paper:Paraphrasing Complex Network: Network Compression via Factor Transfer
official implementation:https://github.com/Jangho-Kim/Factor-Transfer-pytorch
背景
尽管现有的知识蒸馏方法如KD、FitNet等带来了性能的改善,但直接传递教师的输出忽略了教师和学生之间的内在差异,如网络结构、通道数量、初始条件等。因此,我们需要重新解释教师网络的输出来解决这些差异。例如,从老师和学生的角度来看,对于一个问题,直接给出老师的知识而不做任何解释对教学生来说是不够的。换句话说,在教孩子时,老师不应该使用她自己的术语,因为孩子不能理解它。另一方面,如果老师把自己的术语翻译成更简单的术语,孩子会更容易理解。
本文的创新点
本文提出了一种知识蒸馏方法,使得教师和学生都能生成更容易传递的知识,文中称为“factor”。和传统的方法不一样,该方法不是仅仅直接比较网络的输出,而是训练一个神经网络可以提取好的factor并匹配这些factor。从教师网络中提取factor的网络称为paraphraser,从学生网络提取factor的网络称为translator。paraphraser以无监督的方式训练,期望它提取不同于有监督损失可以获得的知识。translator和学生网络一同训练用来吸收paraphraser从教师网络提取的factor。
方法介绍

Paraphraser
paraphraser通过几个卷积层来得到教师的factor \(F_{T}\),并在训练阶段被一些转置的卷积层进一步处理。大多数卷积自动编码器autoencoder的设计都进行了降采样,从而增加感受野。相反,paraphraser在调整factor通道数量的同时保持空间维度大小,因为它使用了最后一组的特征图,它的特征图已经足够小了。如果教师网络产生m个特征图,我们将factor通道的数量调整为m×k。我们把超参k称为paraphraser rate。
无监督训练paraphraser的reconstruction loss如下
![]()
其中paraphraser网络 \(P(\cdot)\) 以 \(x\) 为输入。
Translator
如图1所示,在训练学生网络时,在学生网络最后一组卷积层的后面插入translator,并与学生网络一起训练。这里translator起到一个buffer的作用,通过重新表述学生网络的特征图,减轻了学生网络直接学习教师网络输出的负担。
学生网络的训练包含两个损失,分类loss和factor transfer loss,如下

其中 \(F_{T},F_{S}\) 分别表示教师和学生的factor。因为使用 \(l_{1}(p=1)\) 损失和 \(l_{2}(p=2)\) 损失的差异不大,后续所有实验都是用 \(l_{1}\) 损失。\(\beta\) 是权重参数,\(C(S(I_{x}),y)\) 表示ground truth \(y\) 和网络softmax输出 \(S(I_{x})\) 之间的交叉熵损失。
代码解析
paraphraser的代码如下,mode=0为无监督训练模式,包含三个卷积和三个转置卷积,步长都为1。
