Java异常处理
Java语言在执行后会中断,也就是在出错位置后的代码都不会被执行,为了使非致命错误后的程序仍然能够执行,引入异常处理机制。
异常
可处理的异常用Exception表示,不可处理的异常用Error表示,通常是栈内存溢出或堆内存溢出,具体又分为编译时异常和运行时异常,编译异常要求开发者必须进行处理,运行时异常可处理也可不处理,区分方法是看其是否继承了RunTimeException类,我们自行规定异常的原则应该是出现异常的概率大,用编译异常,强制要求方法调用者处理,出现异常的概率小,使用运行时异常。
异常抛出
Java执行程序出现异常后,立即创建异常对象,并用throw抛出,创建一个异常对象实例。
编写方法时认为该方法有较大概率出现某种异常,可使用throws进行修饰,让调用者在调用时根据编译异常和运行时异常酌情处理,编译时异常必须处理,使用异常处理机制或继续向上抛出。
异常处理
处理机制为try {} catch(接受异常的实例){} finaly{}其中catch可多层使用,即处理多个异常,处理机制可嵌套使用,finaly内的语句在任何情况下都执行,通常在此进行资源回收。
自定义异常
创建对应的异常子类,继承Exception或RunTimeException,构造有参构造函数并传入message,可在抛出异常时输出message。
包装类
object类是所有类的父类,可以接受所有基本数据类型,基本类型对应的类即包装类,二者可以直接互相赋值,因为包装类提供自动装箱和自动拆箱方法,即基本数据类型转引用数据类型,引用数据类型转基本数据类型。其对应如下图:
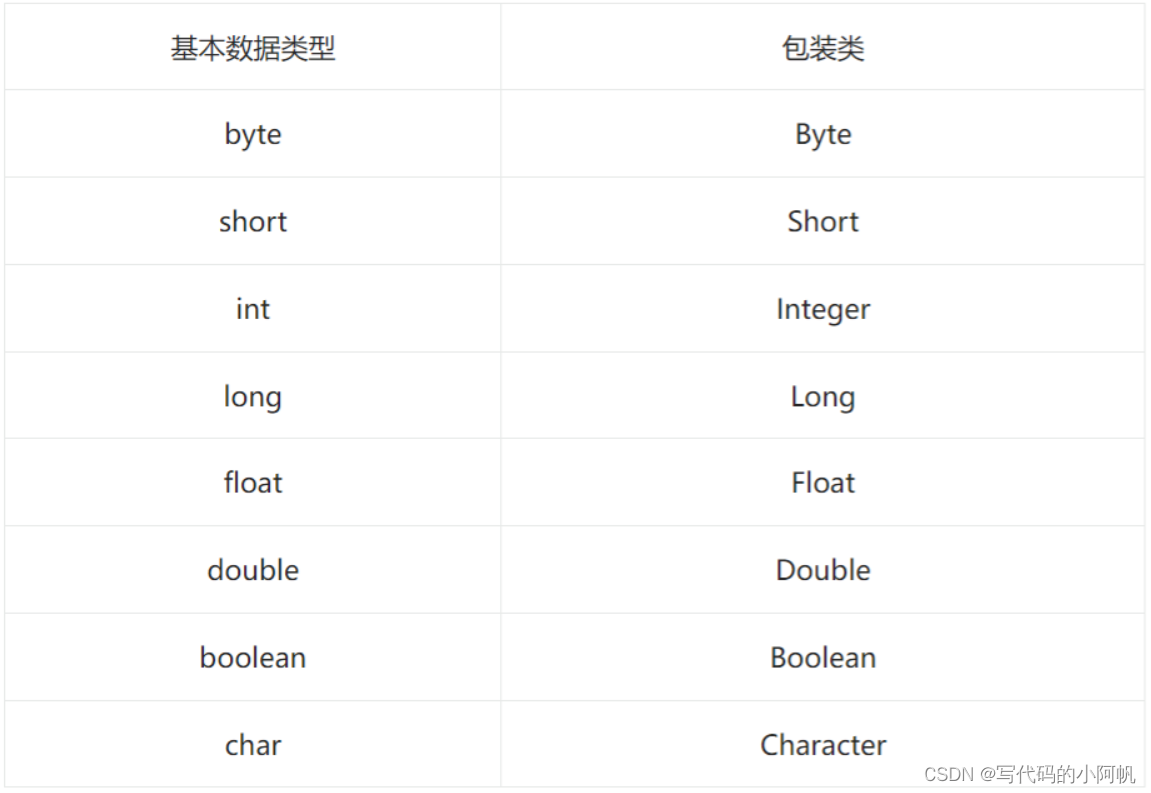
可以看出除了int和char对应不同外,其余基本数据的包装类名均为其首字母大写,其实是Java提供处理基本数据类型的方法。
String类
该类不可被继承,因为在定义中其被final修饰,常用方法总结如下:
equal 判断字符串相等,比较地址
sbstring(a,b) 切割a-b之间的字符
endsWith(a) 判断是否以a为结尾,a可以是字符串
getBytes() 将字符串转为`byte`数组
toLowerCase 大写转为小写,原有小写不变
replace(目标,替换) 将目标字符串转为替换字符串
contains 判断字符串内是否包含一个字符串,返回布尔类型
trim 去除首尾空格
indexOf(a) 返回a对应的下标索引
split(a) 以a为分割,将字符串拆分为对应数组
加强for循环
for(数据类型 遍历到的每个对象 : 容器对象)用于遍历容器内的每一个对象。
集合
