文章目录
- 2.4.1 超参数调整
- 一、batch size
- 二、 epochs
- 三、 Adam:learning rate
- 四、 Adam:weight_decay
- 五、 n_critic
- 2.4.2 模型改进
- 一、 超参数优化
- (一)batch size
- (二)learning rate
- (三)n_critic
- 二、 逐层归一化
- (一) 仅G使用归一化
- (二) Batch Normalization_batch
- (三) Layer Normalization_层数
- (四) Instance Normalization_爆炸
- (五) Group Normalization_参数
- (六) 结论
- 三、 损失函数改进
- (一) MSELoss
- (二) CrossEntropyLoss
- (三) BCEWithLogitsLoss
- 四、 激活函数选择
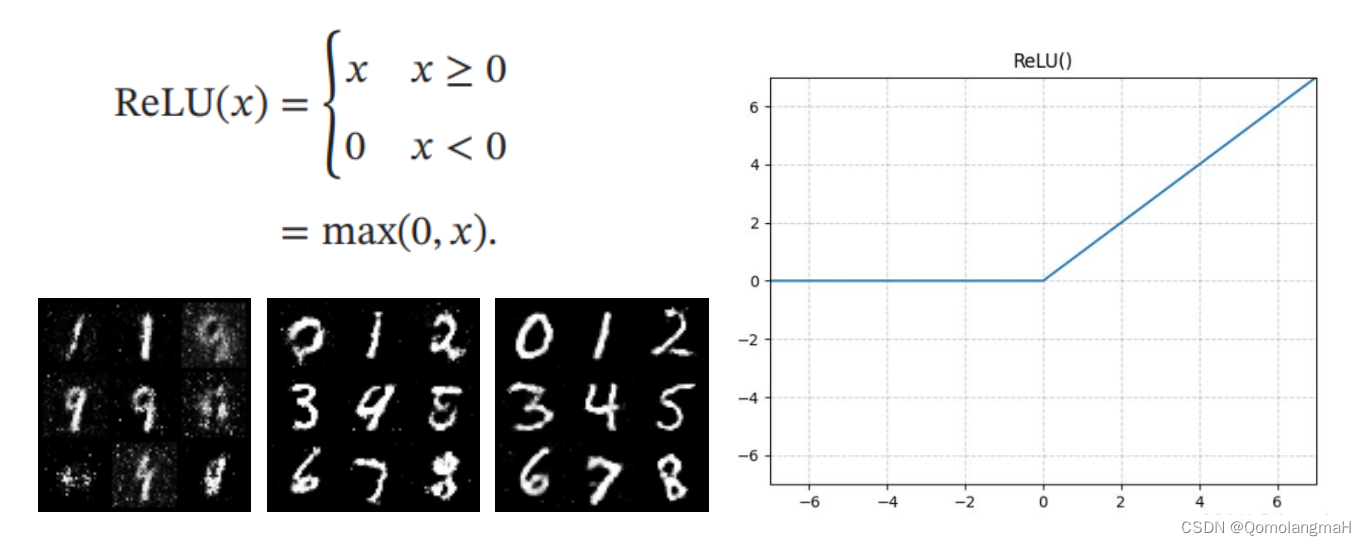
- (一) ReLU
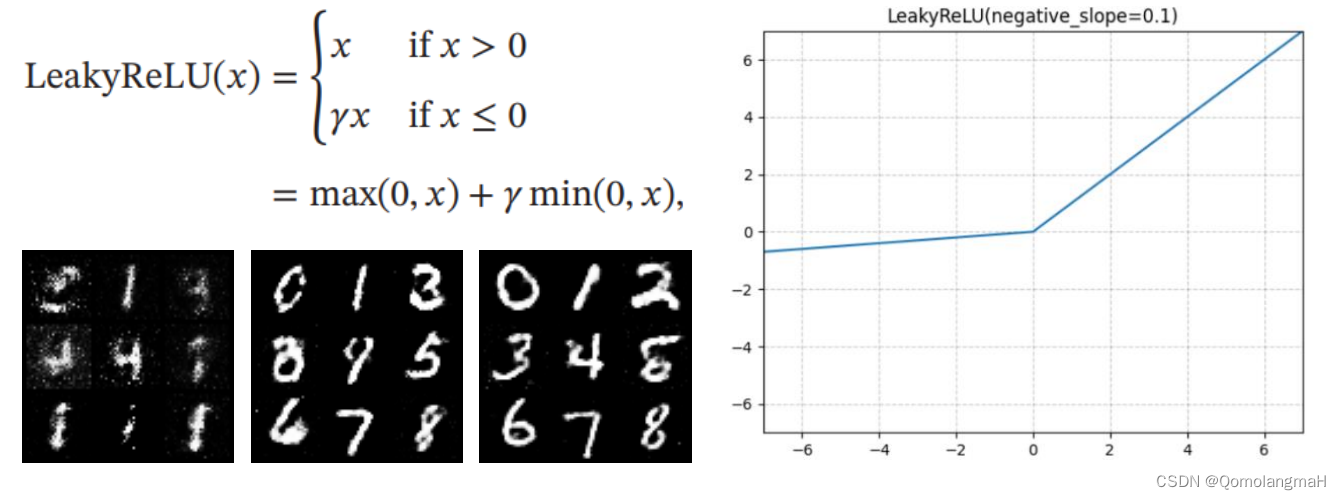
- (二) LeakyReLU
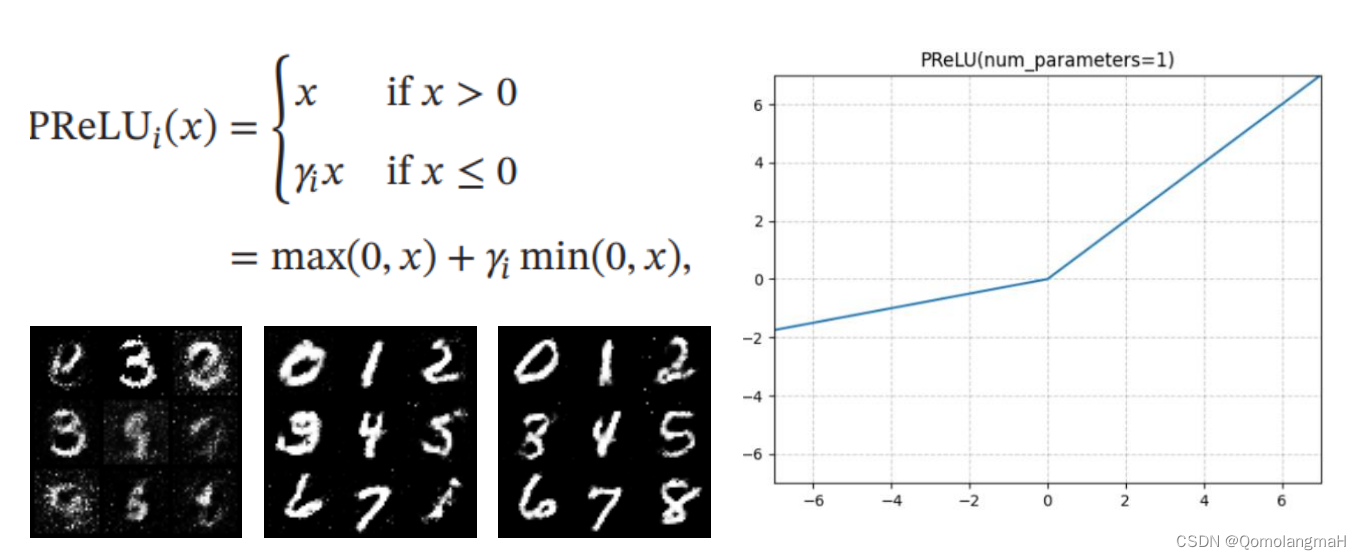
- (三) PReLU
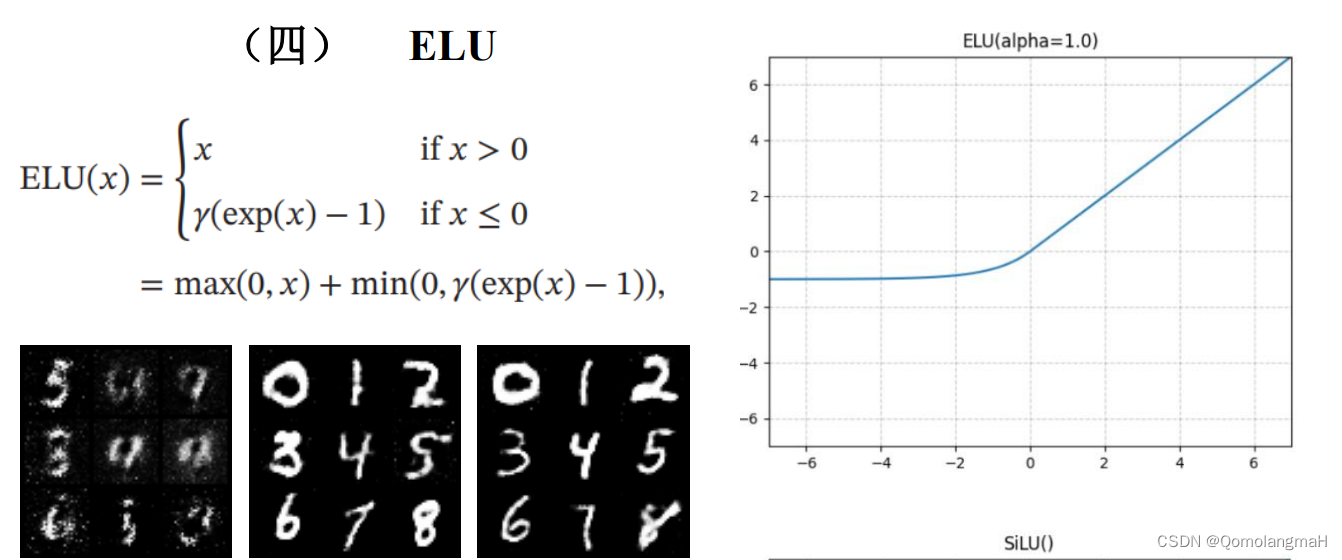
- (四) ELU
- (五) Swish(SiLU)
- (六) GELU
- (七) 结论
- 五、 优化器改进
- (一) AdamW
- (二) Adamax
- (三) RAdam
- 六、 噪声z的分布
- (一) 均匀分布
- (二) 拉普拉斯分布
- (三) 多变量高斯分布
- 七、 其余设想
- (一) 噪声z的维度
- (二) 条件标签C的处理
- (三) 网络层数
- (四) 网络结构改进
- (五) G与D使用不同的学习率
- (六) 再论逐层归一化
- (七) 再论激活函数
- (八) 网络正则化
- 2.4.3 模型测试
声明:本实验所述内容仅为个人胡说八道,不具备任何权威性。
