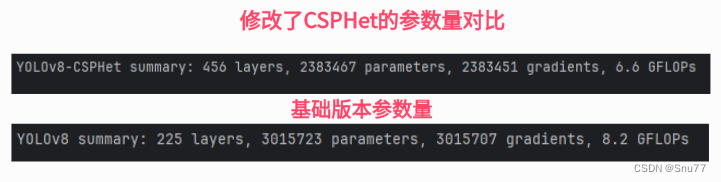
【深度学习:开源BERT】 用于自然语言处理的最先进的预训练
- 是什么让 BERT 与众不同?
- 双向性的优势
- 使用云 TPU 进行训练
- BERT 结果
- 让 BERT 为您所用
自然语言处理 (NLP) 面临的最大挑战之一是训练数据的短缺。由于 NLP 是一个具有许多不同任务的多元化领域,因此大多数特定于任务的数据集仅包含几千或几十万个人工标记的训练样本。然而,基于深度学习的现代 NLP 模型可以从大量数据中获益,当在数百万或数十亿个带注释的训练样本上进行训练时,这些模型会有所改善。为了帮助缩小这一数据差距,研究人员开发了多种技术,用于使用网络上大量未注释的文本(称为预训练)来训练通用语言表示模型。然后,可以对小数据 NLP 任务(如问答和情感分析)对预训练模型进行微调,与从头开始训练这些数据集相比,准确性有了实质性的提高。
本周,我们开源了一种用于 NLP 预训练的新技术,称为 Bidirectional Encoder Representations from Transformers 或 BERT。在此版本中,世界上任何人都可以在大约 30 分钟内在单个 Cloud TPU 上训练自己的先进问答系统(或各种其他模型),或者使用单个 GPU 在几个小时内训练自己的先进问答系统。该版本包括基于 TensorFlow 构建的源代码和许多预训练的语言表示模型。在我们的相关论文中,我们展示了 11 个 NLP 任务的最新结果,包括极具竞争力的斯坦福问答数据集 (SQuAD v1.1)。
是什么让 BERT 与众不同?
BERT 建立在训练前上下文表示的最新工作之上,包括半监督序列学习、生成式预训练、ELMo 和 ULMFit。然而,与这些以前的模型不同,BERT是第一个深度双向、无监督的语言表示,仅使用纯文本语料库(在本例中为维基百科)进行预训练。
