代码仓库:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
截图:
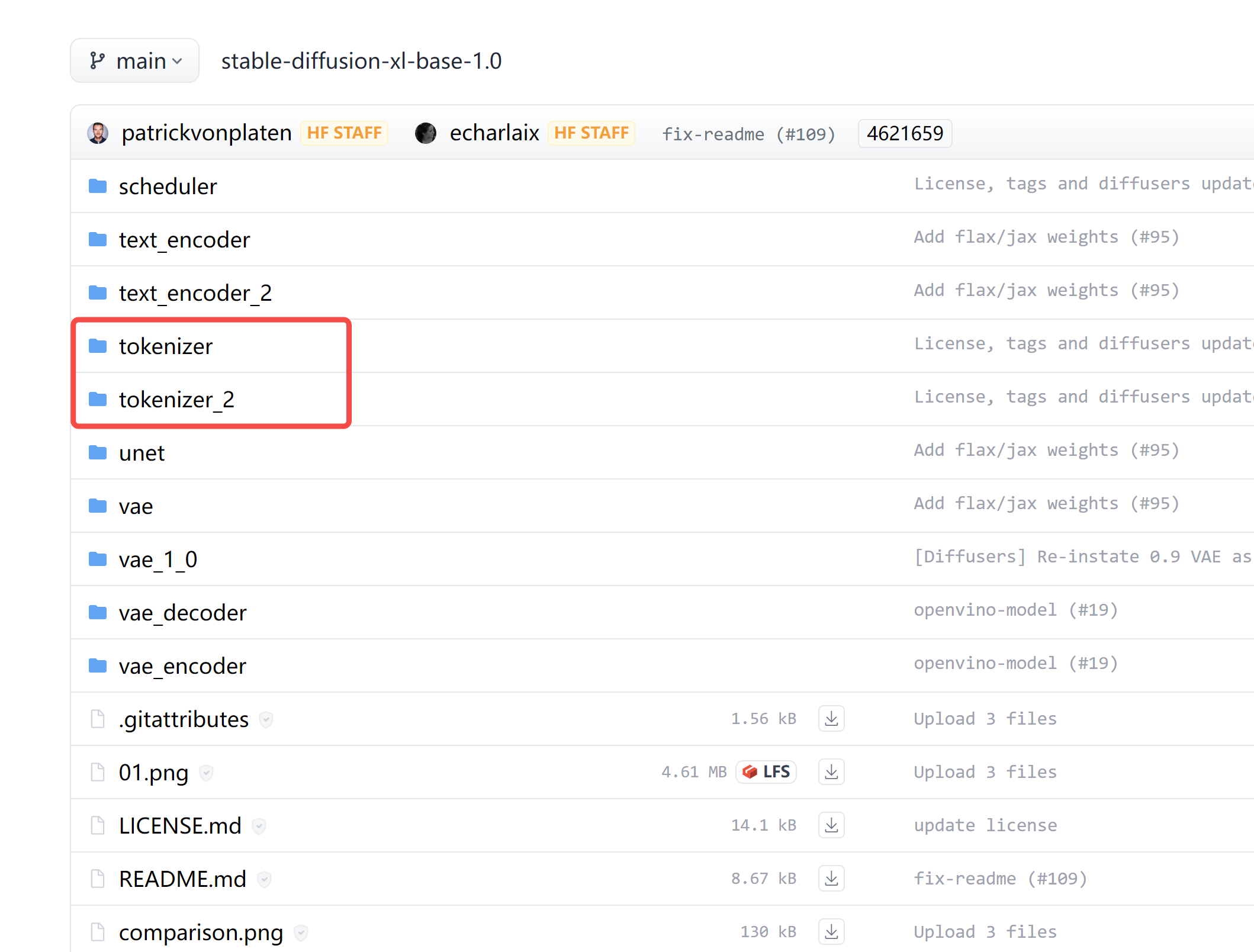
为什么有两个分词器 tokenizer 和 tokenizer_2?
在仔细阅读这些代码后,我们了解到 tokenizer_2 主要是用于 refiner 模型的。
# Load text tokenizer(s)
if not self.pipeline_type.is_sd_xl_refiner():self.tokenizer = make_tokenizer(self.version, self.pipeline_type, self.hf_token, framework_model_dir)
if self.pipeline_type.is_sd_xl():self.tokenizer2 = make_tokenizer(self.version, self.pipeline_type, self.hf_token, framework_model_dir, subfolder='tokenizer_2')
代码片段:
elif version == 'xl-1.0':if pipeline.is_sd_xl_base():return "stabilityai/stable-diffusion-xl-base-1.0"elif pipeline.is_sd_xl_refiner():return "stabilityai/stable-diffusion-xl-refiner-1.0"else:raise ValueError(f"Unsupported SDXL 1.0 pipeline {pipeline.name}")
什么是分词器?
分词器(Tokenizer)是自然语言处理(NLP)中的一种工具,其主要任务是将文本划分成更小的单元,通常是词语或子词。这些小单元被称为标记(tokens)。分词器在NLP任务中扮演着关键角色,其主要应用包括:
-
文本预处理: 在将文本输入NLP模型之前,通常需要对文本进行预处理。分词器负责将连续的文本转换成离散的标记序列,以便模型更好地理解和处理文本。
-
特征提取: 在一些NLP任务中,模型需要将文本表示为数值向量,以进行机器学习任务。分词器的作用是将文本转换成模型能理解的标记序列,然后进行嵌入(embedding)等操作,最终得到文本的数值向量表示。
-
语言模型训练: 在训练语言模型时,分词器帮助模型理解文本结构,学习单词或子词之间的关系,以及捕捉语法和语义信息。
-
机器翻译: 在机器翻译任务中,分词器有助于将源语言和目标语言的文本分别转换成标记序列,使模型能更好地理解和转换语言之间的对应关系。
-
信息检索: 在信息检索任务中,分词器有助于将用户查询或文档文本转换成可检索的标记序列,以便进行文本匹配和检索相关信息。
在NLP领域中,分词器的选择通常取决于任务的性质和语言的特点。不同的语言和任务可能需要不同类型的分词策略,包括基于词典的方法、统计方法、基于深度学习的方法等。一些流行的分词器包括基于深度学习的BERT Tokenizer、基于规则的NLTK分词器、基于统计的Stanford分词器等。