机器视觉概述
机器视觉是人工智能正在快速发展的一个分支。简单说来,机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是通过机器视觉产品(即图像摄取装置,分CMOS和CCD两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
面临的挑战
视角变化

光照变化

尺寸变化

形态变化

背景混淆

遮挡

类内物体的外观差异

Opencv入门案例
读取图片
本节我们将来学习,如何使用opencv显示一张图片出来,我们首先需要掌握一条图片读取的api
cv.imread("图片路径","读取的方式")
# 图片路径: 需要在工程目录中,或者一个文件的绝对路径
# 读取方式: 分别有如下三种:cv.IMREAD_COLOR : 以彩图的方式加载,会忽略透明度(默认方式)cv.IMREAD_GRAYSCALE: 以灰色图片方式加载cv.IMREAD_UNCHANGED: 直接加载,透明度会得到保留示例代码如下:
import cv2 as cv# 读取图片 参数1:图片路径, 参数2:读取的方式
img = cv.imread("img/lena.png",cv.IMREAD_COLOR)
# 显示窗口 参数1:窗口名称, 参数2:图片数据
cv.imshow("src",img)# 让程序处于等待推出状态
cv.waitKey(0)
# 当程序推出时,释放所有窗口资源
cv.destroyAllWindows()写入文件
刚才我们知道,如何读取文件,接下来,我们来学习如何将内存中的图片数据写入到磁盘中!
暂时我们还没有学习,如何直接代码构建一张图片,为了演示,我们先读取一张图片,然后再将它写入到文件中,后面我们会学习如何直接内存中构建一张图片
import cv2 as cv
img = cv.imread("img/lena.png", cv.IMREAD_UNCHANGED)# 将图片写入到磁盘中,参数1: 图片写入路径,参数2: 图片数据
cv.imwrite("img/lena_copy.png",img)cv.waitKey(0)
cv.destroyAllWindows()理解像素
当我们将一张图片不断放大之后,我们就可以看到这张图片上一个个小方块,这里面的每一个小方块我们就可以称之为像素点! 任何一张图片,都是有若干个这样的像素所构成的!
操作像素
为了便于大家能够理解像素,我们现在手工来创建一张图片,例如我们使用np.zeros这样的函数可以创建一个30x40的矩阵,那个这个矩阵其实就可以表示一张图片,矩阵中每一个元素都是一个像素点,每个像素点又由BGR三部分组成,这里我们需要强调一下Opencv中,颜色空间默认是BGR不是RGB,所以我们想表示红色需要使用(0,0,255),想表示绿色需要(0,255,0)
下面我们就来操作图片,在图片的正中央增加一根红色的线!

这里我直接给出示例代码,然后我们来看一下运行效果吧!
import cv2 as cv
import numpy as np# 构建一个空白的矩阵
img = np.zeros((30,40,3),np.uint8)# 将第15行所有像素点全都改成红色
for i in range(40):# 设置第15行颜色为红色img[15,i] = (0,0,255)# 显示图片
cv.imshow("src",img)cv.waitKey(0)
cv.destroyAllWindows()就这样我们的图片正中间就多了一根红色的线
Opencv图像处理基础
图片的几何变换
图片剪切
正如我们前面所学到的,图片在程序中表示就是一个矩阵,我们要想操作图片,只需要操作矩阵元素就可以了.
接下来,我们要来完成图片的剪切案例,其实我们只需要想办法截取出矩阵的一部分即可!
在python中,矩阵的截取是很容易的一件事!
例如如下代码:
mat[起始行号:结束行号,开始列号:结束列号]
import cv2 as cv# 读取原图
img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
cv.imshow("source",img)
# 从图片(230,230) 截取一张 宽度130,高度70的图片
dstImg = img[180:250,180:310]
# 显示图片
cv.imshow("result",dstImg)cv.waitKey(0)
图片镜像处理
图片的镜像处理其实就是将图像围绕某一个轴进行翻转,形成一幅新的图像. 我们经常可以通过某个小水坑看到天空中的云, 只不过这个云是倒着的! 这个就是我们称为的图片的镜像!
下面我们来看这样一个示例吧!我们将lena这张图片沿着x轴进行了翻转

