大家好,今儿咱们来说说关于随机森林的一些核心点~
首先,随机森林是一种集成学习方法,通过组合多个决策树来进行预测。每个决策树都是在不同的数据子集上训练的,同时引入了随机性,使得每棵树都有差异。
最终的预测结果是通过对所有树的预测结果进行平均或投票得到。
基本决策树
随机森林的基础是决策树。决策树是一种树状结构,每个节点表示一个特征,每个叶子节点表示一个类别或一个数值。学习过程是递归的,根据选择的特征将数据划分成子集,直到达到停止条件。
随机性引入
-
随机抽样: 针对每个决策树的训练集,从原始数据集中进行随机抽样(有放回抽样),形成不同的训练子集。这使得每棵树的训练集都是略有不同的。
-
随机特征选择: 在每次决策树的节点划分时,随机选择一个特征进行划分。这防止了某个特定特征对模型的过度依赖。
Bootstrap Aggregating (Bagging)
-
针对每个随机抽样得到的训练子集,训练一个独立的决策树。
-
预测时,对所有决策树的输出取平均(回归问题)或进行投票(分类问题)。
预测
-
对于回归问题,将所有决策树的预测结果取平均。
-
对于分类问题,进行投票,选择得票最多的类别作为最终预测。
随机森林核心公式:
对于回归问题:
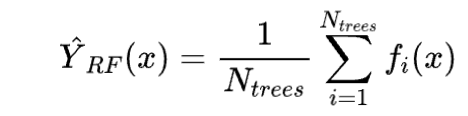
对于分类问题:
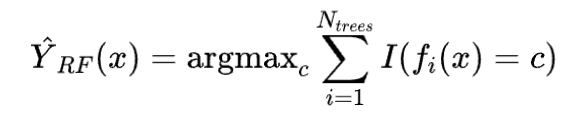
其中:
-
是随机森林的预测结果。
-
是随机森林中决策树的数量。
-
是第 棵决策树的预测结果。
-
是指示函数。
一个核心代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor# 生成随机数据集
rng = np.random.RandomState(1)
X = np.sort(200 * rng.rand(600, 1) - 100, axis=0)
y = np.pi * np.sin(X).ravel() + 0.5 * rng.rand(600)# 创建随机森林模型
n_trees = 100
max_depth = 30
regr_rf = RandomForestRegressor(n_estimators=n_trees, max_depth=max_depth, random_state=2)
regr_rf.fit(X, y)# 生成新数据进行预测
X_test = np.arange(-100, 100, 0.01)[:, np.newaxis]
y_rf = regr_rf.predict(X_test)# 绘制结果
plt.figure(figsize=(10, 6))
plt.scatter(X, y, edgecolor="k", c="navy", s=20, marker="o", label="Data")
plt.plot(X_test, y_rf, color="darkorange", label="Random Forest Prediction", linewidth=2)
plt.xlabel("Input Feature")
plt.ylabel("Target")
plt.title("Random Forest Regression")
plt.legend()
plt.show()
这段代码创建了一个包含随机噪声的正弦波形数据集,然后使用随机森林回归模型进行拟合,并在图中展示了拟合结果。
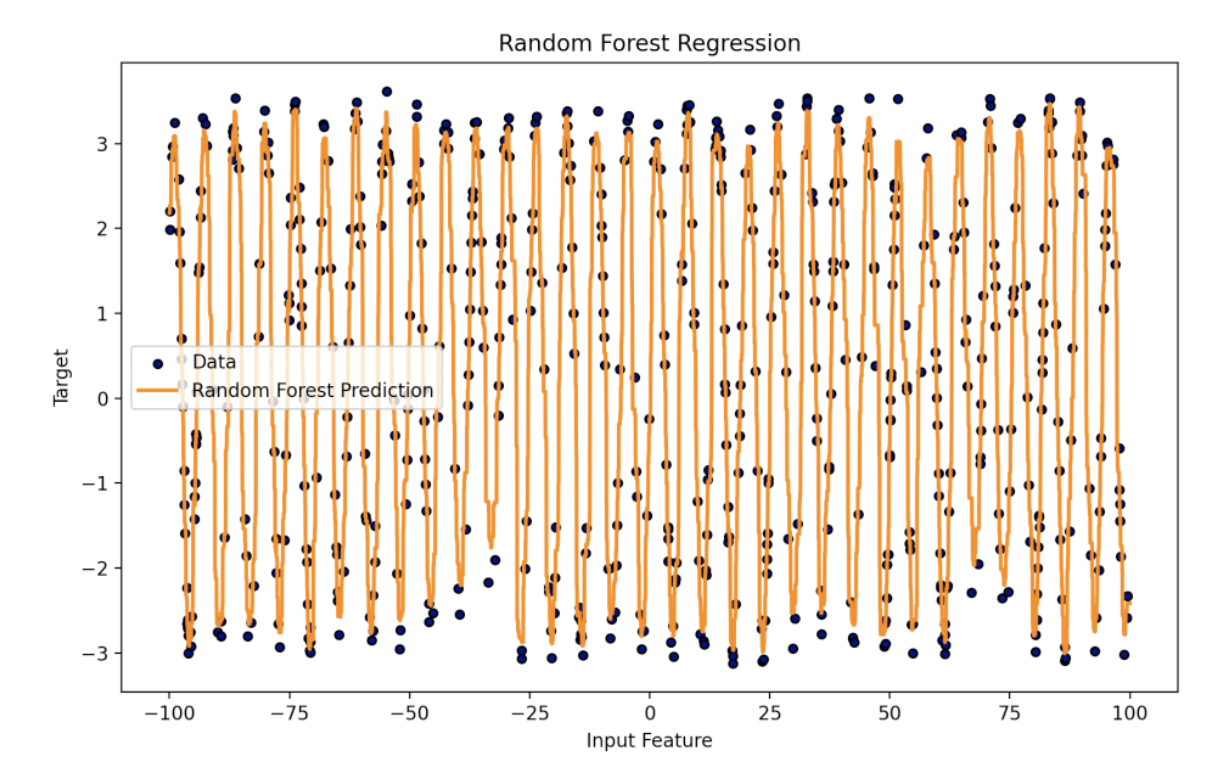
随机森林通过引入随机性和集成多个决策树的预测结果,提高了模型的泛化能力和鲁棒性。它适用于回归和分类问题,并在处理高维数据、大规模数据集和复杂任务时表现良好。
然而,需要注意过多的树可能导致过拟合,而较少的树可能导致欠拟合。在实际应用中,调整超参数(如树的数量和深度)是调整模型性能的关键。
最后
每天一个简单通透的小案例,如果你对类似于这样的文章感兴趣。