本实验可视化工具:【深度学习实验】TensorBoard使用教程【SCALARS、IMAGES、TIME SERIES】
2.4.1 超参数调整
具体内容详见:【论文复现】基于CGAN的手写数字生成实验——超参数调整
一、batch size
二、 epochs
三、 Adam:learning rate
四、 Adam:weight_decay
五、 n_critic
2.4.2 模型改进
一、 超参数优化
关于超参数优化,有网格搜索、随机搜索、贝叶斯优化等多种方法,针对于本实验,由于设备限制选择手动调参,下面对实验结论进行总结:
(一)batch size
- a) 当batch size设置合适,此时再增加batch size大小,梯度也不会变得更准确;同时为了达到更高的训练网络精度,需要增大epoch,使训练时间变长;
- b) 大batch size不仅提高稳定性,还能减少训练时间;
- c) 考虑到训练时间及GPU限制,后续其它改进方案实验均使用batch size = 128。
(二)learning rate
- a) Adam优化器学习率太小,收敛速度慢,也可能会陷入局部最优点;学习率太大,loss振动幅度大,模型难以收敛;
- b) Adam权重衰减改善模型训练效果不明显,却加大了训练时间;
- c) 后续实验将使用lr_g = lr_d = 0.0001,不进行权重衰减。
(三)n_critic
- a) 生成器和判别器训练需要进行平衡,G和D频繁地交替训练会导致初始阶段不稳定,loss水平震荡。
- b) n_critic越大,loss进入收敛状态越快,但同时也会使得训练过程变得更加缓慢,后续依旧使用 n_critic = 5进行实验。
二、 逐层归一化
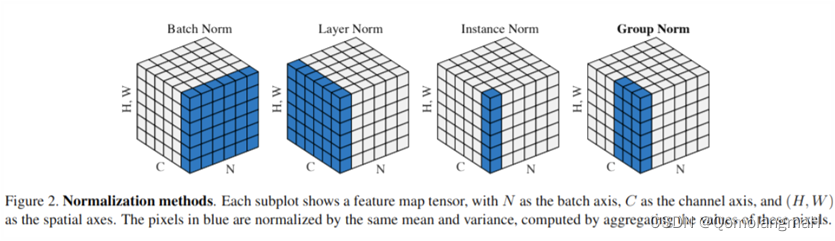
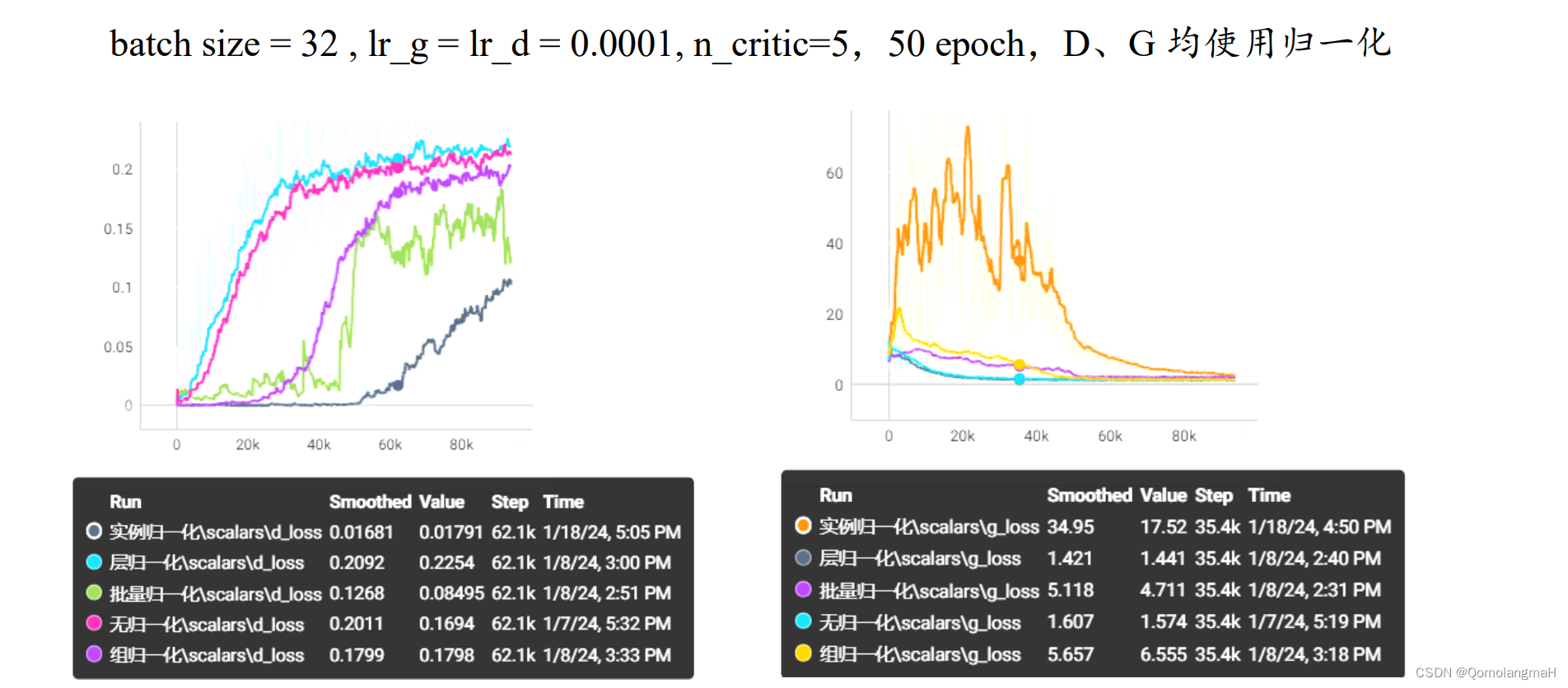
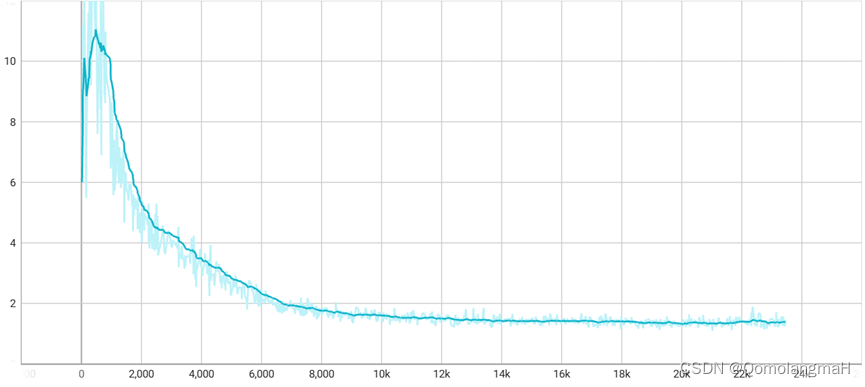
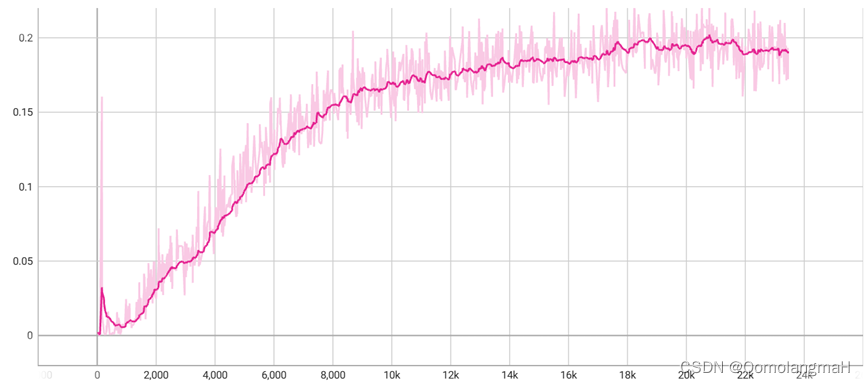