为什么这很重要?预训练的表示可以是无上下文的,也可以是上下文的,上下文表示可以是单向的或双向的。word2vec 或 GloVe 等上下文无关模型为词汇表中的每个单词生成单个单词嵌入表示。例如,“bank”一词在“bank account”和“bank of the river”中具有相同的上下文无关表示形式。相反,上下文模型会根据句子中的其他单词生成每个单词的表示形式。例如,在句子“我访问了银行帐户”中,单向上下文模型将基于“我访问了”而不是“帐户”来表示“银行”。然而,BERT 使用其前一个和下一个上下文来表示“银行”——“我访问了…account“——从深度神经网络的最底层开始,使其深度双向。
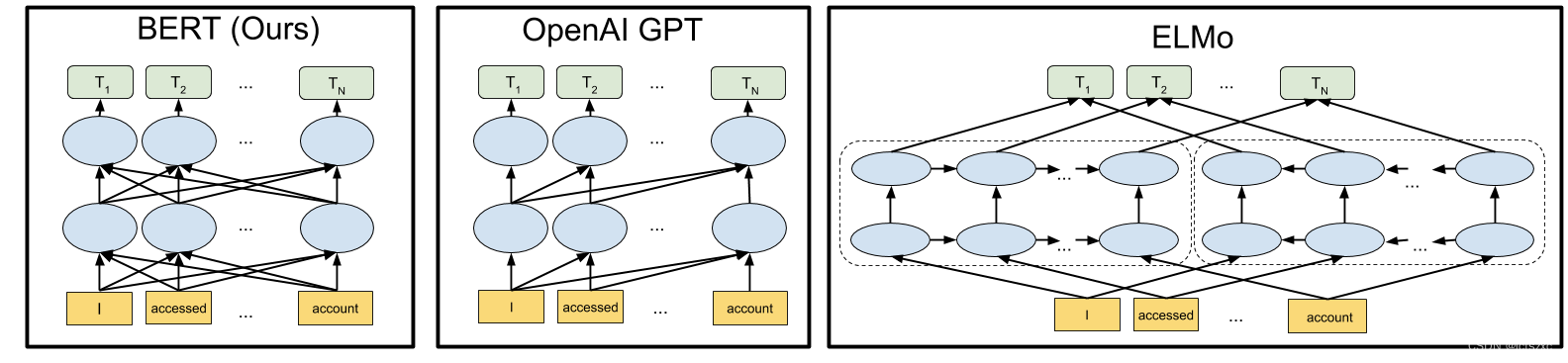
BERT的神经网络架构与以前最先进的上下文预训练方法相比的可视化如下所示。箭头表示从一层到下一层的信息流。顶部的绿色框表示每个输入词的最终上下文表示:
双向性的优势
如果双向性如此强大,为什么以前没有做过?要理解原因,请考虑通过预测句子中前面单词的每个单词来有效地训练单向模型。但是,不可能通过简单地将每个单词调整为前一个和下一个单词来训练双向模型,因为这将允许被预测的单词在多层模型中间接地“看到自己”。
为了解决这个问题,我们使用简单的技术,将输入中的一些单词屏蔽掉,然后双向调节每个单词以预测被屏蔽的单词。例如:
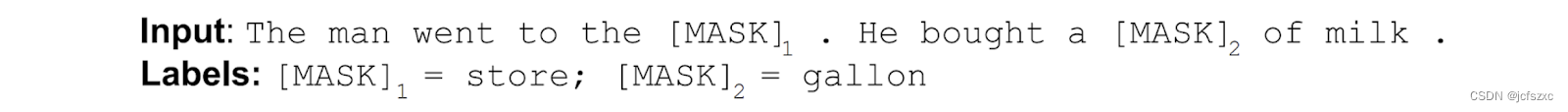
虽然这个想法已经存在很长时间了,但 BERT 是第一次成功地将其用于预训练深度神经网络。
BERT 还通过预训练一个非常简单的任务来学习建模句子之间的关系,该任务可以从任何文本语料库生成:给定两个句子 A 和 B,B 是语料库中 A 之后的实际下一个句子,还是只是一个随机句子?例如:

使用云 TPU 进行训练
