📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前服务于工业互联网
擅长主流Oracle、MySQL、PG、高斯及Greenplum运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 📣 1.背景
- 📣 2.方案
- 📣 3.大表转分区
- ✨ 3.1 数据库参数调整
- ✨ 3.2 分别导出表结构和数据
- ✨ 3.3 备份原表
- ✨ 3.4 新建原表
- 3.5 在线分区
- 📣 4.SQL调优
- ✨ 4.1 慢查询开启
- ✨ 4.2 DB参数优化
- ✨ 4.3 索引创建原则
- ✨ 4.4 查询建议
- 📣 5.总结
想起以前刚面试入职的第一家公司,也是自己真正入行DBA,就遇到了MySQL 亿级大表调优这个事儿!
📣 1.背景
想起以前刚面试入职的第一家公司,也是自己真正入行DBA,就遇到了MySQL亿级大表调优这个事儿!** 实例(主从复制架构)*** 告警中每天凌晨在Zabbix报警,从报警来看存在一定的主从延迟。** 实例的慢查询数量在慢查询记录中很多,系统数据写入很大,大多是都是一些历史数据,** 应用那方每天在做手动删除一个月前数据的任务,应用每天都在抱怨,备份蛮烦,日常运维太闹心了,那接下来我们就开始做大表转分区及慢查询调优的工作
📣 2.方案
对于业务繁忙的数据库来说,在运行了一定时间后,往往会产生一些数据量较大的表,特别是对于每天新增数据较多的日志表或者流水表,大表对于日常的运维非常的不方便,特别是数据的清理、迁移,表的访问性能也会随着数据量的增大而受到影响,因此,对于大表我们需要进行优化拆分,通常拆分的方案有

📣 3.大表转分区

✨ 3.1 数据库参数调整
–导出时设置
set global wait_timeout=28800000;
set global net_read_timeout=28800;
set global net_write_timeout=28800;
set global max_allowed_packet=1G;
导入时设置
#关闭二进制日志
set sql_log_bin=0;
##默认为1时代表每一次事务提交都直接将日志写入硬盘
将其修改为2时代表不直接写入硬盘而是写入系统缓存,等待定时flush到硬盘
set global innodb_flush_log_at_trx_commit = 2;
##当每进行20000次事务提交之后,MySQL将进行一次fsync之类的
磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
set global sync_binlog = 20000;
set global max_allowed_packet=110241024*1024;
set global net_buffer_length=100000;
set global interactive_timeout=28800000;
set global wait_timeout=28800000;
✨ 3.2 分别导出表结构和数据
目的是导出表结构重新建表,并将导出的数据导入分布表--导出表结构
mysqldump -uroot -proot -h192.168.6.10 -P3306 --databases XXX \
--tables XXX --single-transaction \
--hex-blob --no-data --routines --events --triggers --master-data=2 --set-gtid-purged=OFF \
--default-character-set=utf8 | sed -e 's/DEFINER[ ]*=[ ]*[^*]*\*/\*/' \
-e 's/DEFINER[ ]*=.*FUNCTION/FUNCTION/' \
-e 's/DEFINER[ ]*=.*PROCEDURE/PROCEDURE/' \
-e 's/DEFINER[ ]*=.*TRIGGER/TRIGGER/' \
-e 's/DEFINER[ ]*=.*EVENT/EVENT/' \
-e 's/DEFINER[ ]*=.*SQL SECURITY DEFINER/SQL SECURITY DEFINER/' \
> /home/mysql/backup/XXX_ddl.sql--导出数据,可以带条件 --where="column1=1"
mysqldump -uroot -proot -h192.168.6.10 -P3306 --databases XXX \
--tables XXX \
--single-transaction --hex-blob --no-create-info \
--skip-triggers --master-data=2 \
--default-character-set=utf8 > /home/mysql/backup/XXX_data.sql
✨ 3.3 备份原表
RENAME TABLE ### TO XXXX;
在进行表重命名时,需要注意以下几点:
1.确保新表名不与现有表名冲突:
在重命名表时,需要确保新表名在当前数据库中是唯一的,
以避免与现有表名发生冲突。
2.检查外键关联:如果表存在外键关联,
那么在重命名表时需要确保外键关联的表名也相应地进行了更新。
✨ 3.4 新建原表
mysql -uroot -proot
-h192.168.6.10 -P3306 数据库名
-f --default-character-set=utf8 <XXX_ddl.sql
说明:通过dump导入的方式,就可以新建原表
3.5 在线分区

alter table account_history partition by range(to_days(create_time))
(PARTITION create_time_202401 VALUES LESS THAN (to_days('2024-02-01')),PARTITION create_time_202402 VALUES LESS THAN (to_days('2024-03-01')),PARTITION create_time_DEFAULTE VALUES LESS THAN MAXVALUE
); 结果报错:
Error Code: 1503. A UNIQUE INDEX must
include all columns in the table's partitioning function'
主键必须包含分区字段才可以
ALTER TABLE account_history DROP PRIMARY KEY,
ADD PRIMARY KEY(`id`,`create_time`);如何将分区表转换回普通表
ALTER TABLE account_history remove partitioning;
分区的过程是将一个表或索引分解为多个更小、更可管理的部分。
对于开发者而言,分区后的表使用方式和不分区基本上还是一模一样,
只不过在物理存储上,
原本该表只有一个数据文件,现在变成了多个,
每个分区都是独立的对象,可以独自处理,
也可以作为一个更大对象的一部分进行处理。
为此落实在数据库端的历史检索SQL响应时间就缩短到1-5秒时间范围

📣 4.SQL调优
✨ 4.1 慢查询开启
慢查询日志(slow_query_log)主要用来记录执行时间超过设置的某个时长的SQL语句,
能够帮助数据库维护人员找出执行时间比较长、
执行效率比较低的SQL语句,并对这些SQL语句进行针对性优化。
• 慢查询日志可以帮助 DBA 找出执行效率缓慢的 SQ语句,
为数据库优化工作提供帮助。
• 慢查询日志默认是不开启的,
建议开启慢查询日志。
• 当需要进行采样分析时手工开启。
除了在文件中配置开启慢查询日志外,
也可以在MySQL命令行中修改参数开启慢查询日志
mysql> SET GLOBAL slow_query_log = 1;
mysql> SET GLOBAL slow_query_log_file = ‘/data/mysql/log/query_log/slow_statement.log’;
mysql> SET GLOBAL long_query_time = 10;
mysql> SET GLOBAL log_output = ‘FILE’;
✨ 4.2 DB参数优化
在这里我列出了官方推荐以及我实践中的稳定性良好的可靠的参数,
以 InnoDB 为主。
--Connections
# 保持在缓存中的可用连接线程
# default = -1(无)
thread_cache_size = 16
# 最大的连接线程数(关系型数据库)
# default = 151
max_connections = 1000
# 最大的连接线程数(文档型/KV型)
# default = 100
#mysqlx_max_connections = 700--缓冲区 Buffer
# 缓冲区单位大小;default = 128M
innodb_buffer_pool_size = 128M
# 缓冲区总大小,内存的70%,单位大小的倍数
# default = 128M
innodb_buffer_pool_size = 6G
# 以上两个参数的设定,MySQL会自动改变 innodb_buffer_pool_instances 的值--I/O 线程数
# 异步I/O子系统
# default = NO
innodb_use_native_aio = NO
# 读数据线程数
# default = 4
innodb_read_io_threads = 32
# 写入数据线程数
# default = 4
innodb_write_io_threads = 32--Open cache
# default = 5000
open_files_limit = 10000
# 计算公式:MAX((open_files_limit-10-max_connections)/2,400)
# default = 4000
table_open_cache = 4495
# 超过16核的硬件,肯定要增加,以发挥出最大性能
# default = 16
table_open_cache_instances = 32
✨ 4.3 索引创建原则
过多查询的表,过少写入的表。
数据量过大导致的查询效率慢。
经常作为条件查询的列。
批量的重复值,不适合创建索引;比如<业务状态>列
值过少重复的列,适合创建索引;比如、列尽量能够覆盖常用字段
字段值区分度高
字段长度小(合适的长度,不是越小越好,至少能足够区分每个值)
相对低频的写入操作,以及高频的查询操作的表和字段上建立索引
通过非聚集索引检索记录的时候,需要2次操作,先在非聚集索引中检索出主键,然后再到聚集索引中检索出主键对应的记录,这个过程叫做回表,比聚集索引多了一次操作。
✨ 4.4 查询建议
1.避免使用*,以避免回表查询。
2.不常用的查询列或text类型的列,尽量以单独的扩展表存放。
3.条件避免使用函数。
4.条件避免过多的or,建议使用in()/union代替,
in中的数据不可以极端海量,至少个数小于1000比较稳妥。
5.避免子查询,子查询的结果集是临时表不支持索引、或结果集过大、或重复扫描子表;
以join代替子查询,尽量以inner join代替最为妥当。
6.避免使用’%Sol%'查询,或以’Sol%'代替。
📣 5.总结
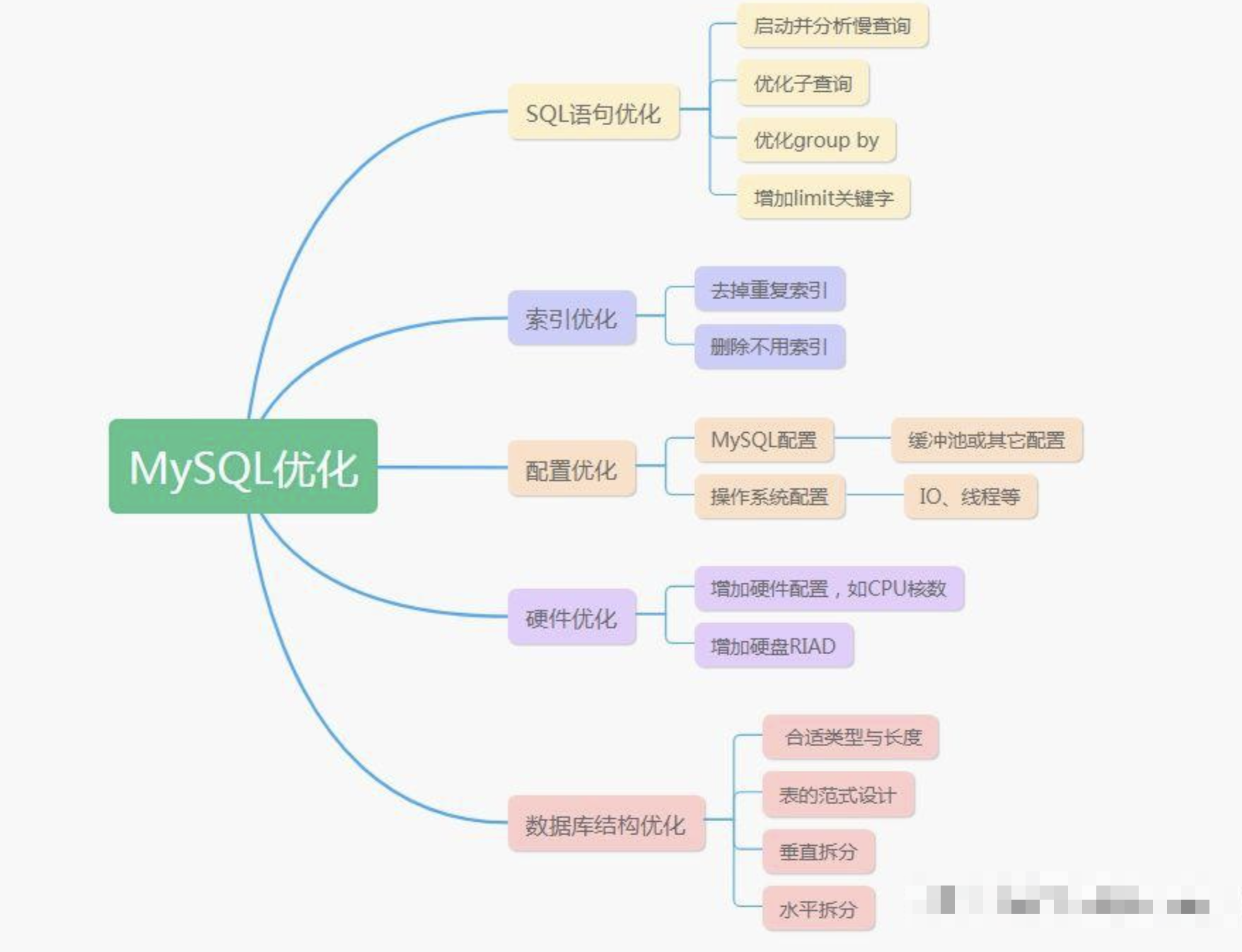
MySQL是一款广泛使用的关系型数据库管理系统。
随着数据量的增加和应用需求的变化,数据库性能调优变得越来越重要。
本文介绍的MySQL调优的经验,并通过实例分析,
帮助您更好地理解如何提高数据库性能。