class Paraphraser(nn.Module):def __init__(self, in_planes, planes, stride=1):super(Paraphraser, self).__init__()self.leakyrelu = nn.LeakyReLU(0.1)# self.bn0 = nn.BatchNorm2d(in_planes)self.conv0 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn1 = nn.BatchNorm2d(planes)self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn2 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn0_de = nn.BatchNorm2d(planes)self.deconv0 = nn.ConvTranspose2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn1_de = nn.BatchNorm2d(in_planes)self.deconv1 = nn.ConvTranspose2d(planes, in_planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn2_de = nn.BatchNorm2d(in_planes)self.deconv2 = nn.ConvTranspose2d(in_planes, in_planes, kernel_size=3, stride=1, padding=1, bias=True)# ### Mode 0 - throw encoder and decoder (reconstruction)# ### Mode 1 - extracting teacher factorsdef forward(self, x, mode):if mode == 0:# encoderout = self.leakyrelu((self.conv0(x)))out = self.leakyrelu((self.conv1(out)))out = self.leakyrelu((self.conv2(out)))# decoderout = self.leakyrelu((self.deconv0(out)))out = self.leakyrelu((self.deconv1(out)))out = self.leakyrelu((self.deconv2(out)))if mode == 1:out = self.leakyrelu((self.conv0(x)))out = self.leakyrelu((self.conv1(out)))out = self.leakyrelu((self.conv2(out)))# only throw decoderif mode == 2:out = self.leakyrelu((self.deconv0(x)))out = self.leakyrelu((self.deconv1(out)))out = self.leakyrelu((self.deconv2(out)))return out训练paraphraser时前面的网络和教师网络是一致的,在最后一组卷积后面添加paraphraser。训练的代码如下,其中model就是教师网络,outputs[2]为教师网络最后一组卷积的输出,module为paraphraser,criterion为nn.L1Loss()。
outputs = model(inputs)
# reconstructed feature maps (Mode 0; see FeatureProjection.py)
output_p = module(outputs[2], 0)
loss = criterion(output_p, outputs[2].detach())translator的代码如下,只包含三个卷积
class Translator(nn.Module):def __init__(self, in_planes, planes, stride=1):super(Translator, self).__init__()self.leakyrelu = nn.LeakyReLU(0.1)# self.bn0 = nn.BatchNorm2d(in_planes)self.conv0 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn1 = nn.BatchNorm2d(planes)self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=1, padding=1, bias=True)# self.bn2 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=True)def forward(self, x):out = self.leakyrelu((self.conv0(x)))out = self.leakyrelu((self.conv1(out)))out = self.leakyrelu((self.conv2(out)))return out在蒸馏下训练学生网络的代码如下,teacher和student分别是教师和学生网络,输出都取最后一组卷积的输出。module_t和module_s分别是paraphraser和translator,这里mode=1,从上面paraphraser的代码可以看出mode=1时只经过前面三层卷积。最后cricriterion=nn.L1Loss(),criterion_CE=nn.CrossEntropyLoss()。
teacher_outputs = teacher(inputs)
student_outputs = student(inputs)factor_t = module_t(teacher_outputs[2], 1)
factor_s = module_s(student_outputs[2])loss = BETA * (criterion(utils.FT(factor_s), utils.FT(factor_t.detach()))) + criterion_CE(student_outputs[3], targets)实验结果
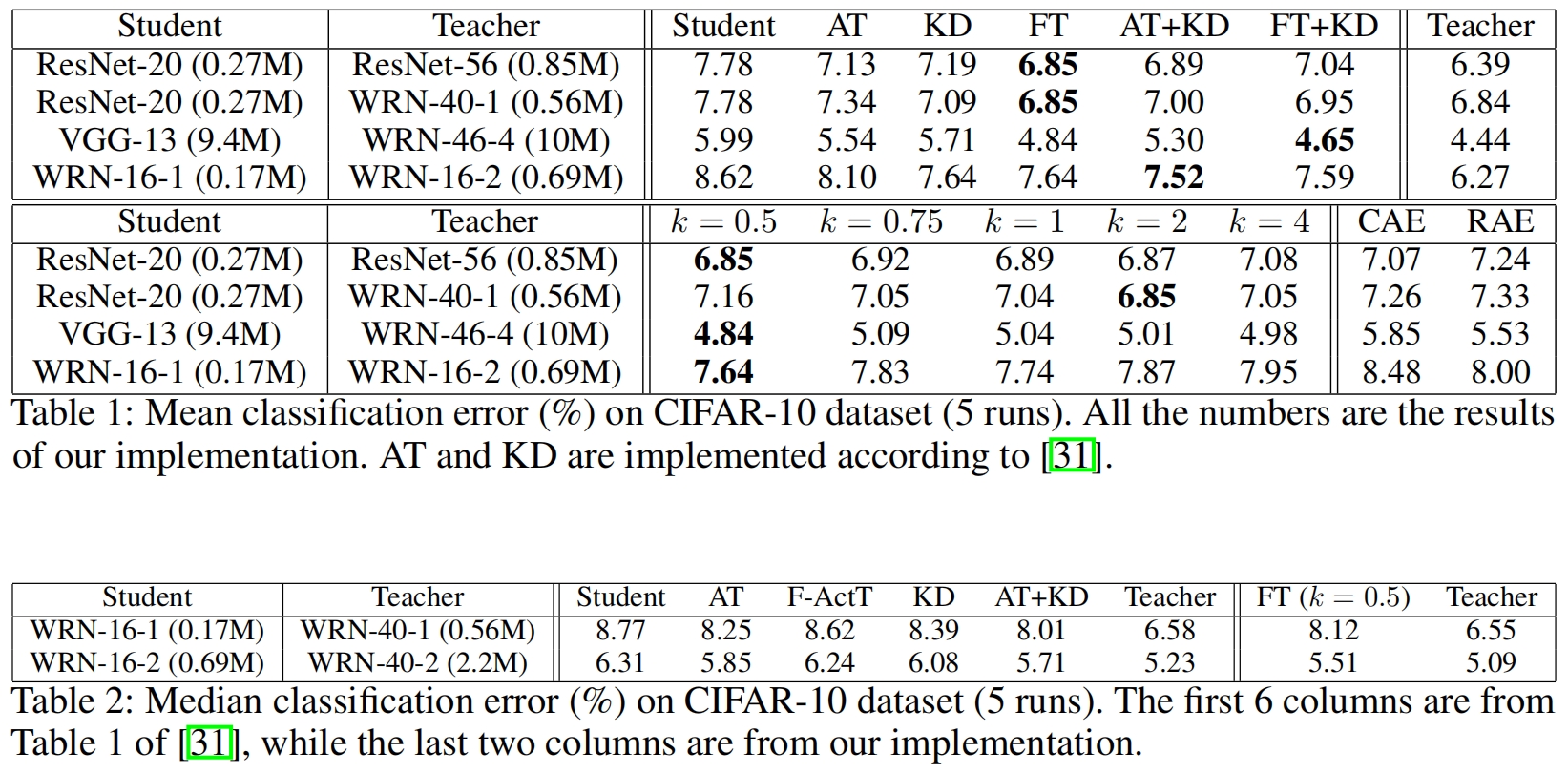
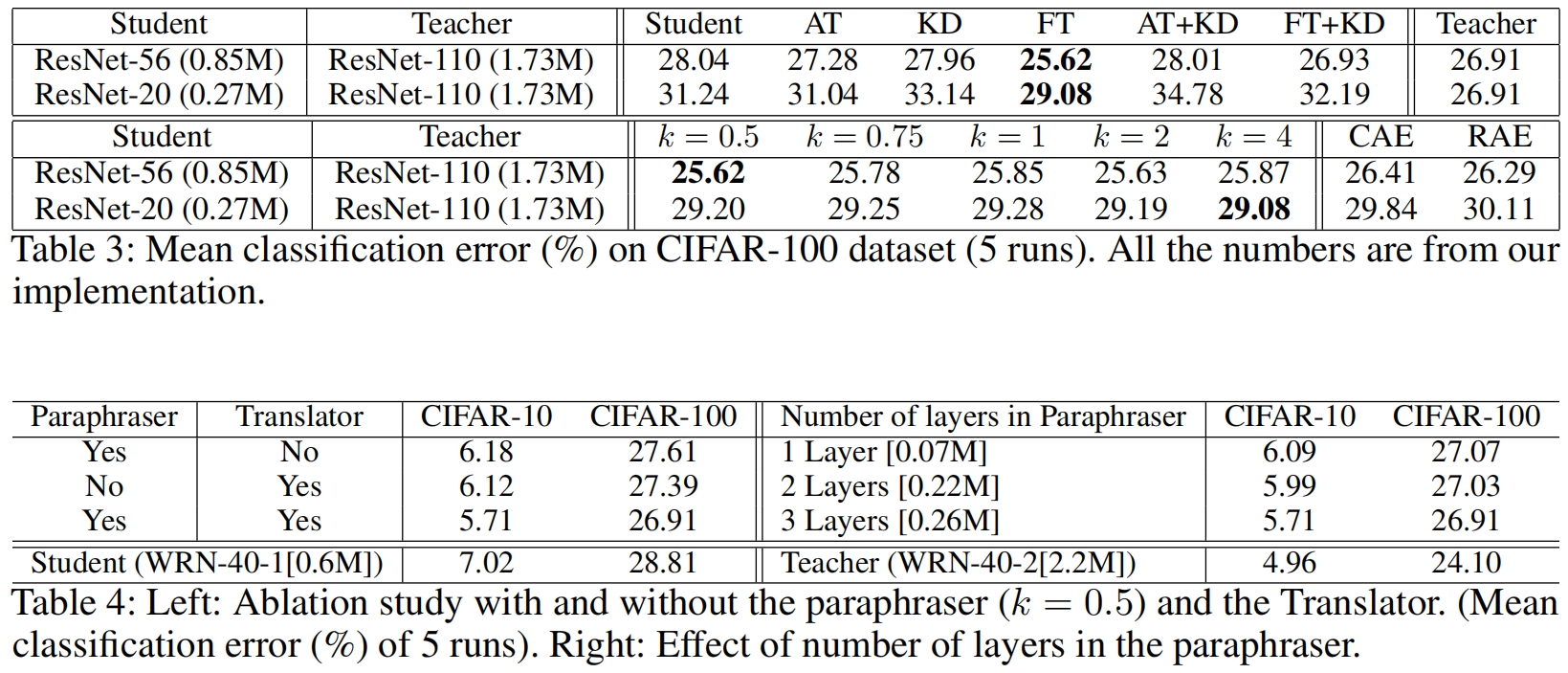
下面是Factor Transfer与其它蒸馏方法在CIFAR-10和CIFAR-100数据集上的结果对比,可以看出当FT与原始KD结合使用时,效果可能会变差。