如果我们想在一个窗口中显示出两张图片,那么我们就需要知道图片的宽高信息啦!
如何获取呢? 看下面的示例代码:
imgInfo = img.shape
imgInfo[0] : 表示高度
imgInfo[1] : 表示宽度
imgInfo[2] : 表示每个像素点由几个颜色值构成知道了上述信息之后,我们就可以按照如下步骤实现啦!
实现步骤:
- 创建一个两倍于原图的空白矩阵
- 将图像的数据按照从前向后,从后向前进行绘制
代码实现
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个两倍于原图大小的矩阵
dstImg = np.zeros((height*2,width,3),np.uint8)# 向目标矩阵中填值
for row in range(height):for col in range(width):# 上部分直接原样填充dstImg[row,col] = img[row,col]# 下半部分倒序填充dstImg[height*2-row-1,col] = img[row,col]# 显示图片出来
cv.imshow("dstImg",dstImg)cv.waitKey(0)
cv.destroyAllWindows()图片缩放
对于图片的操作,我们经常会用到,放大缩小,位移,还有旋转,在接下来的课程中,我们将来学习这些操作!
首先,我们来学习一下图片的缩放
关于图片的缩放,常用有两种:
- 等比例缩放
- 任意比例缩放
要进行按比例缩放,我们需要知道图片的相关信息,我们可以通过
imgInfo = img.shape
imgInfo[0] : 表示高度
imgInfo[1] : 表示宽度
imgInfo[2] : 表示每个像素点由几个颜色值构成
图片缩放的常见算法:
- 最近领域插值
- 双线性插值
- 像素关系重采样
- 立方插值
默认使用的是双线性插值法,这里我们给出利用opencv提供的resize方法来进行图片的缩放
import cv2 as cv# 读取一张图片
img = cv.imread("img/lena.jpg", cv.IMREAD_COLOR)
# 获取图片信息
imgInfo = img.shape
print(imgInfo)
# 获取图片的高度
height = imgInfo[0]
# 获取图片的宽度
width = imgInfo[1]
# 获取图片的颜色模式,表示每个像素点由3个值组成
mode = imgInfo[2]# 定义缩放比例
newHeight = int(height*0.5)
newWidth = int(width*0.5)
# 使用api缩放
newImg = cv.resize(img, (newWidth, newHeight))
# 将图片展示出来
cv.imshow("result",newImg)cv.waitKey(0)
cv.destroyAllWindows()
图片操作原理
我们在前面描述过一张图片,在计算机程序中,其实是用矩阵来进行描述的,如果我们想对这张图片进行操作,其实就是要对矩阵进行运算.
矩阵的运算相信大家在前面课程的学习中,已经学会了,下面我们来给大家列出常见的几种变换矩阵

这里我给大家演示的是图片的位移操作,将一个矩阵的列和行看成坐标系中的x和y我们就可以轻易的按照前面我们所学过的内容来操作矩阵啦!
import cv2 as cv
import numpy as np
import matplotlib.pyplot as pltsrt = cv.imread("img/23.jpg", cv.IMREAD_COLOR)
plt.figure(figsize=(3,3))
getRGB(srt)
height,width = srt.shape[0:2]#创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,3), np.uint8)for row in range(height):for col in range(width):color = srt[row,col]#图像位移tx = 10ty = 50dy = ty + rowif dy >=height: dy = height-1dx = tx + colif dx >=width: dx = width-1dstImg[dy,dx] = color # 显示图片出来
getRGB(dstImg)显示效果:

图片移位
刚才我们采用的是纯手工的方式来操作图片,其实我们完全没必要那样做,opencv中已经帮我们提供好了相关的计算操作,我们只需提供变换矩阵就好啦!
cv.warpAffine(原始图像,变换矩阵,(高度,宽度))下面是位移的示例代码:
import cv2 as cv
import numpy as npimg = cv.imread("img/lena.jpg",cv.IMREAD_COLOR)
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]
# 定义位移矩阵
matrixShift = np.float32([[1,0,50],[0,1,100]])
# 调用api
dstImg = cv.warpAffine(img,matrixShift,(width,height))cv.imshow("dst",dstImg)
cv.waitKey(0)图片旋转
图片的旋转其实也是很简单的,只不过默认是以图片的左上角为旋转中心
import cv2 as cv
import numpy as np
import matplotlib.pyplot as pltimg = cv.imread("img/25.jpg",cv.IMREAD_COLOR)
imgInfo = img.shape
height,width = imgInfo[0:2]# 定义放射矩阵, 参数1: 以中心点为参考点 参数2: 旋转角度 参数3: 缩放系数
matrixAffine = cv.getRotationMatrix2D((width* 0.5, height*0.5), 45, 0.5)
# 进行放射变换
dstImg = cv.warpAffine(img, matrixAffine,(width,height))getRGB(dstImg)效果:

图片仿射变换
仿射变换是在几何上定义为两个向量空间之间的一个仿射变换或者仿射映射(来自拉丁语,affine,“和…相关”)由一个非奇异的线性变换(运用一次函数进行的变换)接上一个平移变换组成。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt## 防止图片颜色突变方法
def getRGB(img):img1 = cv.cvtColor(img, cv.COLOR_BGR2RGB)plt.imshow(img1)img = cv.imread("img/14.jpg", cv.IMREAD_COLOR)
imgInfo = img.shape
height,width = imgInfo[0:2]
# getRGB(img)# 定义图片左上角 ,左下角,,右上角的坐标
matrixSrc = np.float32([[0,0],[0,width-1],[height-1,0]])#将原来的点映射到新的点
matrixDst = np.float32([[150,100],[150,900],[900,150]])#将两个矩阵组合在一起,放射变换矩阵
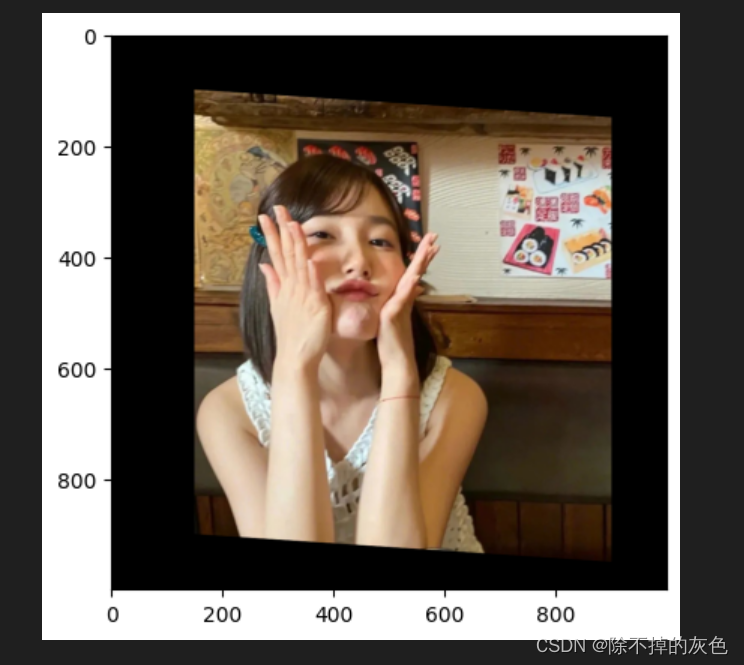
matrixAffine = cv.getAffineTransform(matrixSrc, matrixDst)dstImg = cv.warpAffine(img, matrixAffine,(width,height))getRGB(dstImg)效果:
图像金字塔
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
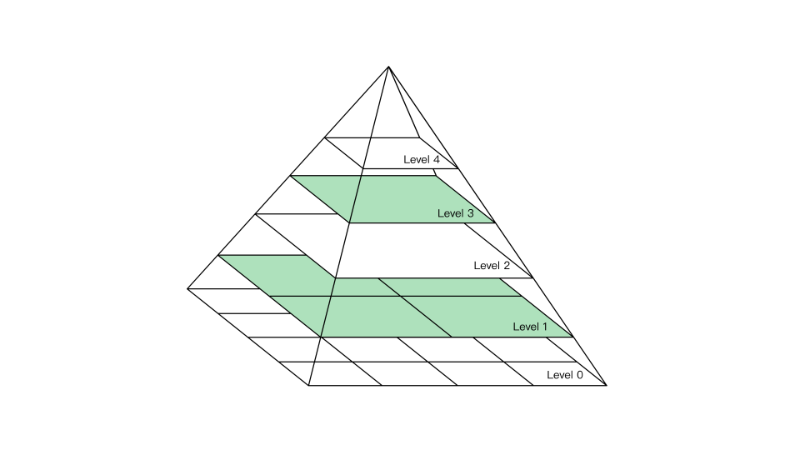
降低图像的分辨率,我们可以称为下采样
提高图像的分辨率,我们可以称为上采样
下面我们来测试一下采用这种采样操作进行缩放和我们直接进行resize操作他们之间有什么差别!
我们可以看到,当我们对图片进行下采样操作的时候,即使图片变得非常小,我们任然能够看到它的轮廓,这对后面我们进行机器学习是非常重要的一步操作,而当我们直接使用resize进行操作的时候,我们发现图片似乎不能完全表示它原有的轮廓,出现了很多的小方块!

