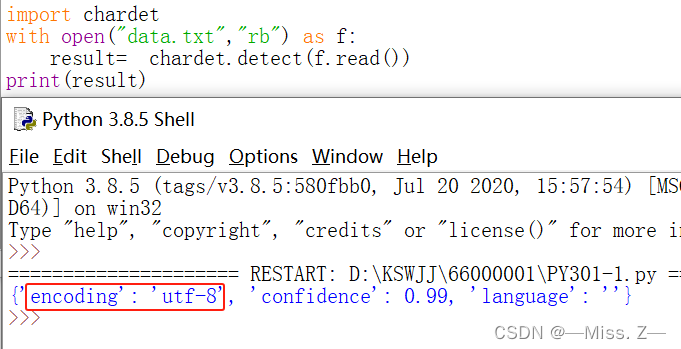
读取文件时,出现“UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xae in position 38: illegal multibyte sequence”错误提示:表明你在使用GBK编码尝试解码文件时遇到了无效的多字节序列。这通常发生在文件中包含了不被GBK编码支持的字符或者文件本身不是以GBK编码保存的。
- 解决方法:确认文件编码: 首先确保你了解文件的实际编码方式。你可以使用一些工具或者文本编辑器来查看文件的编码。如果不确定,可以尝试使用chardet库来自动检测文件编码。
import chardet
with open('data.txt', 'rb') as f:result = chardet.detect(f.read())
print(result)
问题2:提取主题词及其出现频次。要求:在文件PY301-2.py中补充代码,提取clean.txt文件中长度不少于3字符的词语并统计词频,将词频最高的10词语作为主题词,并将主题词及其频次输出到屏幕。示例如下:
4.0:10,制造业:9…(略)
注意:输出格式采用英文冒号和英文逗号,标点符号前后无空格,各词语中间用逗号分隔,最后一个词语后无逗号。
import jieba
f = open('clean.txt', 'r')
data = f.read()
l = jieba.lcut(data)
d = {}
for i in l :if len(i) >= 3 :d[i] = d.get(i, 0) + 1
lt = list(d.items())
lt.sort(key = lambda x:x[1],reverse = True)
for i in lt[:9]:print(i[0],':',i[1],end=',',sep='')
print(lt[9][0],':',lt[9][1],sep='')
f.close()
4. 考生文件夹下的文件data.txt是教有部中国大学MOOC平台的某HTML页面源文件,里面包含了我国参与MOOC建设的一批大学或机构列表。
问题1:请编写程序,从data.txt中提取大学或机构名称列表,将结果写入文件univ.txt,每行一个大学或机构名称,按照大学或机构在data.txt出现的先后顺序输出。
提示:所有大学名称在data.txt文件中以 alt=“北京理工大学”形式存在。
fi = open("data.txt", "r") # 此处可多行
f = open("univ.txt", "w")lines = fi.readlines()
for line in lines:if 'alt=' in line:line = line.split('alt="')[1].split('"')[0]f.write(line + '\n')
fi.close()
f.close()
解析:
line = line.split('alt="')[1].split('"')[0]
取line.split('alt="')[1]--> line = [‘北京大学" width=“164” height=“60”>’]
取line.split('alt="')[1].split('"')[0]--> line = [‘北京大学’]


问题2:请编写程序,从univ.txt文件中提取大学名称,大学名称以出现“大学”或“学院”字样为参考,但不包括“大学生”等字样,将所有大学名称在屏幕上输出,大学各行之间没有空行,最后给出名称中包含“大学”和“学院”的名称数量,同时包含“大学”和“学院”的名称当作“大学”处理,不计为“学院”。
f = open("univ.txt", "r")
n = 0 # 包含大学的名称数量
L = []
lines = f.readlines()
for line in lines:if "学院" in line and "大学" in line and "大学生" not in line: #同时包含“大学”和“学院”L.append(line)n += 1elif "学院" in line:L.append(line)elif "大学" in line and "大学生" not in line: #出现"大学"但不包括"大学生"L.append(line)n += 1
for i in L:print(i, end = '')
f.close()
print("包含大学的名称数量是{}".format(n))
print("包含学院的名称数量是{}".format(len(L) - n))
5. 考生文件夹下的文件data.txt是一个来源于网上的技术信息资料。
问题1:用Python语言中文分词第三方库ieba对文件data.txt进行分词,并选择长度大于等于3个字符的关键词,写入文件out1.txt,每行一个关键词,各行的关键词不重复,输出顺序不做要求。
import jieba
f = open('data.txt', 'r')#此处可多行
data = f.read()
f.close()
f = open('out1.txt', 'w')
data1 = jieba.lcut(data)
d = []
for x in data1 :if len(x) >= 3 and x not in d :d += [x]f.write(x + '\n')
f.close()
print(d)
问题2:对文件data.txt进行分词,对长度不少于3个字符的关键词,统计出现的次数,按照出现次数由大到小的顺序输出到文件out2.txt,每行一个关键词及其出现次数。
import jieba
f = open('data.txt', 'r')#此处可多行
data = f.read()
f.close()
f = open('out2.txt', 'w')
data1 = jieba.lcut(data) #分词
d = {}for x in data1:if len(x) >= 3:d[x] = d.get(x, 0) + 1 #统计关键词长度≥3的词频ls = list(d.items()) #降序排序
ls.sort(key = lambda x : x[1], reverse = True) # 此行可以按照词频由高到低排序
for l in ls:f.write(l[0] + ':' + str(l[1]) + '\n') #将频次转换为字符类型用于连接f.close()
6. 词频统计并输出。要求如下:
(1)对“红楼梦.txt”中文本进行分词,并对人物名称进行归一化处理,仅归一化以下内容:凤姐、凤姐儿、凤丫头归一为凤姐;宝玉、二爷、宝二爷归一为宝玉;黛玉、罐儿、林妹妹、黛王道归一为黛玉;宝钗、宝丫头归一为宝钗;贾母、老祖宗归一为贾母;袭人、袭人道归一为袭人;贾政、贾政道归一为贾政;贾琏、琏二爷归一为贾琏。
(2)不统计“停用词txt”文件中包含词语的词频。
(3)提取出场次数不少于40次的人物名称,将人物名称及其出场次数按递减排序,保存到result.csv文件中,出场次数相同的,则按照人物名称的字符顺序排序。示例如下:
宝玉,123
凤姐,101
…(略)
其中,人物名称与出场次数之间采用英文逗号分隔,无空格,每组信息一行。
import jiebaf = "红楼梦.txt"
sf = "停用词.txt"
f1 = open(f, encoding = "utf-8")
datas = f1.read()
f1.close()
f2 = open(sf, encoding = "utf-8")
words = f2.read()
f2.close()
data = jieba.lcut(datas)
d = {}
word=["一个","如今","一面","众人","说道","只见","不知","两个","起来","二人","今日","听见","不敢","不能","东西","只得","心中","回来","几个","原来","进来","出去","一时","银子","起身","答应","回去"]
for i in data:if len(i) < 2 or i in words or i in word:continueif i in["凤姐", "凤姐儿", "凤丫头"]:i = "凤姐"elif i in["宝玉", "二爷", "宝二爷"] :i = "宝玉"elif i in["黛玉", "颦儿", "林妹妹", "黛玉道"] :i = "黛玉"elif i in["宝钗", "宝丫头"] :i = "宝钗"elif i in["贾母", "老祖宗"] :i = "贾母"elif i in["袭人", "袭人道"] :i = "袭人"elif i in["贾政", "贾政道"] :i = "贾政"elif i in["贾琏", "琏二爷"] :i = "贾琏"d[i] = d.get(i, 0) + 1
l = list(d.items())
l.sort(key = lambda x : (x[1], x[0]), reverse = True)
f = open("result.csv", 'w')
for i in l:if i[1] < 40: #提取出场次数不少于40次的人物名称breakf.write(i[0] + ',' + str(i[1]) + '\n')
f.close()
7. 考生文件来下存在2个Python源文件和1个文本文件,分别对应2个问题,其中,文本文件“八十天环游地球.txt”是法国作家儒勒凡尔纳《八十天环游地球》长篇小说的网络版本,请修改源文件实现以下功能。
问题1:提取章节题目并输出到文件。要求,在PY301-1.py中补充代码,提取“八十天环游地球.txt”中所有章节的题目,并且将提取后的题目输出到“八十天环游地球-章节.txt”文件中,每行一个标题。
f = open("八十天环游地球.txt")
fo = open("八十天环游地球-章节.txt",'w')
for i in f: #i是文件中的每一行,类型是字符串(str)line = i.strip().split()if line[0][0] == "第" and "章" in line[0]:fo.write(i)
fo.close()
f.close()
问题2:统计每章节的高频词并打印输出。要求:在PY301-2.py中补充代码,统计“八十天环游地球.txt”中每一章的标题和内容中,出现次数最多的词语(词语长度不少于2个字符)及其次数,输出格式为章节名、词语及其出现的次数,以空格分隔。
f = open("八十天环游地球.txt")
datas = f.readlines() #返回一个列表类型,列表中某个元素对应文本中的一行
l = []
for i in range(len(datas)): line = datas[i].split(' ') #每行中的文字,以空格为分隔符 if datas[i][0] == "第" and "章" in line[0] : #一行文本的开头一个字为“第”,并且"章"也在这一行l.append(i) #记录每个“第XX章”的行数下标
for i in range(len(l)):if i != len(l) - 1 : data = ''.join(datas[l[i]:l[i + 1]]) #将每一章的文字以空格符进行连接else: #最后一章data = ''.join(datas[l[i]:])s = data.split()[0]words = jieba.lcut(data)d = {}for y in words:if len(y) < 2:continued[y] = d.get(y, 0) + 1lis = list(d.items())lis.sort(key = lambda x : x[1], reverse = True)print(s, lis[0][0], lis[0][1])f.close()
每个单引号之间包含的是一个字符串元素,而逗号后面的空格是由print函数的默认行为引起的。在默认情况下,print函数会在打印每个元素之间添加一个空格。

8. 在考生文件夹下存在3个Python源文件PY301-1.py、PY301-2.py、PY301-3py和素材文件data.txt。data.txt是由学生信息构成的数据文件,每行是一个学生的相关信息,包括姓名、班级和分数。姓名和其他信息之间用英文冒号隔开,班级和分数之间用英文逗号隔开,班级由“系名+班级序号”组成,如“计算191”。