到目前为止我们所描述的一切似乎都相当简单,那么它缺少什么让它工作得这么好呢?云 TPU。云 TPU 使我们能够自由地快速实验、调试和调整我们的模型,这对于我们超越现有的预训练技术至关重要。 Google 研究人员于 2017 年开发的 Transformer 模型架构也为我们奠定了 BERT 成功所需的基础。 Transformer 在我们的开源版本以及tensor2tensor 库中实现。
BERT 结果
为了评估性能,我们将 BERT 与其他最先进的 NLP 系统进行了比较。重要的是,BERT 取得了所有成果,几乎没有对神经网络架构进行任何针对特定任务的更改。在 SQuAD v1.1 上,BERT 达到了 93.2% 的 F1 分数(准确度衡量标准),超过了之前 91.6% 的最先进分数和 91.2% 的人类水平分数:
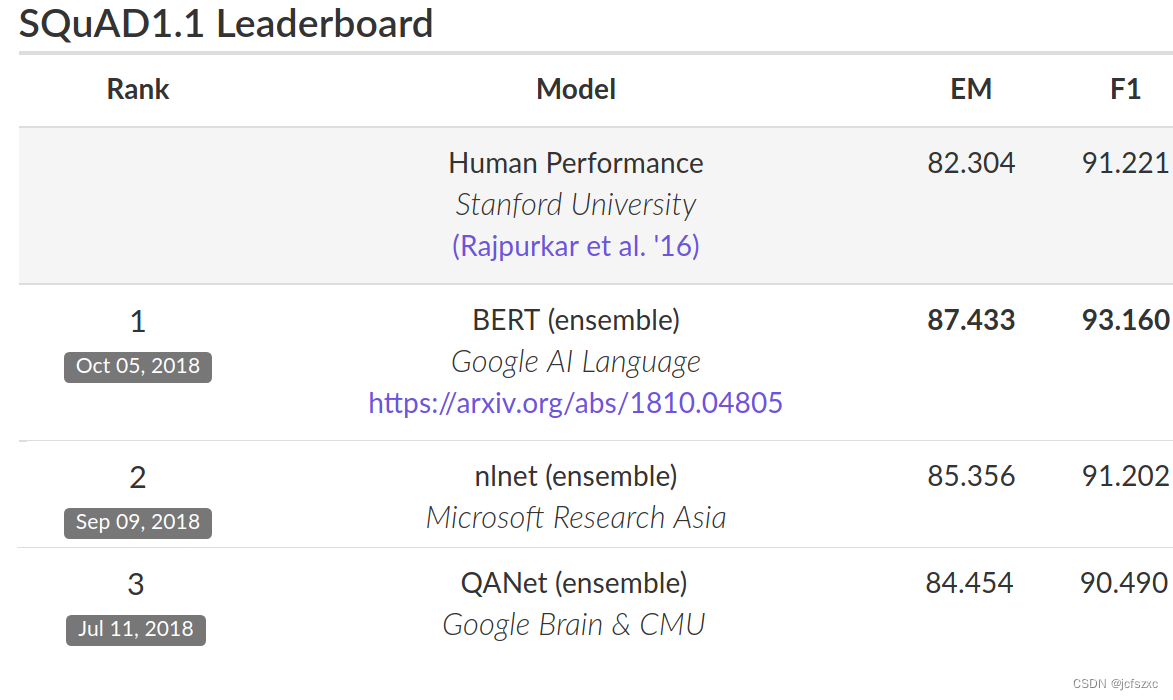
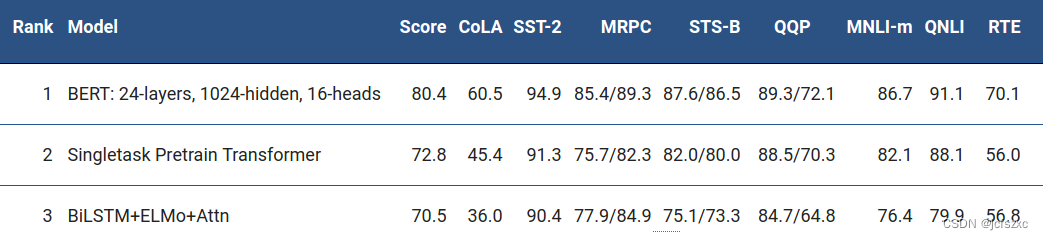
BERT 还在极具挑战性的 GLUE 基准测试(一组 9 个不同的自然语言理解 (NLU) 任务)上将最先进的技术提高了 7.6% 的绝对值。在这些任务中,人工标记的训练数据量从 2,500 个样本到 400,000 个样本不等,BERT 大大提高了所有这些任务的最新准确性:
#
让 BERT 为您所用
我们发布的模型可以在几个小时或更短的时间内对各种 NLP 任务进行微调。开源版本还包括运行预训练的代码,尽管我们相信大多数使用 BERT 的 NLP 研究人员永远不需要从头开始预训练自己的模型。我们今天发布的 BERT 模型是纯英语的,但我们希望在不久的将来发布已经过各种语言预训练的模型。
开源 TensorFlow 实现和指向预训练 BERT 模型的指针可在 http://goo.gl/language/bert 中找到。或者,您可以通过 Colab 的笔记本“BERT FineTuning with Cloud TPU”开始使用 BERT。
您还可以阅读我们的论文“BERT:用于语言理解的深度双向变压器的预训练”了解更多详细信息。