D、G均使用归一化时,相较于不使用归一化方法,只有层归一化对模型收敛起到了积极的作用,其它方法效果很差,其中实例归一化效果最差40 step内明显震荡,此后开始收敛。层归一化在每层的输出上进行归一化,确保了下一层输入分布相对稳定,有利于网络的训练和收敛。 为什么组归一化和批量归一化在中间位置,效果接近?为什么组归一化不接近层归一化?为什么实例归一化如此抽象?为什么批量归一化效果反而差? 我对各种逐层归一化进行了大量实验,下面将对有所发现的实验结果进行展示:
(一) 仅G使用归一化
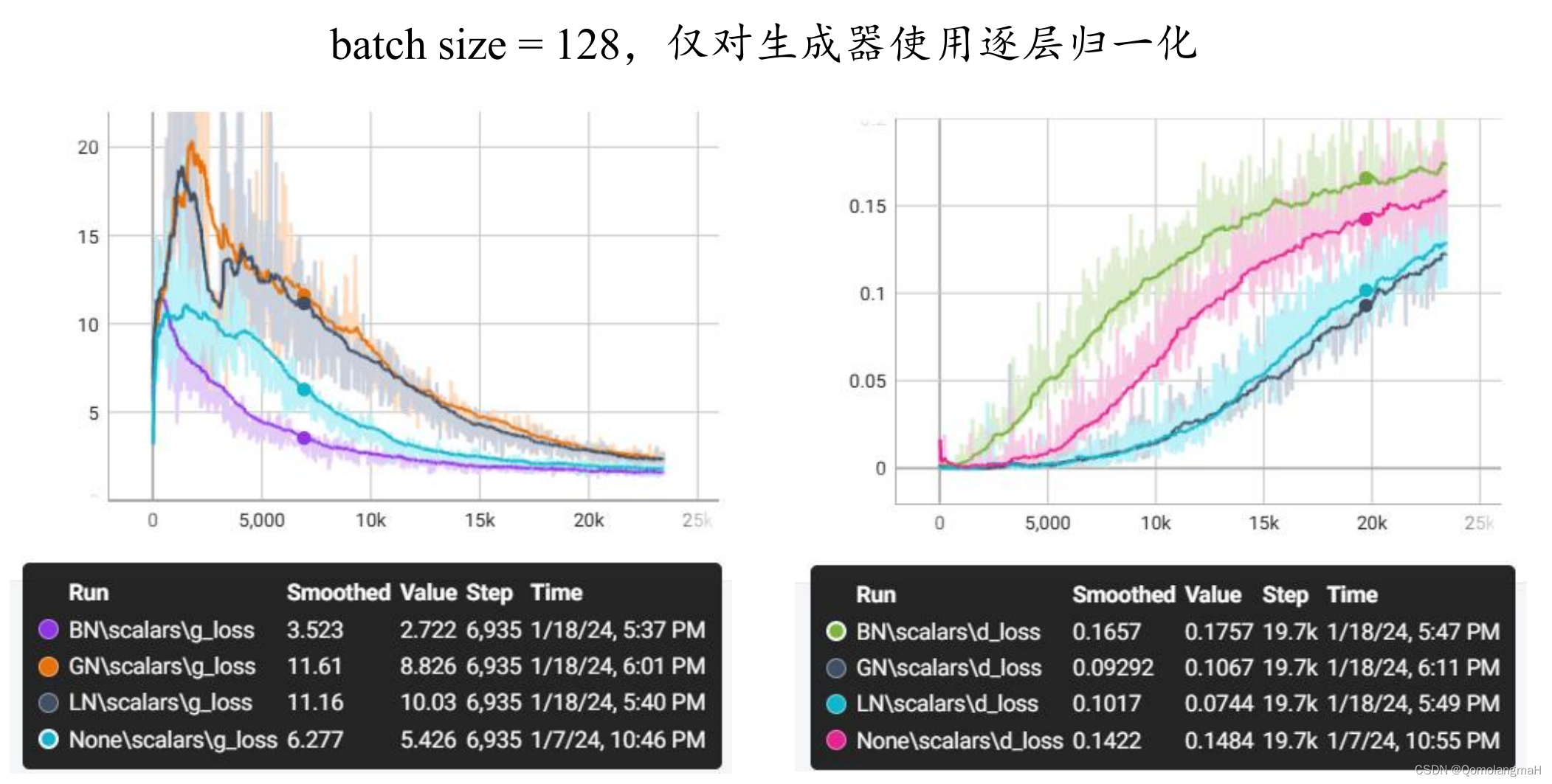
如图所示,仅对生成器使用逐层归一化时,组归一化性能接近层归一化,二者的loss损失下降缓慢,均劣于不进行归一化,而批量归一化反而稳定性更好,网络更快收敛。
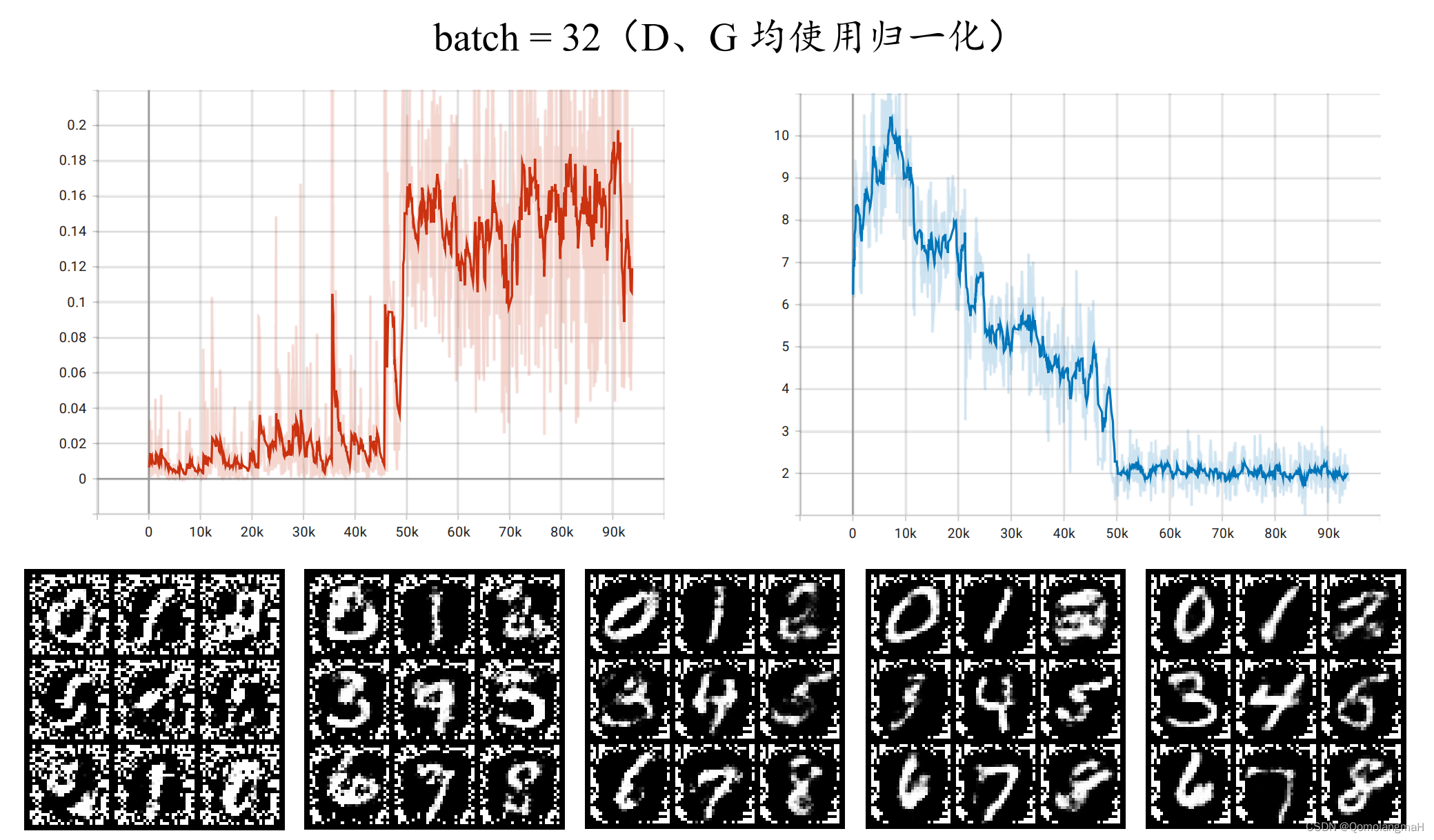
同时对生成器和判别器使用批量归一化时,生成图像边缘全是噪点,我觉得是因为批量归一化相当于在训练过程中引入了额外的噪音,导致判别器的训练不稳定,50k step 时d-loss曲线突然直线上升(g-loss直线下降),最终生成图像的质量差。而仅对生成器进行批量归一化生成图片质量很好,且收敛速度更快:
(二) Batch Normalization_batch



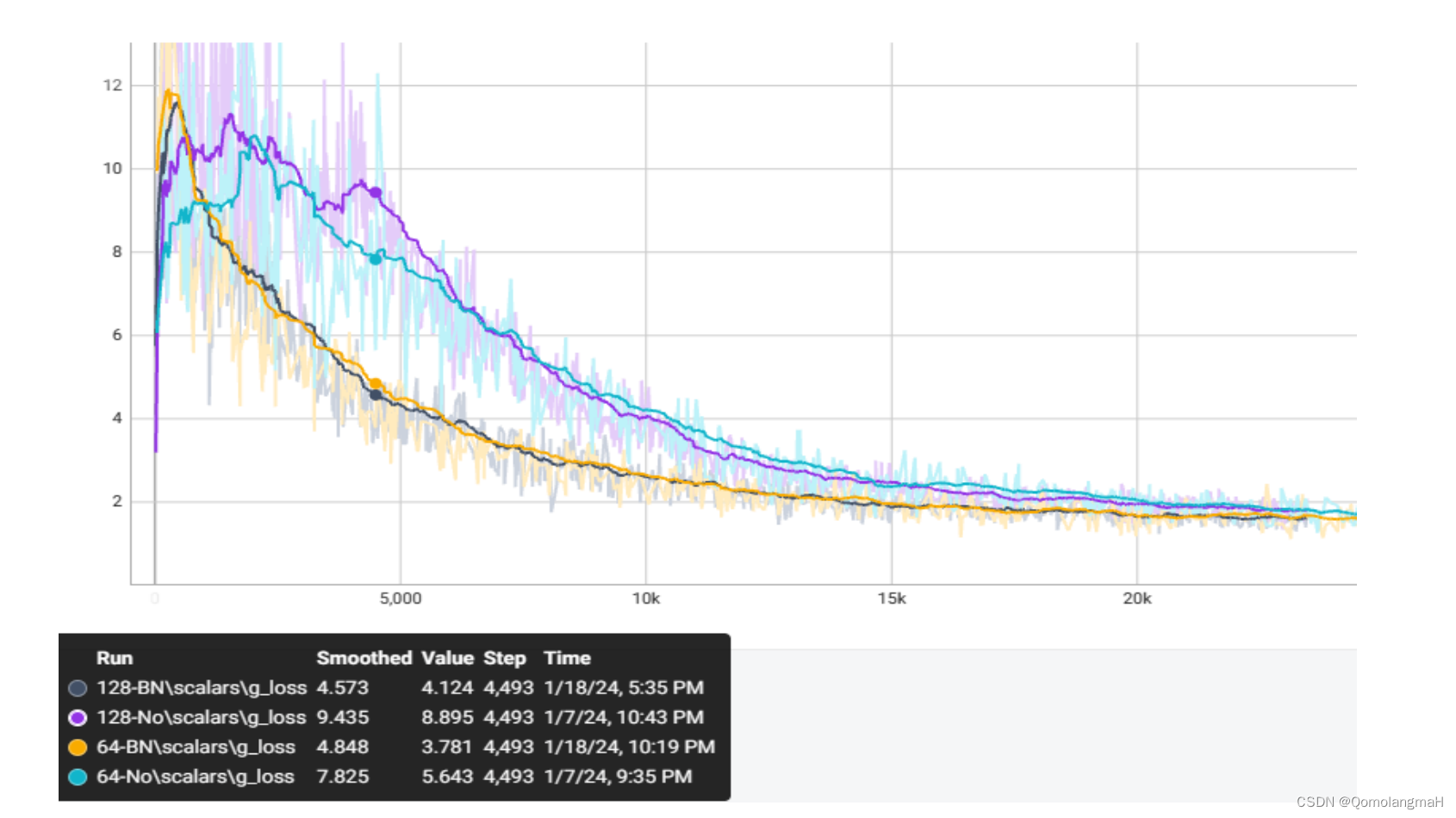
批量归一化可以使模型更快速地学习数据分布,减缓训练过程中的振荡,加快模型的收敛过程。但batch size不能太小,否则计算的均值、方差不足以代表整个数据分布。而如果batch size太大,即使内存容量允许,也需要跑更多的epoch,导致训练时间变长。
(三) Layer Normalization_层数


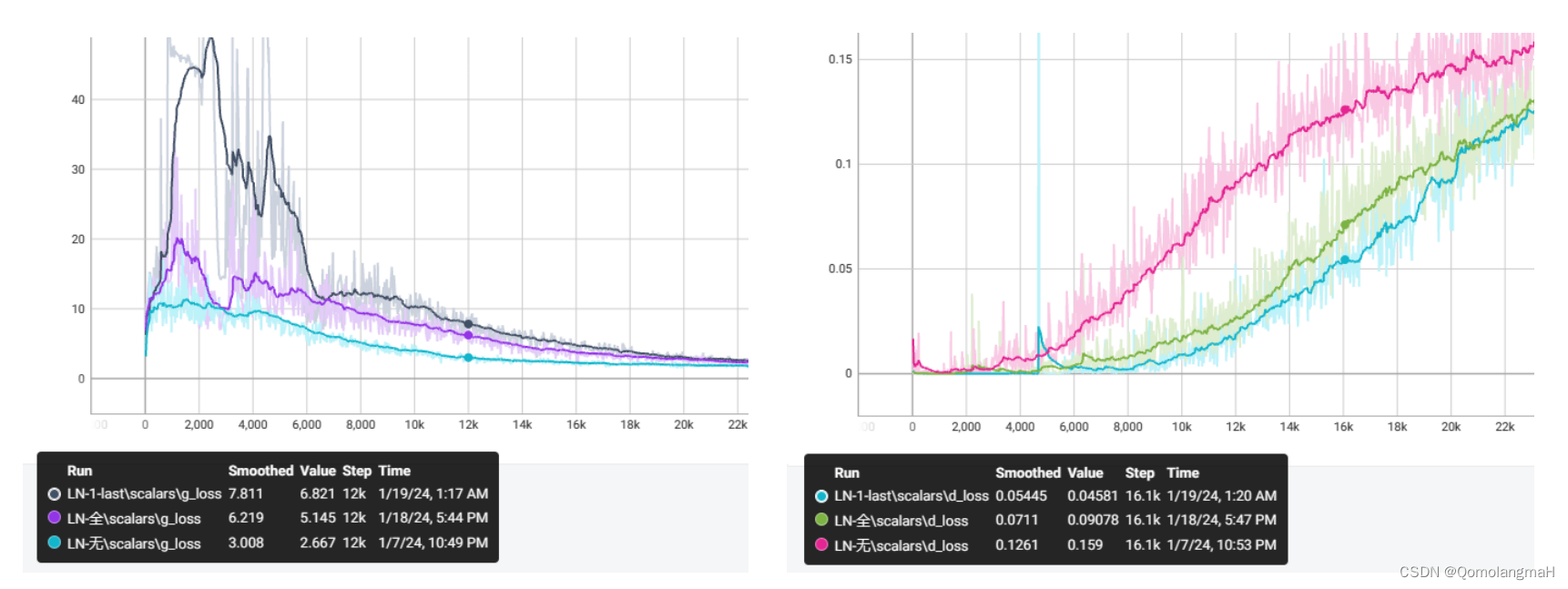
层归一化对某一层的所有神经元输入进行归一化,本应缓解梯度爆炸问题,使训练更加稳定和快速。但却不适用于本实验,本实验中不使用层归一化效果反而好,并且减少归一化层数反而会加快生成器的收敛速度。
(四) Instance Normalization_爆炸
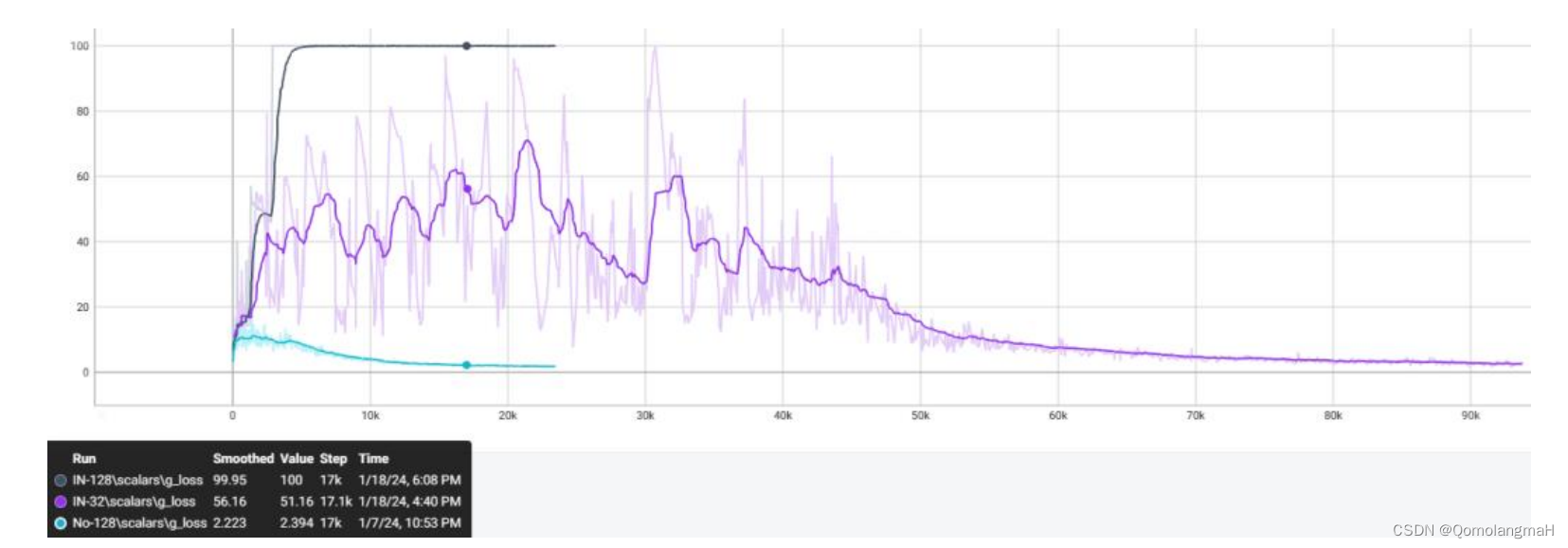
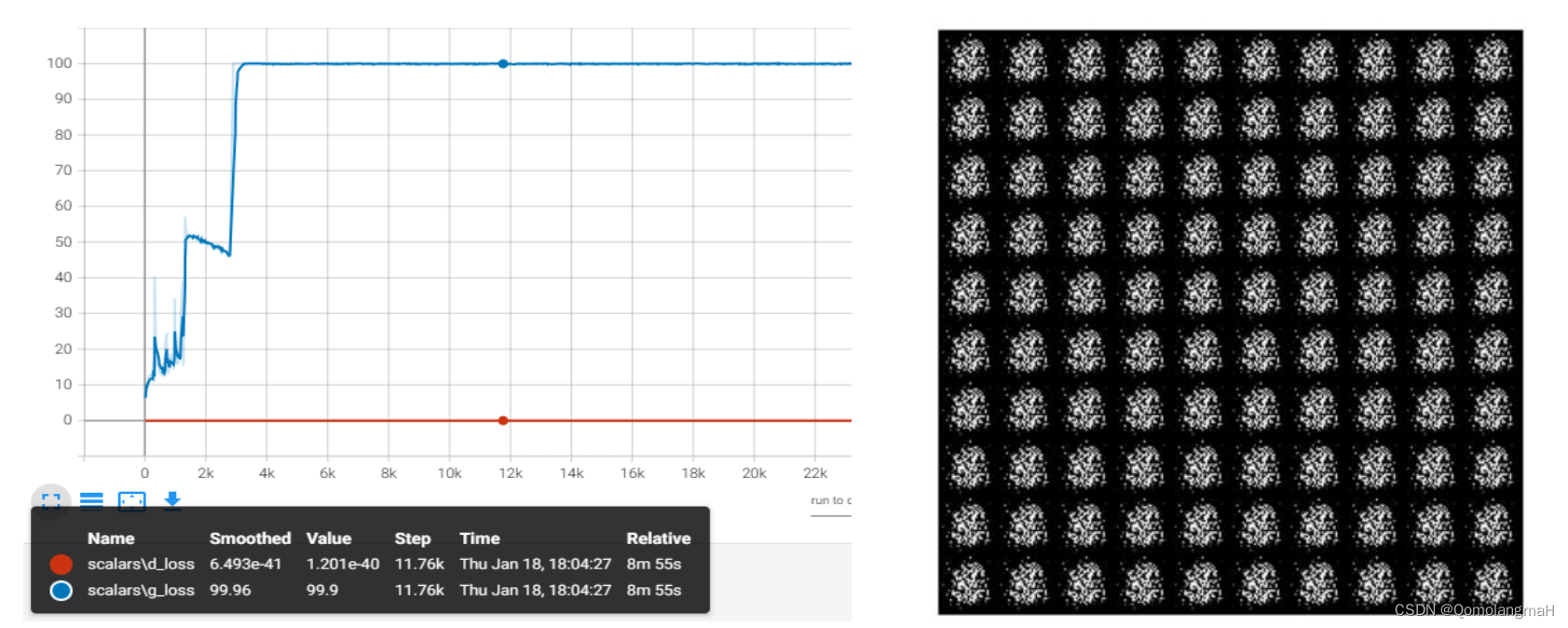
batch size = 32时效果最差,40k step持续震荡,实例归一化在每个样本的特征上进行归一化,即对样本的每个像素点的信息进行归一化,导致了对每个样本的敏感性强,不利于网络的稳定性,因而40k step内明显水平震荡,需要较长训练时间才开始进入收敛。而当batchsize=128时,生成器直接损失爆炸、判别器损失为0,这里暂时得出结论,实例归一化不适用CGAN手写数字生成实验,亦或与其它超参数设置有关,有待进一步探索……
(五) Group Normalization_参数
GN的其极端情况就是LN和IN,最初实验中,组归一化参数设置过小,更逼近IN,所以效果差。而如前文所述,BN效果差是因为对判别器也使用归一化,所以虽然GN和BN在中间位置效果接近,但其本质上并无关联。适当修改组归一化参数,并在不同batch size上进行实验,可观察到GN效果很好,甚至接近BN:


(六) 结论
BN能够解决内部协方差偏移问题,可以使得模型更快速地学习数据分布,减缓训练过程中的振荡,加快模型的收敛过程,模型改进成功!MNIST图像数据特征维度间同质化,组归一化也比较合适(本质上,GN就是为了改善BN的不足而来的),反观LN 和 IN 则基本完全不适用。
三、 损失函数改进
本实验使用的是BCELoss(测量目标值和输入概率之间的二元交叉熵),下面尝试使用不同激活函数:
(一) MSELoss
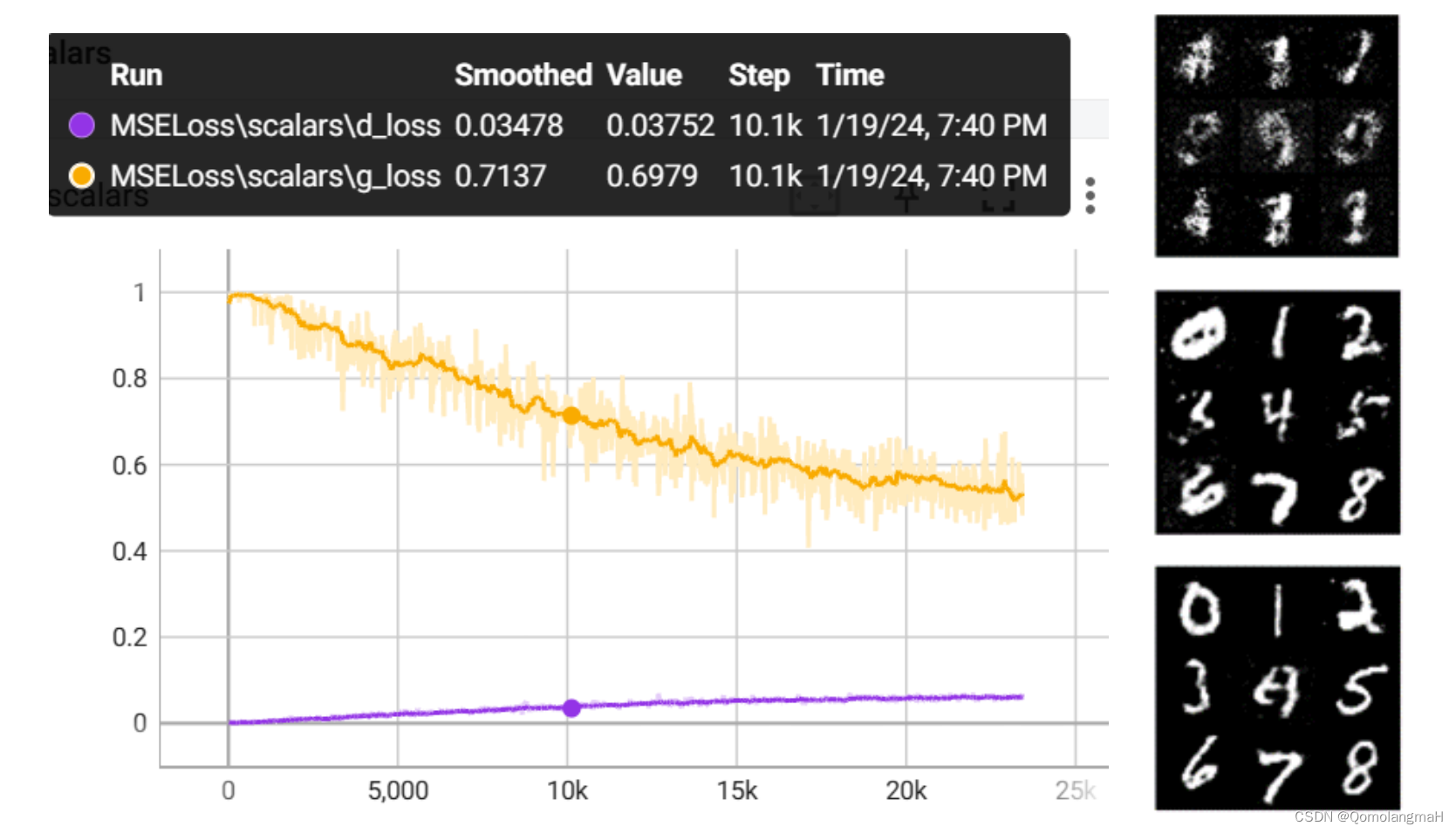
即最小二乘损失,能在训练初期避免D梯度消失和G梯度爆炸。
(二) CrossEntropyLoss
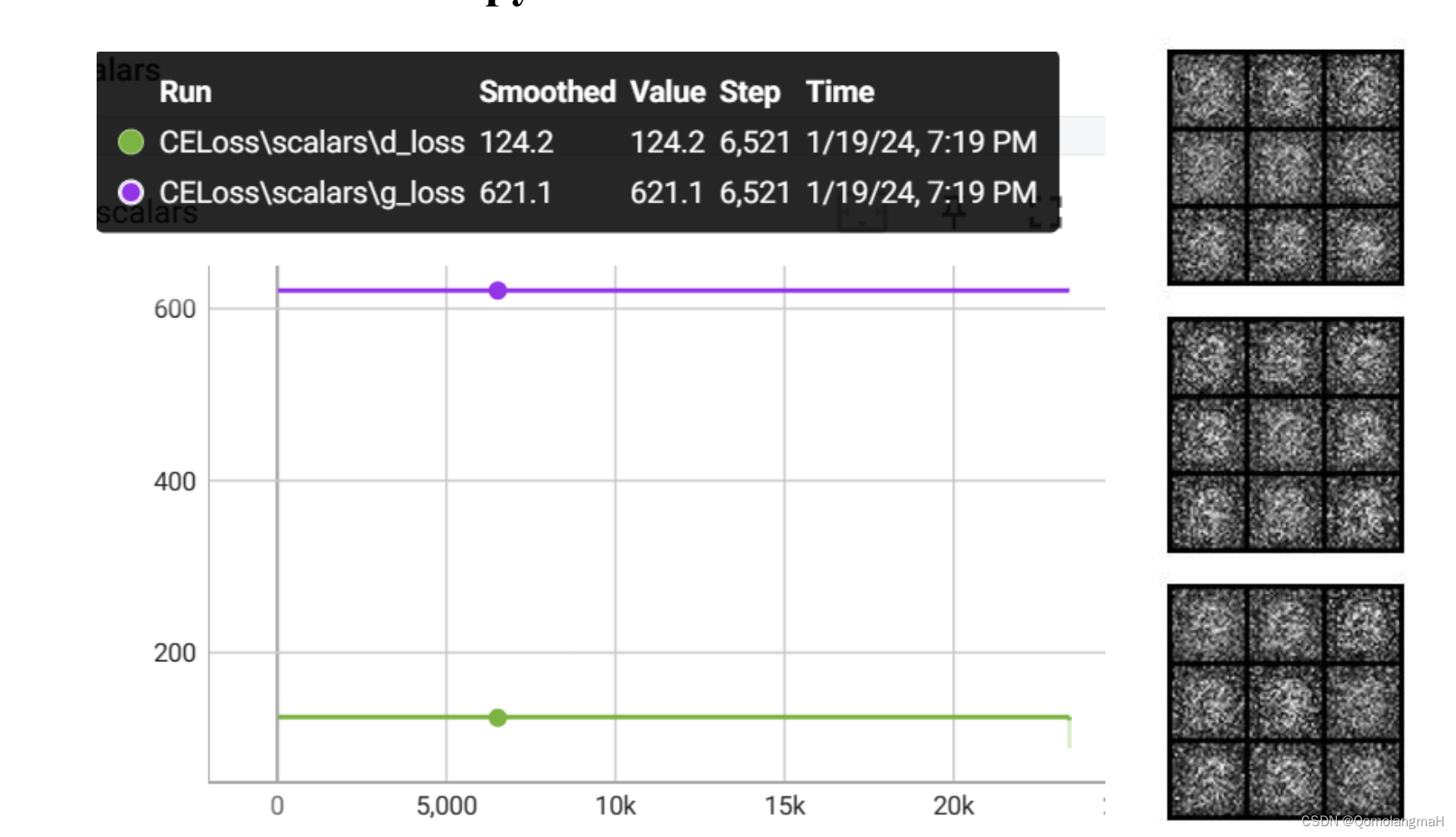
即交叉熵损失,完全不适用于本实验。
(三) BCEWithLogitsLoss
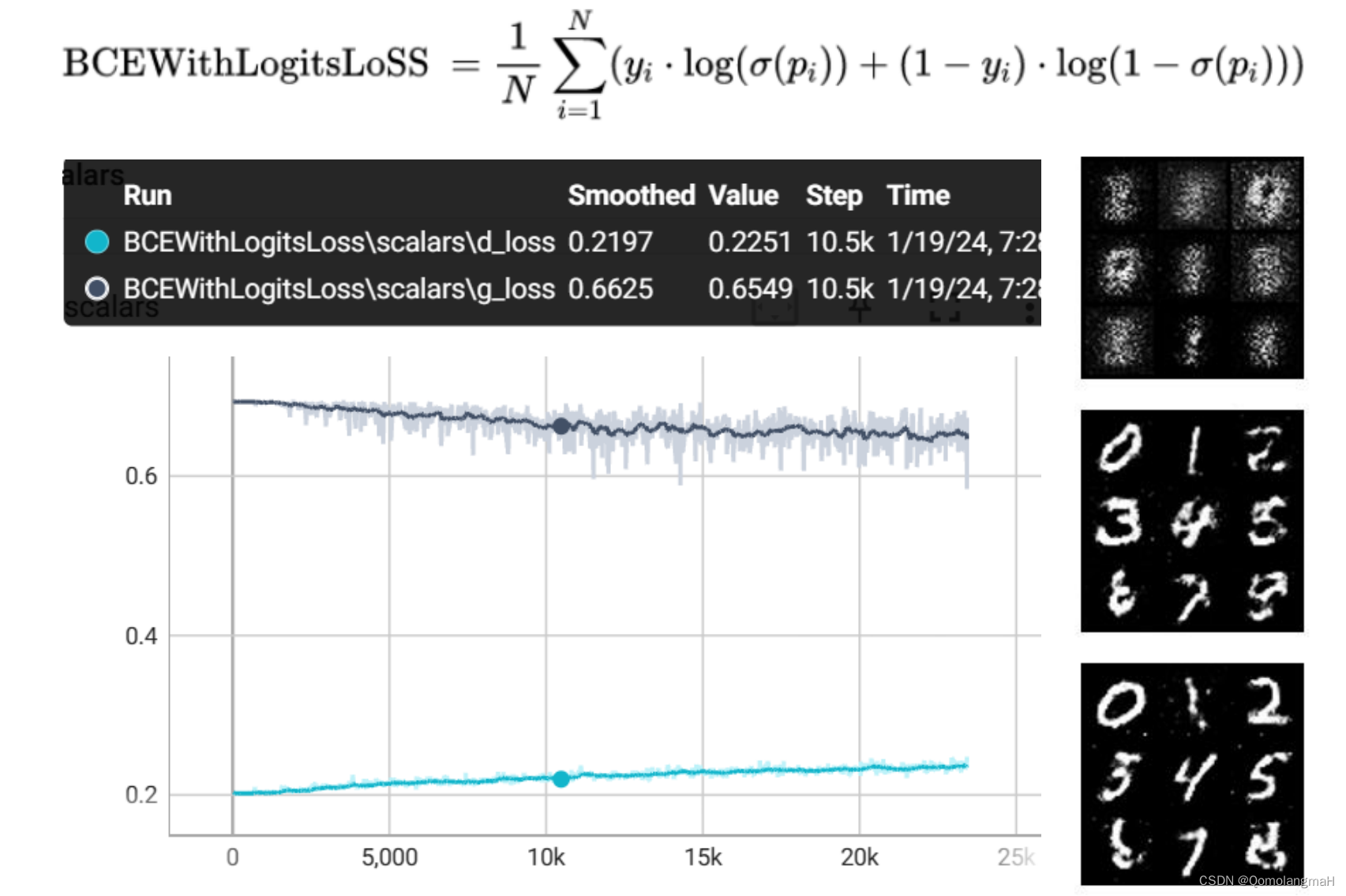
即Sigmoid + BCELoss ,实验2中的vanilla,与MSELoss一样,能够避免出现损失值过大或过小的情况,优化训练初期。接下来需要调整其它超参数,才能进一步提高图像生成质量。
四、 激活函数选择
本实验使用的是LeakyReLU激活函数,下面尝试使用不同激活函数,其中生成数字图像分别在1250、11300、23450 step
(一) ReLU
(二) LeakyReLU
(三) PReLU
(四) ELU
(五) Swish(SiLU)

(六) GELU
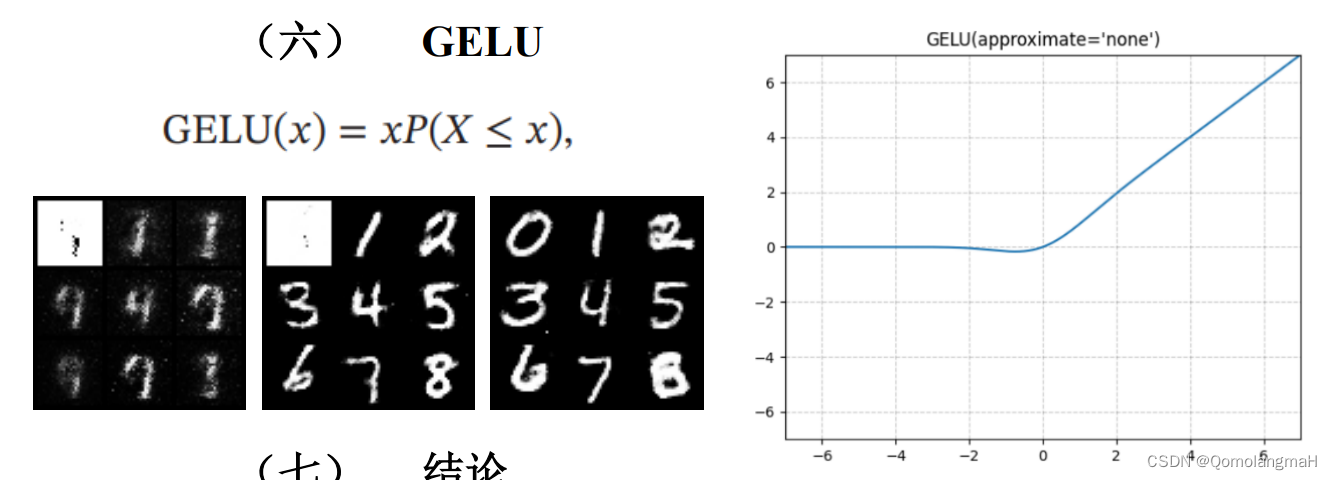
(七) 结论
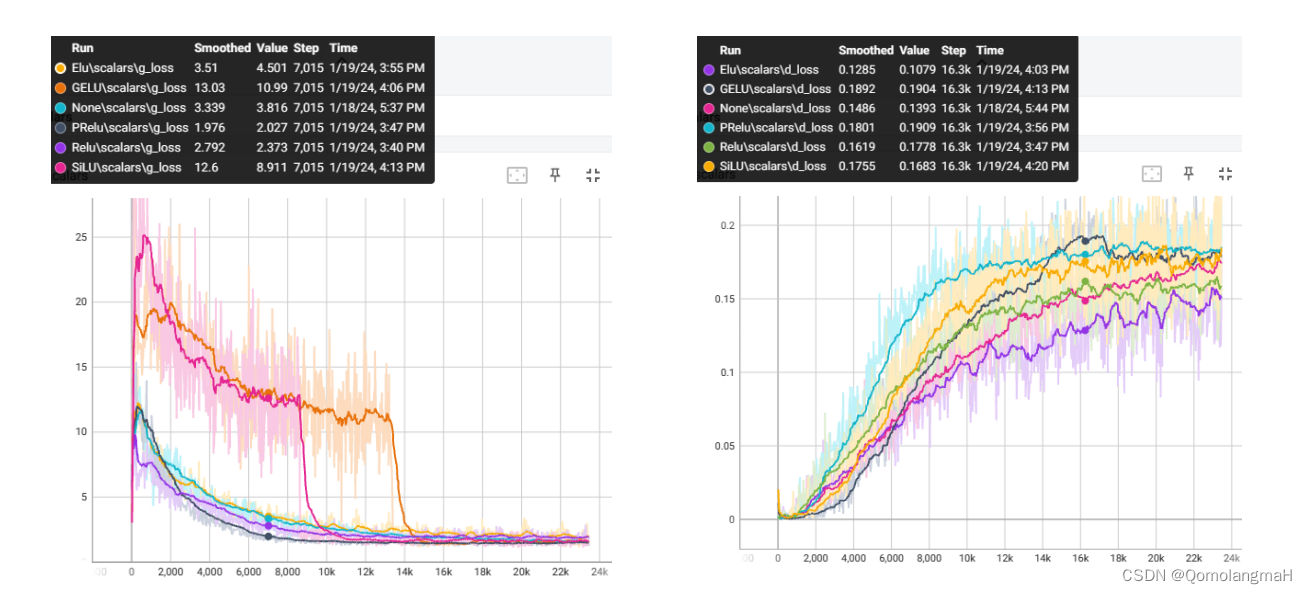
- g_loss:PReLU>ReLu>ELU>LeakyReLU>SiLu>GELU
- d_loss:PReLU>SiLu >GELU >ReLu >LeakyReLU>ELU
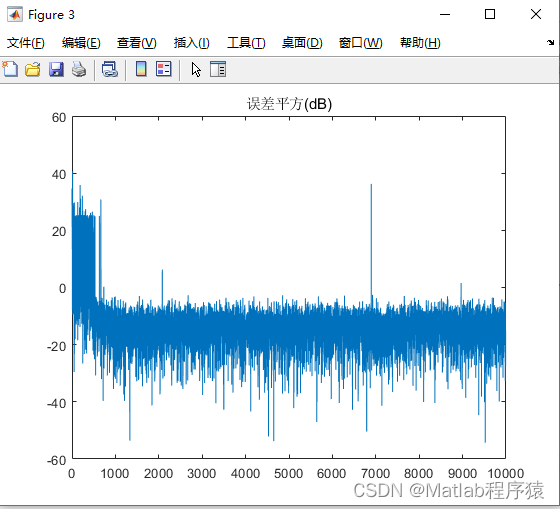
无论是生成器还是判别器,PReLU比其他激活函数收敛得更快,模型改进成功!至于其它激活函数的效果排序,个人认为一次实验具有偶然性,后续使用其它超参数进行实验也得出了不同顺序,但PReLU始终最优。
观察到g_loss 曲线SiLu 9k step前下降缓慢,9kstep骤降;GELU 14k step前下降缓慢此后骤降。且二者生成的手写数字存在少量白底黑噪点图片,与正常的黑底白字大相径庭,猜测是其参数设置问题,也或许与其它超参数设置有关,有待进一步实验……
五、 优化器改进
本实验使用的是Adam优化器,可尝试选择其它优化器
# Use Adam optimizer for updating discriminator's parameters
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=lr_d, weight_decay=1e-2)
# Use Adam optimizer for updating generator's parameters
g_optimizer = torch.optim.Adam(generator.parameters(), lr=lr_g, weight_decay=1e-2)
(一) AdamW
Adam的进化版,比Adam收敛得更快:

查询资料可知,L2正则和Weight Decay在Adam算法中并不等价,只有在标准SGD的情况下,可以将L2正则和Weight Decay看做一样。由于Adam加入了一阶动量和二阶动量,基于包含L2正则化项的梯度来计算一阶动量和二阶动量,使得参数的更新系数就会变化,与单纯的权重衰减就会变得不同。正如超参数调整Adam:weight_decay实验结果所示,使用Adam优化带L2正则的损失并不有效,反而浪费时间。

(二) Adamax
Adamax基于无穷范数的Adam的变体,即将L2范数推广为无穷范数。
(三) RAdam
Rectified Adam能根据方差分散度,动态地打开或者关闭自适应学习率,提供了一种不需要可调参数学习率预热的方法。
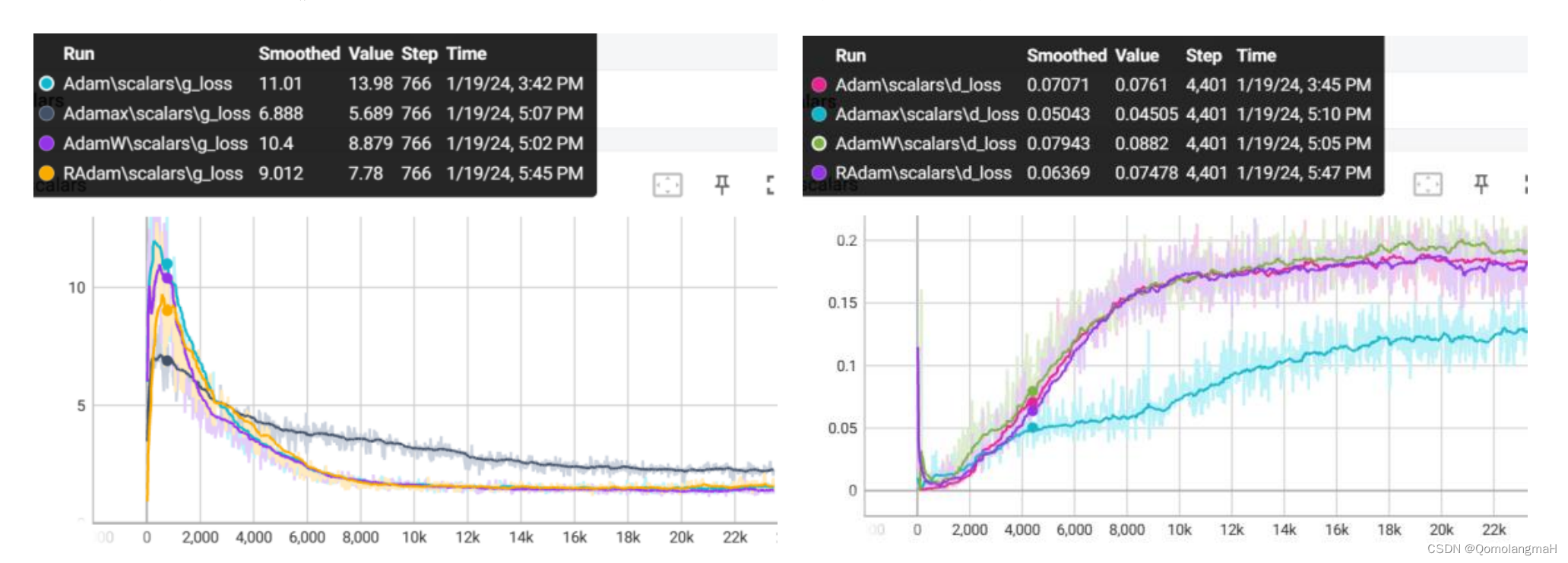
Adamax效果最差不适用于本实验,其余的训练稳定性大致复合Radam > AdamW > Adam,果然各变种的提出是有意义的……
六、 噪声z的分布
随机噪声向量z用于生成伪造的样本数据。在训练过程中,随机噪声向量z会被输入到生成器中,生成器会将其转换为与真实样本类似的数据,然后与真实样本一起输入到判别器中进行训练。本实验噪声向量选用高斯分布:
# Generate random noise vector z
z = Variable(torch.randn(batch_size, 100)).to(device)# Generate random labels for the fake images
fake_labels = Variable(torch.LongTensor(np.random.randint(0, 10, batch_size))).to(device)# Generate fake images using the generator
fake_images = generator(z, fake_labels)
(一) 均匀分布
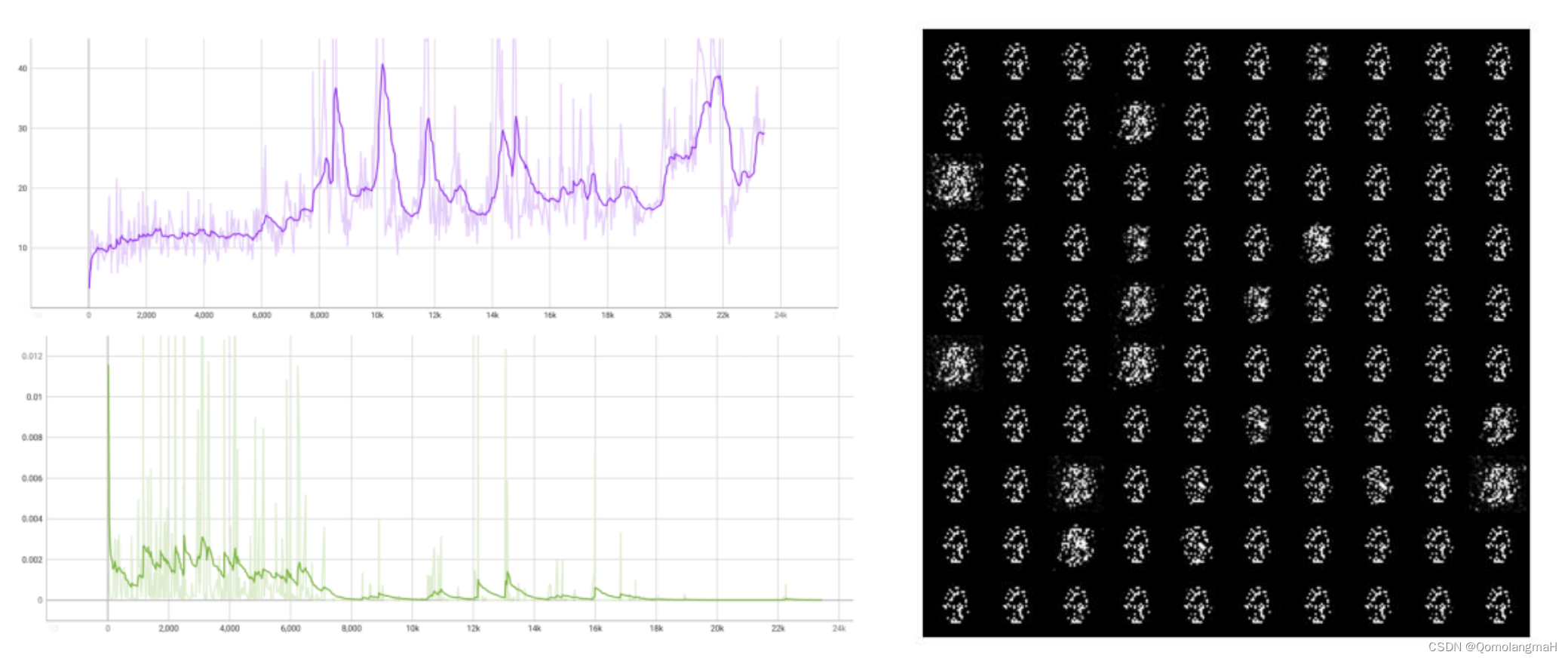
(二) 拉普拉斯分布
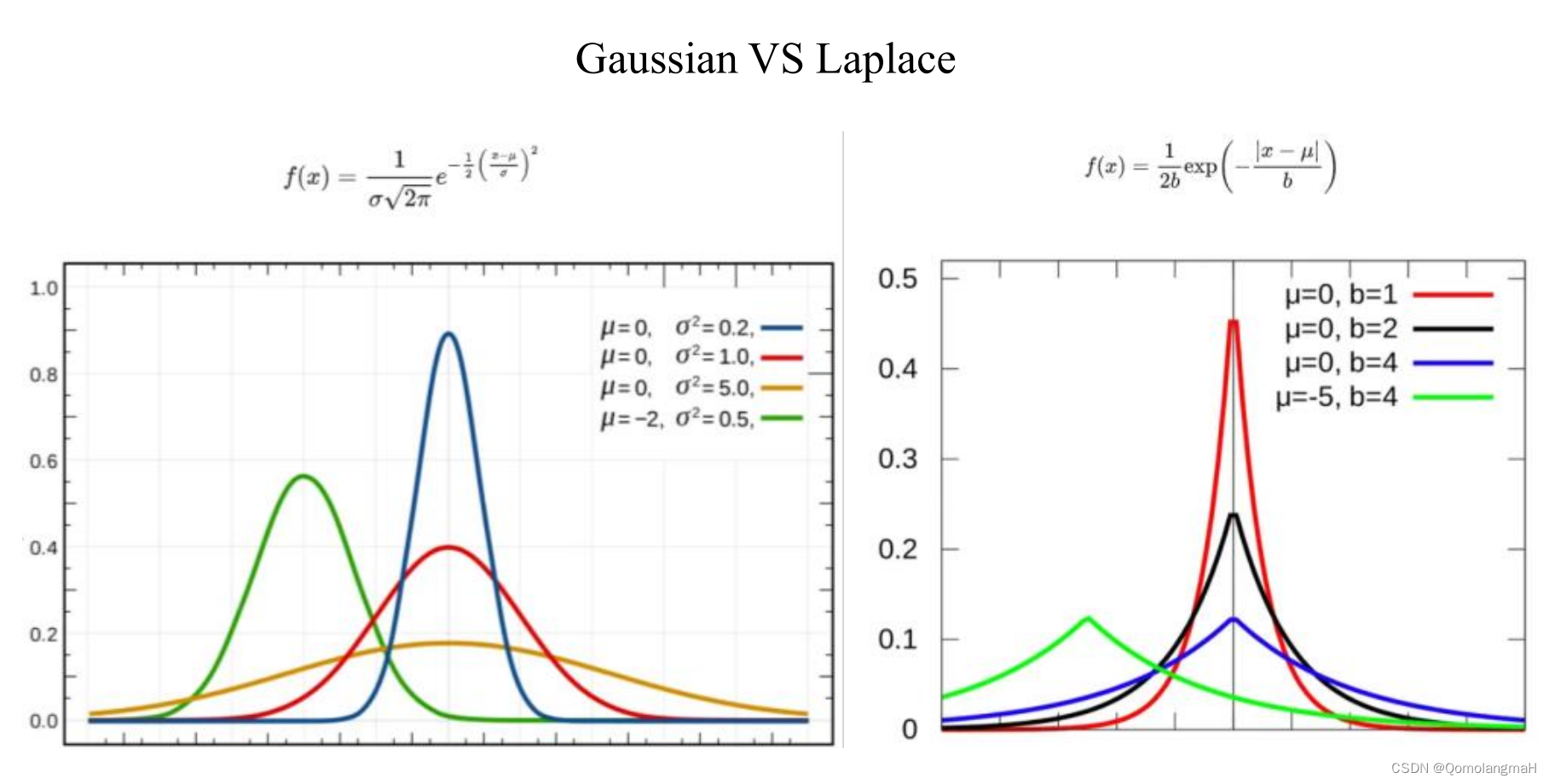
(三) 多变量高斯分布
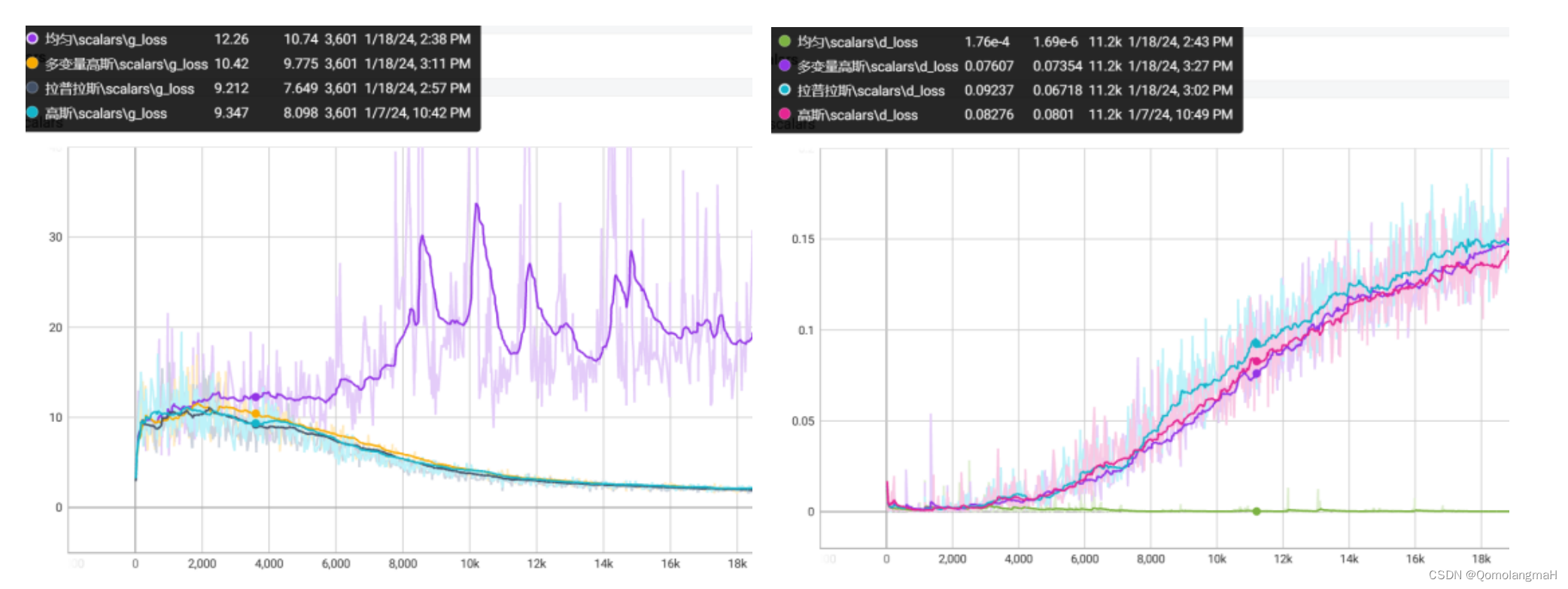