下面这里是我们当前案例的示例代码
import cv2 as cv;src_img = cv.imread("img/lena.jpg",cv.IMREAD_COLOR);
imgInfo = src_img.shape
height = imgInfo[0]
width = imgInfo[1]pry_down1 = cv.pyrDown(src_img)
cv.imshow("down1",pry_down1)
pry_down2 = cv.pyrDown(pry_down1)
cv.imshow("down2",pry_down2)
pry_down3 = cv.pyrDown(pry_down2)
cv.imshow("down3",pry_down3)
pry_down4 = cv.pyrDown(pry_down3)
cv.imshow("down4",pry_down4)pyr_up1 = cv.pyrUp(pry_down1)
cv.imshow("up1",pyr_up1)
pyr_up2 = cv.pyrUp(pry_down2)
cv.imshow("up2",pyr_up2)
pyr_up3 = cv.pyrUp(pry_down3)
cv.imshow("up3",pyr_up3)
pyr_up4 = cv.pyrUp(pry_down4)
cv.imshow("up4",pyr_up4)# 对比resize
img2 = cv.resize(src_img,(int(height/2),int(width/2)))
cv.imshow("img1/2",img2)img4 = cv.resize(src_img,(int(height/4),int(width/4)))
cv.imshow("img1/4",img4)img8 = cv.resize(src_img,(int(height/8),int(width/8)))
cv.imshow("img1/8",img8)img16 = cv.resize(src_img,(int(height/16),int(width/16)))
cv.imshow("img1/16",img16)cv.waitKey(0)
cv.destroyAllWindows()图像特效
图像融合
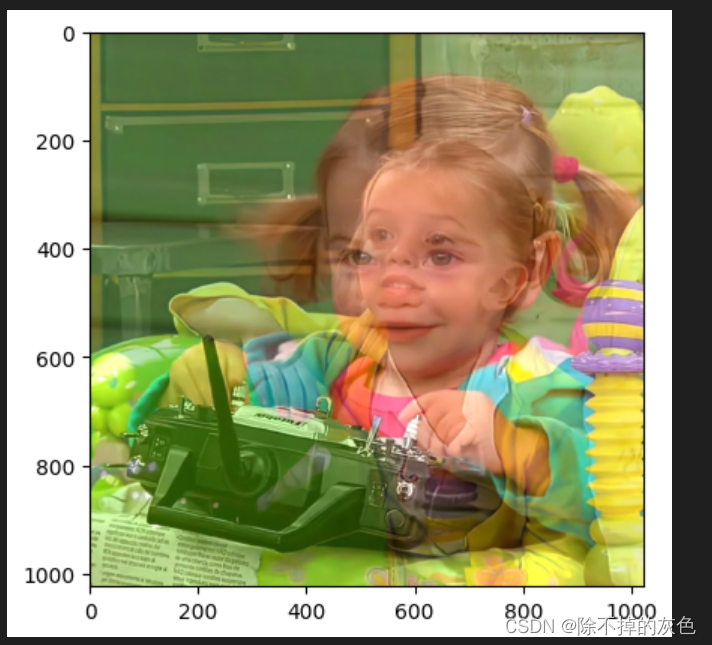
图像融合,即按照一定的比例将两张图片融合在一起!例如下面图一图二经过融合之后形成图三!
执行这样的融合需要用到opencv提供的如下api
cv.addWeighted(图像1,权重1,图像2,权重2,叠加之后的像素偏移值)
注意:
进行叠加的两张图片宽高应该相同
叠加之后的像素偏移值如果填的话不要填太大,超过255会导致图像偏白
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt## 防止图片颜色突变方法
def getRGB(img):img1 = cv.cvtColor(img, cv.COLOR_BGR2RGB)plt.imshow(img1)img = cv.imread("img/1.jpg",cv.IMREAD_COLOR)
getRGB(img)
height,width = img.shape[0:2]
height,widthimg2 = cv.imread("img/2.jpg", cv.IMREAD_COLOR)
getRGB(img2)
height,width = img2.shape[0:2]
height,width#进行叠加时的插值
dst = cv.addWeighted(img, 0.7, img2, 0.5 , 0)
getRGB(dst)效果:
灰度处理
一张彩色图片通常是由BGR三个通道叠加而成,为了便于图像特征识别,我们通常会将一张彩色图片转成灰度图片来进行分析,当我们转成灰色图片之后,图片中边缘,轮廓特征仍然是能够清晰看到的,况且在这种情况下我们仅需要对单一通道进行分析,会简化很多操作!
示例代码
import cv2 as cv# 方式一 : 直接以灰度图像的形式读取
# img = cv.imread("img/itheima.jpg", cv.IMREAD_GRAYSCALE)
# cv.imshow("dstImg",img)
# cv.waitKey(0)# 方式二: 以彩图的方式读取
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
# 将原图的所有颜色转成灰色
dstImg = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("dstImg",dstImg)cv.waitKey(0)效果:


原理演示
方式一: gray = (B+G+R)/3
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义一个与原图同样大小的矩阵
dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据
for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度gray = np.uint8((int(b)+int(g)+int(r))/3)print(gray)# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)
cv.waitKey(0)方式二: 利用著名的彩色转灰色心理学公式: Gray = R*0.299 + G*0.587 + B*0.114
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)# 获取图片宽高信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 定义一个与原图同样大小的矩阵
dstImg = np.zeros(imgInfo,np.uint8)# 遍历dstImg,填充数据
for row in range(height):for col in range(width):# 获取原来的像素值(b,g,r) = img[row,col]# 计算灰度# gray = np.uint8((int(b)+int(g)+int(r))/3)# 采用心理学公式计算gray = b*0.114 + g*0.587 + r*0.299# 向目标矩阵中填值dstImg[row,col]=graycv.imshow("dstimg",dstImg)
cv.waitKey(0)颜色反转
灰图反转
例如在一张灰度图片中,某个像素点的灰度值为100, 然后我们进行颜色反转之后,灰度值变为255-100 = 155 , 从下图我们可以看出,进行颜色反转之后,整张图片看起来非常像我们小时候所看到的胶卷底片!
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt## 防止图片颜色突变方法
def getRGB(img):img1 = cv.cvtColor(img, cv.COLOR_BGR2RGB)plt.imshow(img1)img = cv.imread("img/5.jpg", cv.IMREAD_GRAYSCALE)imgInfo = img.shape
height,width = imgInfo[0:2]#创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,1),np.uint8)for row in range(height):for col in range(width):#获取原图中的 灰度值gray = img[row,col]#反转newColor = 255 - gray#填充dstImg[row,col] = newColorgetRGB(dstImg)效果如下:

彩图反转
学会了前面灰度图片的反转,下面我们进一步来学习彩色图片的反转. 相对于灰度图片,彩色图片其实只是由3个灰度图片叠加而成,如果让彩色图片进行颜色反转,我们其实只需要让每个通道的灰度值进行反转即可!
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)
# 获取原图信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 创建一个和原图同样大小的矩阵
dstImg = np.zeros((height,width,3),np.uint8)for row in range(height):for col in range(width):# 获取原图中的灰度值(b,g,r) = img[row,col]# 反转new_b = 255-bnew_g = 255-gnew_r = 255-r# 填充dstImg[row,col]=(new_b,new_g,new_r)cv.imshow("dstimg",dstImg)
cv.waitKey(0)显示效果:

马赛克效果
马赛克指现行广为使用的一种图像(视频)处理手段,此手段将影像特定区域的色阶细节劣化并造成色块打乱的效果,因为这种模糊看上去有一个个的小格子组成,便形象的称这种画面为马赛克。其目的通常是使之无法辨认。
下面,我们来介绍一下实现马赛克的思路!
假设我们将要打马赛克的区域按照4x4进行划分,我们就会得到如下左图的样子!
接下来我们要干的就是让这个4x4块内的所有像素点的颜色值都和第一个像素点的值一样.
经过运算之后,我们整个4x4块内的所有像素点就都成了黄色! 从而掩盖掉了原来的像素内容!

代码如下:
import cv2 as cv
import numpy as np# 将图片数据读取进来
img = cv.imread("img/itheima.jpg",cv.IMREAD_COLOR)
cv.imshow("img",img)
# 获取原图信息
imgInfo = img.shape
height = imgInfo[0]
width = imgInfo[1]# 遍历要打马赛克的区域 宽度430 高度220
for row in range(160,240):for col in range(380,670):# 每10×10的区域将像素点颜色改成一致if row%10==0 and col%10==0:# 获取当前颜色值(b,g,r) = img[row,col]# 将10×10区域内的颜色值改成一致for i in range(10):for j in range(10):img[row+i,col+j]= (b,g,r)# 显示效果图
cv.imshow('dstimg',img)
cv.waitKey(0)效果: