今天再分享一个新的调度框架deeprm
本项目基于hongzimao/deeprm,原作者还著有论文Resource Management with Deep Reinforcement Learning 。
这个框架研究的也蛮多的,我在一篇博士论文中也看到了基于此的研究工作,但是论文题目忘记了。
运行launcher,这是基于TensorFlow1版本的,所以最好安装TensorFlow1的虚拟环境运行,会更顺畅一点,可以直接在CPU上跑
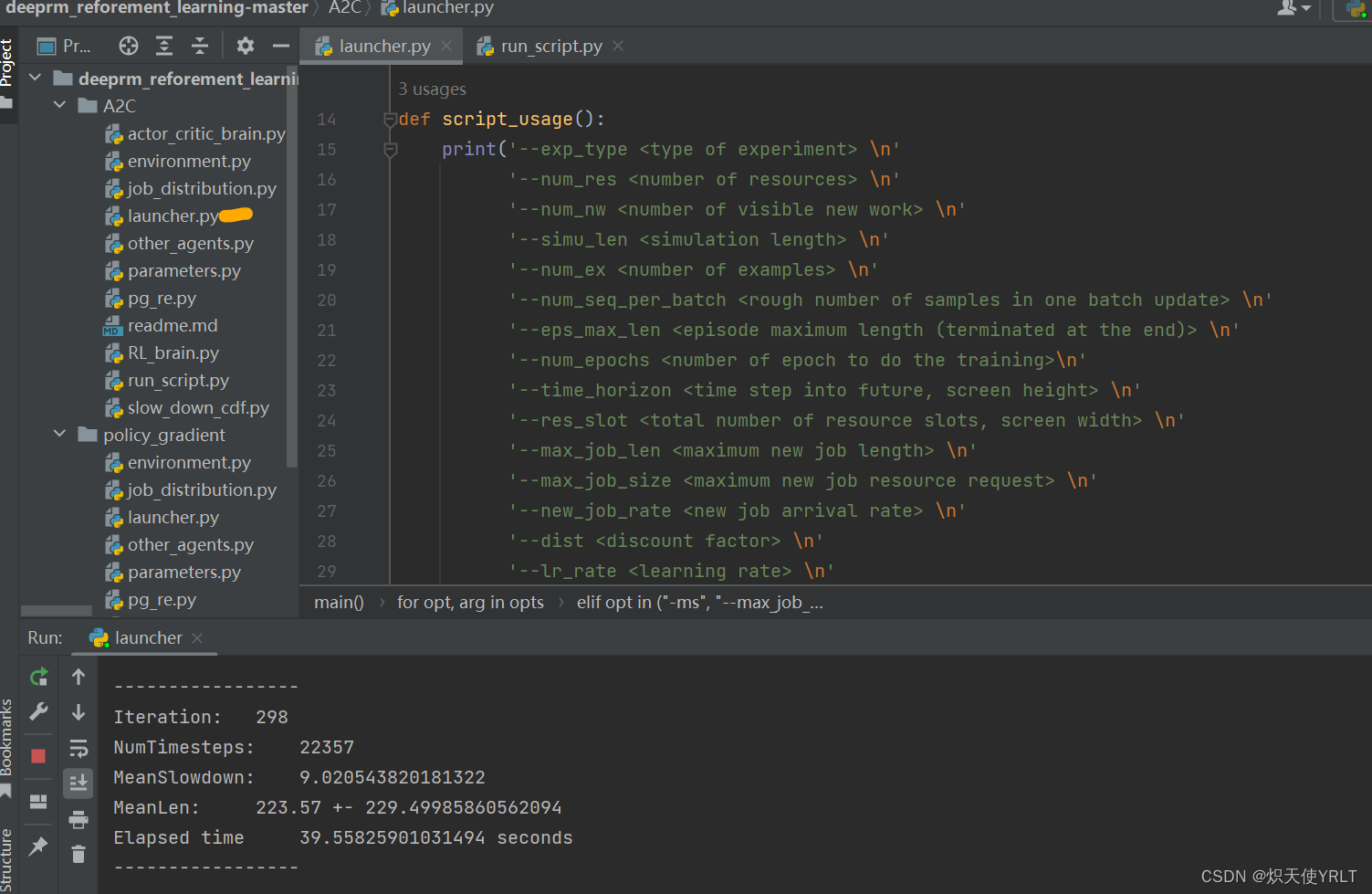
不过CPU还是慢的,我这已经跑298次了,还没结束,几个小时了。
里面也还有其他几种方法的对比
---------- Tetris -----------
total discount reward : -565.3984681984684
---------- SJF -----------
total discount reward : -328.1574092574093
---------- Random -----------
total discount reward : -396.59327339327336
在policy gradient文件夹中也是一样,只不过是基于两种策略方式,但是policy gradient里面的程序运行会有一点问题,报错
AttributeError: 'AxesSubplot' object has no attribute 'set_color_cycle'
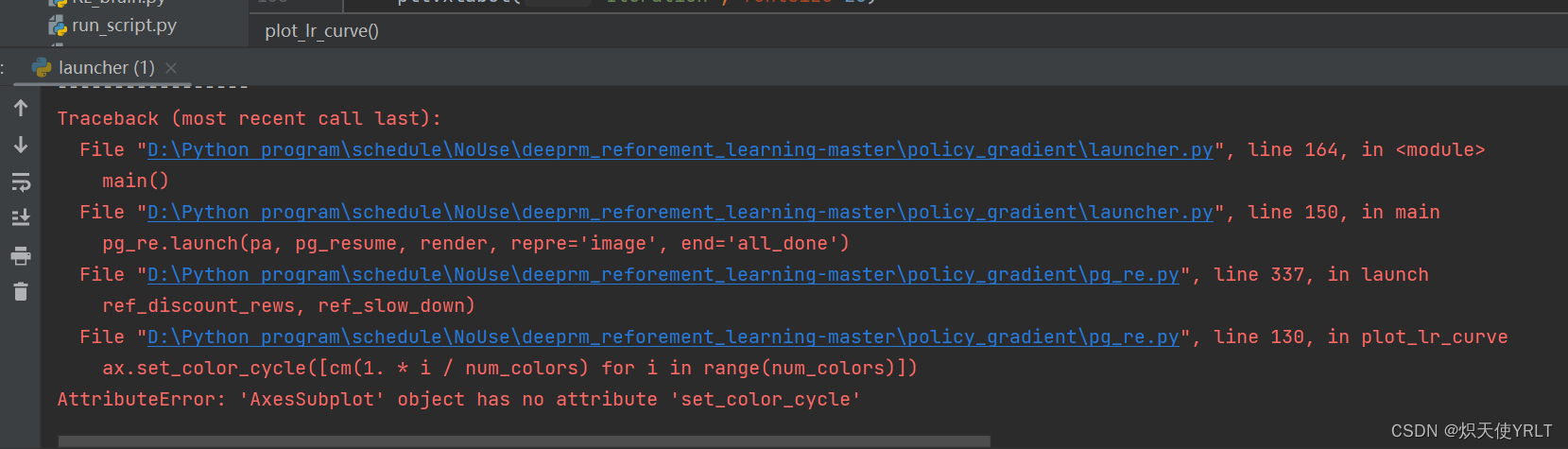
这个错误表明在代码中使用了已经被弃用的 set_color_cycle 方法,因此导致了 AttributeError。在最新版本的 Matplotlib 中,set_color_cycle 方法已经被弃用,取而代之的是 set_prop_cycle 方法。
要解决这个问题,可以将 set_color_cycle 替换为 set_prop_cycle。
ax.set_color_cycle([cm(1. * i / num_colors) for i in range(num_colors)])
替换为
ax.set_prop_cycle(color=[cm(1. * i / num_colors) for i in range(num_colors)])
通过这种方式,应该能够解决该错误
然而,然而又出了新的问题
prop_cycle = cycler(*args, **kwargs)File "C:\Users\zl\anaconda3\envs\py36\lib\site-packages\matplotlib\rcsetup.py", line 904, in cyclerraise TypeError("If only one positional argument given, it must "
TypeError: If only one positional argument given, it must be a Cycler instance.
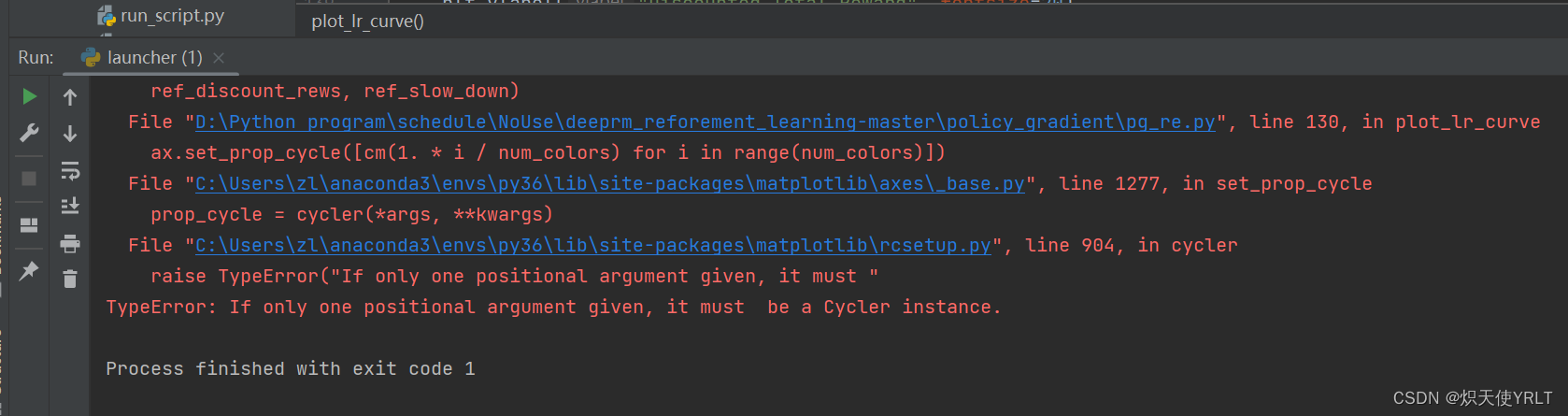
所以,与其这样不断的递归的解决问题,倒不如直接对matplotlib进行降级处理,满足它编写程序时所需的包版本要求,这是最简单快速的解决方案