均匀分布完全不适用,高斯与拉普拉斯效果接近,未尝试其余分布,模型暂时没有得到优化。
七、 其余设想
下面正式开始胡说八道……
(一) 噪声z的维度
# Generate random noise vector z
z = Variable(torch.randn(batch_size, 100)).to(device)# Generate random labels for the fake images
fake_labels = Variable(torch.LongTensor(np.random.randint(0, 10, batch_size))).to(device)# Generate fake images using the generator
fake_images = generator(z, fake_labels)
本实验采用100维的随机噪声,尝试使用其它维度,并修改网络参数,效果并未改善,所以到底多少维比较适合呢?
(二) 条件标签C的处理
本实验中的CGAN在条件标签的处理上,用的是concatenate操作,也就是在某个维度上,直接叠加相关数据。
z = z.view(z.size(0), 100) # Reshape the input latent vector
c = self.label_emb(labels) # Obtain embeddings for the corresponding labels
x = torch.cat([z, c], 1) # Concatenate latent vector and label embeddings
out = self.model(x) # Pass the concatenated input through the generator network
还可不可以用别的操作来改善效果?本人很菜,还没有试过。
(三) 网络层数
增加神经网络的层数能提高表征能力(通用近似定理),但也会增加训练的难度,深层网络更容易出现梯度消失和梯度爆炸问题,且有过度拟合风险,故本实验仅使用四层。
(四) 网络结构改进
CGAN 网络使用的是全连接层,如果采用卷积等其它结构(如DCGAN),额……CDCGAN?或许能使模型进一步优化。