集合是容器的一种,用于高效存储数据,且只能存放引用数据类型,基本数据类型在存放时会自动装箱,同一集合内的数据元素类型没有限制。
Collection集合有List和Set两个接口,分别对应ArryList、LinkedList和HashSet、TreeSet实例。
Map集合的两个实例为HashMap、TreeMap。
Collection集合的基本方法如下:
Collection collection=new ArrayList();//建立实例
add 添加元素
addall 复制所有元素
clear 移除所有元素
iterator 返回迭代器 可用于遍历 hasNext判断是否有下一个元素,删除修改需要对迭代器操作
remove 删除元素
cotains 判断集合是否包含元素
泛型
Java5之后推出的新特性,List<数据类型> list = new ArryList<>();,用于限制集合内存放的数据类型
List
具体实现类有ArrayList和LinkedList,分别是基于数组和链表实现。
ArrayList有序,可重复,提供了按照索引访问元素的方法,但对多线程不安全,需要手动同步,默认容量为10,装满后自动触发扩容机制,扩为原来的1.5倍。
vector是线程安全的ArrayList,但效率很低,多线程场景下进入方法会发生线程阻塞,可以采用其他方法保证线程安全;扩容时扩大为原来的2倍。
和ArrayList的扩容机制都是创建大数组并复制内容覆盖掉原有数组。
LinkedList同样有序可重复,但底层封装了双向链表,且通过节点方式存储数据,故随机增删效率高,无扩容机制,存储一个元素就创建一个新节点。
Set
HashSet
HashSet底层封装HashMap集合,存储元素在Map的Key部分,无序不可重复。
TreeSet
底层使用TreeMap,可对存入元素进行排序,存入自定义元素需要实现比较器接口,重写比较器规则。
Map
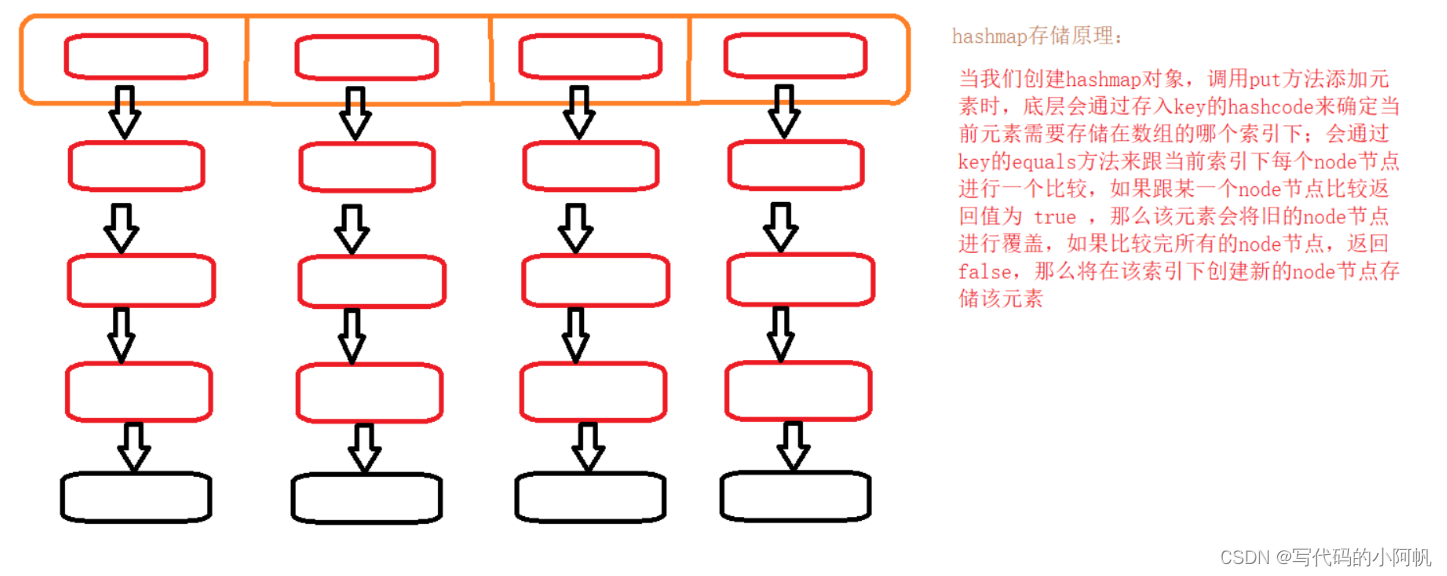
hashMap是保存具有映射关系的数据,即key—value对应的结构,二者都为引用数据类型,key一般为String类型,其中key用set方法存放,不允许重复,该结构为单向一对一结构,底层实现基于链表和数组(哈希表),可定义可用泛型。
执行原理
hashmap通过存储key的hashcode来确定再数组上索引的位置,然后根据key来跟该下标索引下所有的链表节点进行equals比较,如果equals方法返回true,说明key相同,后者会覆盖前者,返回false,将创建新的节点。扩容因子为2.0。
