物以类聚 人以群分
文章目录
- 简介
- 为什么有设计模式?
- 设计模式七大原则
- 单一职责原则(Single Responsibility Principle - SRP)
- 开放封闭原则(Open/Closed Principle - OCP)
- 里氏替换原则(Liskov Substitution Principle - LSP)
- 依赖倒置原则(Dependency Inversion Principle - DIP)
- 接口隔离原则(Interface Segregation Principle - ISP)
- 合成/聚合复用原则(Composition/Aggregation Reuse Principle - CARP)
- 最少知道原则(Least Knowledge Principle - LKP)
- 单例模式
- 饿汉模式
- 懒汉模式
- 工厂模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 小结
- 建造者模式
- 代理模式
- 总结
简介
在软件开发领域,设计模式是一种被广泛采用的解决复杂问题的方法论。而C++作为一种强大而灵活的编程语言,也在设计模式的应用中发挥着重要作用。设计模式旨在提供一种可复用的解决方案,以解决在软件设计和开发过程中经常遇到的各种问题。这些模式并非僵硬的规则,而是灵活的指导原则,通过它们,程序员能够更加高效、优雅地构建可维护和可扩展的代码。
为什么有设计模式?
设计模式的存在源于软件开发中的一些普遍挑战,例如代码复杂性、变更管理、可维护性和可扩展性。在开发大型项目或面对复杂业务逻辑时,往往需要一种结构化的方法来组织和管理代码。设计模式提供了一套经过验证的解决方案,帮助开发人员有效地应对这些挑战。这样做的优势有如下几点:
| 优势 | 说明 |
|---|---|
| 可重用性 | 设计模式通过提供通用的解决方案,使得代码变得更加可重用。这有助于减少重复性代码,提高开发效率。 |
| 可维护性 | 使用设计模式能够使代码更加模块化和易于维护。每个模式都解决特定类型的问题,使得变更更加可控和可预测。 |
| 可扩展性 | 设计模式鼓励松耦合的设计,从而使系统更加灵活和可扩展。当需求变化时,可以更容易地引入新的功能或修改现有功能。 |
| 提高代码质量 | 应用设计模式通常会导致更清晰、更易理解的代码结构,从而提高代码的质量。这对于团队协作和后期维护都是至关重要的。 |
| 共享最佳实践 | 设计模式是经过时间验证的最佳实践的总结。通过共享这些经验和智慧,开发人员可以从中汲取经验教训,避免重复犯同样的错误。 |
设计模式在C++编程中扮演着重要的角色,为程序员提供了一种有力的工具来构建健壮、可维护的应用程序。接下来将深入探讨一些常见的C++设计模式,以及它们在实际应用中的具体应用场景和优势。
设计模式七大原则
设计模式的七大原则是在软件设计中为了编写可维护、灵活、可扩展的代码而提出的一系列指导性原则。这些原则有助于开发人员设计出更具健壮性和可维护性的系统。
| 原则 | 简介 |
|---|---|
| 单一职责原则 | 单一职责原则要求一个类应该只有一个引起变化的原因,即一个类应该只负责一个职责。这有助于使类更加简单、易于维护。 |
| 开放封闭原则 | 开放封闭原则要求软件实体(类、模块、函数等)应该对扩展开放,对修改关闭,允许系统在不修改现有代码的情况下进行功能的扩展。 |
| 里氏替换原则 | 里氏替换原则规定,所有引用基类的地方必须能够替换为其子类,即子类应该能够替代父类而不影响程序的正确性。 |
| 依赖倒置原则 | 依赖倒置原则要求高层模块不应该依赖于底层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,而细节应该依赖于抽象。 |
| 接口隔离原则 | 接口隔离原则要求客户端不应该被迫依赖于其不使用的接口,一个类不应该强迫客户端依赖于它们不需要的方法。 |
| 合成/聚合复用原则 | 合成/聚合复用原则强调多用组合/聚合,少用继承。通过合成或聚合关系,降低系统耦合性,增强系统的灵活性。 |
| 最少知道原则 | 最少知道原则要求一个对象应当对其他对象有尽可能少的了解,也就是说,一个类不应该了解太多关于其它类的内部细节。 |
这些原则共同构成了面向对象设计的基石,通过遵循这些原则,开发人员能够更好地应对变化,编写出更加稳定、可维护、可扩展的软件系统。
单一职责原则(Single Responsibility Principle - SRP)
单一职责原则要求一个类应该只有一个引起变化的原因,即一个类应该只负责一个职责。一个类承担的职责越少,它的职责就越单一,这有助于类的复用、理解和维护。单一职责原则使得类变得更加灵活,更容易进行修改和拓展。
如何遵循单一职责原则:
- 分离不同职责: 将一个类中不同的职责拆分成独立的类,每个类负责一个职责。
- 保持类的一致性: 确保每个类都遵循自己的单一职责,不要包含与其职责无关的功能。
示例:
考虑一个简单的例子,有一个Report类负责生成报告,并且需要将报告保存到文件中。一般来说,我们只需要定义一个类,然后分别定义两个方法负责生成报告和保存报告。
// 违反单一职责原则的版本
class Report {
public:void generateReport() {// 生成报告的代码}void saveToFile() {// 将报告保存到文件的代码}
};
而按照单一职责原则,我们可以将生成报告和保存到文件两个职责分开:
// 遵循单一职责原则的版本
class Report {
public:void generateReport() {// 生成报告的代码}
};class ReportSaver {
public:void saveToFile(const Report& report) {// 将报告保存到文件的代码}
};
这样,Report类专注于生成报告,而ReportSaver类专注于保存报告到文件,每个类都有一个清晰的职责。这使得代码更加模块化、易于理解和维护。
开放封闭原则(Open/Closed Principle - OCP)
