记录一下痛失的超级轻松的数据分析实习(线上),hr问我有没有相关经历,我说我会用jupyter book进行数据导入,清洗,可视化,特征工程,建模,python学和用的比较多,然后hr问我会不会R,我直接蒙了,它招募里面明明是写python和R会一款即可,我没接触过R啊,自然就实话实说了,结果。。。当然是寄了~
算了反正个人感觉是和python差不多,但是能记住多少就得看我脑子了,我简单自学一下吧,下一期出python的数据导入,清洗,可视化,特征工程,建模那些,然后做个简单对比吧~
R语言是一种编程语言和开发环境,主要用于数据分析和统计领域。它提供了丰富的统计分析和数据可视化功能,可以进行数据清洗、数据处理、建模和预测等各种数据分析任务。
1.安装与基础使用
(1)安装
【1】R语言
下载网址:https://cran.r-project.org/

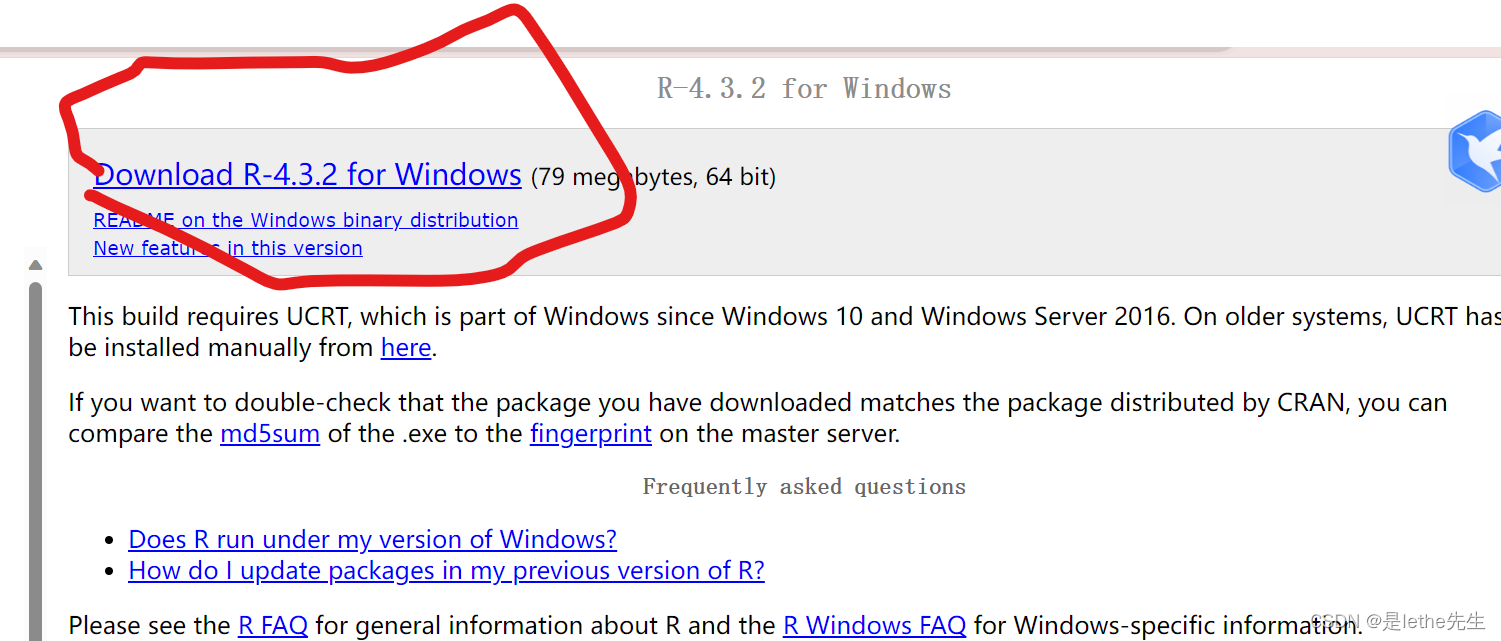
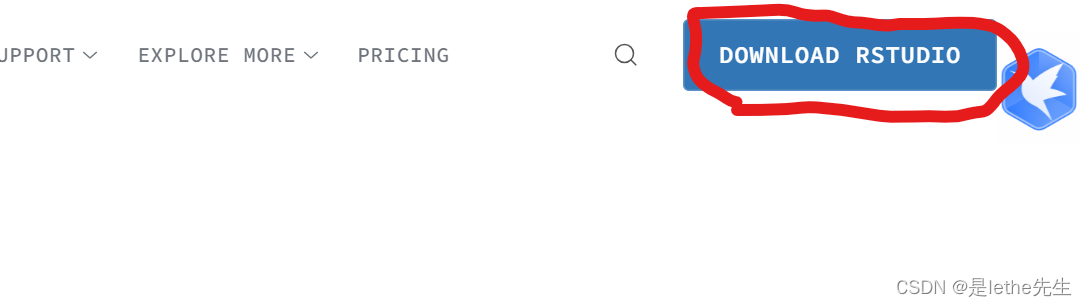
【2】Rstudio
下载网址:https://www.rstudio.com/products/rstudio/
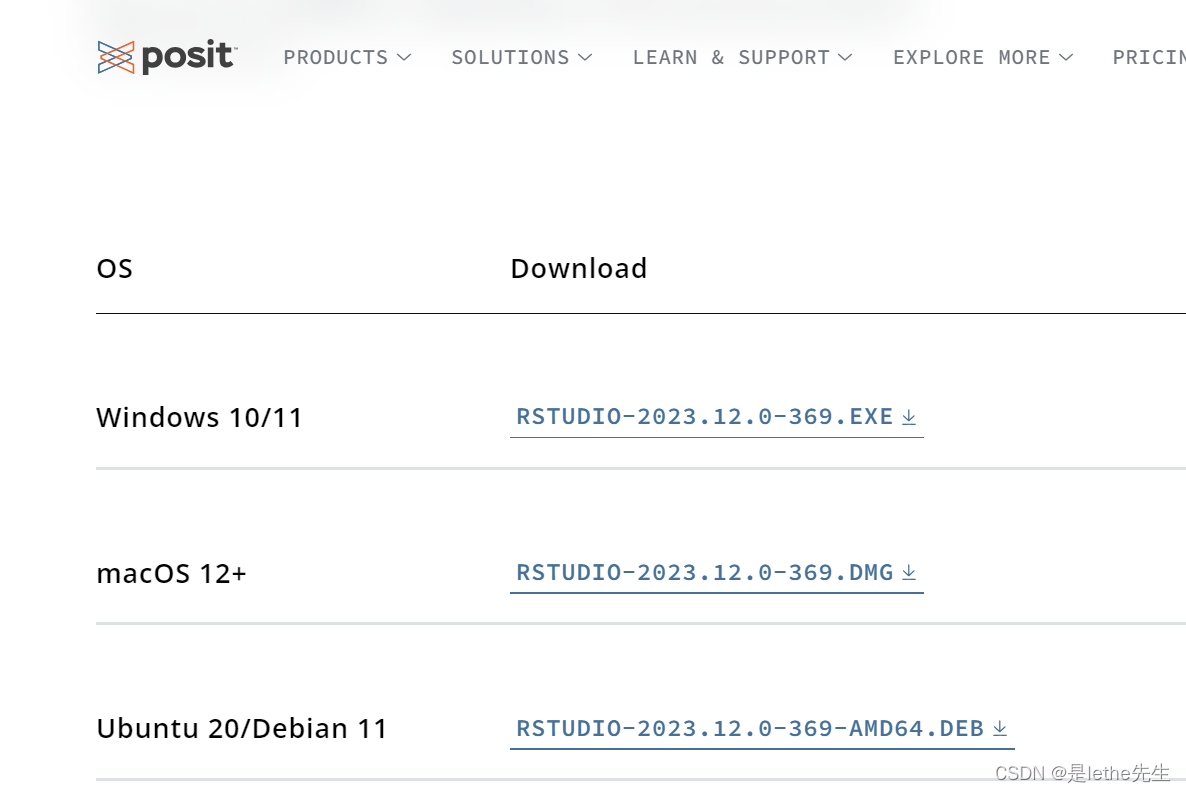
(下滑选择你电脑的版本)点击下载即可~不想那么麻烦的直接用我的安装包吧,给我点个赞就行了,栓Q:百度网盘链接:https://pan.baidu.com/s/1m6KX976JXM47xO7SpcSE8g?pwd=clyy

【3】简单使用
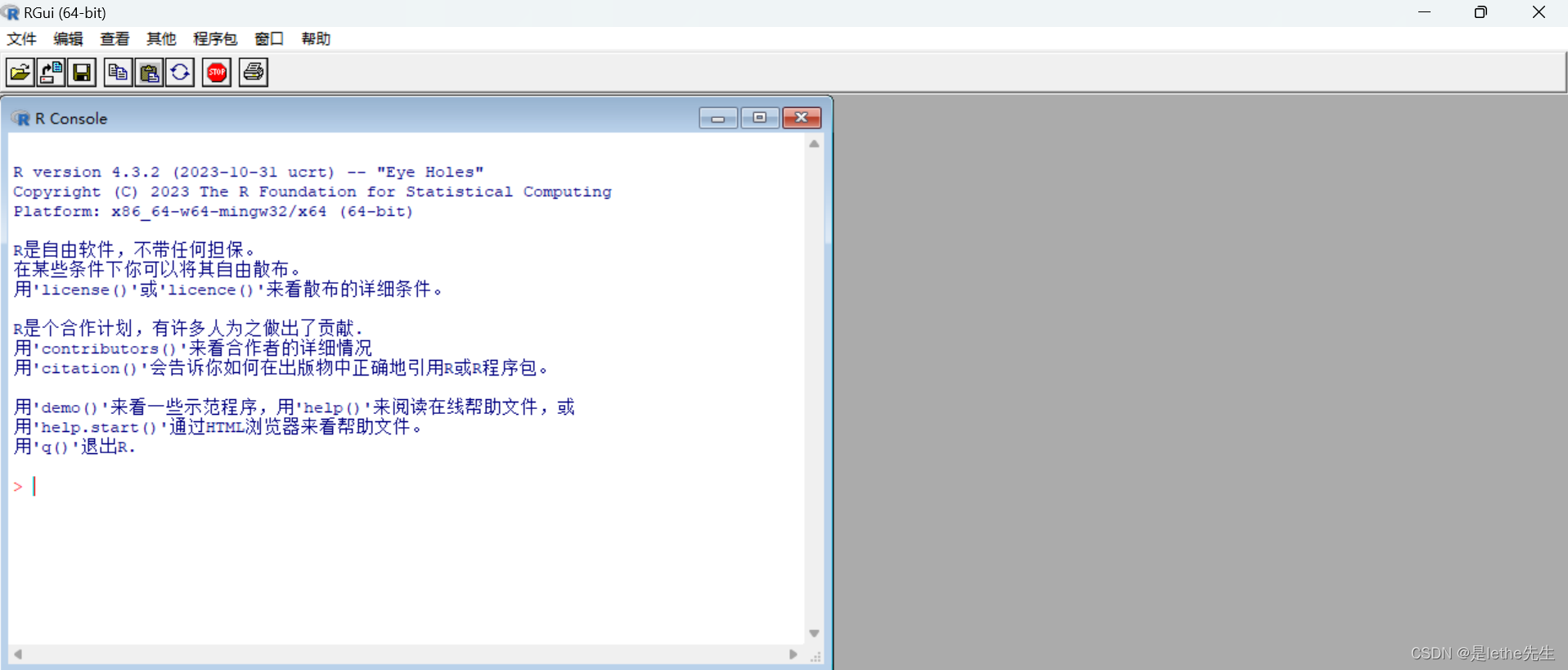


2.基础语法
【1】变量赋值:使用“<-”或“=”符号将值赋给变量。
例如:x <- 10 或 x = 10。
【2】数据类型:R语言中的主要数据类型有数值(numeric)、字符(character)、逻辑(logical)和因子(factor)等。
-
数值(numeric):R语言的数值类型可以表示整数(如1, 2, 3)和浮点数(如1.5, 2.7)。在R中,数值类型使用内置的双精度浮点数表示。
-
字符(character):R语言的字符类型用于表示文本数据,如姓名、地址等。用双引号或单引号括起来的文本被当作字符类型。
-
逻辑(logical):类似bool,R语言的逻辑类型用于表示逻辑真(TRUE)和逻辑假(FALSE)。逻辑类型常用于条件判断和布尔运算。
-
因子(factor):类似于C语言中的枚举类型(enum)。它们都用于表示有限的类别数据,仅允许取特定的值,R语言的因子类型用于表示有限的类别数据。因子是通过将非数值类型的数据转换为离散的、有限的、按照特定顺序的类别来处理。
【3】向量:可以使用c()函数创建向量。
例如:x <- c(1, 2, 3)。