equals方法仅比较地址,若要根据内容比较需重写方法,重写方法可使用alt+insert快捷键生成。
//常用方法
put(key,value) //添加元素
size //获取长度
containsKey/value //判断集合中是否包含某个key/value
remove(key) //根据key删除
get(key) //根据key获取value
遍历方法
方法一:获取所有key,通过get方法获取value
Set<String> s=hashMap.keySet();
//返回set集合包含的所有key,再for循环获取value即可。
方法二:通过entrySet方法,将Map转为Set
Set<Map.Entry<String,Object>> entries=hashMap.entrySet();
获得Set格式的Map集合,加强for循环,使用get方法获得key和value即可。
TreeMap
存储时根据key排序,保证数据的有序状态,底层使用红黑树存储数据,可以自定义排序规则,String中已实现,自编写类要实现比较器规则,通过imlements comparble实现接口,再重写compareTo方法,该方法返回整型,正数为升序,非正为降序。
HashTable
底层封装哈希表,线程安全版本的HashMap集合,key和value不能为空,与HashMap的区别如下:
● 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
● 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
● 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
● Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。因为Hashtable使用的是安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。
如果你使用null值,就会使得其无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断。
● 快速失败(fail—fast)是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
总结
List是Java给我们在数组基础上改进形成的更方便的表结构,在存储添加单一信息时更加方便;Map结构则是一种映射关系,需要根据key来找到对应的value时使用;Set结构感觉同时继承二者,不大明白单独存在的必要性。