# Neural network layers for the generator
self.model = nn.Sequential(nn.Linear(110, 256), # Input size is 100 (latent vector size) + 10 (embedding size for labels)nn.LeakyReLU(0.2, inplace=True), # LeakyReLU activation functionnn.Linear(256, 512), # Hidden layer with 512 unitsnn.LeakyReLU(0.2, inplace=True),nn.Linear(512, 1024), # Hidden layer with 1024 unitsnn.LeakyReLU(0.2, inplace=True),nn.Linear(1024, 784), # Output layer with 784 units (MNIST image size)nn.Tanh() # Hyperbolic tangent activation function for mapping output to [-1, 1]
)
(五) G与D使用不同的学习率
本实验lr_g = lr_d, 若尝试不同学习率,或许能加速模型收敛,由于时间因素,尚未进行实验。
(六) 再论逐层归一化
- G与D使用不同的归一化方法,效果如何?
- 仅对D使用归一化,效果如何?
- 是否“逐层”归一化?
- 归一化方法混合使用?
(七) 再论激活函数
- 激活函数与归一化先后顺序(先BN后Relu/先Relu后BN)
- 不同激活函数与不同归一化方法的n种组合……
(八) 网络正则化
- 提前停止
- 训练过程加入早停法?
- 丢弃法
- dropout参数设置
- 数据增强
- MNIST数据集有没有必要进行旋转、翻转、缩放、平移、亮度色度对比度调整等操作?
- 标签平滑
- 条件标签C的平滑处理?
2.4.3 模型测试
Batch Normalization + PReLU激活函数+AdamW优化器: