目录
一、ChatGPT和文心一言大模型的对比分析
1.1 二者训练的数据情况分析
1.2 训练大模型数据规模和参数对比
1.3 二者3.5版本大模型对比总结
二、ChatGPT和文心一言功能对比分析
2.1 二者产品提供的功能情况分析
2.2 测试一下各种功能的特性
2.2.1 文本创作能力
2.2.2 代码功能
2.2.3 画图功能
三、总结
前言:
ChatGPT和文心一言都是基于大模型驱动的AIGC产品,由于两者训练的基础数据不同,造成了两者功能和性能上的差异。
本文将分析两者大模型的区别,然后测试二者功能和性能上的差异。
一、ChatGPT和文心一言大模型的对比分析
对于ChatGPT和文心一言,市场上免费的最高大模型版本都是3.5,想要对比二者的区别,就要从二者大模型训练的数据集和模型参数上分析。
1.1 二者训练的数据情况分析
我们来问一下两个产品训练数据来源?
ChatGpt的回答:

文心一言的回答:

1.2 训练大模型数据规模和参数对比
问一下训练数据量级和模型参数量级?
ChatGpt回答:

GPT3.5大模型几百亿的参数量级;用于训练数据规模大,具体未知。
文心一言回答:

文心一言3.5大模型参数没有在官网找到,推论不超过千亿;用于训练清洗好的数据集有数十亿。
1.3 二者3.5版本大模型对比总结
这里我们问的是两者训练的数据量级;ChatGpt回答的是有数百亿的参数,文心一言回答的是原始数据量级;这里补充个概念B(十亿),表示用于大模型训练的参数量。
训练数据集:ChatGpt从论文、GitHub、模型、Facebook的对话数据集、SOTA38.5万个对话的高质量数据等作为训练数据,数据集很大,但具体详情数据未知;文心一言从网络、新闻、博客等清理出数十亿处理后的数据作为数据集;
模型参数:ChatGpt3.5大模型有数百亿的参数,几十B;文心一言大模型的参数没有说明,推论有几百亿的参数。
两个3.5版本大模型,从训练数据量和数据参数大小问答没有具体的指标;能从数据来源知道ChatGPT的训练数据更丰富,模型参数上没有详细的数据指标对比。
二、ChatGPT和文心一言功能对比分析
两个产品面向应用市场,可以免费使用的最新功能和性能对比分析。
2.1 二者产品提供的功能情况分析
ChatGpt回答:

文心一言回答:

总结:两者都能提供问答交流、文本创作、学科知识等交流; ChatGpt能提供编程辅助,文心一言能提供图片生成功能;
2.2 测试一下各种功能的特性
2.2.1 文本创作能力
写一首描述人工智能的七言绝句:
ChatGpt回答:
第一次写:
在芯片雄伟展神威,智慧涌动若潮汐。
代码谱写奇迹歌,铸就未来数千纸。
第二次写:
电流流转翼智慧,机械心灵识未来。
代码舞动奇思妙,数算世间新秩序。
文心一言回答:
第一次写:
智能光芒照万方,人勤智慧是吾邦。
能描妙境超凡俗,画出未来入梦乡。
第二次写:
智能科技耀乾坤, 创新发展势如虹。
未来世界谁主宰, 只有人工智能通。
总结:对于ChatGpt和文心一言对于汉字的理解能力与生成能力;
ChatGpt要求的是写七言,但是第一次却出现了八个字的句子,第二次回答才合规,从文学的角度看,它对于语义理解和输出产生的内容,有较高的理解水准,深层次描写了因果关系;
文心一言两次在规范上都是符合,但是从文学角度看,它的理解力和输出内容的深度停留在描述层面,和chatGpt的交流深度有一定的差距。
2.2.2 代码功能
问一下:写一个Flink1.16版本,Kafka到ES的代码。
ChatGpt代码能力:
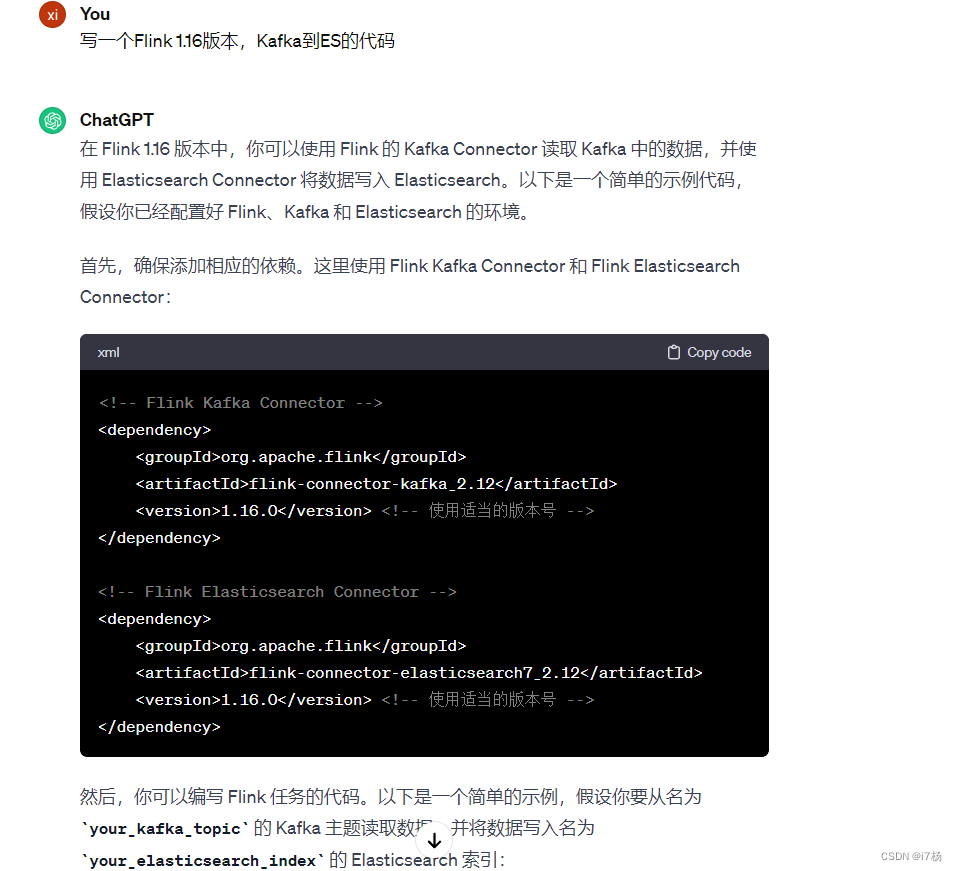
<!-- Flink Kafka Connector xml-->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.16.0</version> <!-- 使用适当的版本号 -->
</dependency><!-- Flink Elasticsearch Connector -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7_2.12</artifactId><version>1.16.0</version> <!-- 使用适当的版本号 -->
</dependency>-----code-----
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.flink.util.Collector;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;public class KafkaToESSinkExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties kafkaProps = new Properties();kafkaProps.setProperty("bootstrap.servers", "your_kafka_bootstrap_servers");kafkaProps.setProperty("group.id", "your_consumer_group_id");// 从 Kafka 读取数据DataStream<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<>("your_kafka_topic", new SimpleStringSchema(), kafkaProps));// 解析 Kafka 数据,可以根据实际情况修改DataStream<Map<String, String>> parsedStream = kafkaStream.map(new KafkaDataParser());// 将数据写入 ElasticsearchList<HttpHost> httpHosts = new ArrayList<>();httpHosts.add(new HttpHost("your_elasticsearch_host", 9200, "http"));ElasticsearchSink.Builder<Map<String, String>> esSinkBuilder = new ElasticsearchSink.Builder<>(httpHosts,new ElasticsearchSinkFunction<Map<String, String>>() {public IndexRequest createIndexRequest(Map<String, String> element) {// 定义将要写入 Elasticsearch 的文档Map<String, String> json = new HashMap<>();json.put("field1", element.get("field1"));json.put("field2", element.get("field2"));// 添加更多字段...return Requests.indexRequest().index("your_elasticsearch_index").type("_doc").source(json);}@Overridepublic void process(Map<String, String> element, RuntimeContext ctx, RequestIndexer indexer) {indexer.add(createIndexRequest(element));}});// 设置批量写入选项esSinkBuilder.setBulkFlushMaxActions(1);// 添加 Elasticsearch SinkparsedStream.addSink(esSinkBuilder.build());env.execute("Kafka to Elasticsearch Sink Example");}// 解析 Kafka 数据的简单 MapFunction,可以根据实际情况修改public static class KafkaDataParser implements MapFunction<String, Map<String, String>> {@Overridepublic Map<String, String> map(String value) throws Exception {// 这里假设 Kafka 中的数据是 JSON 格式// 解析数据并返回一个 Map,其中包含需要写入 Elasticsearch 的字段// 根据实际情况修改解析逻辑// 示例:{"field1": "value1", "field2": "value2"}return parseJsonToMap(value);}private Map<String, String> parseJsonToMap(String json) {// 实现 JSON 到 Map 的解析逻辑// 这里简单演示,具体实现取决于实际数据格式和字段Map<String, String> result = new HashMap<>();// 示例:{"field1": "value1", "field2": "value2"}String[] keyValuePairs = json.replaceAll("[{}\"]", "").split(",");for (String pair : keyValuePairs) {String[] entry = pair.split(":");result.put(entry[0].trim(), entry[1].trim());}return result;}}
}
文心一言的代码能力:
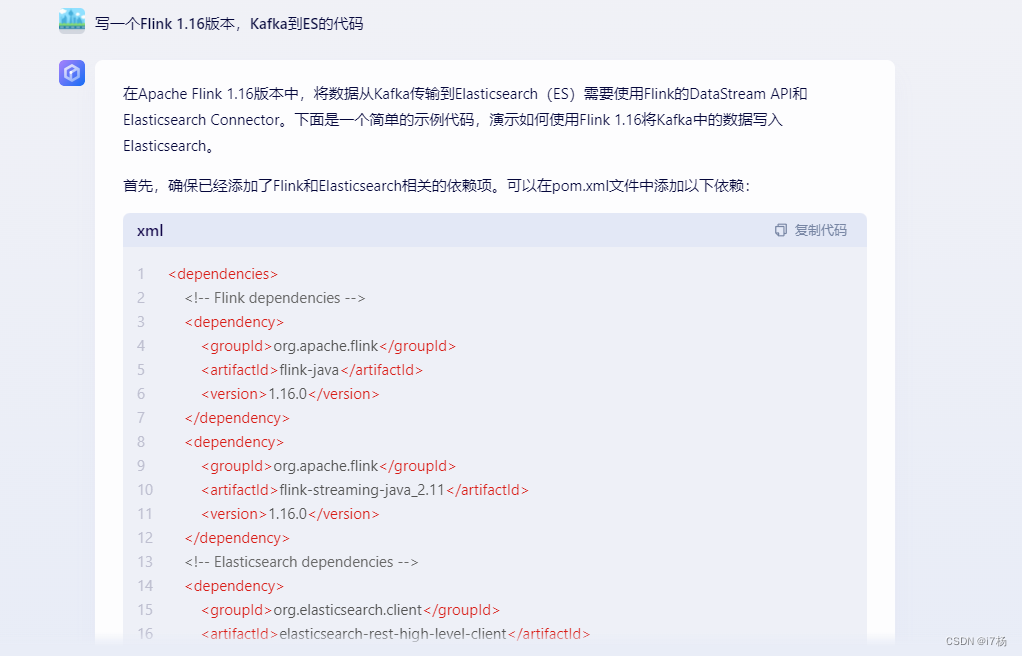
-------xml----
<dependencies> <!-- Flink dependencies --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.16.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>1.16.0</version> </dependency> <!-- Elasticsearch dependencies --> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.15.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7</artifactId> <version>1.16.0</version> </dependency>
</dependencies>----------------code-------------------------------------
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.*;
import org.apache.flink.streaming.connectors.elasticsearch.*;
import org.apache.flink.streaming.connectors.elasticsearch7.*;
import org.apache.flink.util.Collector;
import org.apache.flink.api.common.serialization.*;
import org.apache.flink.api.java.*;
import org.apache.flink.api.*;
import org.apache.flink.*;
import org.elasticsearch.*;
import org.elasticsearch.action.*;
import org.elasticsearch.client.*;
import org.elasticsearch.client.indices.*;
import org.elasticsearch.common.*;
import org.elasticsearch.common.xcontent.*;
import org.elasticsearch.rest.*;
import org.elasticsearch.transport.*;
import java.*;
import java.util.*;
import java.util.*;
import javafx.*; // for Kafka consumer group ID generation (only required if you're on Java 8u20 or earlier) public class KafkaToES { public static void main(String[] args) throws Exception { // Set up the execution environment and parameters final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 1000)); // Restart strategy for task failures and exceptions, delay between restarts in milliseconds, number of restart attempts before the job fails if exceptions occur in the tasks (optional) env.setParallelism(1); // Set parallelism for the job (optional) env.enableCheckpointing(60000); // Enable checkpointing for fault tolerance (optional) and set checkpoint interval in milliseconds (optional) env.getCheckpointConfig().setCheckpointTimeout(10000); // Set checkpoint timeout in milliseconds (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) (optional) 256MB - 1GB per TaskManager JVM heap size recommended, depending on your workload and the available memory per TaskManager machine ("node") that Flink is deployed on ("slot configuration") - https://ci-files01-prod.s
结论:两者基础的代码能力都是拥有的,准确性没有验证,但是ChatGpt代码逻辑上的准确性和表达能力优于文心一言,文心一言在代码输出的时候没有写完。
2.2.3 画图功能
chatGpt的画图能力:

文心一言的画图能力:
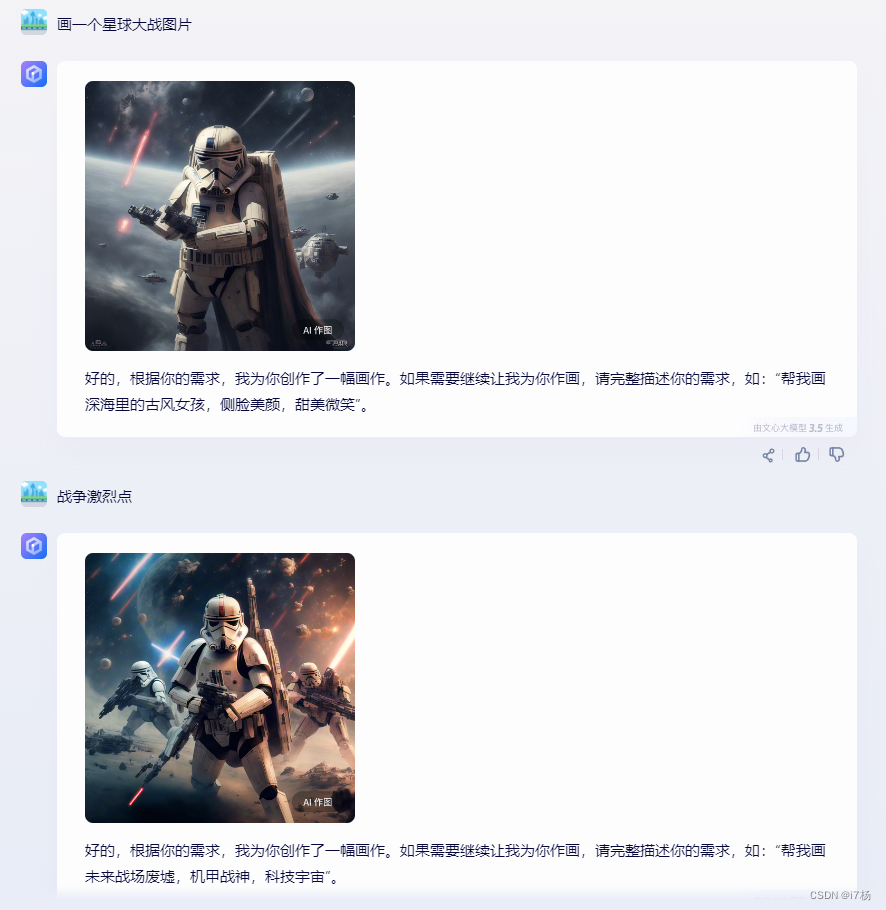
结论:ChatGpt3.5大模型没有提供画图功能,文心一言3.5大模型跨模态提供了画图功能,拥有图片的AIGC能力。
三、总结
ChatGpt和文心一言这两个产品,能免费使用的功能上:文本创作等语言理解深度和代码输出质量上,ChatGpt比文心一言更有优势;但是文心一言在AI作画上功能上是独有的;另外一个可用性上,文心一言是国内的产品,使用方便,ChatGPT需要VPN翻墙和申请ChatGPT账号,操作上麻烦点。以上是笔者分析出来的区别。