目录
一.GC调优的核心指标
1.1吞吐量(Throughput)
1.2延迟(Latency)
1.3内存使用量
二.GC调优的方法
2.1监控工具
Jstat工具
VisualVm插件
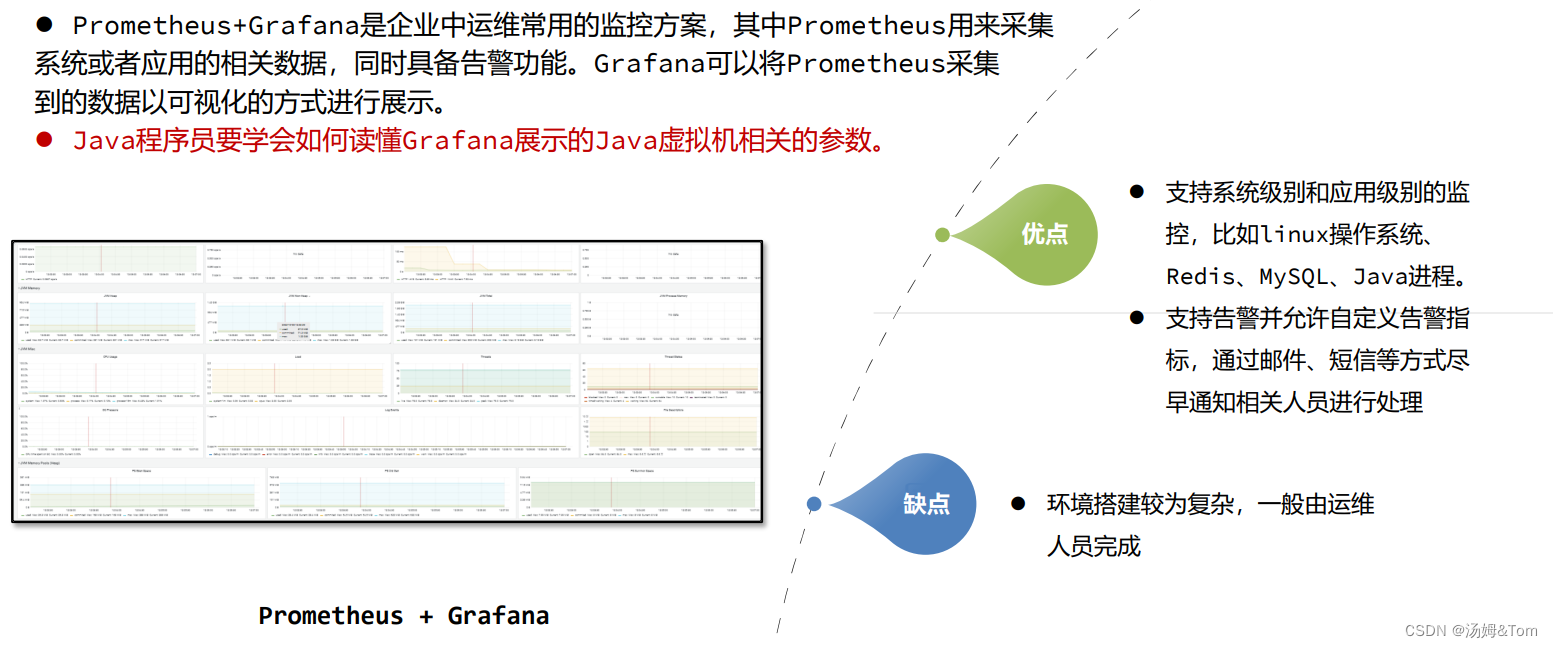
Prometheus + Grafana
2.2诊断原因
GC日志
GC Viewer
GCeasy
2.3常见的GC模式
正常情况
缓存对象过多
内存泄漏
持续的FULL GC
元空间不足导致的FULL GC
三.修复GC问题
3.1优化基础JVM参数
参数1 : -Xmx 和 –Xms
参数2 : -XX:MaxMetaspaceSize 和 –XX:MetaspaceSize
参数3 : -Xss虚拟机栈大小
不建议手动设置的参数
其他参数
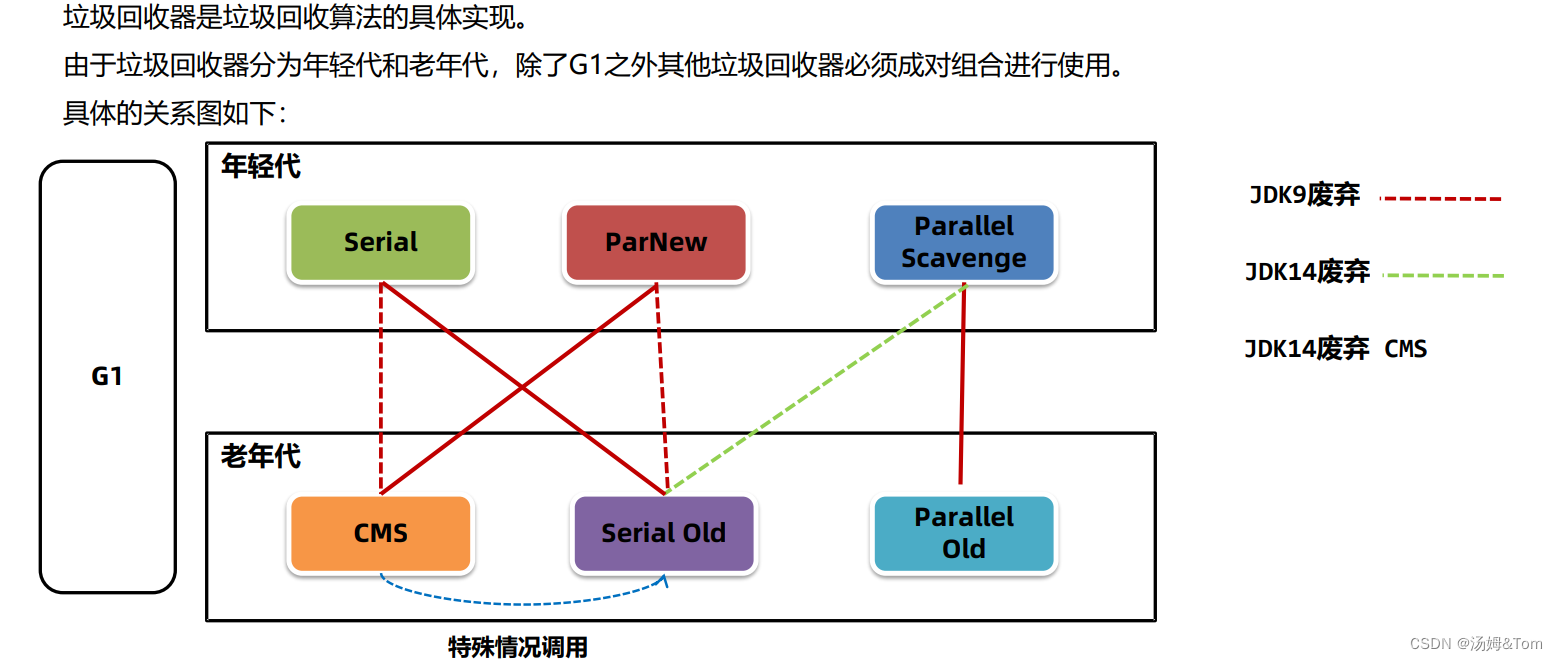
3.2垃圾回收器的选择
GC调优

GC调优指的是对垃圾回收(Garbage Collection)进行调优。GC调优的主要目标是避免由垃圾回收引起程序性能下降。
GC调优的核心分成三部分:
- 通用JVM参数的设置。
- 特定垃圾回收器的JVM参数的设置。
- 解决由频繁的FULL GC引起的程序性能问题。
GC调优没有唯一的标准答案,如何调优与硬件、程序本身、使用情况均有关系,重点学习调优的工具和方法。
一.GC调优的核心指标
所以判断GC是否需要调优,需要从三方面来考虑,与GC算法的评判标准类似:
1.1吞吐量(Throughput)
吞吐量分为业务吞吐量和垃圾回收吞吐量
业务吞吐量指的在一段时间内,程序需要完成的业务数量。比如企业中对于吞吐量的要求可能会是这样的:
- 支持用户每天生成10000笔订单
- 在晚上8点到10点,支持用户查询50000条商品信息
保证高吞吐量的常规手段有两条:
- 优化业务执行性能,减少单次业务的执行时间
- 优化垃圾回收吞吐量
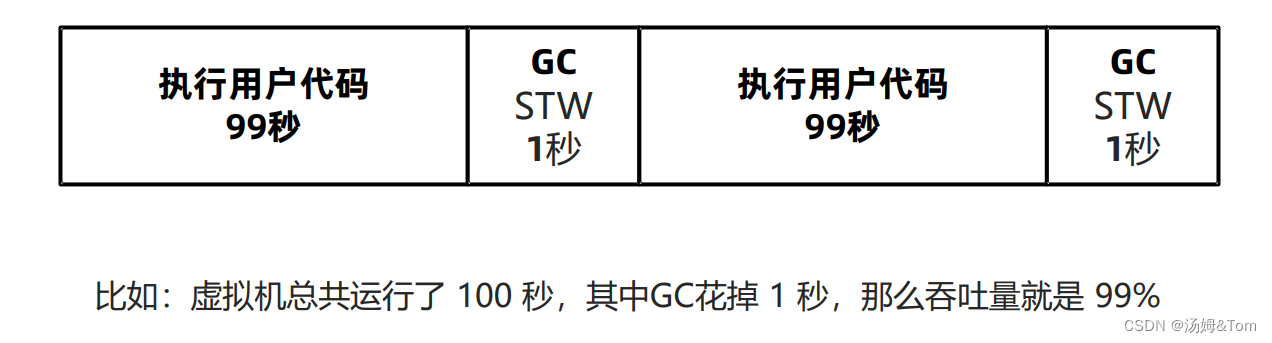
垃圾回收吞吐量指的是 CPU 用于执行用户代码的时间与 CPU 总执行时间的比值,即吞吐量 = 执行用户代码时间 /(执行用户代码时间 + GC时间)。吞吐量数值越高,垃圾回收的效率就越高,允许更多的CPU时间去处理用户的业务,相应的业务吞吐量也就越高。
1.2延迟(Latency)
延迟指的是从用户发起一个请求到收到响应这其中经历的时间。
延迟 = GC延迟 + 业务执行时间,所以如果GC时间过长,会影响到用户的使用。


1.3内存使用量
内存使用量指的是Java应用占用系统内存的最大值,一般通过JVM参数调整,在满足上述两个指标的前提下, 这个值越小越好。

通常这3个指标不能同时兼顾
二.GC调优的方法
2.1监控工具
Jstat工具

无法精确到GC产生的时间,只能 用于判断GC是否存在问题
VisualVm插件

Prometheus + Grafana
2.2诊断原因
GC日志
通过GC日志,可以更好的看到垃圾回收细节上的数据,同时也可以根据每款垃圾回收器的不同特点更好地发现存在的问题。
- 使用方法(JDK 8及以下):-XX:+PrintGCDetails -Xloggc:文件名
- 使用方法(JDK 9+):-Xlog:gc*:file=文件名
注: -verbose:gc 是将GC日志输出到控制台上,而上面是将GC日志单独输出到一个文件
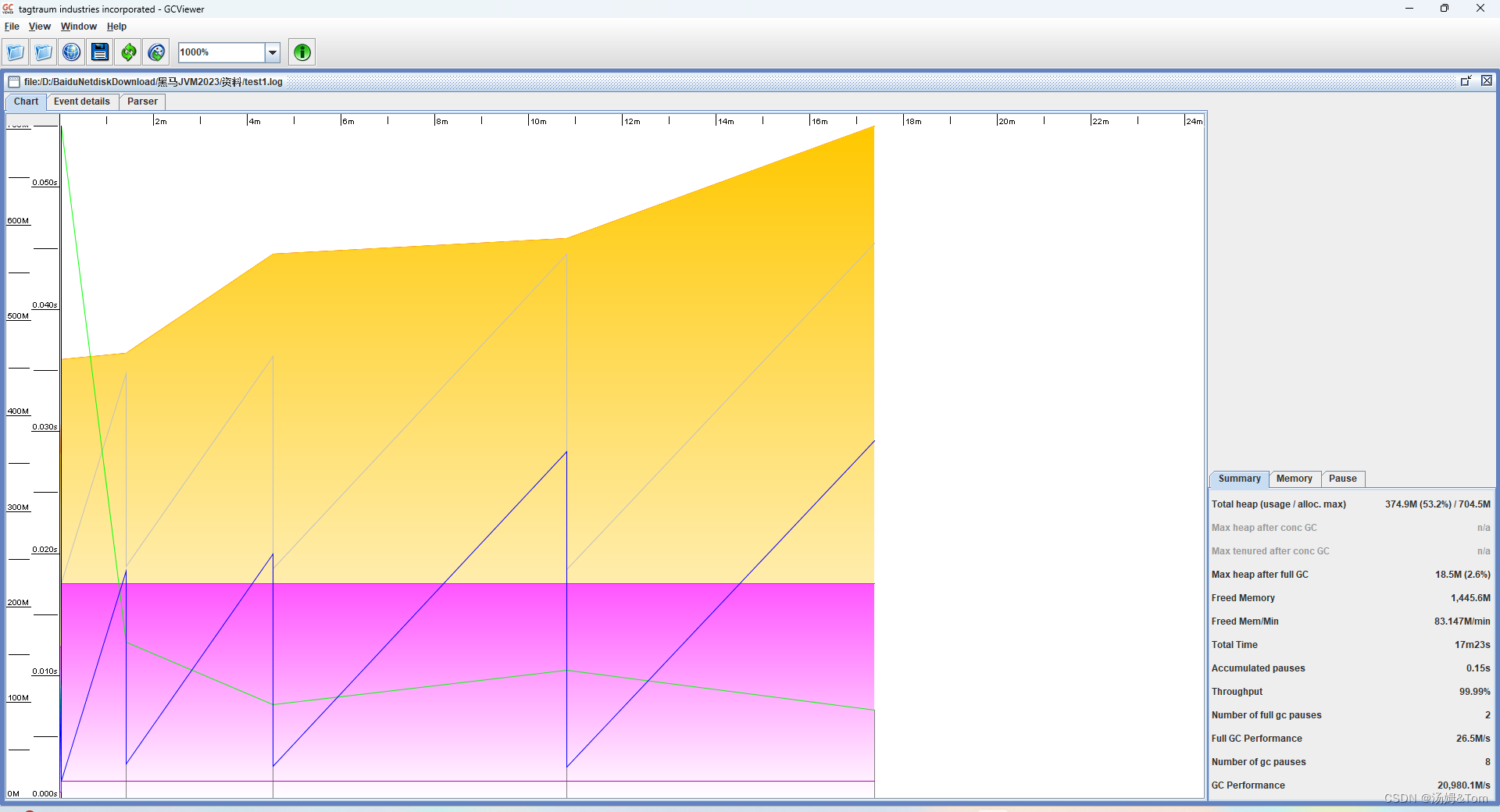
GC Viewer
GCViewer是一个将GC日志转换成可视化图表的小工具,github地址:https://github.com/chewiebug/GCViewer
使用方法:java -jar gcviewer的jar包 日志文件.log
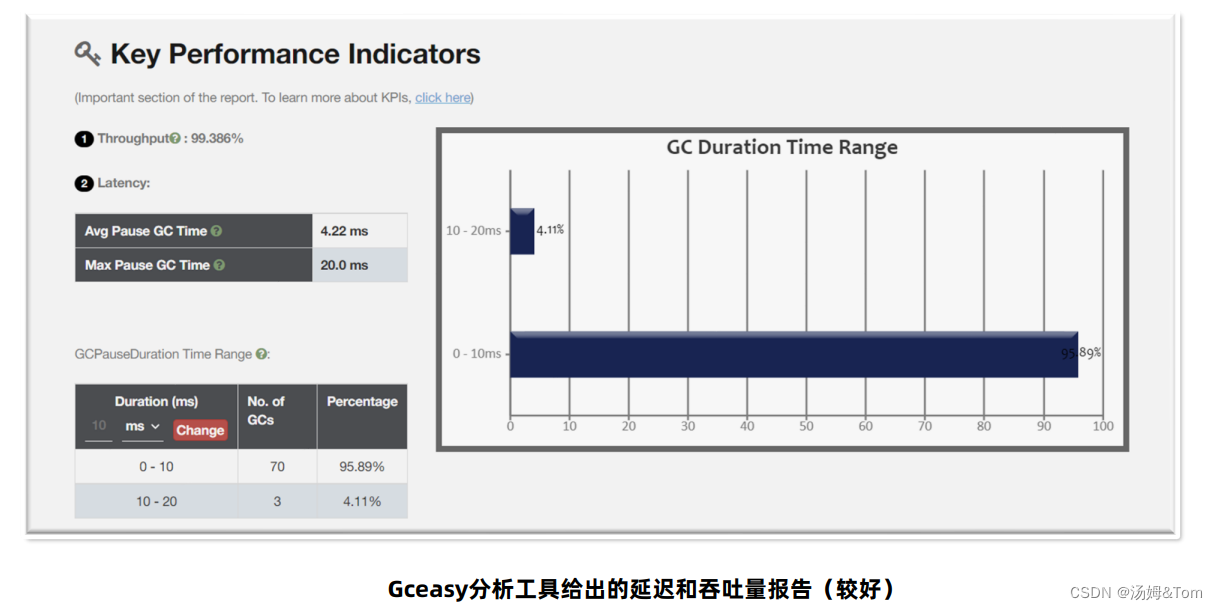
GCeasy
GCViewer是将GC日志可视化,而GCeasy是业界首款使用AI机器学习技术在线进行GC分析和诊断的工具。定位内存泄漏、GC延迟高的问题,提供JVM参数优化建议,支持在线的可视化工具图表展示。官方网站:Universal JVM GC analyzer - Java Garbage collection log analysis made easy (gceasy.io)

2.3常见的GC模式
正常情况
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,存留的对象较少。

缓存对象过多
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,处于比较高的位置。
问题产生原因: 程序中保存了大量的缓存对象,导致GC之后无法释放,可以使用MAT或者HeapHero等工具进行分析内存占用的原因。

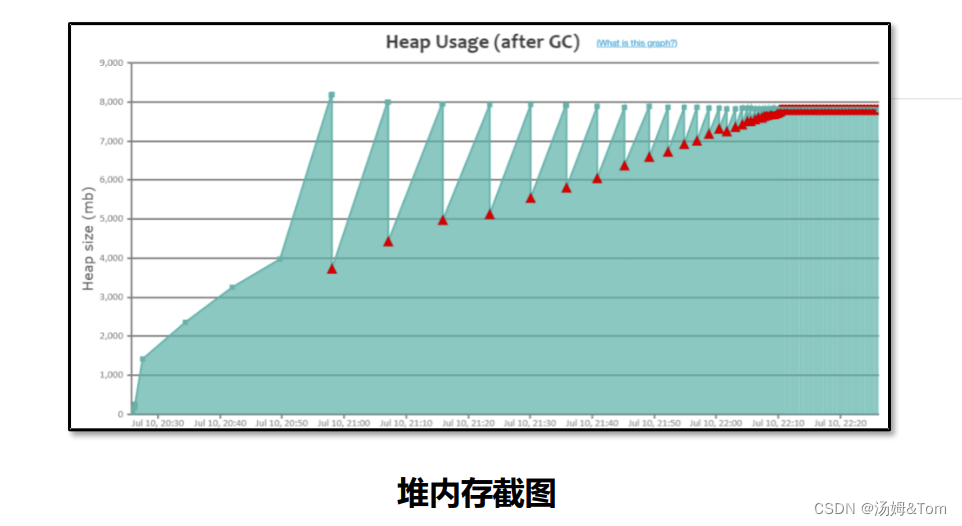
内存泄漏
特点:呈现锯齿状,每次垃圾回收之后下降到的内存位置越来越高,最后由于垃圾回收无法释放空间导致对象无法分配产生OutOfMemory的错误。
问题产生原因: 程序中保存了大量的内存泄漏对象,导致GC之后无法释放,可以使用MAT或者HeapHero等工具 进行分析是哪些对象产生了内存泄漏。
持续的FULL GC
特点:在某个时间点产生多次Full GC,CPU使用率同时飙高,用户请求基本无法处理。一段时间之后恢复正常。
问题产生原因:在该时间范围请求量激增,程序开始生成更多对象,同时垃圾收集无法跟上对象创建速率,导致持续地在进行FULL GC。

元空间不足导致的FULL GC
特点:堆内存的大小并不是特别大,但是持续发生FULL GC。
问题产生原因:元空间大小不足,超过了Java虚拟机设置的阈值,导致持续FULL GC回收元空间的数据。

三.修复GC问题
解决GC问题的手段中,前三种是比较推荐的手段,第四种仅在前三种无法解决时选用:

3.1优化基础JVM参数
参数1 : -Xmx 和 –Xms
-Xmx参数设置的是最大堆内存,但是由于程序是运行在服务器或者容器上,计算可用内存时,要将元空间、操作系统、 其它软件占用的内存排除掉。
案例:服务器内存4G,操作系统+元空间最大值+其它软件占用1.5G,-Xmx可以设置为2g。
最合理的设置方式应该是根据最大并发量估算服务器的配置,然后再根据服务器配置计算最大堆内存的值。

-Xms用来设置初始堆大小,建议将-Xms设置的和-Xmx一样大,有以下几点好处:
- 运行时性能更好,堆的扩容是需要向操作系统申请内存的,这样会导致程序性能短期下降。
- 可用性问题,如果在扩容时其他程序正在使用大量内存,很容易因为操作系统内存不足分配失败。
- 启动速度更快,Oracle官方文档的原话:如果初始堆太小,Java 应用程序启动会变得很慢,因为 JVM 被迫频繁执行垃圾收集,直到堆增长到更合理的大小。为了获得最佳启动性能,请将初始堆大小设置为与最大堆大小相同。
参数2 : -XX:MaxMetaspaceSize 和 –XX:MetaspaceSize
- -XX:MaxMetaspaceSize=值 参数指的是最大元空间大小,默认值比较大,如果出现元空间内存泄漏会让操作系统可用内存不可控,建议根据测试情况设置最大值,一般设置为256m。当元空间大小超过这个值时,会抛出OutOfMemoryError。
- -XX:MetaspaceSize=值 参数指的是到达这个值之后会触发FULL GC(指的不是初始元空间大小), 后续什么时候再触发JVM会自行计算。如果设置为和MaxMetaspaceSize一样大,就不会FULL GC,但是对象也无法回收。

参数3 : -Xss虚拟机栈大小
如果我们不指定栈的大小,JVM 将创建一个具有默认大小的栈。大小取决于操作系统和计算机的体系结构。 比如Linux x86 64位 : 1MB,如果不需要用到这么大的栈内存,完全可以将此值调小节省内存空间,合理值为256k – 1m之间。
使用:-Xss256k
不建议手动设置的参数
由于JVM底层设计极为复杂,一个参数的调整也许让某个接口得益,但同样有可能影响其他更多接口。
- -Xmn 年轻代的大小,默认值为整个堆的1/3,可以根据峰值流量计算最大的年轻代大小,尽量让对象只存放在年轻代,不进入老年代。但是实际的场景中,接口的响应时间、创建对象的大小、程序内部还会有一些定时任务等不 确定因素都会导致这个值的大小并不能仅凭计算得出,如果设置该值要进行大量的测试。G1垃圾回收器尽量不要设置该值,G1会动态调整年轻代的大小。

- ‐XX:SurvivorRatio 伊甸园区和幸存者区的大小比例,默认值为8。
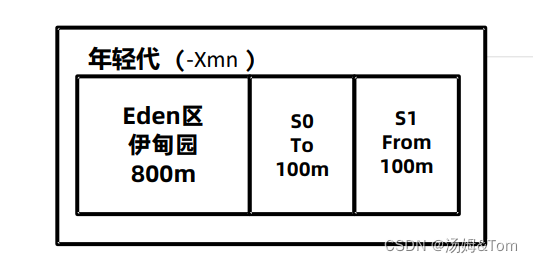
- ‐XX:MaxTenuringThreshold 最大晋升阈值,年龄大于此值之后,会进入老年代。另外JVM有动态年龄判断机制:当 survior 区域的存活对象的总大小占用了 survior 区域大小的50%(可以通过参数指定),那么此时将按照这些对象的存活年龄从小到大排序,然后依次累加,当累加到对象大小超过50%,则将大于等于当前对象年龄的存活对象全部挪到老年代。

其他参数
- -XX:+DisableExplicitGC 禁止在代码中使用System.gc(), System.gc()可能会引起FULL GC,在代码中尽量不要使用。使用DisableExplicitGC参数可以禁止使用System.gc()方法调用。
- -XX:+HeapDumpOnOutOfMemoryError 发生OutOfMemoryError错误时,自动生成hprof内存快照文件。
- -XX:HeapDumpPath= 指定hprof文件的输出路径。
-
打印GC日志
-
JDK8及之前 : -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:文件路径
-
JDK9及之后 : -Xlog:gc*:file=文件路径
-

3.2垃圾回收器的选择