开放封闭原则规定一个软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。这意味着在系统需要变化时,应该通过扩展现有代码的方式来应对,而不是修改已经存在的代码。新功能的添加应该通过增加新的代码,而不是修改现有的代码。一旦一个模块已经稳定,应该避免修改其源代码。修改可能引入新的错误或破坏原有功能。
如何遵循开放封闭原则:
- 抽象和接口: 使用抽象类、接口或者抽象函数来定义可扩展的行为。
- 模块化: 将系统划分为独立的模块,使得每个模块都可以独立扩展而不影响其他模块。
- 使用设计模式: 使用设计模式(如策略模式、观察者模式等)来实现可扩展的结构。
示例:
有一个Shape类,它有一个draw方法用于绘制形状。按照开放封闭原则,我们可以通过扩展而不是修改来添加新的形状:
#include <iostream>// 违反开放封闭原则的版本
class Shape {
public:virtual void draw() const {std::cout << "Drawing Shape" << std::endl;// 绘制形状的代码}
};class Circle : public Shape {
public:void draw() const override {std::cout << "Drawing Circle" << std::endl;// 绘制圆形的代码}
};class Square : public Shape {
public:void draw() const override {std::cout << "Drawing Square" << std::endl;// 绘制正方形的代码}
};在上述代码中,每次需要添加新的形状时,都需要修改Shape类。按照开放封闭原则,我们可以通过扩展而不是修改来实现:
#include <iostream>// 遵循开放封闭原则的版本
class Shape {
public:virtual void draw() const = 0; // 抽象类或接口
};class Circle : public Shape {
public:void draw() const override {std::cout << "Drawing Circle" << std::endl;// 绘制圆形的代码}
};class Square : public Shape {
public:void draw() const override {std::cout << "Drawing Square" << std::endl;// 绘制正方形的代码}
};class Triangle : public Shape {
public:void draw() const override {std::cout << "Drawing Triangle" << std::endl;// 绘制三角形的代码}
};int main() {Circle circle;Square square;Triangle triangle;circle.draw();square.draw();triangle.draw();return 0;
}

通过使用抽象类或接口,我们可以轻松地添加新的形状,而不需要修改现有的Shape类。这样的设计更加符合开放封闭原则,使得系统更易扩展。
里氏替换原则(Liskov Substitution Principle - LSP)
里氏替换原则由计算机科学家 Barbara Liskov 提出。该原则规定,所有引用基类的地方必须能够替换为其子类,也就是说,子类应该能够替代父类而不影响程序的正确性。子类必须能够替代父类,并且在不改变程序正确性的前提下,可以修改或扩展父类的行为。通过继承实现的子类应该保持与其基类的接口和行为一致。
如何遵循里氏替换原则:
- 保持接口一致性: 子类应该保持与父类相同的接口,即实现相同的方法和属性。
- 不破坏父类的行为: 子类可以通过扩展父类的行为,但不应该修改或破坏父类已有的行为。
- 不引入新的异常: 子类的方法不应该引发父类方法未声明的异常。
示例:
有一个 Bird 基类,其中有一个 fly 方法:
class Bird {
public:virtual void fly() {std::cout << "Flying" << std::endl;}
};
现在有一个子类 Penguin,它继承自 Bird:
class Penguin : public Bird {
public:// 重写父类的 fly 方法void fly() override {std::cout << "I can't fly" << std::endl;}
};
这里 Penguin 通过重写 fly 方法,修改了父类 Bird 的行为,但这是符合里氏替换原则的,因为在程序中可以将 Penguin 对象替换为 Bird 对象,而不会影响程序的正确性。
void makeBirdFly(Bird* bird) {bird->fly();
}int main() {Bird bird;Penguin penguin;makeBirdFly(&bird); // 输出: FlyingmakeBirdFly(&penguin); // 输出: I can't flyreturn 0;
}

通过这个例子,我们可以看到,Penguin 作为 Bird 的子类,成功地替代了 Bird,而不引起问题。这就是里氏替换原则的核心思想。
依赖倒置原则(Dependency Inversion Principle - DIP)
依赖倒置原则要求高层模块不应该依赖于底层模块,两者都应该依赖于抽象。抽象不应该依赖于细节,而细节应该依赖于抽象。
考虑一个简单的订单处理系统,其中高层模块是订单服务,底层模块是数据库访问。首先看一看违反依赖倒置原则的设计:
// 违反依赖倒置原则的版本
class OrderService {
public:void processOrder() {// 处理订单逻辑// 直接依赖于具体的数据库访问类MySQLDatabase database;database.saveOrder();}
};class MySQLDatabase {
public:void saveOrder() {// 将订单保存到MySQL数据库}
};
在这个例子中,OrderService 直接依赖于具体的 MySQLDatabase 类,违反了依赖倒置原则。现在,通过引入抽象(接口)来符合依赖倒置原则:
// 遵循依赖倒置原则的版本
class Database {
public:virtual void saveOrder() = 0;// 可以定义其他数据库操作的抽象方法virtual ~Database() = default;
};class OrderService {
public:OrderService(Database& database) : database(database) {}void processOrder() {// 处理订单逻辑// 通过抽象的Database接口进行数据库操作database.saveOrder();}private:Database& database;
};class MySQLDatabase : public Database {
public:void saveOrder() override {// 将订单保存到MySQL数据库}
};
现在,OrderService 依赖于 Database 接口,而不是直接依赖于具体的数据库实现。这样,我们可以轻松替换 MySQLDatabase 类为其他实现 Database 接口的类,而不影响 OrderService 的逻辑。这样的设计符合依赖倒置原则,使系统更加灵活和可维护。
接口隔离原则(Interface Segregation Principle - ISP)
接口隔离原则要求客户端不应该被迫依赖于其不使用的接口,一个类不应该强迫客户端依赖于它们不需要的方法。类中的方法应该是客户端需要的,而不是多余的。
例如一个Worker接口包含了work和eat两个方法,而Manager类只关心工作而不关心吃饭,如下两个版本:
// 违反接口隔离原则的版本
class Worker {
public:virtual void work() = 0;virtual void eat() = 0;// Worker 接口包含了工作和吃饭两个方法// Manager 类只关心工作,但仍然需要实现 eat 方法
};class Manager : public Worker {
public:void work() override {// 管理者的工作}void eat() override {// 管理者的吃饭}
};
在这个例子中,Worker接口包含了work和eat两个方法,而Manager类虽然只关心工作,但仍然被迫实现eat方法,违反了接口隔离原则。现在,我们通过接口隔离原则进行改进:
// 遵循接口隔离原则的版本
class Workable {
public:virtual void work() = 0;
};class Eatable {
public:virtual void eat() = 0;
};class Manager : public Workable {
public:void work() override {// 管理者的工作}
};
在这个改进后的版本中,我们将Worker接口拆分为两个独立的接口:Workable和Eatable。Manager类只需要实现Workable接口中的work方法,而不再需要实现不需要的eat方法。这样符合接口隔离原则,使得每个类只需要关心它们真正需要的接口方法。
合成/聚合复用原则(Composition/Aggregation Reuse Principle - CARP)
合成/聚合复用原则强调多用组合/聚合,少用继承。通过合成或聚合关系,降低系统耦合性,增强系统的灵活性。通过将现有的类组合成新的类,或者通过聚合将现有的对象组合在一起,实现代码的复用,而不是通过继承来获得复用。避免使用过多的继承,因为继承关系通常导致较高的耦合度和较低的灵活性。
例如一个Car类通过继承引入Engine类:
// 违反合成/聚合复用原则的版本
class Engine {
public:void start() {// 启动引擎的代码}
};class Car : public Engine {
public:void drive() {start(); // 通过继承关系调用 Engine 类的方法// 驾驶汽车的代码}
};
在这个例子中,Car类通过继承关系调用了Engine类的方法。这样的设计存在问题,因为它导致Car类与Engine类之间的高耦合度。通过合成/聚合复用原则进行改进如下:
// 遵循合成/聚合复用原则的版本
class Engine {
public:void start() {// 启动引擎的代码}
};class Car {
public:Car(Engine& engine) : _engine(engine) {}void drive() {_engine.start(); // 通过合成关系调用 Engine 类的方法// 驾驶汽车的代码}private:Engine& _engine;
};
在这个改进后的版本中,我们将Car类的行为与Engine类的实现通过合成关系连接在一起,而不是通过继承关系。现在,Car类通过构造函数接收一个Engine对象,这降低了耦合度,并使得Car类更加灵活,可以在运行时选择不同类型的引擎。这符合合成/聚合复用原则,提高了系统的灵活性。
最少知道原则(Least Knowledge Principle - LKP)
最少知道原则,也被称为迪米特法则(Law of Demeter,LoD),要求一个对象应当对其他对象有尽可能少的了解,也就是说,一个类不应该了解太多关于其它类的内部细节。一个对象(类)应该尽量减少与其它对象(类)之间的交互,只与最直接的朋友类进行通信。对于一个对象的方法调用,最好不要调用对象内部多层嵌套的方法,而应当直接调用该对象的直接成员方法。
例如一个OrderProcessor类直接与数据库进行交互:
// 违反最少知道原则的版本
class OrderProcessor {
public:void processOrder(Order& order) {// 直接与数据库交互,了解太多关于数据库的内部细节DatabaseConnector connector;connector.connect();connector.saveOrder(order);}
};class Order {};
class DatabaseConnector {
public:void connect() {// 连接到数据库的代码}void saveOrder(Order& order) {// 将订单保存到数据库的代码}
};
在这个例子中,OrderProcessor类直接与DatabaseConnector类进行交互,了解了太多关于数据库连接和保存的内部细节,违反了最少知道原则。可以通过引入一个中介类 OrderRepository 来符合最少知道原则:
// 遵循最少知道原则的版本
class OrderProcessor {
public:void processOrder(Order& order) {// 使用 OrderRepository 作为中介,减少与数据库的直接交互OrderRepository repository;repository.saveOrder(order);}
};class Order {};
class OrderRepository {
public:void saveOrder(Order& order) {// 通过 OrderRepository 连接到数据库并保存订单DatabaseConnector connector;connector.connect();connector.saveOrder(order);}
};class DatabaseConnector {
public:void connect() {// 连接到数据库的代码}void saveOrder(Order& order) {// 将订单保存到数据库的代码}
};
在这个改进后的版本中,OrderProcessor类不再直接了解数据库的内部细节,而是通过中介类 OrderRepository 进行数据库操作。这样使得每个类只需了解与其直接关联的类的细节,符合最少知道原则。
单例模式
单例模式是一种设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问该实例。单例模式有许多优点和用处,主要体现在以下方面:
| 优点 | 说明 |
|---|---|
| 唯一性保证 | 单例模式确保一个类只有一个实例。这对于那些需要在整个应用程序中共享状态或协调某些操作的情况非常有用。 |
| 统一的访问接口 | 通过单例模式,可以提供一个全局的访问点,使得其他对象能够方便地访问到该单例实例。这有助于统一管理和调用资源。 |
| 共享资源 | 单例模式可以用于共享资源,例如数据库连接、日志文件、配置文件等。通过单例模式,可以确保这些资源在整个应用程序中只有一个实例,避免资源浪费和冲突。 |
| 懒加载 | 单例模式可以延迟实例化,只有在需要时才创建实例。这在一些资源开销较大的情况下非常有用,可以提高程序的性能和效率。 |
| 避免全局变量 | 单例模式提供了一种避免使用全局变量的方法,避免了全局变量可能引发的命名冲突和不易维护性的问题。 |
| 线程安全 | 在多线程环境中,单例模式的实现可以通过加锁等方式确保线程安全,防止多个线程同时创建多个实例。 |
| 简化调用 | 单例模式使得代码调用变得简单,不需要每次都传递实例或者使用全局变量,而是通过统一的访问点获取实例。 |
饿汉模式
饿汉模式是单例模式的一种实现方式,它在程序启动时就创建单例实例,无论是否被使用。如下实例:
#include <iostream>class Singleton {
private:// 私有构造函数,防止外部实例化Singleton() {}// 私有静态成员变量,存储唯一实例static Singleton instance;public:// 获取单例实例的静态方法static Singleton& getInstance() {return instance;}// 其他成员函数void someFunction() {std::cout << "Some function of the singleton.\n";}
};// 初始化静态成员变量
Singleton Singleton::instance;int main() {// 获取单例实例Singleton& singleton = Singleton::getInstance();// 使用单例实例的函数singleton.someFunction();return 0;
}

在饿汉模式中,单例实例在程序启动时就已经创建好了。这通过将实例定义为类的静态成员变量,并在类外初始化的方式实现。因此,无论何时调用 getInstance 方法,都会返回同一个实例。
优点:
- 线程安全:在多线程环境中,由于实例在程序启动时就已经创建,因此不需要担心多个线程同时创建实例的问题。
缺点:
- 资源浪费:如果实例在整个程序生命周期中都没有被使用,那么在程序启动时就创建实例可能会造成资源浪费。
- 不支持懒加载:由于实例在程序启动时就被创建,饿汉模式不支持懒加载,可能会增加程序启动时间。
饿汉模式适用于那些实例在程序生命周期内始终需要被使用的情况。如果资源消耗较小,且需要在程序启动时就进行一些初始化操作,饿汉模式是一个简单而有效的选择。
懒汉模式
懒汉模式是单例模式的另一种实现方式,它在首次使用时才创建单例实例。如下:
#include <iostream>class LazySingleton {
private:// 私有构造函数,防止外部实例化LazySingleton() {}public:// 获取单例实例的静态方法static LazySingleton& getInstance() {// 私有静态成员变量,存储唯一实例static LazySingleton _instance;return _instance;}// 其他成员函数void someFunction() {std::cout << "other function running.....\n";}
};int main() {// 获取单例实例LazySingleton& singleton1 = LazySingleton::getInstance();LazySingleton& singleton2 = LazySingleton::getInstance();// 输出是否为同一个实例std::cout << "singleton1 == singleton2? " << (&singleton1 == &singleton2 ? "Yes" : "No") << "\n";// 使用单例实例的函数singleton1.someFunction();return 0;
}

在懒汉模式中,单例实例在首次调用 getInstance 方法时创建。
优点:
- 资源延迟分配:在首次使用时才创建实例,避免了在程序启动时就分配资源的情况,降低了资源浪费。
- 支持懒加载:只有在需要时才创建实例,支持懒加载。
缺点:
- 线程不安全:如果在多线程环境中,多个线程同时调用
getInstance方法,可能会导致创建多个实例。为了解决这个问题,可以在getInstance方法中加入线程安全的措施,比如加锁。
懒汉模式适用于那些实例在程序运行过程中可能不会一直被使用,可以等到真正需要使用时再进行初始化。需要注意线程安全性,如果在多线程环境中使用,可以考虑使用一些同步机制来保证线程安全。
总体而言,单例模式是一种设计模式,它提供了一种确保类只有一个实例,并提供全局访问点的机制。这有助于在应用程序中更好地管理和共享资源,同时提高了代码的可维护性和可读性。然而,过度使用单例模式可能会导致全局状态过多,应该根据具体情况慎重选择使用。
工厂模式
工厂模式是一种创建型设计模式,旨在提供一个接口,让子类决定实例化哪个类。这样可以将类的实例化延迟到子类,从而实现解耦合。工厂模式包括简单工厂模式、工厂方法模式和抽象工厂模式。
简单工厂模式
简单工厂模式是工厂模式的一种,它提供了一个单一的工厂类,根据传入的参数决定创建哪种产品类的实例。简单工厂模式的主要目的是将对象的实例化过程封装起来,使得客户端代码无需关心对象的具体创建细节。
其关键组成部分如下:
-
抽象产品类(Abstract Product):
- 定义了产品的接口,具体产品类实现这个接口。
-
具体产品类(Concrete Product):
- 实现了抽象产品类定义的接口。
-
工厂类(Simple Factory):
- 负责根据客户端的需求创建具体的产品类实例。包含一个静态方法,通过传入的参数来决定创建哪种产品。
示例代码:
#include <iostream>// 抽象产品类
class Product {
public:virtual void display() = 0;
};// 具体产品类A
class ConcreteProductA : public Product {
public:void display() override {std::cout << "Product A\n";}
};// 具体产品类B
class ConcreteProductB : public Product {
public:void display() override {std::cout << "Product B\n";}
};// 简单工厂类
class SimpleFactory {
public:// 根据参数创建不同的产品实例static Product* createProduct(char productType) {if (productType == 'A') {return new ConcreteProductA();} else if (productType == 'B') {return new ConcreteProductB();}return nullptr;}
};int main() {// 使用简单工厂创建产品实例Product* productA = SimpleFactory::createProduct('A');Product* productB = SimpleFactory::createProduct('B');// 使用产品实例productA->display();productB->display();// 释放内存delete productA;delete productB;return 0;
}

在这个示例中,Product 是抽象产品类,ConcreteProductA 和 ConcreteProductB 是具体产品类,它们都实现了 Product 定义的接口。SimpleFactory 是简单工厂类,通过静态方法 createProduct 根据传入的参数来创建不同的产品实例。
优点:
- 封装了对象的创建过程,使客户端代码更加简洁,无需了解具体的创建细节。
- 对象的创建和使用分离,降低了客户端代码对具体产品类的依赖。
缺点:
- 增加新产品需要修改工厂类的代码,不符合开闭原则,不够灵活。
- 工厂类的职责相对较多,不够符合单一职责原则。
工厂方法模式
工厂方法模式定义一个用于创建对象的接口,但是由子类决定要实例化的类是哪一个。这样,工厂方法模式使得一个类的实例化延迟到其子类。
关键组成部分:
-
抽象产品类(Product):
- 定义产品的接口,具体产品类实现这个接口。
-
具体产品类(Concrete Product):
- 实现了抽象产品类定义的接口。
-
抽象工厂类(Factory):
- 声明一个工厂方法(Factory Method),用于创建产品的抽象接口。
-
具体工厂类(Concrete Factory):
- 实现抽象工厂类,负责创建具体的产品对象。
示例代码:
#include <iostream>// 抽象产品类
class Product {
public:virtual void display() = 0;
};// 具体产品类A
class ConcreteProductA : public Product {
public:void display() override {std::cout << "Product A\n";}
};// 具体产品类B
class ConcreteProductB : public Product {
public:void display() override {std::cout << "Product B\n";}
};// 抽象工厂类
class Factory {
public:// 工厂方法,用于创建产品virtual Product* createProduct() = 0;
};// 具体工厂类A
class ConcreteFactoryA : public Factory {
public:Product* createProduct() override {return new ConcreteProductA();}
};// 具体工厂类B
class ConcreteFactoryB : public Factory {
public:Product* createProduct() override {return new ConcreteProductB();}
};int main() {// 使用具体工厂创建产品实例Factory* factoryA = new ConcreteFactoryA();Factory* factoryB = new ConcreteFactoryB();Product* productA = factoryA->createProduct();Product* productB = factoryB->createProduct();// 使用产品实例productA->display();productB->display();// 释放内存delete factoryA;delete factoryB;delete productA;delete productB;return 0;
}

在这个示例中,Product 是抽象产品类,ConcreteProductA 和 ConcreteProductB 是具体产品类,它们都实现了 Product 定义的接口。Factory 是抽象工厂类,其中声明了一个工厂方法 createProduct,具体工厂类 ConcreteFactoryA 和 ConcreteFactoryB 分别实现了这个工厂方法,负责创建具体的产品对象。
优点:
- 将对象的创建过程推迟到子类,符合开闭原则,易于扩展。
- 客户端代码只依赖于抽象工厂和抽象产品,不依赖于具体实现,降低了耦合性。
缺点:
- 类的数量增多,增加了系统的复杂度。
- 每次新增产品都需要增加具体工厂类和具体产品类,不够灵活。
工厂方法模式适用于产品族的情况,即需要创建一系列相关或依赖的产品。如果系统中只有一个产品等级结构,可以考虑使用简单工厂模式。
抽象工厂模式
抽象工厂模式提供了一个接口用于创建一系列相关或依赖的对象,而无需指定它们的具体类。抽象工厂模式将一组相关的产品组合成一个工厂,客户端代码通过抽象接口使用这个工厂,而不需要关心具体产品的创建过程。
关键组成部分:
-
抽象产品A类和抽象产品B类:
- 定义产品的接口,具体产品类实现这个接口。
-
具体产品A1、A2类和具体产品B1、B2类:
- 实现了抽象产品A类和抽象产品B类定义的接口。
-
抽象工厂类:
- 声明一组创建产品的抽象方法,通常有多个方法对应一个产品族的创建。
-
具体工厂类:
- 实现抽象工厂类的抽象方法,负责创建具体产品对象,通常对应一个产品族。
示例代码:
#include <iostream>// 抽象产品A类
class AbstractProductA {
public:virtual void display() = 0;
};// 具体产品A1类
class ConcreteProductA1 : public AbstractProductA {
public:void display() override {std::cout << "Product A1\n";}
};// 具体产品A2类
class ConcreteProductA2 : public AbstractProductA {
public:void display() override {std::cout << "Product A2\n";}
};// 抽象产品B类
class AbstractProductB {
public:virtual void display() = 0;
};// 具体产品B1类
class ConcreteProductB1 : public AbstractProductB {
public:void display() override {std::cout << "Product B1\n";}
};// 具体产品B2类
class ConcreteProductB2 : public AbstractProductB {
public:void display() override {std::cout << "Product B2\n";}
};// 抽象工厂类
class AbstractFactory {
public:virtual AbstractProductA* createProductA() = 0;virtual AbstractProductB* createProductB() = 0;
};// 具体工厂1类
class ConcreteFactory1 : public AbstractFactory {
public:AbstractProductA* createProductA() override {return new ConcreteProductA1();}AbstractProductB* createProductB() override {return new ConcreteProductB1();}
};// 具体工厂2类
class ConcreteFactory2 : public AbstractFactory {
public:AbstractProductA* createProductA() override {return new ConcreteProductA2();}AbstractProductB* createProductB() override {return new ConcreteProductB2();}
};int main() {// 使用抽象工厂创建产品实例AbstractFactory* factory1 = new ConcreteFactory1();AbstractFactory* factory2 = new ConcreteFactory2();AbstractProductA* productA1 = factory1->createProductA();AbstractProductB* productB1 = factory1->createProductB();AbstractProductA* productA2 = factory2->createProductA();AbstractProductB* productB2 = factory2->createProductB();// 使用产品实例productA1->display();productB1->display();productA2->display();productB2->display();// 释放内存delete factory1;delete factory2;delete productA1;delete productB1;delete productA2;delete productB2;return 0;
}
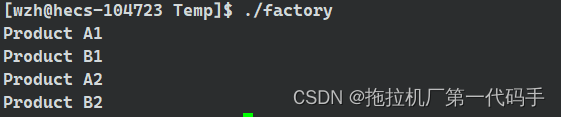
在这个示例中,AbstractProductA 和 AbstractProductB 是抽象产品类,ConcreteProductA1、ConcreteProductA2、ConcreteProductB1 和 ConcreteProductB2 是具体产品类,它们都实现了对应的抽象产品接口。AbstractFactory 是抽象工厂类,其中声明了一组抽象方法,每个方法用于创建一个具体产品对象。ConcreteFactory1 和 ConcreteFactory2 是具体工厂类,分别实现了这组抽象方法,负责创建具体产品对象。
优点:
- 将一组相关或依赖的产品组合在一起创建,保证了产品之间的一致性。
- 客户端代码通过抽象接口使用工厂和产品,不依赖具体的实现,降低了耦合性。
- 符合开闭原则,易于扩展。
缺点:
- 增加新产品族需要新增一组抽象产品类和对应的具体产品类,不够灵活。
小结
- 当对象的创建过程比较复杂,包括多个步骤或者依赖于其他对象时,使用工厂模式可以将创建过程封装在工厂类中,使得客户端代码更加简洁。
- 当对象的创建需要满足一些特定条件或者约束时,工厂模式可以在工厂类中进行处理,以确保创建的对象满足特定的要求。
- 当有多个类似的对象需要创建时,工厂模式可以提供一种灵活的方式来实现对象的创建和管理,提高代码的复用性。
- 工厂模式可以降低系统中各个类之间的耦合性,客户端代码只需要知道工厂接口和产品接口,而不需要知道具体的实现类。
- 当类的实例化不是在编译时确定的,而是在运行时根据某些条件或者配置文件动态决定时,工厂模式非常有用。
| 优点 | 说明 |
|---|---|
| 封装性好 | 工厂模式将对象的创建过程封装在工厂类中,客户端代码只需要关心工厂接口和产品接口,而不需要了解具体的实现细节。 |
| 代码解耦 | 工厂模式可以降低系统中各个类之间的耦合性,使得系统更加灵活和易于维护。 |
| 易于扩展 | 当需要新增一种产品或者更改某个产品的创建过程时,只需要修改对应的工厂类,而不会影响到其他部分的代码,符合开闭原则。 |
| 符合单一职责原则 | 工厂模式将对象的创建过程集中在一个工厂类中,每个工厂类负责创建一种产品,符合单一职责原则。 |
| 提高代码复用性 | 工厂模式提供了一种灵活的方式来管理对象的创建过程,使得相似的对象可以通过相同的方式进行创建,提高了代码的复用性。 |
总的来说,工厂模式在需要创建多个相似对象、对象创建复杂、需要根据条件动态选择创建对象等场景下,是一种非常有用的设计模式。
建造者模式
建造者模式(Builder Pattern)是一种创建型设计模式,它的主要目的是将一个复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。这样,通过不同的具体建造者,可以构建出不同表示的对象。
关键组成部分:
-
产品类(Product):
- 定义了需要构建的复杂对象。
-
抽象建造者类(Builder):
- 声明了产品的构建过程中各个部分的抽象方法。
-
具体建造者类(Concrete Builder):
- 实现了抽象建造者类,负责具体产品的构建过程。
-
指挥者类(Director):
- 负责调用建造者的方法来构建产品,不涉及具体产品的信息。
示例代码:
#include <iostream>
#include <string>// 产品类
class Product {
public:void setPartA(const std::string& partA) {partA_ = partA;}void setPartB(const std::string& partB) {partB_ = partB;}void setPartC(const std::string& partC) {partC_ = partC;}void display() const {std::cout << "Part A: " << partA_ << "\n";std::cout << "Part B: " << partB_ << "\n";std::cout << "Part C: " << partC_ << "\n";}private:std::string partA_;std::string partB_;std::string partC_;
};// 抽象建造者类
class Builder {
public:virtual void buildPartA() = 0;virtual void buildPartB() = 0;virtual void buildPartC() = 0;virtual Product getResult() = 0;
};// 具体建造者类A
class ConcreteBuilderA : public Builder {
public:void buildPartA() override {product_.setPartA("A1");}void buildPartB() override {product_.setPartB("B1");}void buildPartC() override {product_.setPartC("C1");}Product getResult() override {return product_;}private:Product product_;
};// 具体建造者类B
class ConcreteBuilderB : public Builder {
public:void buildPartA() override {product_.setPartA("A2");}void buildPartB() override {product_.setPartB("B2");}void buildPartC() override {product_.setPartC("C2");}Product getResult() override {return product_;}private:Product product_;
};// 指挥者类
class Director {
public:Director(Builder* builder) : builder_(builder) {}void construct() {builder_->buildPartA();builder_->buildPartB();builder_->buildPartC();}private:Builder* builder_;
};int main() {// 使用建造者模式构建产品ConcreteBuilderA builderA;ConcreteBuilderB builderB;Director directorA(&builderA);directorA.construct();Product productA = builderA.getResult();Director directorB(&builderB);directorB.construct();Product productB = builderB.getResult();// 显示产品信息std::cout << "Product A:\n";productA.display();std::cout << "\n";std::cout << "Product B:\n";productB.display();return 0;
}

在这个示例中,Product 是需要构建的复杂对象,Builder 是抽象建造者类,声明了产品的构建过程中各个部分的抽象方法。ConcreteBuilderA 和 ConcreteBuilderB 是具体建造者类,实现了 Builder 定义的抽象方法,负责具体产品的构建过程。Director 是指挥者类,负责调用建造者的方法来构建产品,不涉及具体产品的信息。
优点:
- 将一个复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。
- 客户端代码无需关心产品的构建过程和组成部分,只需使用指挥者和具体建造者即可。
缺点:
- 如果产品的构建过程相对简单,使用建造者模式可能会显得过于繁琐。此时可以考虑使用简单工厂模式或者工厂方法模式。
代理模式
代理模式(Proxy Pattern)是一种结构型设计模式,其目的是为其他对象提供一个代理或者占位符,以控制对这个对象的访问。在代理模式中,有三个主要角色:
-
抽象主题(Subject):
- 定义了代理类和真实主题类的共同接口,客户端通过这个接口访问真实主题。
-
真实主题(Real Subject):
- 实现了抽象主题接口,定义了真实对象的具体操作。
-
代理(Proxy):
- 实现了抽象主题接口,维护了一个指向真实主题的引用,同时可以控制对真实主题的访问。
代理模式可以分为静态代理和动态代理两种实现方式。静态代理需要在编译期间确定代理类和真实类的关系,而动态代理则是在运行时动态生成代理类。
静态代理示例代码:
#include <iostream>// 抽象主题
class Subject {
public:virtual void request() = 0;
};// 真实主题
class RealSubject : public Subject {
public:void request() override {std::cout << "RealSubject: Handling request.\n";}
};// 代理
class Proxy : public Subject {
private:RealSubject* realSubject_;public:Proxy(RealSubject* realSubject) : realSubject_(realSubject) {}void request() override {std::cout << "Proxy: Logging before requesting.\n";realSubject_->request();std::cout << "Proxy: Logging after requesting.\n";}
};int main() {RealSubject* realSubject = new RealSubject();Proxy* proxy = new Proxy(realSubject);proxy->request();delete realSubject;delete proxy;return 0;
}

在这个示例中,Subject 是抽象主题,定义了真实主题和代理类的共同接口。RealSubject 是真实主题,实现了 Subject 定义的接口,定义了真实对象的具体操作。Proxy 是代理类,也实现了 Subject 定义的接口,维护了一个指向真实主题的引用,在调用真实主题的操作前后可以添加额外的逻辑。
优点:
- 可以在客户端和真实主题之间加入中间层,提供额外的功能,比如权限控制、缓存、日志记录等。
- 可以实现对真实主题的远程访问、延迟加载等。
缺点:
- 会增加系统的复杂度,引入了额外的代理类。
代理模式适用于需要在访问对象时添加额外功能的情况,以及需要控制对对象的访问权限的情况。
总结
在本文中,我们深入探讨了设计模式的七大原则以及介绍了四个重要的设计模式,这些原则和设计模式为软件开发提供了强有力的指导,帮助我们设计出结构清晰、可维护、可扩展、松耦合的系统。通过遵循这些原则,我们能够更好地面对变化、提高代码的复用性,并在项目中应对复杂性。
这些原则和设计模式是面向对象设计的基石,它们的应用使得软件系统更易于维护、扩展,提高了系统的可读性和可维护性。通过灵活运用这些原则和设计模式,我们能够更好地应对软件开发中的各种挑战,创造出高质量、可靠性强的软件系统。
最后,如果文章对你有所帮助的话,不妨点上一个小小的👍,感谢支持!