【4】列表:可以使用list()函数创建列表。列表可以包含不同类型的元素。
例如:my_list <- list(1, "apple", TRUE)。
【5】矩阵:可以使用matrix()函数创建矩阵。矩阵是二维的,可以包含相同类型的元素。
例如:my_matrix <- matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)。
【6】数据框:可以使用data.frame()函数创建数据框。数据框是类似于表格的结构,可以包含不同类型的列。
例如:my_dataframe <- data.frame(name = c("Alice", "Bob"), age = c(25, 30))。
【7】函数:可以使用function()函数创建函数。函数可以接受参数,并返回一个结果。
#R语言
my_function <- function(x, y) {z <- x + yreturn(z)
}
#类似于c语言
int f(x,y){int z;z=x+y;return z;
}【8】条件语句:可以使用if-else语句进行条件判断。
#R
if (x > 10) {print("x is greater than 10")
} else {print("x is less than or equal to 10")
}
【9】循环语句:可以使用for循环或while循环进行重复操作。
#R
for (i in 1:5) {print(i)
}while (x < 10) {x <- x + 1print(x)
}
3.数据分析
(1)数据导入
【1】CSV文件:使用read.csv()函数导入CSV文件。
data <- read.csv("data.csv")
【2】Excel文件:使用readxl包中的read_excel()函数导入Excel文件。首先需要安装readxl包,然后使用以下代码导入文件。
install.packages("readxl")
library(readxl)data <- read_excel("data.xlsx")
【3】SPSS文件:使用haven包中的read_sav()函数导入SPSS文件。首先需要安装haven包,然后使用以下代码导入文件。
install.packages("haven")
library(haven)data <- read_sav("data.sav")
【4】SQL数据库:使用RODBC包或DBI包与数据库建立连接,并使用SQL查询从数据库中导入数据。首先需要安装对应的包,然后使用以下代码导入数据。此方法需要详细了解SQL语言和数据库连接配置。
install.packages("RODBC")
library(RODBC)conn <- odbcConnect("database_name", uid="username", pwd="password")
data <- sqlQuery(conn, "SELECT * FROM table_name")
odbcClose(conn)
(2)数据清洗
【1】缺失值处理
# 检测缺失值
is.na(data)# 删除包含缺失值的行
clean_data <- na.omit(data)# 创建逻辑向量指示不包含缺失值的行
complete_cases <- complete.cases(data)
【2】重复值处理
# 检测重复值
duplicated(data)# 删除重复的行
clean_data <- unique(data)
【3】数据转换
# 重命名变量
data$new_var <- data$old_var
data$new_var <- NULL # 删除变量# 修改变量类型
data$new_var <- as.numeric(data$old_var)
data$new_var <- as.character(data$old_var)# 创建新变量
data$new_var <- data$var1 + data$var2# 使用dplyr包进行数据转换
library(dplyr)
clean_data <- data %>%select(var1, var2) %>%filter(var1 > 0) %>%mutate(new_var = var1 + var2)
【4】数据排序
# 对数据框按照某一列排序
sorted_data <- data[order(data$var1), ]# 对向量排序
sorted_vector <- sort(vector)
(3)可视化
【1】基本绘图函数:R语言内置了一些基本的绘图函数,如plot()、barplot()、hist()等
# 创建散点图
plot(x, y)# 创建条形图
barplot(heights)# 创建直方图
hist(data)
【2】ggplot2库:ggplot2是R语言中最流行的可视化库之一,提供了一种基于图层(layer)的绘图系统。使用ggplot2,可以创建包括散点图、条形图、线图、箱线图等各种图形。
# 安装ggplot2库
install.packages("ggplot2")# 使用ggplot2创建散点图
library(ggplot2)
ggplot(data, aes(x, y)) +geom_point()# 使用ggplot2创建条形图
ggplot(data, aes(x, y)) +geom_bar()# 使用ggplot2创建线图
ggplot(data, aes(x, y)) +geom_line()
【3】lattice库:lattice是另一个常用的可视化库,提供了一种基于网格(grid)的绘图系统。lattice库可以创建散点图、条形图、线图等,并支持分组、子图和条件绘图等复杂的可视化需求。
# 安装lattice库
install.packages("lattice")# 使用lattice创建散点图
library(lattice)
xyplot(y ~ x, data=data)# 使用lattice创建条形图
barchart(y ~ x, data=data)# 使用lattice创建线图
xyplot(y ~ x, data=data, type="l")
【4】plotly、ggvis、vega-lite等,没搜到教程,改天有空整理一下
(4)特征工程:是指对原始数据进行处理,以提取有用的特征,并为机器学习模型提供更具信息量和表达能力的输入。
1. 数据清洗:对数据进行清洗,包括处理缺失值、处理异常值、去除重复值等。可以使用函数如`na.omit()`处理缺失值,`outliers()`处理异常值,`duplicated()`去除重复值。
2. 特征选择:选择对目标变量有显著影响的特征。可以使用统计方法(如相关性分析、方差分析)或机器学习方法(如随机森林、LASSO回归)。
# 相关性分析
correlation <- cor(data)# 方差分析
anova_result <- aov(target_variable ~ ., data=data)# 随机森林特征重要性排序
library(randomForest)
rf_model <- randomForest(target_variable ~ ., data=data)
importance <- importance(rf_model)3. 特征编码:将非数值型变量转换为数值形式,以便机器学习模型进行处理。可以使用函数如`factor()`将分类变量转换为因子,`dummyVars()`进行独热编码等。
# 将分类变量转换为因子
data$gender <- factor(data$gender)# 进行独热编码
library(DMwR)
dummy_data <- dummyVars(~., data=data)
encoded_data <- predict(dummy_data, newdata=data)4. 特征缩放:将数值型特征进行缩放,以确保不同特征之间的量纲一致。常见的方法有标准化(将数据转换为均值为0,标准差为1的分布)和归一化(将数据缩放到0-1的范围内)。
# 标准化
scaled_data <- scale(data)# 归一化
normalized_data <- scale(data, center=FALSE, scale=apply(data, MARGIN=2, FUN=max) - apply(data, MARGIN=2, FUN=min))5. 特征生成:通过原始特征的组合、变换或提取等方式生成新的特征。可以使用函数如`mutate()`进行特征生成。
# 通过组合生成新特征
library(dplyr)
generated_data <- data %>%mutate(new_feature = feature1 + feature2)# 通过变换生成新特征
generated_data <- data %>%mutate(new_feature = log(feature1))# 通过提取生成新特征
generated_data <- data %>%mutate(new_feature = substr(feature1, 1, 3))(5)建模
1. 线性回归:使用`lm()`函数进行线性回归建模。
model <- lm(target_variable ~ ., data=data)
summary(model)2. 逻辑回归:使用`glm()`函数进行逻辑回归建模。
model <- glm(target_variable ~ ., data=data, family=binomial)
summary(model)3. 决策树:使用`rpart()`函数进行决策树建模。
library(rpart)
model <- rpart(target_variable ~ ., data=data)
printcp(model)4. 随机森林:使用`randomForest()`函数进行随机森林建模。
library(randomForest)
model <- randomForest(target_variable ~ ., data=data)
print(model)5. 支持向量机:使用`svm()`函数进行支持向量机建模。
library(e1071)
model <- svm(target_variable ~ ., data=data)
summary(model)6. 朴素贝叶斯:使用`naiveBayes()`函数进行朴素贝叶斯建模。
library(e1071)
model <- naiveBayes(target_variable ~ ., data=data)
summary(model)7. K近邻(K-Nearest Neighbors):使用`knn()`函数进行K近邻建模。
library(class)
model <- knn(train_data, test_data, target_variable, k=3)8. 主成分分析(Principal Component Analysis):使用`prcomp()`函数进行主成分分析建模。
model <- prcomp(data, scale.=TRUE)
summary(model)