打开PY301-1.py,编程实现如下功能:
(1)读取data.txt,输出学生的姓名和分数到文件studs.txt,每行一条记录,姓名和分数用英文冒号隔开
fi = open('data.txt','r')
fo = open('studs.txt','w')
students = fi.readlines()
for i in students:i = i.strip().split(':')name = i[0]score = i[1].split(',')[-1]fo.write(name+':'+score+'\n')
fi.close()
fo.close()
打开PY301-2.py,编程实现如下功能:
(2)选出分数最高的学生,打印输出学生的姓名和分数,中间用英文冒号隔开
打开PY301-3.py,编程实现如下功能:
fi = open('data.txt','r')
students = fi.readlines()
l=[]
for i in students:i = i.strip().split(':')name = i[0]score = i[1].split(',')[-1]l.append([name,score])
l.sort(key=lambda x:eval(x[1]),reverse=True)
print(l[0][0]+':'+l[0][1])
fi.close()(3)计算每个班级的平均分,打印输出班级和平均分,平均分小数点后保留2位,中间用英文冒号隔开
fi = open('data.txt','r')
d = {}
students = fi.readlines()
for i in students:i = i.strip().split(':')clas,score = i[1].split(',')d[clas] = d.get(clas,[])+[eval(score)]for i in d:avg_score = sum(d[i])/len(d[i])print('{}:{:.2f}'.format(i,avg_score))
9. 在考生文件夹下存在2个Python源文件PY301-1.py、PY301-2.py和素材文件webpage.txt。
webpage.txt保存了某网站一个网页的HTML格式源代码。在该文件中,JPG图片以一个完整的URL表示
打开PY301-1.py,编程实现如下功能:
(1)统计并打印输出该页面中JPG图像文件的URL数量。注意,JPG扩展名都是大写字母
fi = open('webpage.txt')
datas = fi.readlines()
num = 0
for data in datas:if '.JPG' in data:num += 1
print(num)
fi.close()
打开PY301-2.py,编程实现如下功能:
(2)将webpage.txt页面中的JPG图像文件的URL提取出来,保存在文件images.txt中,每个URL一行
fi = open('webpage.txt')
datas = fi.readlines()
fo = open('images.txt','w')
for data in datas:if '.JPG' in data:data = data.split('src="')[1].split('"')[0]fo.write(data+'\n')
fi.close()
fo.close()
10. 在考生文件夹下存在1个Python源文件PY301.py和1个数据文件data2.csv。在文data2.csv里,第一行是标题,第二行起是部分省份地区参加某项考试的虚拟数据,包括各省区名称、报名、弃考、有效4例。每行是一个省区的一组数据信息,代表报名人数、弃考人数、有效成绩人数。各列数据之间用英文逗号隔开。
打开py301.py文件,编程实现如下功能:
问题1:显示部分数据。读data2.csv文件的前5行的信息,输出在屏幕上;标题行为“省区,报名,弃考,有效”,每个省区的数据写一行,行内教据之间英文逗号分隔。
问题2:统计并保存结果。读取所有数据,统计报名,弃考,有效成绩人数的平均值、最大值、最小值,保存至tongji.csv文件中。其中,标题行为“统计,报名,弃考,有效”,平均值、最大值、最小值数据分别写一行,行内数据之间用英文逗号分隔。
def ravg(lst):sum=0for i in lst:sum+=ireturn round(sum/len(lst),1)qzlst=[]
swlst=[]
zylst=[]
with open("data2.csv","r") as f:datas=f.readlines()for i in datas:if i in datas[:5]:print(i,end='')if i in datas[1:]:ls=i.strip().split(',')qzlst.append(eval(ls[1]))swlst.append(eval(ls[2]))zylst.append(eval(ls[3]))
avglst=["平均值",ravg(qzlst),ravg(swlst),ravg(zylst)]
maxlst=["最大值",max(qzlst),max(swlst),max(zylst)]
minlst=["最小值",min(qzlst),min(swlst),min(zylst)]with open("tongji.csv","w") as f:f.write('统计,报名,弃考,有效\n')f.write('{},{},{},{}'.format(*avglst)+'\n')f.write('{},{},{},{}'.format(*maxlst)+'\n')f.write('{},{},{},{}'.format(*minlst))




![[设计模式Java实现附plantuml源码~创建型] 对象的克隆~原型模式](https://img-blog.csdnimg.cn/direct/2473c30ed78045959184631275c0a1bb.png)